
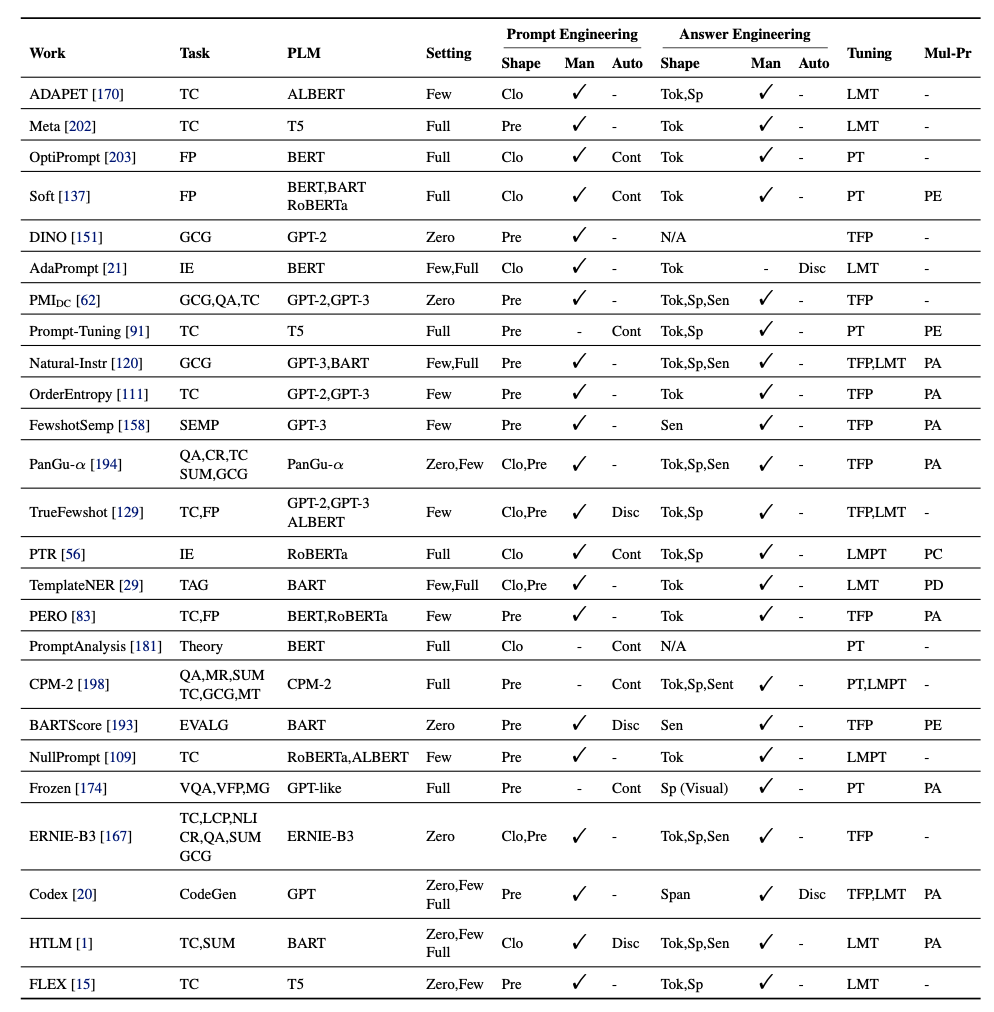
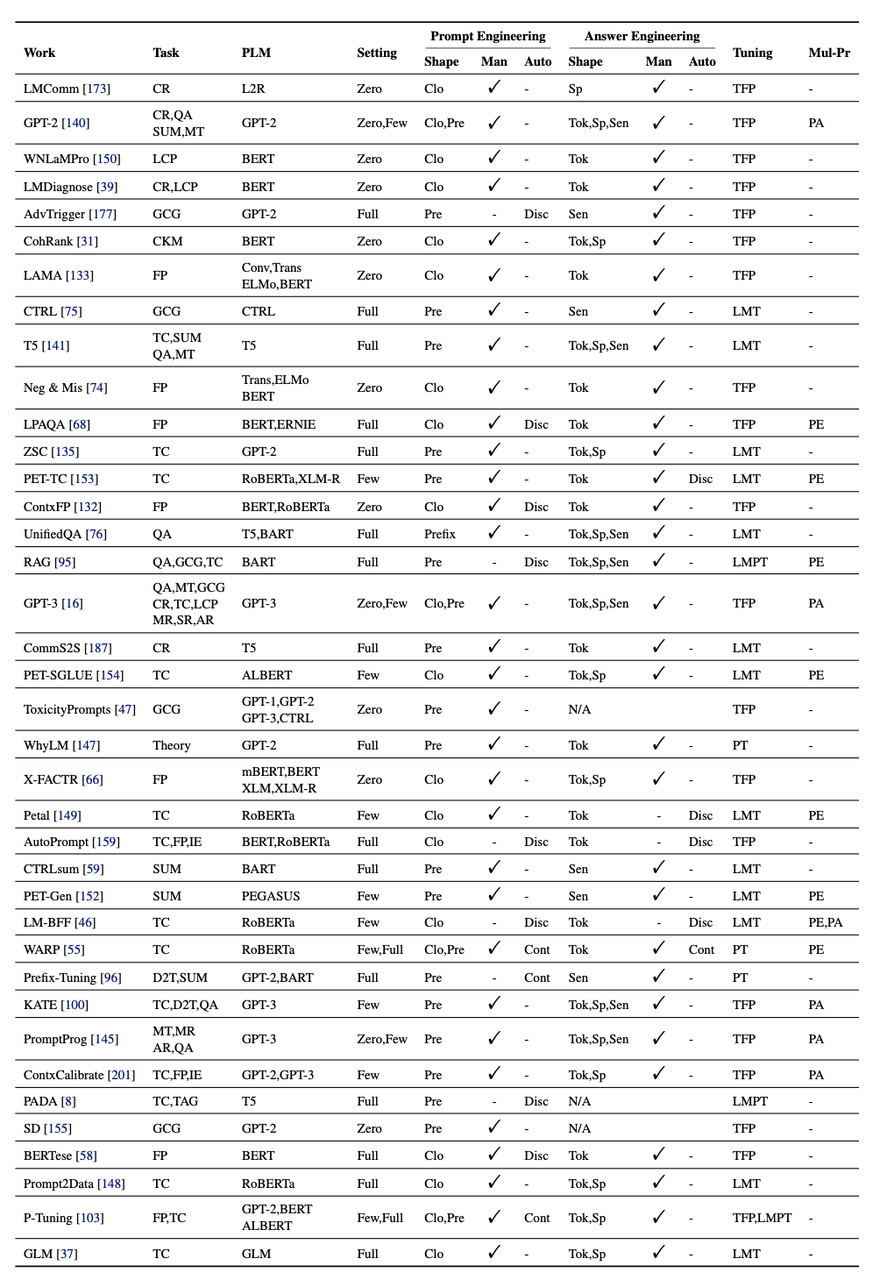
Abbreviation Explanation:
task column
CR: Commonsense Reasoning
QA: Question Answering
SUM: Summarization
MT: Machine Translation
LCP: Linguistic Capacity Probing
GCG: General Conditional Generation
CKM: Commonsense Knowledge Mining
FP: Fact Probing
TC: Text Classification
MR: Mathematical Reasoning
SR: Symbolic Reasoning
AR: Analogical Reasoning
Theory: Theoretical Analysis
IE: Information Extraction
D2T: Data-to-text
TAG: Sequence Tagging
SEMP: Semantic Parsing
EVALG: Evaluation of Text Generation
VQA: Visual Question Answering
VFP: Visual Fact Probing
MG: Multimodal Grounding
