
Click on the above“Beginner’s Guide to Vision” to select “Star” or “Pin“
Important content delivered at the first moment
In recent years, the field of computer vision recognition and search has been very active, with many startups emerging and large companies investing heavily in this area. Visual search is actually one of the most important research topics in the field of deep learning (or artificial intelligence), with very broad applications in real life.
Typically, visual search involves two tasks: first, the detection and localization of the object to be searched; second, searching for that object from a repository (knowledge graph, image library, information database, etc.) or querying related scenes. For example, from simple image-to-image search, license plate recognition, to face recognition, identification of plants or pets, tracking of humans or vehicles, autonomous driving of drones and self-driving cars, and intelligent robots, all these fields rely on computer vision search technology. This is also the significance of Google open-sourcing its object detection code based on TensorFlow.
In addition to the Faster R-CNN, R-FCN, and SSD detection algorithms already implemented in Google’s open-source version, there are many other detection algorithms, such as another end-to-end detection algorithm, YOLO (You Only Look Once), which may have slightly lower precision than Faster R-CNN (not absolute, as different data and network designs can lead to differences), but has a faster detection speed. The subsequent YOLO 9000 (an upgraded version of YOLO) is mentioned in the paper as being able to detect and recognize more than 9000 categories of objects, and it does so more quickly and accurately.

Computers can recognize images faster and more accurately than ever before, but they require a lot of data. Therefore, ImageNet and Pascal VOC have established large and free datasets containing millions of images over many years, labeling images with keywords that describe their content, including cats, mountains, pizza, and sports activities. These open-source datasets are the foundation for using machine learning for image recognition.
The annual ImageNet image recognition competition is well-known. ImageNet was initiated by computer scientists from Stanford University and Princeton University in 2009, starting with 80,000 labeled images, and today this dataset has increased to 1.4 million images, which can be used for machine training at any time.
Pascal VOC is supported by several universities in the UK, and although the number of images is smaller, each image has richer annotations. This enhances the accuracy and application range of machine learning and speeds up the entire process by omitting some tedious sub-tasks.
Today, tech giants like Google and Facebook, startups, and universities are using these open-source image collections to train their machine learning models. However, tech giants enjoy another advantage: Google and Facebook can obtain millions of already labeled images from Google Photos and social networks. Have you ever wondered why Google and Facebook allow you to upload so many images for free? The reason is that these images can train their deep learning networks to be more accurate.
1. Example illustration:
Amazon’s Firefly caused quite a stir at the time, although it is hard to say whether this product was successful, but it was indeed a bold move.
Baidu also has image search and recognition, and Microsoft does too.
Google had Google Goggles long ago, although the technology is very different from what it is today.
Pinterest also launched a similar feature last year, allowing users to search for similar photos or products based on their own shared photos.
Alibaba’s image search – Taobao emphasizes searching for the same or similar products by taking pictures with your phone.
2. If you want to build an image search engine, how do you search for images?
One method relies on tags, keywords, and text descriptions associated with the image, known as tag search, or text-to-image search.
The other method is to quantify the image and extract a set of numbers to represent the image’s color, texture, or shape, and then search for images by comparing their similarity, known as example search, or image-to-image search.
The final method combines the previous two methods, relying on both textual information related to the image and quantifying the image itself, known as hybrid search.
There are three types of image search engines: tag search, example search, and hybrid search.
Tag Search
When you enter a keyword in Google or Baidu and click the search button, this is our familiar text search method, and image tag search is very similar to text search. Image tag search engines rarely focus on the image itself, relying instead on textual clues. These clues can come from various sources, but the main methods are:
Manual annotation: In this case, administrators or users provide tags and keywords for the image content;
Contextual hints: Typically, contextual hints only apply to web pages. Unlike manual annotation where we must manually extract tags, contextual hints automatically check the text content or image tags surrounding the image. The drawback of this method is that we must assume that the content of the image is related to the text on the web page. This may apply to websites like Baidu Encyclopedia, where the images on the page are highly relevant to the content of the article;
Example Search:
These types of image search engines attempt to quantify the image itself, known as content-based image retrieval (CBIR) systems. A simple example is characterizing the color of the image by the average value of the pixel intensity, standard deviation, and skewness. (If you are just building a simple image search engine, in many cases, this method works quite well.)
For a given image dataset, all images in the dataset are calculated for feature values and stored on disk. When we quantify an image, we describe the image and extract image features. These image features are abstractions of the image and are used to characterize the content of the image; the process of extracting features from a collection of images is called indexing.
Assuming we have now extracted features from every image in the dataset, how do we search? The first step is to provide our system with a query image, which is an example we are looking for in the dataset. The query image extracts features in exactly the same way as the indexed images. We then use a distance function (such as Euclidean distance) to compare our query features with the features in the indexed dataset. We then sort and display the results based on similarity (the smaller the Euclidean distance, the more similar).
Hybrid Method:
If we are building an image search engine for Twitter. Twitter allows images to be used in tweets. At the same time, Twitter also allows you to provide tags for your tweets. We can use the tweet tags to build image tag searches and analyze and quantify the image features themselves to establish example searches. This method constructs a hybrid image search engine that includes both textual keywords and features extracted from the image.
The best example is Google’s image search. Google’s image search actually analyzes the features of the image itself to perform the search, but Google is primarily a text search engine, so it also allows you to search by tags.
