
Jishi Guide
This article summarizes Prompt Learning/Tuning. >> Join the Jishi CV technology exchange group to stay at the forefront of computer vision
Since the advent of Self-Attention and Transformer, they have become the new stars in the field of natural language processing. Thanks to the global attention mechanism and parallel training, Transformer-based natural language models can easily encode long-distance dependencies, while parallel training on large-scale natural language datasets has become possible. However, due to the wide variety of natural language tasks and the minor differences between tasks, fine-tuning a large model separately for each task is not cost-effective. In computer vision, different image recognition tasks often also require fine-tuning of the entire large model, which is also economically impractical. The introduction of Prompt Learning provides a good direction for this problem.
This article’s NLP section mainly references the review [1].
1. Development of NLP Models
In the past, many machine learning methods were based on fully supervised learning.
Since supervised learning requires a large amount of data to learn high-performance models, and in NLP, large-scale training data (i.e., data labeled for specific tasks) is insufficient, researchers typically focused on feature engineering before the emergence of deep learning, which involves using domain knowledge to extract good features from the data;
After the advent of deep learning, as features can be learned from data, researchers turned to architecture engineering, which involves designing a suitable network structure to introduce inductive bias into the model, thereby facilitating the learning of good features.
From 2017 to 2019, NLP models began to shift to a new paradigm (BERT), namely pre-train and fine-tune. In this paradigm, a language model (LM) is pre-trained using a fixed structure, and the pre-training method involves having the model complete the context (e.g., fill-in-the-blank).
Since pre-training does not require expert knowledge, it can be trained directly on large-scale text collected from the internet. Then this LM is adapted to downstream tasks by introducing additional parameters or fine-tuning. At this point, researchers turned to objective engineering, which is to design better objective functions for pre-training and fine-tuning tasks.
2. Prompt Learning
2.1 What is a Prompt?
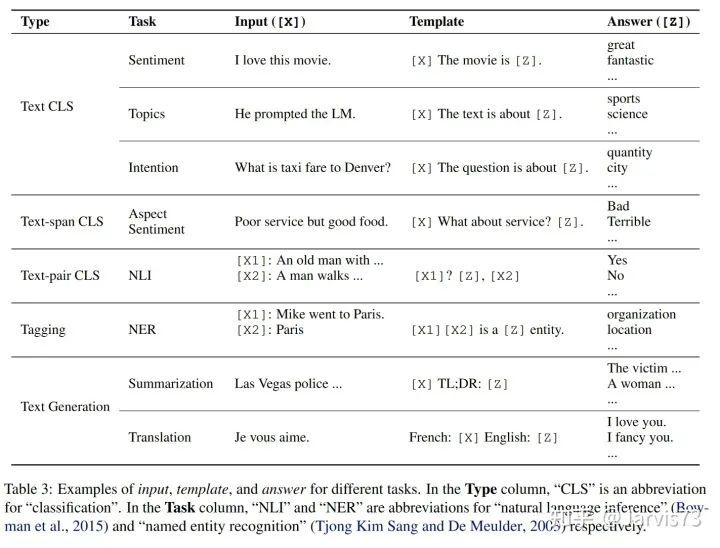
During the process of objective engineering, researchers found that aligning the objectives of downstream tasks with the objectives of pre-training is beneficial. Therefore, downstream tasks reconstruct the original task objectives into fill-in-the-blank questions by introducing textual prompts.
For example, a reconstruction of the input “I missed the bus today.” is:
-
Sentiment Prediction Task. Input: “I missed the bus today. I felt so___.” where “I felt so” is the prompt, and then the LM fills in the blank with a word representing sentiment. -
Translation Task. Input: “English: I missed the bus today. French: ___” where “English:” and “French:” are prompts, and then the LM should fill in the corresponding French sentence in the blank.
We find that using different prompts on the same input can achieve different tasks, thereby allowing downstream tasks to align well with pre-training tasks and achieve better predictive performance.
