

Selected from Awni
Translated by Machine Heart
Contributors:Nurhachu Null, Lu Xue
After the application of deep learning in the field of speech recognition, the word error rate has significantly decreased. However, speech recognition has not yet reached human levels and still has multiple unresolved issues. This article introduces the unresolved problems in speech recognition from various aspects such as accents, noise, multiple speakers, context, and deployment.
Since the application of deep learning in the field of speech recognition, the word error rate has significantly decreased. However, even though you have read many papers on this topic, we still have not achieved human-level speech recognition. There are many failure modes in speech recognizers. Recognizing these issues and taking steps to address them is key to advancing speech recognition. This is the only way to transform automatic speech recognition (ASR) from “serving some people most of the time” to “serving everyone all the time.”
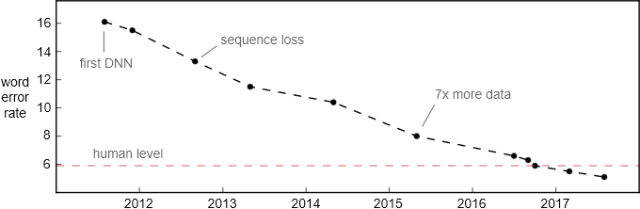
Improvement of word error rate on the Switchboard conversational speech recognition benchmark. This test set was collected in 2000 and includes 40 phone recordings, with each conversation taking place between two randomly selected native English speakers.
If the dialogue speech recognition results based on Switchboard have reached human levels, it is akin to claiming that autonomous driving has reached human driving levels in a sunny, smoothly flowing town. Although the progress in speech recognition on conversational speech is evident, the assertion that it has reached human levels is ultimately too broad. The following are some aspects of speech recognition that still need improvement.
Accents and Noise
One of the most obvious flaws in speech recognition is its handling of accents and background noise. The most direct reason is that the vast majority of training data consists of American English with a high signal-to-noise ratio. For instance, the training and testing sets for Switchboard conversational speech are recorded by native English speakers (mostly Americans) in almost noise-free environments.
However, more training data itself does not overcome this issue. Many languages have dialects and accents. It is impractical to collect sufficiently annotated data for every case. Developing a speech recognizer specifically for American English requires over 5,000 hours of transcribed audio data!
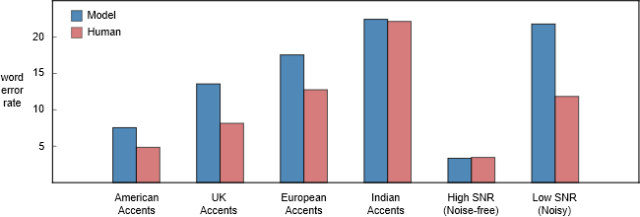
Comparison of word error rates between the Baidu Deep Speech 2 model and human transcribers on different types of speech data. We note that human transcribers perform worse on non-American-accented speech. This may be because most transcribers are Americans. I hope local transcribers in a certain area will have a lower error rate.
As for background noise, the noise inside a moving car is almost impossible to have a signal-to-noise ratio of -5dB. Humans can easily understand each other in such environments, but the performance of speech recognizers drops sharply due to the presence of noise. From the above figure, we can see that there is a huge gap in word error rates between humans and models in low and high signal-to-noise ratio audio.
Semantic Errors
Typically, word error rate is not the actual target of a speech recognition system. What we care about is the semantic error rate, which is the proportion of segments of speech that are not correctly understood in meaning.
For example, if someone says “let’s meet up Tuesday,” and the speech recognizer interprets it as “let’s meet up today.” There can be word error rates even without semantic errors. In this example, if the speech recognizer drops “up” and recognizes it as “let’s meet Tuesday,” the meaning of the sentence does not change.
When using word error rate as a standard, we must be cautious. A 5% word error rate corresponds to about one error every 20 words. If a sentence has a total of 20 words (which is the average length of an English sentence), then in this case, the sentence error rate is 100%. We hope that the erroneous words do not change the meaning of the sentence; otherwise, even if the word error rate is only 5%, the speech recognizer may completely misinterpret the entire sentence’s meaning.
When comparing models with humans, it is important to examine the nature of the errors rather than just focusing on the conclusive number of word error rate (WER). From my experience, humans generally make fewer errors than recognizers during transcription, especially severe semantic errors.
Recently, Microsoft researchers compared the errors made by humans and Microsoft’s human-level speech recognizer [3]. They found that one difference between the two is that the model confuses “uh” and “uh huh” more frequently than humans. These two phrases have significantly different meanings: “uh” is just a filler word, while “uh huh” indicates agreement and acknowledgment. Both humans and models make many similar errors.