3. Text search can also be subdivided into three types:
The first type uses people to label the text.
In the early days, in the 1970s and 1980s, there were very small image sets that were labeled by people, and searching by text was sufficient. This developed into the social media era around 2004, where the tags on images on platforms like Flickr were also added by people, but the volume of grassroots contributions became very large. This also enabled quite good image searches. Further down the line, labeling was no longer done by people adding tags to their own images, but by designing labeling platforms – a well-known one is Google’s acquisition of Image Labeler – which labeled images in a gamified way. These labels can certainly be used for image searches, which is a method of searching images through manually added text labels.
The second type indexes images through webpage text.
The current common image search engines on the internet are basically based on this technology. Indexing images through webpage text involves many details, including how to extract effective text from the webpage, and since 2008, many image analysis components have been introduced into web-based image searches. That is, although the image is a picture on the web page, it will also undergo content analysis – whether tagging or feature extraction – to improve the precision of text searches.
The third type is automatic labeling.
A large number of academic papers focus on this direction, known as concept detection or tagging. This can range from dozens, hundreds, to thousands or tens of thousands of labels.

4. This category can be further subdivided into several types:
Predefined categories. For example, if we predefine only a thousand categories and then train a classifier to label this image. This does not limit the range of labels, or the range of labels is very large, and then learn a common description method between images and labels to achieve a form of near-free text labeling.
Implicit tagging refers to implicit automatic labeling. During the operation of the search engine, when users search, they click on the search results, establishing a correlation between the search term and the search result through this click action. This method can also be considered a form of labeling. Although it has some noise, it is actually very effective and can even use some methods to reduce the noise and transfer labels between similar images to expand label coverage. This labeling plays a crucial role in improving the search quality of web-based image search engines.
5. Image Search – From Popularity to Decline and Now to Revival
In the early 1990s, it was known as CBIR (Content-Based Image Retrieval). However, at that time, it could only search through a few thousand or tens of thousands of images, and the search results were very difficult to guarantee. There was a term that has remained popular to this day called “semantic gap”, which was often used to question whether image-based search or CBIR was reliable.
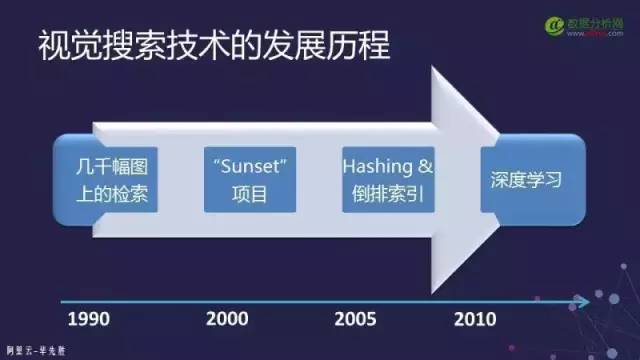
The decline of image search did not improve until around 2008, when a company called TinEye emerged, providing a web service that allows you to submit an image and find similar images on the internet. When your images grow to millions, billions, or even tens of billions, it becomes unmanageable. Therefore, at this point, images need to be indexed. Indexing in text searches is done using inverted indexing methods, which is very easy to implement. However, images are different; the description of an image is its features, and these features are a vector.
How to use high-dimensional features to build indexes:
Partition trees use various tree methods to segment and chunk data for easier searching.
Hashing: Most papers on image search focus on hashing.
Neighborhood Graph: Methods of building indexes using adjacency graphs.
Invert Index: Convert all image features into visual words and use inverted methods.
These methods can generally be converted into each other, although sometimes there is information loss during conversion. For large-scale image searches with very large data volumes, I personally believe that using inverted methods is more suitable.
Deep learning in image search:
With the advent of deep learning, we can learn a neural network according to our desired goals to extract features from images. In fact, search and recognition are inseparable, especially in large-scale image searches where recognition and detection are essential. Recognition sometimes also needs to be accomplished through search; for example, when there are many categories, it is often necessary to use search methods rather than model methods for recognition. Therefore, the boundary between search and recognition has become increasingly blurred in the era of big data, and they need to mutually utilize each other.
6. Why use OpenCV+Python to implement an image search engine?
First of all, OpenCV is an open-source computer vision processing library with extensive applications in computer vision, image processing, and pattern recognition. Its interface is safe and easy to use, and it performs well across platforms, making it a rare library for computer image and vision processing.
Secondly, Python’s syntax is more user-friendly, close to natural language and extremely flexible. Although its computational efficiency is not high, it far surpasses C++ or other languages in rapid development. Introducing pysco can optimize loops in Python code, which helps to narrow the computational gap with C/C++. Moreover, image processing requires a lot of matrix calculations, and introducing numpy for matrix operations can reduce programming complexity, allowing more focus on matching logic rather than the intricacies of computation.
Image Search Engine Algorithm and Framework Design:
Basic Steps
Use color space feature extractors and composition space feature extractors to extract image features.
Image index table construction driver generates an image feature index table for the image library to be searched.
Image search engine driver executes search commands, generates original image features and passes them to the image search matcher.
Image search matching kernel executes search matching tasks. Returns the top limit number of best matching images.
Required Modules
numpy. The weapon for scientific computing and matrix operations.
cv2. The Python module for accessing OpenCV.
re. Regularization module. Parses the composition and color feature sets in csv.
csv. Efficiently reads csv files.
glob. Regularly obtains file paths in folders.
argparse. Sets command line parameters.