Later, researchers discovered that using different prompts on the same task also leads to significant differences in predictive performance, which is why many studies have begun to focus on prompt engineering.
2.2 What Pre-trained Models Are There?
-
Left-to-Right LM: GPT, GPT-2, GPT-3 -
Masked LM: BERT, RoBERTa -
Prefix LM: UniLM1, UniLM2 -
Encoder-Decoder: T5, MASS, BART
2.3 What Methods of Prompt Learning Are There?
-
Classified by the shape of the prompt: fill-in-the-blank style, prefix style. -
Classified by human involvement: manually designed, automatic (discrete, continuous)
3. Prompt Tuning
3.1 Strategies for Fine-tuning
Fine-tuning large-scale pre-trained models on downstream tasks has become a common training mode for many NLP and CV tasks. However, as the model size and the number of tasks increase, fine-tuning the entire model results in storing a model copy for each fine-tuning task, consuming a large amount of storage space. This becomes especially important in edge devices where storage space and network speed are limited, making parameter sharing crucial.
A relatively straightforward method of sharing parameters is to fine-tune only a portion of the parameters or to add a small number of additional parameters to the pre-trained model. For example, for classification tasks:
-
Linear: only fine-tune the classifier (a linear layer), freezing the entire backbone network. -
Partial-k: only fine-tune the last k layers of the backbone network, freezing other layers [2][3]. -
MLP-k: add a k-layer MLP as a classifier. -
Side-tuning [4]: train a “side” network, then fuse the pre-trained features and the “side” network’s features before inputting them into the classifier. -
Bias: only fine-tune the bias parameters of the pre-trained network [5][6]. -
Adapter [7]: insert additional MLP modules into the Transformer via a residual structure.
In recent years, Transformer models have shone in NLP and CV. Transformer-based models have matched or even surpassed convolution-based models in numerous CV tasks.