CodeGen: Code Generation
prompt engineering shape column
Clo: Cloze
Pre: Prefix
answer engineering shape column
Tok: token-level
Sp: span-level
Sent: sentence-level / document-level
tuning column
TFP: tuning-free prompting
LMT: fixed-prompt LM tuning
PT: fixed-LM prompt tuning
LMPT: prompt+LM tuning
mul-pr column
PA: prompt augmentation
PE: prompt ensembling
PC: prompt composition
PD: prompt decomposition
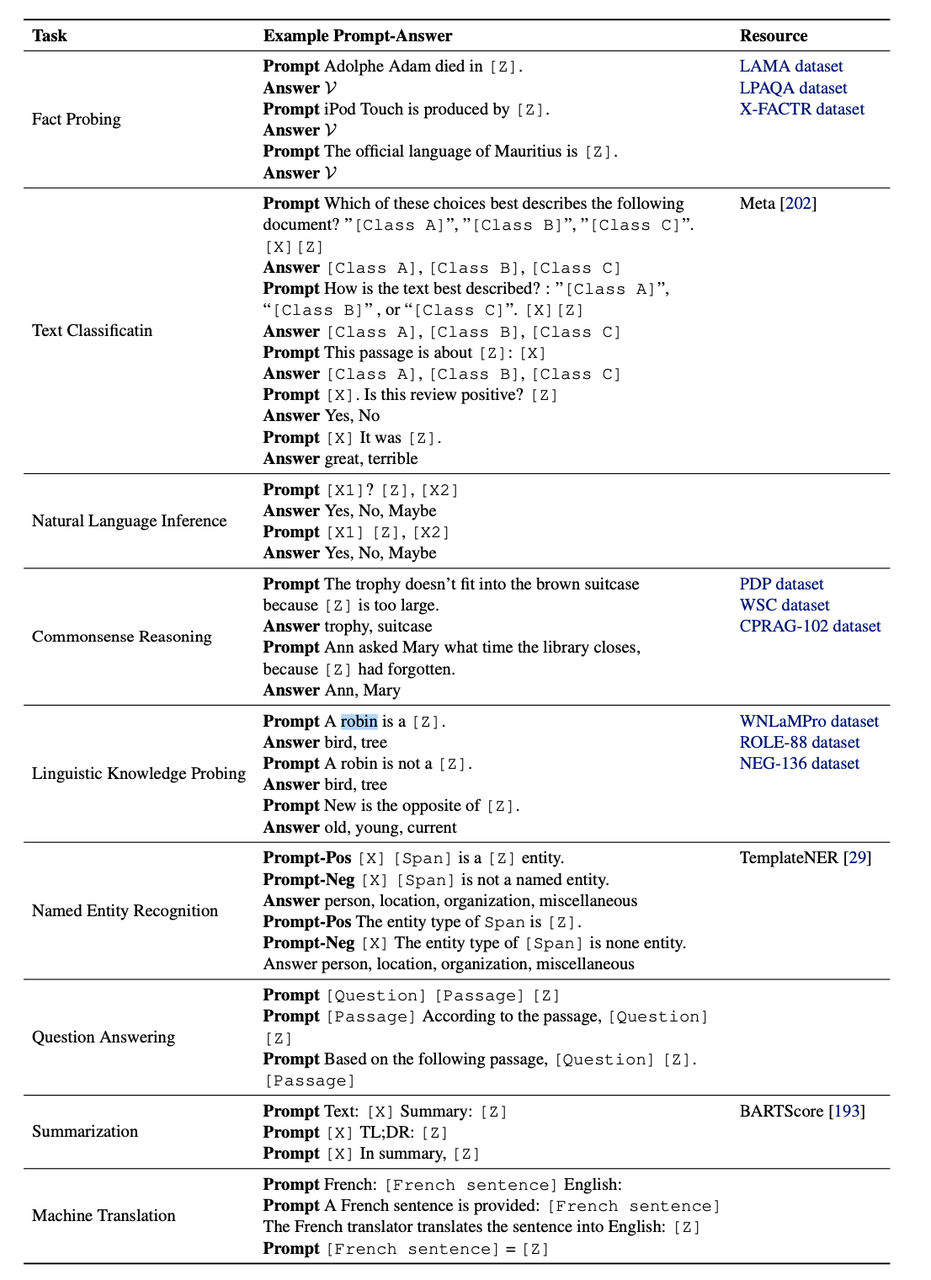
7.2 Common Templates
8. Challenges in Template Learning
8.1 Template Design Aspects
1. Currently, template learning is mainly applied in classification and generation tasks, while its application in other tasks (such as information extraction and text analysis) is relatively rare. The reason lies in the lack of intuitive template design for these other tasks. Future developments may require transforming these tasks into formats suitable for classification and generation tasks or designing more powerful answer engines.
2. In many NLP tasks, the input may contain various structured information, such as trees, graphs, tables, etc. Effectively representing this information in template engines and answer engines is a significant challenge. The current approach mainly encodes some vocabulary into templates, but there has been no attempt for more complex structures.