Encapsulation Classes and Drivers
Color Space Feature Extractor ColorDescriptor.
Class member bins. Records the best bins allocation for the hue, saturation, and brightness distribution histogram generated in the HSV color space. If bins are allocated too much, it may lead to poor program efficiency and overly strict matching requirements; if bins are allocated too little, it may lead to insufficient matching precision and inability to represent image features.
Member function getHistogram(self, image, mask, isCenter). Generates the color feature distribution histogram of the image. The image is the image to be processed, the mask is the mask for the image processing area, and isCenter determines whether it is the center of the image to effectively weight the color feature vector. The weight is set to 5.0. The OpenCV method calcHist() is used to obtain the histogram, and normalize() method is used for normalization.
Member function describe(self, image). Converts the image from BGR color space to HSV color space (note that OpenCV reads images in BGR rather than RGB). Generates masks for the upper left, upper right, lower left, lower right, and center parts. The center mask is in the shape of an ellipse. This effectively distinguishes between the center and edge parts, allowing for weighted processing of color features in the getHistogram() method.
Composition Space Feature Extractor StructureDescriptor.
Class member dimension. Normalizes (down-samples) all images to the size specified by dimension. This allows for unified matching and generation of composition space features.
Member function describe(self, image). Converts the image from BGR color space to HSV color space (note that OpenCV reads images in BGR rather than RGB). Returns the matrix of the HSV color space, waiting for the next processing step in the search engine core.
Image Search Matching Kernel Searcher.
Class members colorIndexPath and structureIndexPath. Records the paths of the color space feature index table and the structure feature index table.
Member function solveColorDistance(self, features, queryFeatures, eps = 1e-5). Calculates the Euclidean norm of the features and queryFeatures. eps is to avoid division by zero errors.
Member function solveStructureDistance(self, structures, queryStructures, eps = 1e-5). Similarly calculates the Euclidean norm of the feature vectors. eps is to avoid division by zero errors. Needs to be normalized, and the distance of color and structure feature vectors should be proportionate, not overly biased.
Member function searchByColor(self, queryFeatures). Uses the csv module’s reader method to read the index table data. Uses the re split method to parse the data format. Uses a dictionary searchResults to store the distance between the query image and the images in the library, with the key being the image name in the library and the value being the distance.
Member function transformRawQuery(self, rawQueryStructures). Converts the unprocessed query image matrix into a feature vector form for matching.
Member function searchByStructure(self, rawQueryStructures). Similar to 4.
Member function search(self, queryFeatures, rawQueryStructures, limit = 3). Combines the results of searchByColor and searchByStructure to obtain the total matching score, where a lower score represents a smaller overall distance and a higher matching degree. Returns the top limit number of best matching images.
Index Table Construction Driver index.py.
Introduces color_descriptor and structure_descriptor. Used to parse images from the image library to obtain color space feature vectors and composition space feature vectors.
Uses argparse to set command line parameters. Parameters include image library path, color space feature index table path, and composition space feature index table path.
Uses glob to obtain the image library path.
Generates an index table text and writes it to a csv file.
The driver program can be started with the following command line format.
dataset is the image library path. color_index.csv is the color space feature index table path. structure_index.csv is the composition space feature index table path.
Image Search Engine Driver searchEngine.py.
Introduces color_descriptor and structure_descriptor. Used to parse the image to be matched (searched) to obtain color space feature vectors and composition space feature vectors.
Uses argparse to set command line parameters. Parameters include image library path, color space feature index table path, composition space feature index table path, and the path of the image to be searched.
Generates an index table text and writes it to a csv file.
The driver program can be started with the following command line format.
dataset is the image library path. color_index.csv is the color space feature index table path. structure_index.csv is the composition space feature index table path, query/pyramid.jpg is the path of the image to be searched.

7. The four basic requirements of an image search system
In the process of index establishment, we must first find these images on the internet, and after discovering them, we must select them. Because there are many images on the internet, it is impossible to include all images in the index; this involves what images should be included to meet users’ search needs. This requirement states that the selected images should be able to meet the search needs of most people at the current time point, which can actually be transformed into a machine learning problem to solve.
After selection, we need to understand and index the images to know what content is in the image. If it is web-based, we need to extract information from the webpage; if it is completely image-based, we need to extract features from the image for understanding and indexing. After establishing the index, we need to push these indexes to the search service machines. For example, an internet image search engine may require thousands of machines to hold the indexes of this image library.
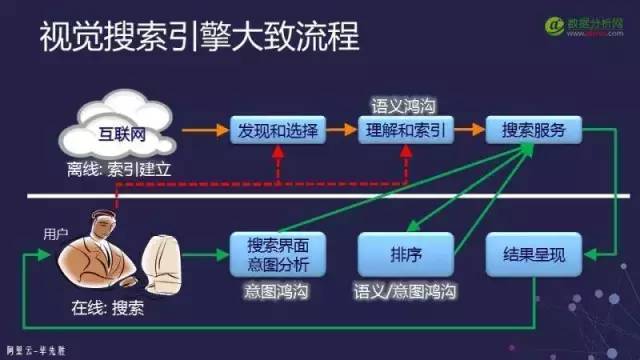
Key requirements for visual search:
The first is relevance: This is a fundamental requirement. When an image is provided, the results must be related to the given image. How to define “relevance” is generally considered for image search to mean “the same as it” or “similar to it.” For example, products of the same style are considered relevant, regardless of whether the colors are the same; relevance is generally the most concerning issue for searchers.
