Follow the official account “ML_NLP“
Set as “Starred“, delivering heavy content promptly!

Introduction
With the rapid development of social networks, the ways people express themselves on platforms have become increasingly rich, such as expressing emotions and opinions through images, text, and videos. Analyzing the emotions in multimodal data (this article refers to sound, images, and text, excluding sensor data) presents both opportunities and challenges in the current field of sentiment analysis.
On one hand, traditional sentiment analysis has focused on a single modality. For instance, text sentiment analysis aims to analyze, mine, and infer the emotions contained within the text. Now, there is a need to process and analyze data from multiple modalities, which poses a greater challenge for researchers. On the other hand, multimodal data contains more information compared to unimodal data, and multiple modalities can complement each other. For example, in identifying whether a tweet is ironic, “What a beautiful day!” If viewed only from the text, it is not ironic. However, if accompanied by an image of a cloudy day, it may indeed be ironic. The complementary information from different modalities can help machines better understand emotions. From a human-computer interaction perspective, multimodal sentiment analysis allows machines to interact with humans in a more natural manner. Machines can understand user emotions based on people’s expressions and gestures in images, tones in voices, and recognized natural language, and respond accordingly.
In summary, the development of multimodal sentiment analysis technology stems from the demands of real life, where people express emotions in a more natural way, and technology should have the capability for intelligent understanding and analysis. Although multimodal data contains more information, how to fuse multimodal data to enhance effectiveness rather than counteract is a key challenge. How to utilize the alignment information between different modalities and model the associations between them, such as how people think of cats when they hear “Meow”, are all current points of interest in the field of multimodal sentiment analysis. To better introduce relevant research in the field of multimodal sentiment analysis, this article organizes the related tasks in multimodal sentiment analysis and summarizes commonly used datasets and corresponding methods.
Overview of Related Tasks
This article organizes related research tasks through different modality combinations (Text + Image: Text + Image, Video: Text + Image + Audio). There are few specifically constructed datasets for the combination of Text + Audio, generally constructed through ASR on speech or using Text + Image + Audio to create Text + Audio datasets. For Text + Audio, there is more research in the speech direction, so this article does not cover it. As shown in Table 1, sentiment analysis tasks aimed at images and text include sentiment classification tasks, aspect-level sentiment classification tasks, and irony detection tasks. Sentiment analysis tasks aimed at videos include sentiment classification tasks for comment videos, sentiment classification tasks for news videos, sentiment classification tasks for dialogue videos, and irony detection tasks for dialogue videos. This article summarizes the relevant datasets and methods corresponding to the tasks, detailed in the third section.
Table 1 Overview of Multimodal Sentiment Analysis Tasks
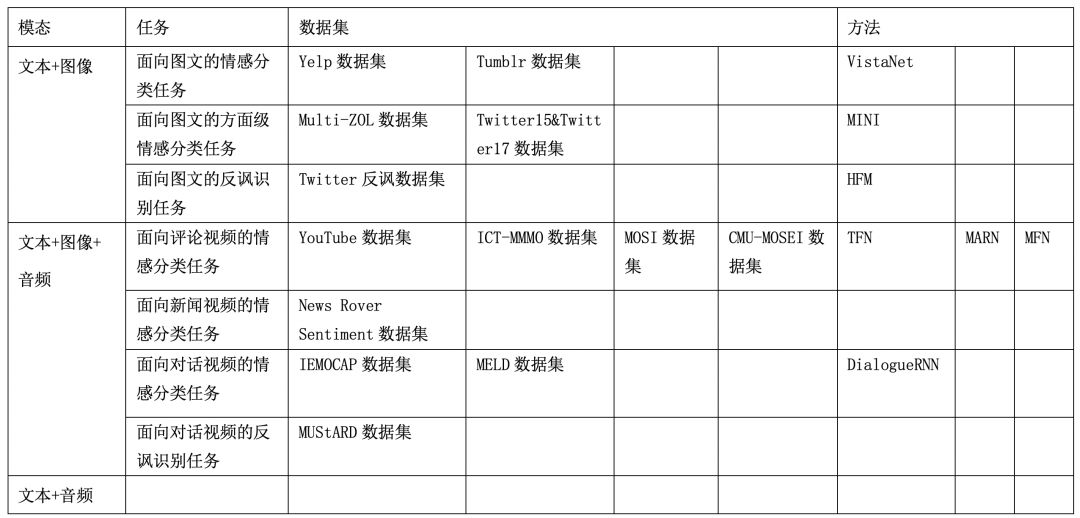
Datasets and Methods
This article summarizes 13 publicly available datasets, including 8 video datasets and 5 image-text datasets. It also summarizes relevant research methods corresponding to five tasks: sentiment classification tasks aimed at images and text, aspect-level sentiment classification tasks, irony detection tasks aimed at images and text, sentiment classification tasks for comment videos, and sentiment classification tasks for dialogue videos.
Sentiment Classification Tasks for Images and Text
Datasets
The Yelp dataset comes from the Yelp.com review site, collecting reviews about restaurants and food from five cities: Boston, Chicago, Los Angeles, New York, and San Francisco. There are a total of 44,305 reviews and 244,569 images (each review has multiple images), with an average of 13 sentences and 230 words per review. The sentiment annotation of the dataset assigns scores of 1, 2, 3, 4, and 5 to the sentiment tendency of each review.