Comparison of Transformer and ConvNet: A significant characteristic of Transformers compared to ConvNets is that they operate differently on spatial (temporal) dimensions.
-
ConvNet: Convolution kernels perform convolution operations in the spatial dimension, thus merging information from features at different spatial locations through convolution (learnable) operations, and only merging within local areas. -
Transformer: Features at different spatial (temporal) locations merge information through Attention (non-learnable) operations, merging globally.
The non-learnable strategy of Transformers during feature merging makes it easy to extend the model by adding additional features.
3.2 Prompt-based Fine-tuning in NLP
-
Prefix-Tuning -
Prompt-Tuning -
P-Tuning -
P-Tuning-v2
3.3 Prompt-based Fine-tuning in CV
3.3.1 Classification
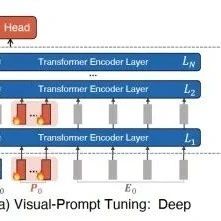
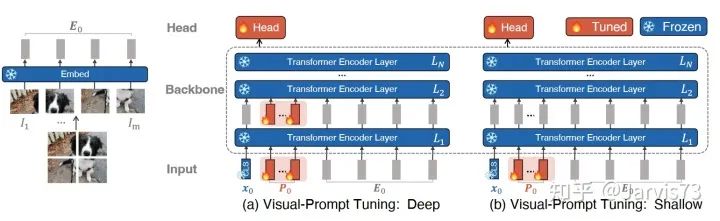
Visual Prompt Tuning [8]
-
VPT-Shallow
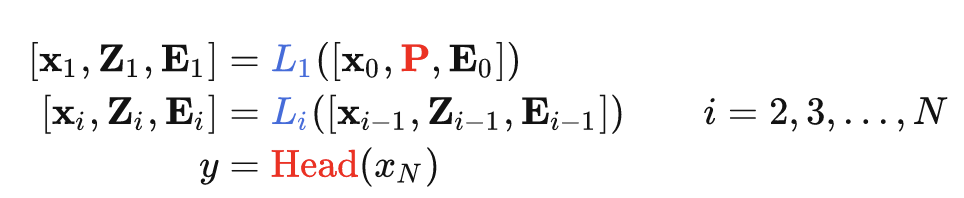
-
VPT-Deep
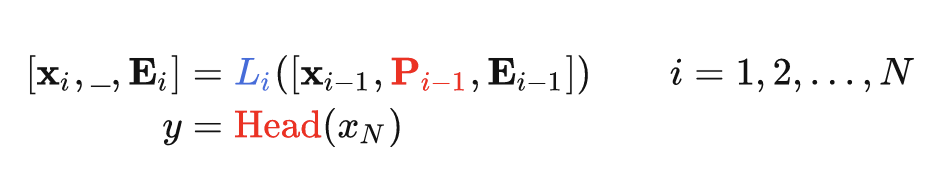
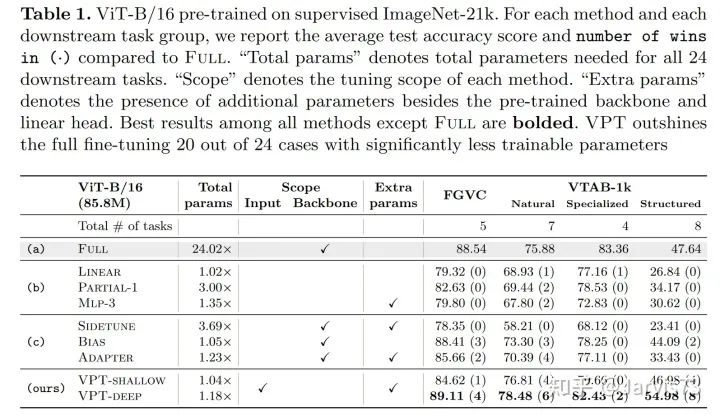
3.3.2 Continual Learning
Learning to Prompt for Continual Learning [9]
Introduce a prompt pool, for each input, take the N prompts closest to it from the pool and add them to the image tokens. The distance measurement of the input and prompts is obtained by calculating the distance between the input feature and each prompt’s key, which are optimized together with the classification target through gradients.
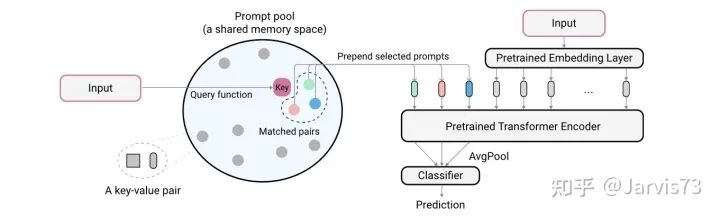
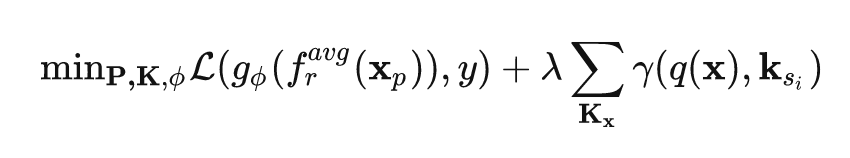
Note: Finally, use prompts for classification.
3.3.3 Multimodal Models
Vision-Language Model: Context Optimization (CoOp) [10]
Pre-trained models for multimodal learning, such as CLIP, align the feature spaces of text and images through contrastive learning.
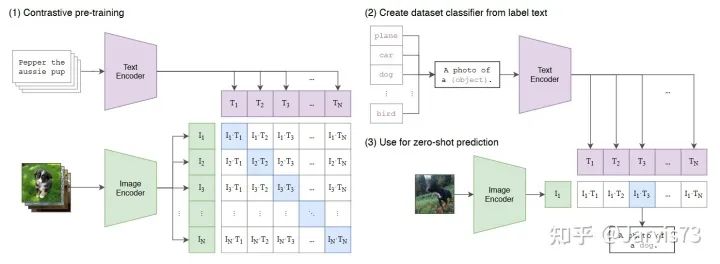
Choosing different text prompts has a significant impact on accuracy.