The second is coverage: This is very relevant to products. It should not be that I can only search for clothes and not other products, or I can only search for products and not other things. Otherwise, the user experience will be very poor, and even in e-commerce search engines, if users input a non-product, how should we respond? This involves the issue of coverage.
The third is scalability: ① Whether it can efficiently and quickly handle a large number of products and changes to products, that is, whether it can quickly put a large number of products into the index and whether the index can be easily updated, which is a scalability issue regarding the index construction process for products. ② Whether it can respond to a large number of user search requests, that is, when there are many users accessing the search service simultaneously, it must be able to respond quickly to all requests.
The fourth is user experience: This is more related to the design of interactive user interfaces.

8. Key technologies related to product image search
First, you need to know the general type of an image. For example, if it is a product, you need to know whether it is a shirt – whether it is a men’s shirt or a women’s shirt, or shoes, etc. This helps avoid completely unreliable search results; this is generally referred to as classification or recognition.
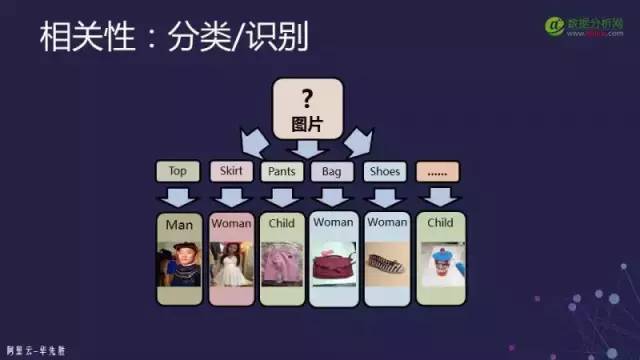
Subject detection: There are many fast methods for subject detection in the field of computer vision, generally starting with Proposal Window and then classifying it. This scenario usually requires very fast speed; all operations – including the aforementioned classification, subject detection, and subsequent steps to the final return result – must be returned to the user within hundreds of milliseconds. Therefore, our Proposal Window cannot be too many; otherwise, the computation will be enormous, leading to the subsequent Proposal Window refinement step.

Image features to describe: The basic method is still using deep learning tools to force the neural network to converge to a place so that the feature output can reflect the characteristics of the product, such as type, style, pattern, color, etc.

Coverage can be discussed from three angles:
The coverage of the index. This is what we generally refer to when mentioning coverage. Simply put, the more products included in the index, the better, and the more diverse the types, the better; this is relatively easy to understand.
The coverage of features. The coverage of features refers to the ability of product descriptions to cover various categories, not just shoes or clothing, but also other things, including non-products. To ensure precise descriptions and optimize descriptive ability, different types generally use different features for description.
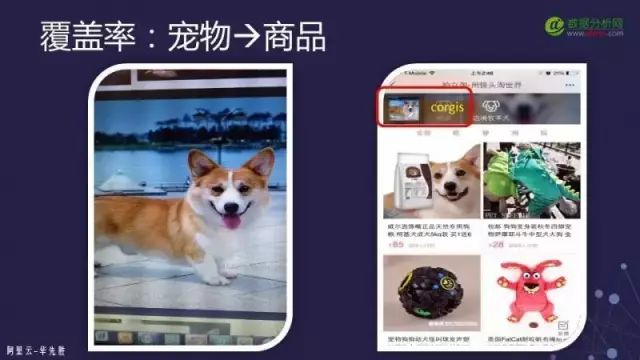
The coverage of searches. This coverage is unique to the e-commerce scenario, as e-commerce only has an index of product images and no other indexes; so if a user inputs an image that is not a product, how should we respond? For example, if a user sees a cute dog on the street and takes a picture to search on the platform, how should we handle it? At this point, we can recognize the dog and return some dog-related products to the user as a solution. If it is a landscape or food, we can also identify the scenery or recognize the calories in the food and return this information to the user.
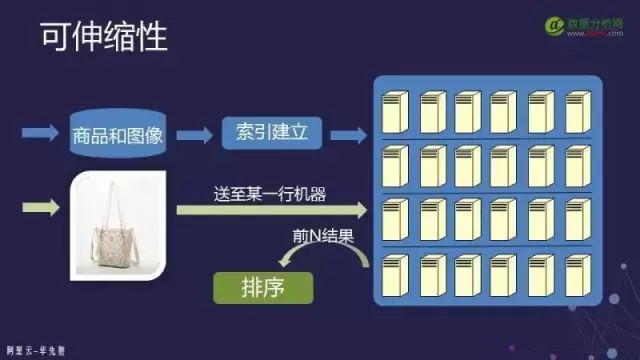
Scalability can be achieved in two main ways:
The first is through system methods, that is, implementing through a large number of machines. Indexing technology has a systemic approach, so the requirements for indexing are not that high; many methods can fully meet the construction needs of search systems. As mentioned in the architecture of search engines, indexing is distributed across many machines, so as long as the search efficiency of data on each machine is high enough, the system can complete large-scale search tasks.
The second is through algorithms, focusing on how to achieve efficiency on a single machine.