The Tumblr dataset is a multimodal emotion dataset collected from Tumblr. Tumblr is a microblogging service where users post multimedia content that usually includes images, text, and tags. The dataset is constructed by searching for tweets corresponding to fifteen selected emotions and only selecting those that contain both text and images, followed by data processing to remove content that originally contained corresponding emotional words and tweets that are primarily not in English. The entire dataset contains 256,897 multimodal tweets, with emotional annotations including fifteen emotions such as happiness, sadness, and disgust.
Methods
Combining the characteristics of the Yelp dataset, [1] proposed that “images do not independently express emotions but serve as auxiliary parts to highlight significant content in the text.” VistaNet uses images to guide text attention to determine the importance of different sentences for document sentiment classification.
As shown in Figure 1, VistaNet has a three-layer structure: word encoding layer, sentence encoding layer, and classification layer. The word encoding layer encodes the words in a sentence, and then obtains the sentence representation through soft-attention. The sentence encoding layer encodes the sentence representation obtained from the previous layer and obtains the document representation through the visual attention mechanism. The document representation serves as input to the classification layer, which outputs the classification result. Structurally, VistaNet is similar to the Hierarchical Attention Network, both used for document-level sentiment classification, both having a three-layer structure, and the first two layers being GRU Encoder + Attention structures. The difference is that VistaNet uses a visual attention mechanism.
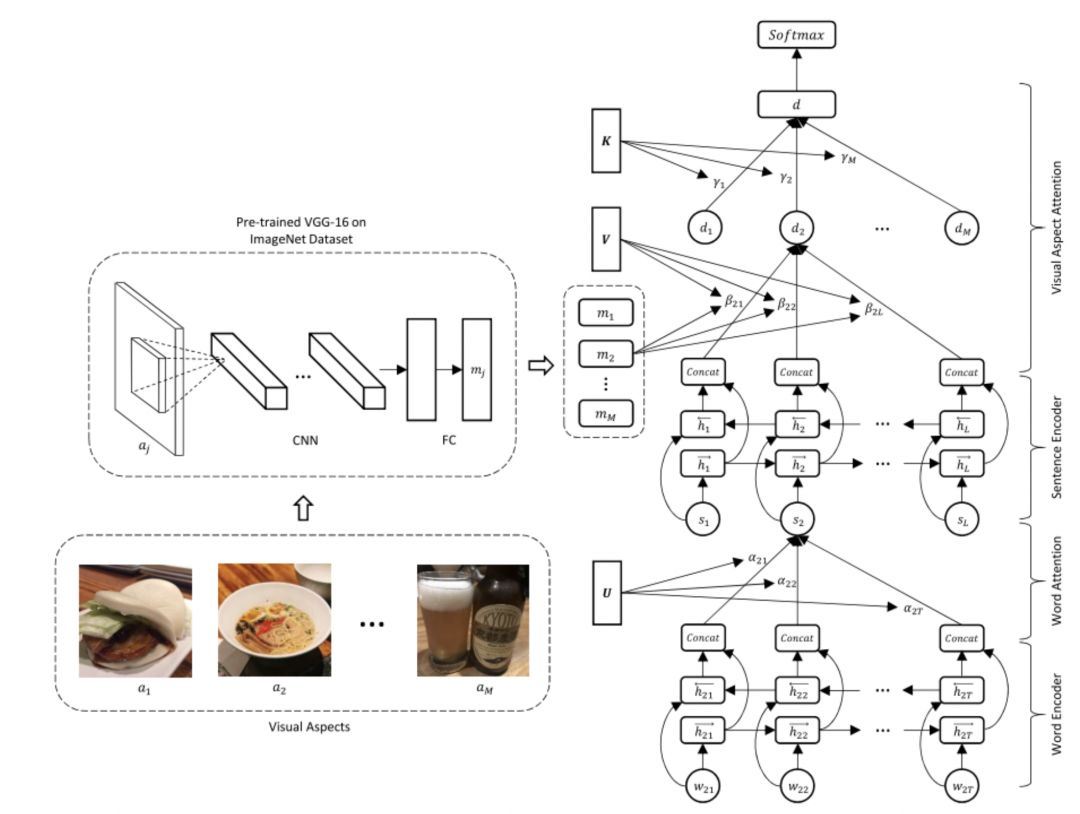
Figure 1 VistaNet Model Architecture
Aspect-Level Sentiment Classification Tasks for Images and Text
Datasets
The Multi-ZOL dataset collects IT information and reviews about mobile phones from the commercial portal site ZOL.com. The original data includes 12,587 reviews (7,359 unimodal reviews and 5,288 multimodal reviews), covering 114 brands and 1,318 mobile phones. Among the 5,288 multimodal reviews, they constitute the Multi-ZOL dataset. In this dataset, each multimodal data contains a text content, an image set, and at least one but no more than six evaluation aspects. These six aspects are cost-performance ratio, performance configuration, battery life, appearance and feel, shooting effect, and screen. A total of 28,469 aspects are obtained. For each aspect, there is a sentiment score ranging from 1 to 10.