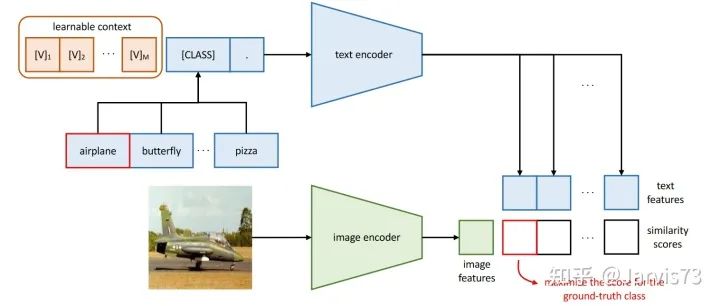
Replace manually set prompts with learnable prompts:
-
[CLASS] at the end: -
[CLASS] in the middle:
Prompts can be shared between different classes or use different prompts for each class (more effective for fine-grained classification tasks).
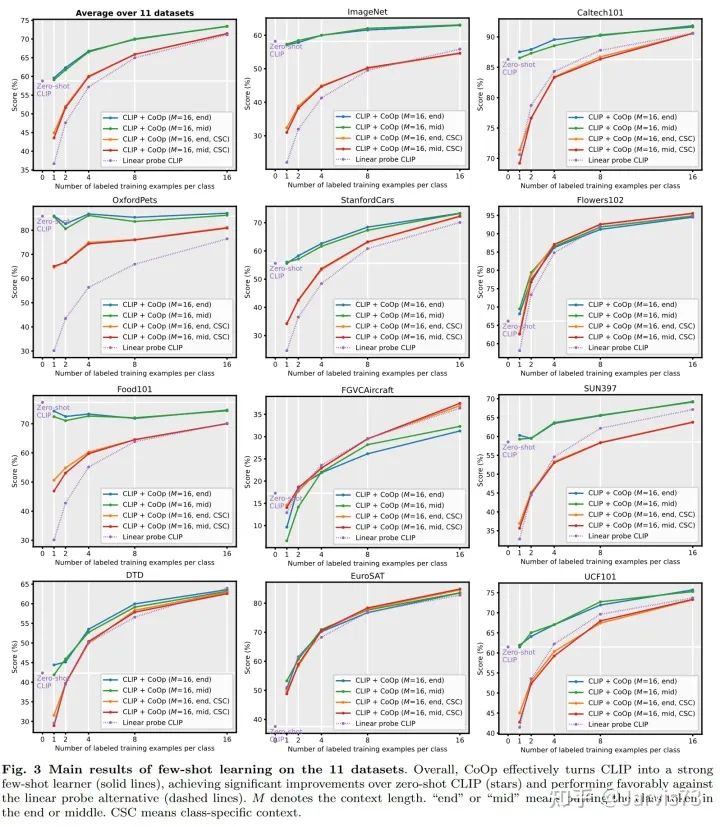
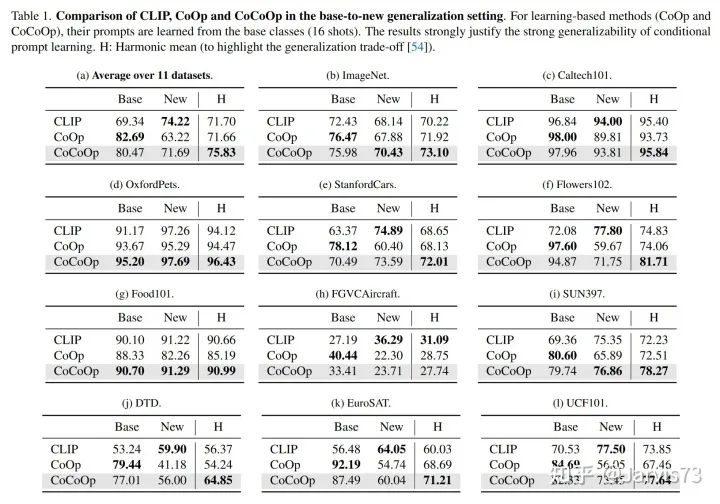
Conditional Prompt Learning for Vision-Language Models [11]
CoOp performs poorly when generalizing to new categories.