Monophonic, Multiple Speakers
The Switchboard conversational speech recognition task is relatively easy because each speaker records using an independent microphone. There is no overlapping speech from multiple speakers in the same audio stream. However, humans can understand spoken content even when multiple speakers talk simultaneously.
A good conversational speech recognizer must be able to segment audio based on who is speaking (sound source). It should also understand audio with overlapping speech from multiple speakers (source separation). This should be achieved without requiring a microphone to be installed at each speaker’s mouth, allowing conversational speech recognition to work anywhere.
Domain Variation
Accents and background noise are just two issues that speech recognizers need to enhance robustness against. There are several other factors:
-
Echo in changing acoustic environments
-
Hardware defects
-
Defects in audio encoding and compression
-
Sampling rates
-
Speaker’s age
Most people can’t even distinguish between mp3 files and wav files. Before we claim that the performance of speech recognizers has reached human levels, they need to be robust enough to handle these issues.
Context
You may notice that the error rate at human levels is actually quite high on benchmark test sets similar to Switchboard. If, during a conversation with a friend, they misunderstand one word every 20 words, it becomes very difficult to continue the conversation.
The reason for this is that the evaluation is conducted without considering context. In real life, many other cues help us understand what someone is saying. Humans use context that speech recognizers do not include, such as:
-
The historical process of the conversation and the topic being discussed.
-
Visual cues when a person is speaking, such as facial expressions and lip movements.
-
Understanding of the conversation partner.
Currently, Android’s speech recognizer has access to your contacts, allowing it to accurately recognize your friends’ names. Voice search in mapping products uses your geographical location to narrow down the range of where you want to navigate.
The accuracy of automatic speech recognition (ASR) systems has indeed improved with the help of such signals. However, here we only have a preliminary understanding of the types of context that can be used and how to utilize them.
Deployment and Application
The latest advancements in conversational speech recognition are not deployable. When considering what makes a new speech recognition algorithm deployable, it is helpful to assess its latency and required computational power. These two are related; generally, if an algorithm requires more computational power, the latency it introduces will also increase. However, for simplicity, I will discuss them separately.
Latency: What I mean by “latency” refers to the time from when the user finishes speaking to when the transcription is complete. Low latency is a common product constraint in ASR. It can significantly affect user experience. Latency requirements of tens of milliseconds are common in ASR systems. While this may sound extreme, please remember that generating transcription results is usually the first step in a series of expensive computations. For example, in voice search, the actual network-scale search must occur after speech recognition.
Bidirectional recurrent layers are a good example of improvements to eliminate latency. All the latest advanced results in conversational speech recognition use them. The issue is that we cannot compute anything with the first bidirectional layer until the user finishes speaking. Therefore, latency increases with the length of the speech.
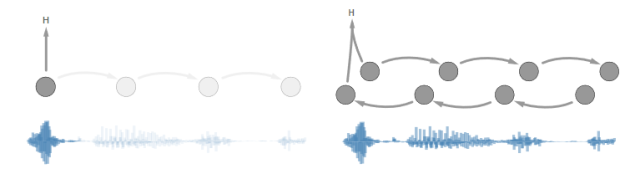
Left image: We can start transcribing immediately when forward recurrence occurs.
Right image: When bidirectional recurrence occurs, we must wait for all speech to arrive before we can start transcribing.
The effective way to incorporate future information in speech recognition is still under research and discovery.
Computation: The computational power required to transcribe a speech is an economic constraint. We must consider the cost-effectiveness of improving the accuracy of speech recognizers. If an improvement fails to meet the economic threshold, it cannot be deployed.
The Next Five Years
The field of speech recognition still has many open challenges, including:
-
Extending speech recognition capabilities to new domains, accents, and far-field, low signal-to-noise ratio speech.
-
Incorporating more contextual information into the speech recognition process.
-
Source and sound source separation.
-
Semantic error rates and new evaluation methods for speech recognizers.
-
Ultra-low latency and ultra-efficient inference.
I look forward to progress in the field of speech recognition in these areas over the next five years.
Original link: https://awni.github.io/speech-recognition/
Long press the QR code below to subscribe for free!
How to Join the Society
Register as a member:
Individual Membership:
Follow the society’s WeChat: China Command and Control Society (c2_china), reply “Individual Member” to obtain the membership application form, fill out the form as required, and if you have any questions, you can leave a message in the public account. You can only pay the membership fee online after passing the society’s review.
Institutional Membership:
Follow the society’s WeChat: China Command and Control Society (c2_china), reply “Institutional Member” to obtain the membership application form, fill out the form as required, and if you have any questions, you can leave a message in the public account. You can only pay the membership fee after passing the society’s review.
Recent Activities of the Society
1. The Second National Member Representative Conference of the China Command and Control Society
December 6, 2017
Long press the QR code below to follow the society’s WeChat

Thank you for your attention