9. Image Recognition Technology:
Image recognition technology is a combination of digital image processing and pattern recognition technology. Digital image processing is the basic behavior of using computers or other digital devices to process various image information to meet target recognition needs. Pattern recognition studies how to enable machines to achieve human-like learning, recognition, and judgment capabilities regarding things, thus satisfying the judgment behavior of target recognition.
To simulate human image recognition activities, various image recognition models have been proposed. For example, the template matching model. This model holds that to recognize an object in an image, one must have a memory pattern of that object in past experiences, also known as a template. If the current stimulus matches the template in the brain, the object is recognized.
The basic process of image recognition is to extract the essential expression of representative unknown sample patterns (such as various features) and match them with the standard pattern expressions stored in the machine (known as the dictionary) one by one using certain criteria, identifying the closest expression of the input sample sub-pattern among the standard pattern expressions stored in the machine. The expression corresponding to that category is the recognition result. Therefore, image recognition technology is a process of automatically completing the recognition and evaluation of objects in images using computers and mathematical reasoning methods based on a large amount of information and data.
The image recognition process includes four stages: image acquisition (feature analysis), image preprocessing, feature extraction, and pattern matching.
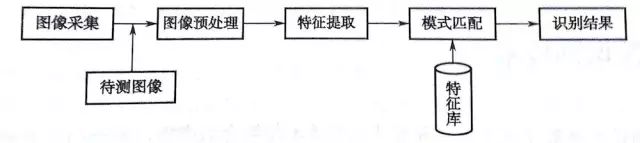
First, the original information of the image is captured using high-definition cameras, scanners, or other image acquisition devices. Traditional global feature representation methods, such as color, shape, texture, etc., are simple and intuitive but are easily affected by factors such as lighting, cropping, rotation, and noise, and are currently basically only used as auxiliary means.
The role of image preprocessing can be summarized as: using certain means to normalize image information to facilitate subsequent processing work. The role of the feature extraction section is to extract the most representative feature information of an object and convert it into the form of feature vectors or matrices. Pattern matching refers to the system comparing the features of the test image with the information in the feature library to achieve recognition through the selection of suitable classifiers.

1. Image Preprocessing
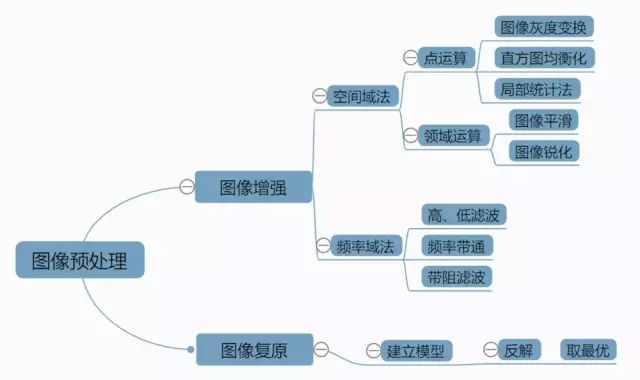
Image preprocessing technology refers to a series of operations performed before formally processing the image. Image preprocessing technology can be divided into two major aspects: image enhancement and image restoration technology. Image enhancement technology occupies a large proportion in image preprocessing, and is a necessary step in image preprocessing. Its difference from image restoration technology lies in the fact that image restoration aims to restore the original essence of the image.
Generally speaking, there are two methods of image enhancement technology: spatial domain and frequency domain methods. The spatial domain method mainly processes the image directly in the spatial domain, divided into two aspects: point operations and neighborhood operations (local operations). Point operations include several methods such as image grayscale transformation, histogram equalization, and local statistical methods;
Neighborhood operations include several aspects such as image smoothing and sharpening. The frequency domain method performs operations on the transformed values of the image in a certain transformation domain; for example, we perform a Fourier transform on the image, then perform certain calculations on the frequency spectrum in the transformation domain, and finally inverse transform the calculated image back to the spatial domain. Frequency domain methods are generally divided into high-pass, low-pass, band-pass, and band-stop filtering, etc. Image restoration technology is the process of using prior knowledge of the image to alter a degraded image.
2. Transform Domain Processing
Image transform domain processing describes the characteristics of an image using spatial frequency (wave number) as the independent variable, allowing the value of an image element to be decomposed into a linear superposition of simple oscillatory functions with different amplitudes, spatial frequencies, and phases. The various spatial frequency components and distributions in the image are referred to as spatial frequency spectrum. This decomposition, processing, and analysis of the spatial frequency characteristics of an image are called spatial frequency domain processing or wave number domain processing. Among many image transformation techniques, commonly used ones include discrete cosine transform, Walsh transform, Fourier transform, Gabor transform, and wavelet transform.
(1) Discrete Cosine Transform (DCT): The basis vectors of the DCT transformation matrix are often considered the best transformation for language and image signals, as they approximate the Toberly vector. Although it is slightly inferior in compression efficiency compared to K-L transform, its efficient processing capability is unmatched by K-L transform, and it has become a major component of international standards such as H.261, JPEG, and MPEG. It is widely used in image coding.
(2) Walsh Transform: This is an orthogonal transformation that eliminates the correlation between adjacent sampling points, concentrating signal energy in the upper left corner of the transformation matrix while producing many zero values in other areas; or within an acceptable error range, allowing small values to be omitted, thus achieving data compression. Walsh transform has been widely applied in image transmission, radar, communications, and biomedical fields.