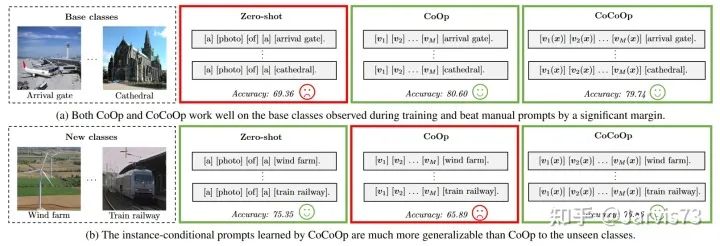
Thus, design prompts to be instance-conditional.
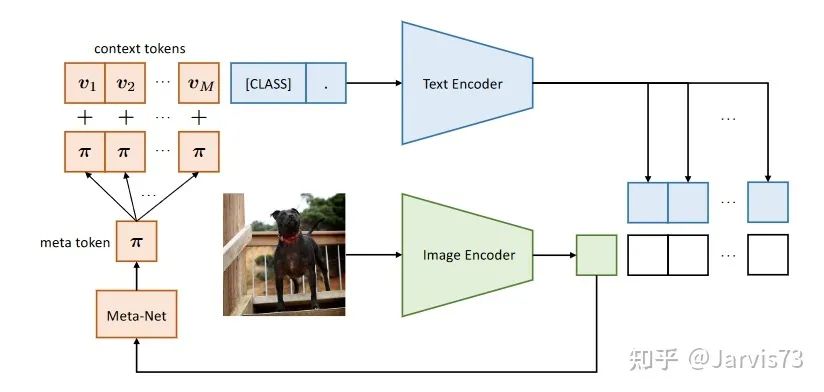
Add features related to the current image to the prompt to improve generalization performance. Specifically, first use the Image Encoder to calculate the feature of the current image, and then map the feature to the prompt’s feature space through a Meta-Net, adding it to the prompt.
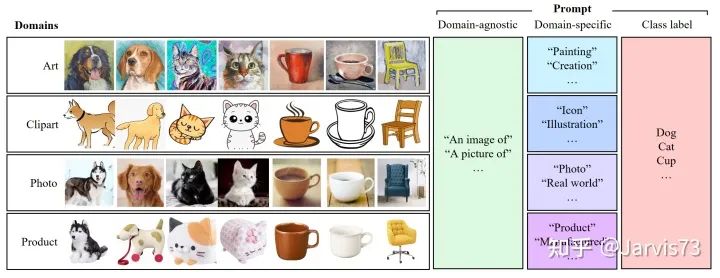
3.3.4 Domain Adaptation
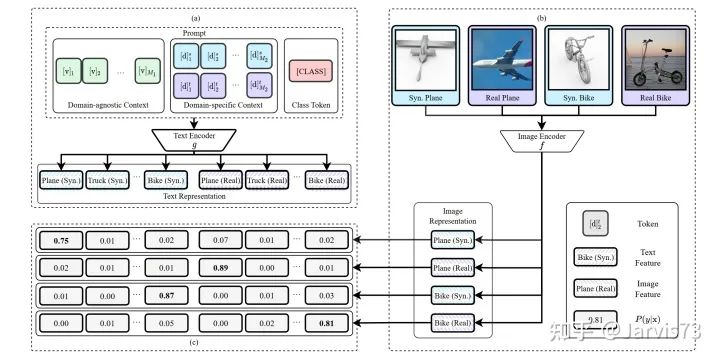
Domain Adaptation via Prompt Learning [12]
Use prompts to identify domain information.