Twitter-15 and Twitter-17 are multimodal datasets containing text and corresponding images, with annotations for target entities and their expressed sentiment tendencies in the text-image pairs. The total data scale is Twitter-15 (3,179/1,122/1,037) tweets with images, Twitter-17 (3,562/1,176/1,234) tweets with images, with sentiment annotations in three categories.
Methods
The aspect-level sentiment classification task studies the sentiment polarity of a given aspect (Aspect) in multimodal documents. An aspect may consist of multiple words, for example, “Eating environment”, and the information contained in the aspect itself has important guiding significance for extracting text and image information. For the Multi-ZOL dataset, [2] proposed the Multi-Interactive Memory Network (MIMN), as shown in Figure 2. The model uses an Aspect-guided attention mechanism to guide the model in generating attention vectors for text and images. To capture the interaction information between modalities and within single modalities, the model uses a Multi-interactive attention mechanism.
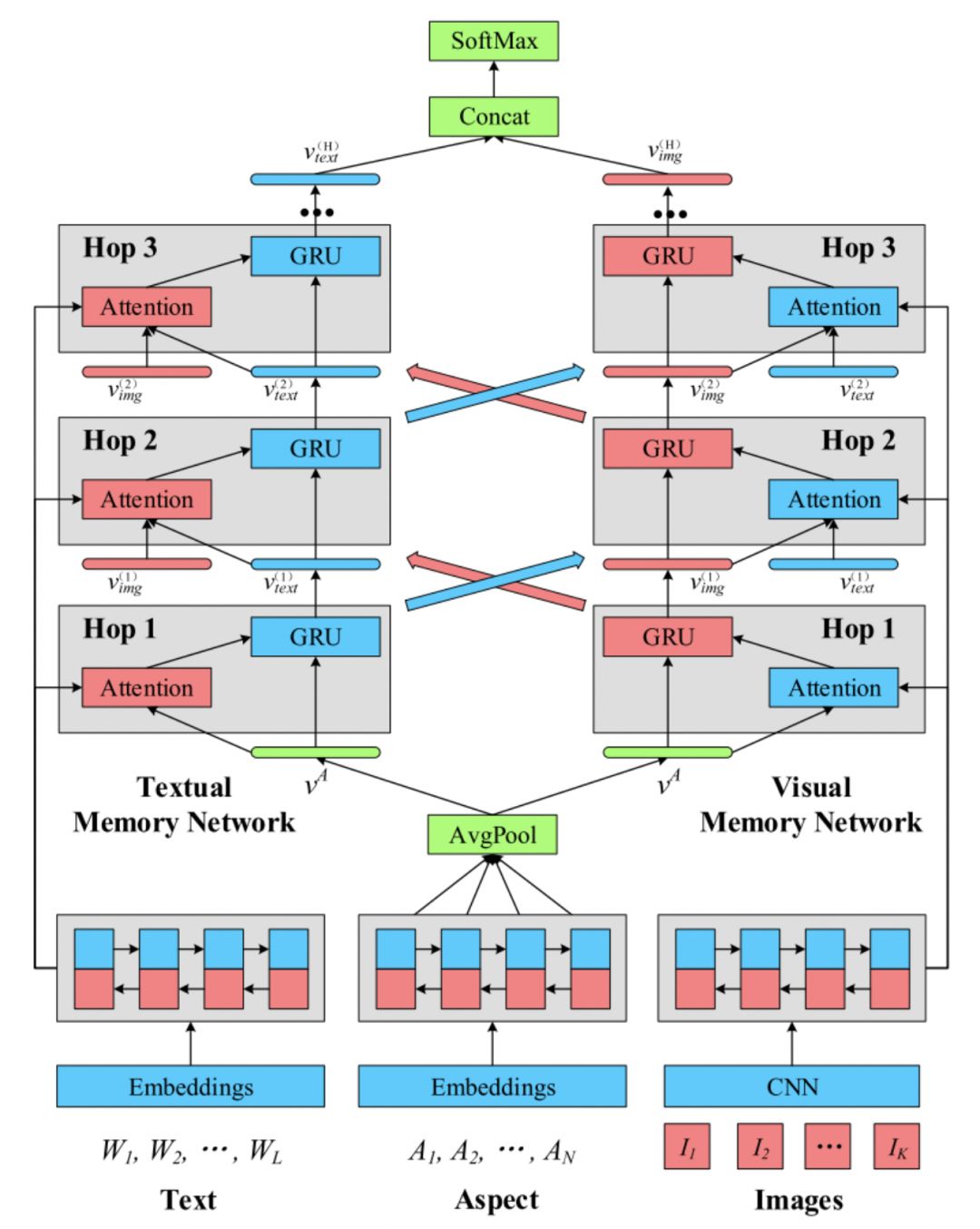
Figure 2 MIMN Model Architecture
Irony Detection Tasks for Images and Text
The goal of the irony detection task is to determine whether a document contains ironic expressions. [3] proposed a Hierarchical Fusion Model to model the image and text information for irony detection.