(3) Fourier Transform: This is a commonly used orthogonal transformation, with its primary mathematical foundation based on Fourier series proposed by the famous mathematician Fourier in 1822. Its main idea is to expand periodic functions into sine series. The introduction of Fourier transform laid the theoretical foundation for images, allowing for the extraction and analysis of image information features by switching between time-space and frequency domains, simplifying computational workload. It is widely used in image transformation, image coding and compression, image segmentation, and image reconstruction.
(4) Gabor Transform: This is a windowed Fourier transform, a special case of short-time Fourier transform when the window function is a Gaussian function. Due to certain limitations of Fourier transform, Gabor proposed the windowed Fourier transform in 1946. A typical application of the windowed Fourier transform is the low-pass filter. Gabor functions can extract relevant features at different scales and orientations in the frequency domain.
(5) Wavelet Transform: Inspired by Fourier transform, Morlet proposed the concept of wavelet analysis in 1984. In 1986, renowned mathematicians Meyer and Mallat collaborated to construct a unified method for image wavelet functions – multi-scale analysis. Currently, wavelet transform theory has achieved excellent results in image denoising applications.
Frequency domain denoising is mainly utilized because some images do not yield ideal results when processed in the spatial domain, leading to the idea of transforming to the frequency domain for processing. This involves using a set of orthogonal function systems to approximate the target function being processed, thereby obtaining the corresponding series coefficients. Frequency domain processing is mainly used in processing related to image spatial frequencies, such as image restoration, image reconstruction, radiation transformation, edge enhancement, image smoothing, noise suppression, frequency spectrum analysis, and texture analysis.

3. Feature Extraction
Feature extraction is a concept in computer vision and image processing that refers to using computers to extract image information, determining whether each point of the image belongs to an image feature. The result of feature extraction divides the points on the image into different subsets, which often belong to isolated points, continuous curves, or continuous areas.
(1) Feature Selection
The original number of features is large, or the original samples exist in a high-dimensional space. The process of selecting the most effective features from a set of features to reduce the dimensionality of the feature space is called feature selection. This means simply ignoring features that do not contribute to or contribute little to class separability. Feature selection is a key issue in image recognition.
(2) Feature Transformation
Through mapping or transformation methods, features described in high-dimensional space can be represented in low-dimensional space, and this process is called feature transformation. The features obtained through feature transformation are some combination of the original feature set, and the new features contain information from the original entire feature set. Principal component analysis is the most commonly used feature transformation method.
The tasks of feature selection and extraction are very important. Feature selection is a key issue in pattern recognition. Since it is often difficult to find the most important features in many practical problems, or due to constraints, one cannot measure them, this complicates the task of feature selection and extraction, making it one of the most challenging tasks in constructing pattern recognition systems.
The basic task of feature selection and extraction is how to identify the most effective features from many features. The core content of solving the feature selection and extraction problem is how to evaluate the existing features and how to generate better features from existing features. Common image feature extraction and description methods include color features, texture features, and geometric shape feature extraction and description methods.

Feature Extraction Algorithms:
Spot feature detection, representative algorithms include: LOG (Laplacian of Gaussian operator detection), DOH (using the second-order derivative Hessian matrix and its determinant of image points);
Corner feature detection, representative algorithms include: Harris corner detection, Shi-Tomasi corner detection, FAST corner detection, etc.;
SIFT (Scale-Invariant Feature Transform) feature detection is a groundbreaking feature detection algorithm. Due to its excellent affine invariance, rotation invariance, and tolerance to lighting, noise, and viewpoint changes, it is widely used in image search matching, and many improved algorithms based on SIFT have emerged.
SURF (Speeded Up Robust Features) feature detection is an efficient variant of SIFT, simplifying the SIFT feature extraction algorithm for higher computational efficiency, enabling real-time processing.
ORB feature detection, based on the FAST feature point detection algorithm and the BRIEF feature description method, has undergone some optimization and improvement, making it a good choice outside SIFT and SURF (both of which are protected by patents).
KAZE/AKAZE (Accelerated KAZE) feature detection has superior performance and stability compared to SIFT, representing a significant breakthrough following SIFT, and is currently the image feature extraction algorithm I prioritize in the system.
Additionally, there are feature extraction detection algorithms based on BRISK/SBRISK (Binary Robust Invariant Scalable Keypoints), FREAK (Fast Retina Keypoints), etc.
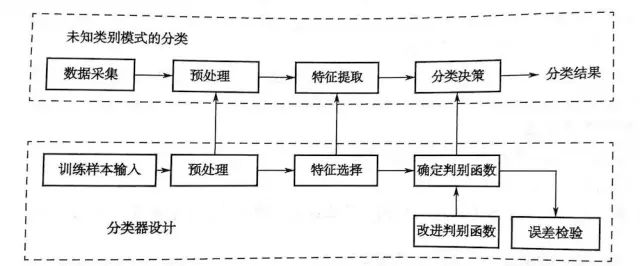
4. Pattern Recognition
Pattern recognition can be divided into supervised learning and unsupervised learning based on the presence or absence of standard samples. Pattern recognition classification or description is typically based on a set of patterns that have already been classified or described, known as the training set, and the learning strategy that arises from this is called supervised learning. Learning can also be unsupervised learning, in which case the system does not require prior knowledge of the pattern classes, but learns to judge the categories of patterns based on statistical regularities or similarities of patterns.