3. The performance of template learning models primarily depends on the choice of templates and the design of answer engines. The mainstream practice is to first establish the answer engine and then select templates. Optimizing both template selection and answer design simultaneously is also a major challenge.
8.2 Aspects of Answer Engines
1. For classification tasks, choosing an answer space reasonably when there are too many categories is a particularly challenging issue.
2. When the answers for classification tasks are multi-byte (multi-token), effectively encoding them is also a challenging problem.
3. For generation tasks, there are often multiple answers. Guiding the learning process to learn multiple answers is still a huge problem.
8.3 Training Strategy Aspects
Currently, there is no systematic solution for selecting appropriate training strategies for different tasks, and there is a lack of systematic explanations on how each strategy affects model results.
8.4 Multi-Template Learning Aspects
1. Template fusion, as an effective method to improve performance, generally shows better results with more fused templates. However, the complexity also increases. Finding effective ways to reduce complexity through distillation and other methods has not yet been researched.
2. When using template enhancement, it is often limited by the length of the input text. Therefore, how to extract more effective enhanced text and how to rank these texts is also an important research direction.
9. References
[1] Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing:https://arxiv.org/pdf/2107.13586.pdf
[2] Language Models as Knowledge Bases?:https://arxiv.org/pdf/1909.01066.pdf
[3] Template-Based Named Entity Recognition Using BART:https://arxiv.org/pdf/2106.01760.pdf
[4] Prefix-Tuning: Optimizing Continuous Prompts for Generation:https://arxiv.org/pdf/2101.00190.pdf
[5] The Power of Scale for Parameter-Efficient Prompt Tuning:https://arxiv.org/pdf/2104.08691.pdf
[6] How Can We Know What Language Models Know?:https://arxiv.org/pdf/1911.12543.pdf
[7] BARTScore: Evaluating Generated Text as Text Generation:https://arxiv.org/pdf/2106.11520.pdf
[8] BERTese: Learning to Speak to BERT:https://arxiv.org/pdf/2103.05327.pdf
[9]Universal Adversarial Triggers for Attacking and Analyzing NLP:https://arxiv.org/pdf/1908.07125.pdf
[10] AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts:https://arxiv.org/pdf/2010.15980.pdf
[11] Making Pre-trained Language Models Better Few-shot Learners:https://arxiv.org/pdf/2012.15723.pdf
[12] PADA: A Prompt-based Autoregressive Approach for Adaptation to Unseen Domains:https://arxiv.org/pdf/2102.12206.pdf
[13] Commonsense Knowledge Mining from Pretrained Models:https://arxiv.org/pdf/1909.00505.pdf
[14] Multimodal Few-Shot Learning with Frozen Language Models:https://arxiv.org/pdf/2106.13884.pdf
[15] Factual Probing Is [MASK]: Learning vs. Learning to Recall:https://arxiv.org/pdf/2104.05240.pdf
[16]Learning How to Ask: Querying LMs with Mixtures of Soft Prompts:https://arxiv.org/pdf/2104.06599.pdf
[17]GPT Understands, Too:https://arxiv.org/pdf/2103.10385.pdf
[18]PTR: Prompt Tuning with Rules for Text Classification:https://arxiv.org/pdf/2105.11259.pdf
[19] How Can We Know When Language Models Know? On the Calibration of Language Models for Question Answering:https://arxiv.org/pdf/2012.00955.pdf
[20] Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference:https://arxiv.org/pdf/2001.07676.pdf
[21] Automatically Identifying Words That Can Serve as Labels for Few-Shot Text Classification:https://arxiv.org/pdf/2010.13641.pdf
[22] Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity:https://arxiv.org/pdf/2104.08786.pdf
10. Join Us
We are from the Lark Business Applications R&D Department of ByteDance. Currently, we have established offices in Beijing, Shenzhen, Shanghai, Wuhan, Hangzhou, Chengdu, Guangzhou, and Sanya. Our focus is mainly on enterprise experience management software, including Lark OKR, Lark Performance, Lark Recruitment, Lark HR systems, as well as Lark Approval, OA, Legal, Finance, Procurement, Travel, and Reimbursement systems. We welcome everyone to join us.