Datasets
The Twitter irony dataset is constructed from the Twitter platform, collecting English tweets containing images and specific topic tags (e.g., #sarcasm, etc.) as positive examples, and collecting tweets with images but without such tags as negative examples. The dataset is further organized by removing tweets containing conventional vocabulary such as sarcasm, irony, and satire. Tweets containing URLs are also removed to avoid introducing additional information. Additionally, words that frequently co-occur with ironic tweets, such as Jokes and Humor, are removed. The dataset is divided into training, development, and test sets, with 19,816, 2,410, and 2,409 tweets with images, respectively. The annotation for this dataset is a binary classification of sarcasm/not sarcasm.
Methods
The HFM (Hierarchical Fusion Model) builds upon the dual modalities of text and image, adding an image attribute modality (Image attribute), which consists of several words describing the components of the image. As shown in Figure 3, the image contains attributes like “Fork”, “Knife”, “Meat”, etc. The authors believe that image attributes can connect the content of images and text, serving as a “bridge”.
According to functionality, HFM is divided into three levels: encoding layer, fusion layer, and classification layer, where the fusion layer can be further divided into representation fusion layer and modality fusion layer. In the encoding layer, HFM first encodes the information from the three modalities to obtain the raw feature vectors (Raw vectors) for each modality, which is a collection of vector representations of all elements in each modality. After averaging or weighted summation of the raw feature vectors, a single vector representation (Guidance vector) for each modality is obtained. After the representation fusion layer processes the raw feature vectors and single vector representations, it obtains the reconstructed feature vector representation (Reconstructed feature vector) that fuses information from other modalities for each modality. Finally, the reconstructed feature vectors from the three modalities are processed through the modality fusion layer to obtain the final fused vector (Fused vector), which serves as input to the classification layer.
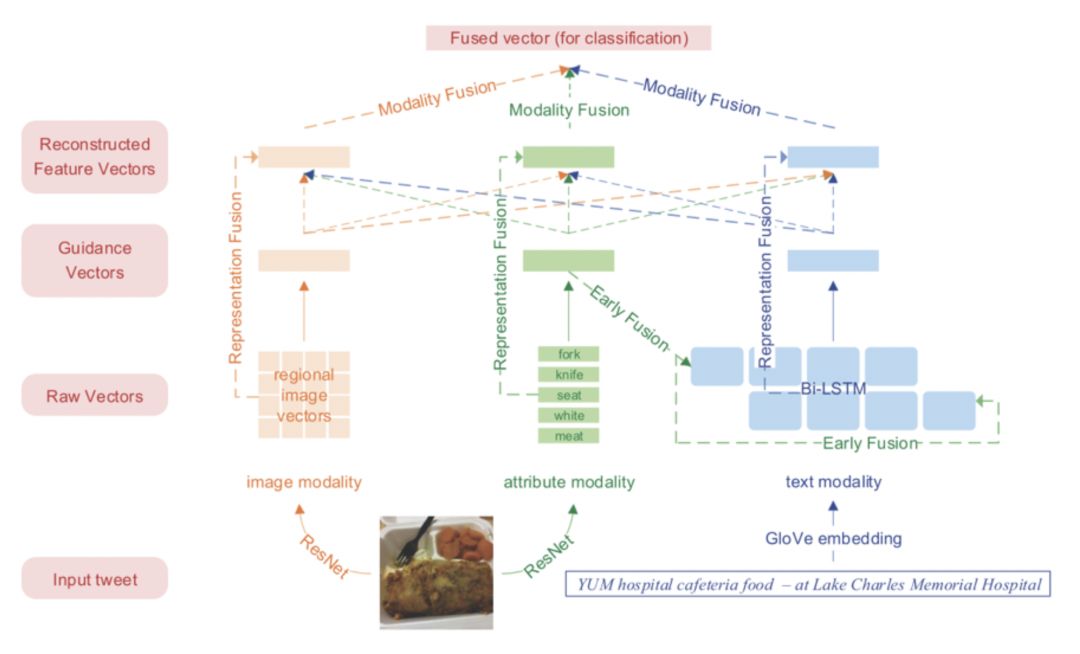
Figure 3 HFN Model Architecture
Sentiment Classification Tasks for Comment Videos
Datasets
The YouTube dataset collects 47 videos from YouTube, which are not based on a single theme but cover a range of topics such as toothpaste, camera reviews, baby products, etc. The videos feature a single speaker addressing the camera, with a total of 20 female and 27 male speakers, aged approximately 14-60, from diverse racial backgrounds. The length of the videos ranges from 2 to 5 minutes, and all video sequences have been normalized to a length of 30 seconds. The annotations for the dataset were made by three annotators watching the videos in random order, labeling them as positive, negative, or neutral. It is important to note that the annotations are not based on viewers’ feelings towards the videos, but rather on the emotional tendencies of the speakers in the videos. Out of the 47 videos, 13 were labeled as positive, 22 as neutral, and 12 as negative.