(1) Data Collection
Data collection refers to converting various information of the research object into a collection of numerical or symbolic (string) sets that can be received by computers using various sensors. This space composed of these numerical or symbolic (string) sets is habitually called pattern space. The key here is the selection of sensors.
The types of data typically obtained include:
Physical parameters and logical values: body temperature, test data, descriptions of whether parameters are normal.
One-dimensional waveforms: EEG, ECG, seasonal vibration waveforms, speech signals, etc.
Two-dimensional images: text, fingerprints, maps, photos, etc.
(2) Preprocessing
To extract effective information for recognition from these numerical or symbolic (string) sets, preprocessing must be conducted to eliminate noise from the input data or information, excluding irrelevant signals and leaving only features closely related to the nature of the research object and the recognition method adopted (such as representing the shape, perimeter, area of the object, etc.).
For example, in fingerprint recognition, the fingerprint scanning device outputs a fingerprint image that varies with the contrast, brightness, or background, and sometimes may even become distorted. However, what people are interested in is only the fingerprint lines, bifurcation points, and endpoints in the image, excluding other parts and the background. Therefore, reasonable filtering algorithms, such as block histogram directional filtering and binary filtering, must be employed to filter out these unnecessary parts from the fingerprint image.
(3) Feature Extraction
Feature extraction refers to the process of searching for the most effective features from raw data, obtaining the features that best reflect the nature of classification, and transforming the high-dimensional measurement space (the space composed of raw data) into a low-dimensional feature space (the space relied upon for classification recognition) to reduce the difficulty of subsequent processing. Features that are easily obtained by humans can be very difficult for machines to acquire, which is the problem of feature selection and extraction in pattern recognition.
Generally, the more types of candidate features there are, the better the results should be. However, this can lead to the curse of dimensionality, where the feature dimensionality is too high for computers to solve. How to determine an appropriate feature space is a very important issue in designing pattern recognition systems.
There are two basic methods to optimize the feature space:
The first is feature selection; if the selected feature space allows similar objects to have compact distributions, it provides a good foundation for successful classifier design. Conversely, if samples of different categories are mixed together in that feature space, no matter how good the design method is, it cannot improve the accuracy of the classifier.
The second is feature combination optimization, which reconstructs the original feature space through a mapping transformation to construct a new, simplified feature space.
(4) Classification Decision
Based on the pattern feature space, the final part of pattern recognition can be carried out: classification decision. The output at this stage may be the type to which the object belongs or the model number of the pattern in the database that is most similar to the object. Given several samples of known categories and features, for example, the discrimination of handwritten Arabic numerals is a classification problem with 10 categories. The machine must first understand the shape features of each handwritten digit. Different people may write the same digit differently, and even the same person may write the same digit in various ways, so the machine must know which category it belongs to. Therefore, a sample library must be established for classification problems. Based on these sample libraries, a discriminant classification function must be established, which is a process accomplished by the machine and is called the learning process. Then, for a new unknown object, its features are analyzed to determine which category it belongs to, which is a method of supervised classification.
The specific steps involve establishing a training set in the feature space, knowing the category of each point in the training set, and based on these conditions, seeking a certain discriminant function or criterion, designing a decision function model, and then determining the parameters in the model based on the samples in the training set, which can be used for discrimination, applying the discriminant function or criterion to judge which class each unknown category point should belong to. In the field of pattern recognition, this process is generally referred to as the training and learning process.
The rules for classification are determined based on the information provided by training samples. The design of the classifier is completed during the training process, utilizing a batch of training samples, including samples of various categories, to roughly outline the regularity of the distribution of various objects in the feature space, providing information for determining what kind of mathematical formula to use and the parameters in those formulas.
In general, the decision of what type of classification function to use is made by humans. The selection of classifier parameters or the results obtained during the learning process depend on the criteria function chosen by the designer. The optimal solutions of different criteria functions correspond to different learning results, yielding classifiers with varying performance. The parameters in the mathematical expressions are often determined through learning, and during the learning process, if it is found that the currently used classification function leads to classification errors, the information on how to correct the errors can be used to guide the classification function in the right direction, forming an iterative process. If the classification function and its parameters increasingly reduce the occurrence of errors, it can be said that it is gradually converging, and the learning process has achieved results, allowing the design to conclude.
Depending on different application purposes, the content of the four parts of the pattern recognition system varies greatly, especially in the data preprocessing and classification decision parts. To improve the reliability of recognition results, it is often necessary to incorporate a knowledge base (rules) to correct potential errors, or to significantly narrow the search space of the patterns to be recognized in the model library by introducing constraints, thereby reducing the computational load of matching.

It is said that
Deep learning is closely related to big data. Does this mean that the larger the dataset, the higher the accuracy of the trained image recognition algorithm?
Over the past 10 years, computer vision technology has achieved great success, much of which can be attributed to the application of deep learning models. Additionally, since 2012, the performance of these systems has significantly improved due to:
1) More complex deep models;
2) Enhanced computational performance;
3) The emergence of large-scale labeled data.