Decouple the class and domain representations in the representation through contrastive learning.
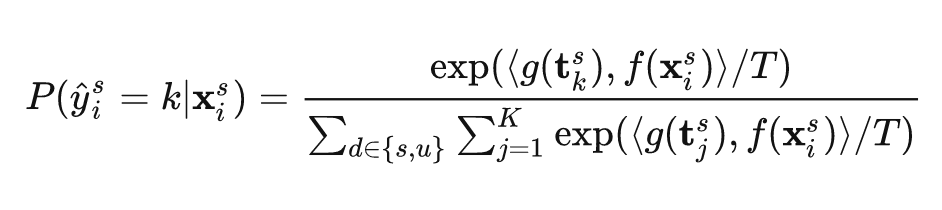
References
-
^Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig. In arXiv 2021 https://arxiv.org/abs/2107.13586
-
^How transferable are features in deep neural networks? Jason Yosinski, Jeff Clune, Yoshua Bengio, Hod Lipson. In NeruIPS 2014 https://proceedings.neurips.cc/paper/2014/hash/375c71349b295fbe2dcdca9206f20a06-Abstract.html
-
^Masked autoencoders are scalable vision learners. Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick. In arXiv 2021 https://arxiv.org/abs/2111.06377
-
^Side-tuning: a baseline for network adaptation via additive side networks. Jeffrey O. Zhang, Alexander Sax, Amir Zamir, Leonidas Guibas, Jitendra Malik. In ECCV 2020 https://link.springer.com/chapter/10.1007/978-3-030-58580-8_41
-
^Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. Elad Ben Zaken, Shauli Ravfogel, Yoav Goldberg. In ACL 2022 https://arxiv.org/abs/2106.10199
-
^TinyTL: Reduce memory, not parameters for efficient on-device learning. Han Cai, Chuang Gan, Ligeng Zhu, Song Han. In NeurIPS 2020 https://proceedings.neurips.cc/paper/2020/hash/81f7acabd411274fcf65ce2070ed568a-Abstract.html
-
^Parameter-efficient transfer learning for nlp. Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly. In ICML 2019 http://proceedings.mlr.press/v97/houlsby19a.html
-
^Visual Prompt Tuning. Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, Ser-Nam Lim. In arXiv 2022 https://arxiv.org/abs/2203.12119
-
^Learning to Prompt for Continual Learning. Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, Tomas Pfister. In CVPR 2022 https://arxiv.org/abs/2112.08654
-
^Learning to Prompt for Vision-Language Models. Kaiyang Zhou, Jingkang Yang, Chen Change Loy, Ziwei Liu. In arXiv 2021 https://arxiv.org/abs/2109.01134
-
^Conditional Prompt Learning for Vision-Language Models. Kaiyang Zhou, Jingkang Yang, Chen Change Loy, Ziwei Liu. In CVPR 2022 https://arxiv.org/abs/2203.05557
-
^Domain Adaptation via Prompt Learning. Chunjiang Ge, Rui Huang, Mixue Xie, Zihang Lai, Shiji Song, Shuang Li, Gao Huang. In arXiv 2022 https://arxiv.org/abs/2202.06687
Reply “CVPR2023” in the public account background to get the latest paper classification resources
Jishi Essentials
Jishi Perspective Dynamics: “Drone + AI” photovoltaic intelligent inspection, hard-core strength meets intelligent brain!|”AI Guardian” goes live, Jishi Perspective protects the safety of Longda Food Factory!|Light up the maritime beacon, Jishi Perspective provides safety management for maritime transport crew!
CVPR2023: Latest 125 papers from CVPR’23 classified by direction|Detection, segmentation, face, video processing, medical imaging, neural network structure, few-shot learning, etc.
Datasets: Summary of open-source dataset resources for autonomous driving|Summary of open-source dataset resources for medical imaging|Summary of open-source dataset resources for satellite images

Click to read the original text to enter the CV community
Gain more technical insights