The ICT-MMMO dataset collects videos of movie reviews from social media sites. The dataset contains 370 multimodal review videos, where a person speaks directly to the camera, expressing their opinions about movies or stating facts related to specific films. All speakers express their views in English, and the length of the videos ranges from 1 to 3 minutes. Overall, there are 370 movie review videos, of which 308 are from YouTube and 62 are entirely negative review videos from ExpoTV, including 228 positive reviews, 23 neutral reviews, and 119 negative reviews. It should be noted that this dataset does not annotate viewers’ feelings about the videos but rather the emotional tendencies of the speakers in the videos.
The MOSI dataset collects vlogs primarily about movie reviews from YouTube. The length of the videos ranges from 2 to 5 minutes, and a total of 93 videos were randomly collected, featuring 89 different speakers, including 41 females and 48 males, most of whom are aged between 20 and 30 and come from diverse racial backgrounds. The annotations for these videos were made by five annotators from the Amazon Mechanical Turk platform, with the average value being annotated into seven categories of sentiment from -3 to +3. The sentiment annotations for this dataset reflect the emotional tendencies of the commentators in the videos, not the viewers’ feelings.
The CMU-MOSEI dataset collects data from YouTube monologue videos, removing those that contain too many characters. The final dataset contains 3,228 videos, 23,453 sentences, 1,000 speakers, and 250 topics, with a total duration of 65 hours. The dataset includes both sentiment and emotion annotations. Sentiment annotations are classified into seven categories for each sentence, and the authors also provide annotations for 2/5/7 categories. Emotion annotations include six aspects: happiness, sadness, anger, fear, disgust, and surprise.
Methods
Comment video files contain text (subtitles), images, and voice information, so the sentiment classification task for comment videos needs to process these three modalities. Videos can be viewed as images arranged in a time sequence, which adds the temporal attribute compared to a single image, thus RNN and its variants can be used for encoding. The following will introduce three works on multimodal sentiment classification models for comment videos, namely the Tensor Fusion Network from EMNLP 2017 [4], the Multi-attention Recurrent Network from AAAI 2018 [5], and the Memory Fusion Network [6].
TFN (Tensor Fusion Network)
Zadeh and his team [4] proposed a multimodal fusion method based on tensor outer product, which is also the source of the TFN name. In the encoding phase, TFN uses an LSTM + 2-layer fully connected network to encode the text modality input, and a 3-layer DNN network to encode the voice and video modalities’ inputs. In the modality fusion phase, the outer product of the output vectors encoded from the three modalities is taken to obtain a multimodal representation vector containing single modality information, bimodal, and trimodal fusion information for the next decision-making operation.
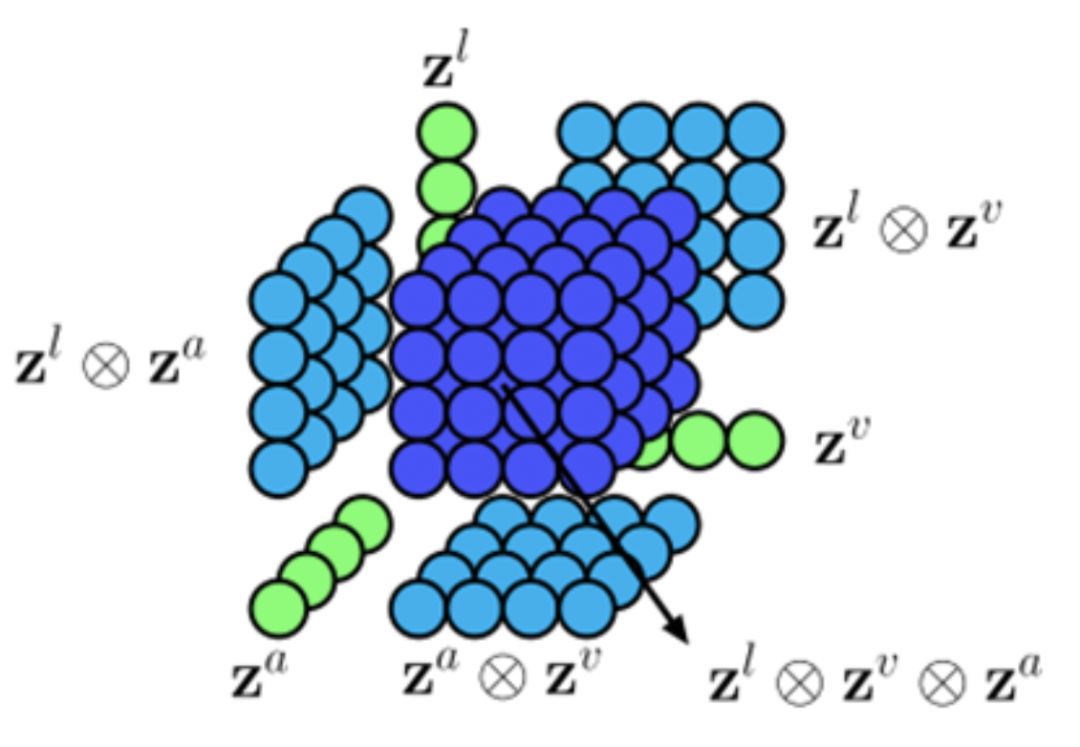
Figure 4 TFN Model Architecture
MARN (Multi-attention Recurrent Network)
MARN is based on the hypothesis that “there are multiple types of information interaction between modalities,” a hypothesis that has been confirmed in cognitive science. Based on this, MARN proposes to use a multi-level attention mechanism to extract different modal interaction information. The model architecture is shown in Figure 5. In the encoding phase, the authors propose a “Long-short Term Hybrid Memory” based on LSTM, adding processing for multimodal representations, while combining modality fusion and encoding. Since modality fusion is required at every moment, the sequences of the three modalities must be equal in length, so modality alignment is needed before encoding.