Every year, we see improvements in computational performance and model complexity, from AlexNet with 7 layers in 2012 to ResNet with 101 layers in 2015. However, the scale of available datasets has not expanded proportionately. ResNet with 101 layers was trained using the same dataset as AlexNet: 100,000 images in ImageNet. Over the past five years, GPU computing power and model complexity have continued to grow, but the scale of training datasets has remained unchanged;
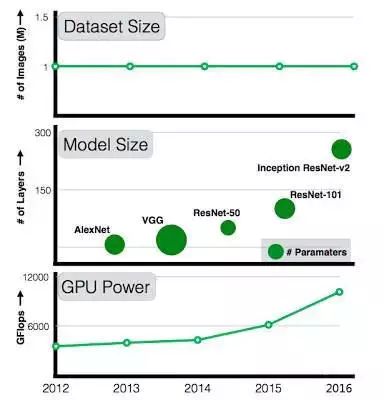
For instance, in 2017, the relationship between “large amounts of data” and deep learning was explored:
1) Using current algorithms, can visual performance still be optimized by providing increasingly noisy labeled images;
2) What is the relationship between data and performance for standard visual tasks such as classification, object detection, and image segmentation;
3) Utilizing large-scale learning techniques to develop state-of-the-art models capable of handling various tasks in the field of computer vision.
Of course, the key issue is where to find datasets that are 300 times larger than ImageNet.
Google has been striving to build such datasets to optimize computer vision algorithms. With the efforts of Geoff Hinton, Francois Chollet, and others, Google has internally constructed a dataset containing 300 million images, labeling these images into 18,291 categories, named JFT-300M. The algorithm used for image labeling combines complex raw network signals with associations between web pages and user feedback. Through this method, these 300 million images have received over 1 billion labels (an image can have multiple labels). Among these 1 billion labels, approximately 375 million were selected through algorithms to maximize the accuracy of the labels for the chosen images. However, there is still noise in these labels: about 20% of the labels for the selected images contain noise.
Finally, unexpected results were obtained from the training:
Better representation learning can be beneficial.
Large-scale data helps representation learning, thus optimizing the performance of all visual tasks we study. Establishing large-scale datasets for pre-training is crucial. This also indicates that unsupervised representation learning and semi-supervised representation learning methods hold good prospects. It seems that the scale of data continues to suppress the noise present in labels.
As the number of training data increases significantly, task performance rises linearly. The relationship between visual task performance and the amount of training data (in logarithmic scale). Even with a dataset of 300 million images, no stagnation in performance increase has been observed.
Model capacity is critical; if we hope to fully utilize the dataset of 300 million images, we need larger (deeper) models. For example, for ResNet-50, the increase in COCO object detection scores is limited, only 1.87%, while using ResNet-152, this score increases by 3%. Furthermore, constructing a dataset containing 300 million images is not the ultimate goal. It is essential to explore whether models can continue to optimize with even larger datasets (containing over 1 billion images).
10. Fields of Application for Visual Search and Image Recognition:
1. Combined with e-commerce, searching for the same or similar clothing items, bags;
2. Combined with social networks, achieving better image understanding and interaction;
3. Combined with self-media, facilitating the search for images and video materials;
4. Combined with intellectual property, accurately tracing image sources and copyright information;
5. Combined with medical health, enabling more accurate pathological research;
6. Combined with industrial production, achieving more reliable defect object screening;
7. Combined with network security, enabling better automated filtering and auditing of image and video content;
8. Combined with security monitoring, achieving more accurate tracking and positioning;
9. Combined with intelligent robots, enabling better object recognition and scene positioning…
Image search, combined with user usage scenarios, can accurately identify and extract the main information in images under complex background conditions and use advanced deep learning techniques in the current field of artificial intelligence for semantic analysis of the obtained image information. The application range of image search has been expanding, such as:
1. Mobile photo shopping: Take a photo of a product in a bookstore, supermarket, or electronics store, and find its price in online malls. Mobile photo shopping search allows users to search for products simply by taking photos of corresponding items, making online shopping more intuitive and convenient.
2. Similar products on shopping websites: Automatically list similar products at the bottom of specific product pages, allowing users to quickly find similar images, saving time and improving efficiency.
3. Catalog sales: Users can take pictures of items of interest while enjoying the convenience and pleasure of flipping through shopping catalogs, immediately being directed to the merchant’s website, activating online behavior. This provides users with a convenient purchasing route.
4. Mobile guided value-added services: Focus on providing viewers with information experiences behind the works; users can take pictures of interesting exhibits, and related in-depth information will immediately display on their phones.
5. Copyright protection: By using image recognition technology, discover where the same source images appear overall or partially, both online and offline, to protect the copyright of image owners.
11. Future Trends in Image Search Development:
The future of image search and recognition technology: Data, users, models, and systems are used together; because it is absolutely not a single algorithm that can solve it, nor is it solely reliant on deep learning, and it is certainly not just a search system or recognition system that can solve it.
Good news!
The Beginner's Guide to Vision Knowledge Planet is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Beginner's Guide to Vision" public account to download the first OpenCV extension module tutorial in Chinese on the internet, covering more than twenty chapters including extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: 52 Lectures on Python Vision Practical Projects
Reply "Python Vision Practical Projects" in the background of the "Beginner's Guide to Vision" public account to download 31 practical vision projects including image segmentation, mask detection, lane detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: 20 Lectures on OpenCV Practical Projects
Reply "20 Lectures on OpenCV Practical Projects" in the background of the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat number below to join the group, and note: "nickname + school/company + research direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for notes; otherwise, you will not be approved. After successfully added, you will be invited into the relevant WeChat group based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~