Figure 5 MARN Model Architecture
MFN (Memory Fusion Network)
While MARN considers various possible distributions of attention weights, MFN considers the range of attention processing. Like MARN, MFN combines modality fusion with encoding; however, during the encoding process, the modalities are independent of each other. Since LSTM is used, there is no shared mixed vector added to the calculation. Instead, MFN uses “Delta-memory attention” and “Multi-View Gated Memory” to capture temporal and modal interactions simultaneously, preserving the multimodal interaction information from the previous moment. Figure 6 shows the processing of MFN at time t.
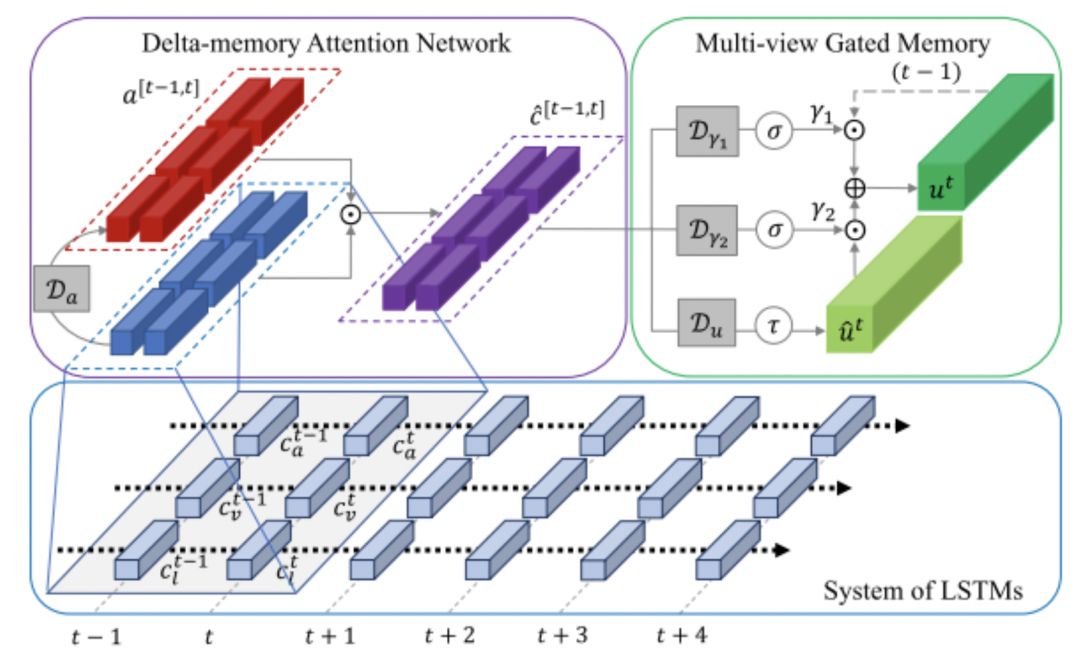
Figure 6 MFN Model Architecture
Sentiment Classification Tasks for Dialogue Videos
Datasets
The MELD dataset is derived from the EmotionLines dataset, which is a pure text dialogue dataset from the classic TV show Friends. The MELD dataset is a multimodal dataset containing video, text, and audio, ultimately comprising 13,709 segments, each with annotations for seven emotions, including fear, as well as sentiment annotations in positive, negative, and neutral categories.
The IEMOCAP dataset is quite special; it is neither collected from existing user-uploaded videos on platforms like YouTube nor from well-known TV shows like Friends. Instead, it is a multimodal dataset obtained by recording performances of 10 actors around specific themes. The dataset contains videos of conversations performed by five male and five female professional actors, with a total of 4,787 improvised conversations and 5,255 scripted conversations, each averaging 4.5 seconds in duration, totaling 11 hours. The final data annotations include ten categories of emotions, such as fear and sadness.
Methods
The goal of dialogue sentiment classification is to determine the sentiment polarity of each dialogue segment, considering speaker information and the context of the dialogue, which is significantly influenced by the previous dialogue content. DialogueRNN [7] uses three GRUs to model speaker information, the context of previous dialogue, and emotional information. The model defines a global context state (Global state) and the state of dialogue participants (Party state). Structurally, it consists of Global GRU, Party GRU, and Emotion GRU components, where the Global GRU computes and updates the Global state at each moment. The Party GRU computes and updates the Party state of the current speaker at that moment. The Emotion GRU computes the emotional representation of the current dialogue content.
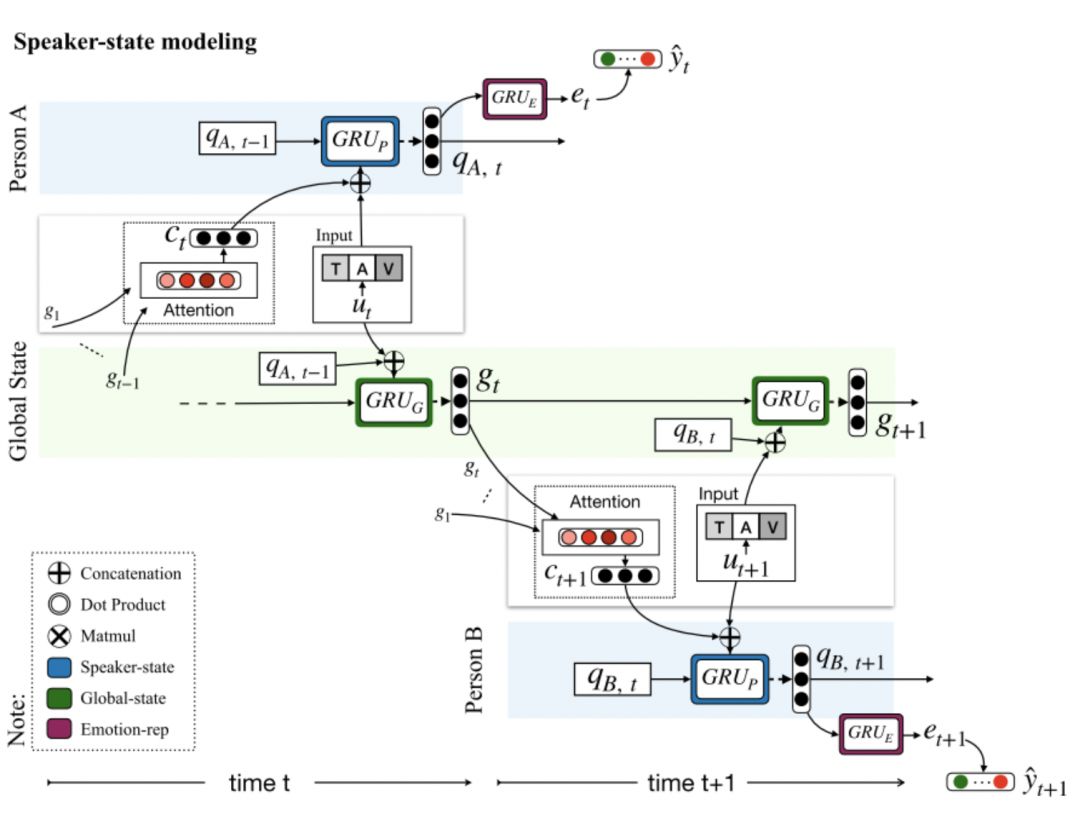
Figure 7 DialogueRNN Model Architecture
Sentiment Classification Tasks for News Videos
Datasets
The News Rover Sentiment dataset is a dataset in the news domain. The videos used in this dataset were recorded between August 13, 2013, and December 25, 2013, from various news programs and channels in the United States. The dataset is categorized by personnel and profession, with video lengths limited to between 4 and 15 seconds. The authors believe it is difficult to interpret people’s emotions in very short videos, while videos longer than 15 seconds may contain multiple statements with different emotions. Ultimately, the dataset contains 929 segments, with each segment annotated in three categories of sentiment.
Irony Detection Tasks for Dialogue Videos
Datasets
The MUStARD dataset is a multimodal sarcasm detection dataset with a wide range of sources, including well-known TV shows like The Big Bang Theory, Friends, and Golden Girls. The authors collected videos containing sarcasm from these shows and obtained non-sarcastic videos from the MELD dataset, resulting in a final dataset containing 690 video segments, with 345 being sarcastic and 345 non-sarcastic. The dataset is annotated for sarcasm presence.
The above dataset information can be summarized in Table 2.
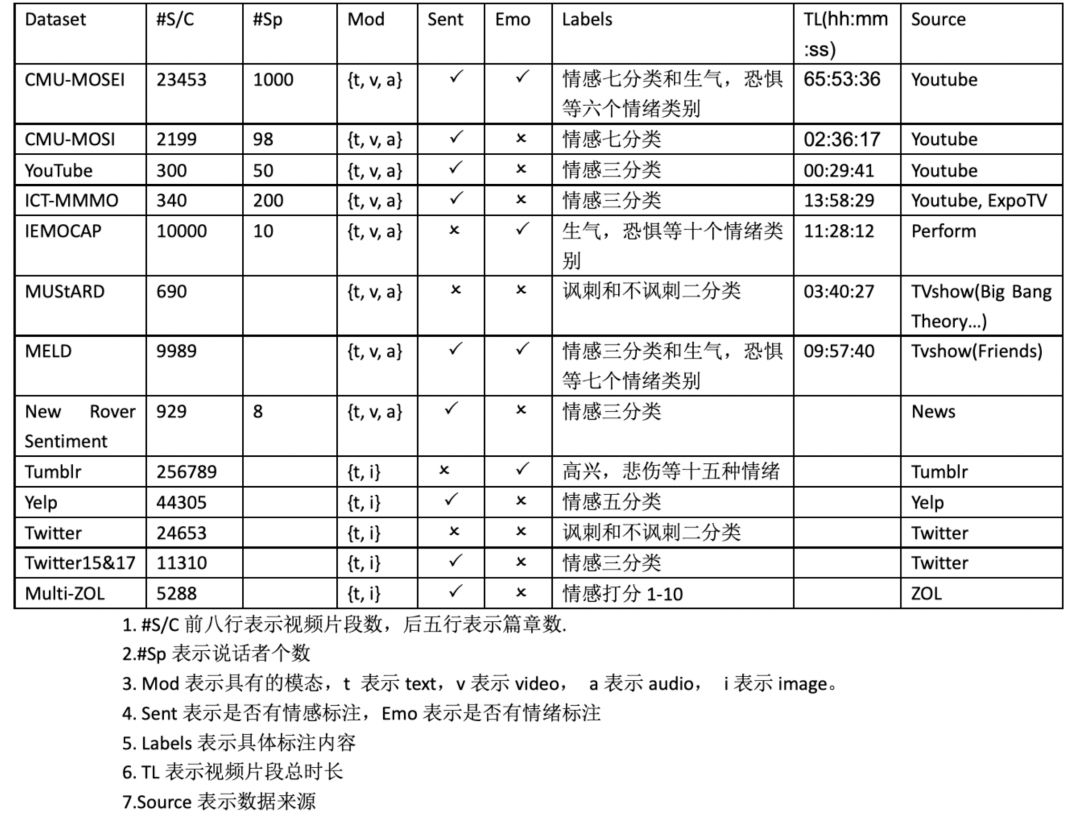
Table 2 Information Table for Multimodal Sentiment Analysis Related Datasets
Conclusion
This article briefly outlines the related tasks in the field of multimodal sentiment analysis and summarizes the datasets and some typical methods corresponding to these tasks. Although multimodal data provides more information, how to process and analyze multimodal information and how to fuse information from different modalities remains a major issue that the field of multimodal sentiment analysis needs to address.
References
[1] Truong T Q, Lauw H W. VistaNet: Visual Aspect Attention Network for Multimodal Sentiment Analysis[C]. National Conference on Artificial Intelligence, 2019: 305-312.
[2] Xu N, Mao W, Chen G, et al. Multi-Interactive Memory Network for Aspect Based Multimodal Sentiment Analysis[C]. National Conference on Artificial Intelligence, 2019: 371-378.
[3] Cai Y, Cai H, Wan X, et al. Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model[C]. Meeting of the Association for Computational Linguistics, 2019: 2506-2515.
[4] Zadeh A, Chen M, Poria S, et al. Tensor Fusion Network for Multimodal Sentiment Analysis[C]. Empirical Methods in Natural Language Processing, 2017: 1103-1114.
[5] Zadeh A, Liang P P, Poria S, et al. Multi-attention Recurrent Network for Human Communication Comprehension[J]. arXiv: Artificial Intelligence, 2018.
[6] Zadeh A, Liang P P, Mazumder N, et al. Memory Fusion Network for Multi-view Sequential Learning[J]. arXiv: Learning, 2018.
[7] Majumder N, Poria S, Hazarika D, et al. DialogueRNN: An Attentive RNN for Emotion Detection in Conversations[C]. National Conference on Artificial Intelligence, 2019: 6818-6825.
[8] Yu J, Jiang J. Adapting BERT for Target-Oriented Multimodal Sentiment Classification[C]. International Joint Conference on Artificial Intelligence, 2019: 5408-5414.
[9] Morency L, Mihalcea R, Doshi P, et al. Towards Multimodal Sentiment Analysis: Harvesting Opinions from the Web[C]. International Conference on Multimodal Interfaces, 2011: 169-176.
[10] Wollmer M, Weninger F, Knaup T, et al. YouTube Movie Reviews: Sentiment Analysis in an Audio-Visual Context[J]. IEEE Intelligent Systems, 2013, 28(3): 46-53.
[11] Zadeh A. Micro-opinion Sentiment Intensity Analysis and Summarization in Online Videos[C]. International Conference on Multimodal Interfaces, 2015: 587-591.
[12] Zadeh A B, Liang P P, Poria S, et al. Multimodal Language Analysis in the Wild: CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph[C]. Meeting of the Association for Computational Linguistics, 2018: 2236-2246.
[13] Poria S, Hazarika D, Majumder N, et al. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations[J]. arXiv: Computation and Language, 2018.
[14] Busso C, Bulut M, Lee C, et al. IEMOCAP: Interactive Emotional Dyadic Motion Capture Database[J]. Language Resources and Evaluation, 2008, 42(4): 335-359.
[15] Ellis J G, Jou B, Chang S, et al. Why We Watch the News: A Dataset for Exploring Sentiment in Broadcast Video News[C]. International Conference on Multimodal Interfaces, 2014: 104-111.
[16] Castro S, Hazarika D, Perezrosas V, et al. Towards Multimodal Sarcasm Detection (An _Obviously_Perfect Paper).[J]. arXiv: Computation and Language, 2019.
This issue’s editor: Ding Xiao
This issue’s editor: Gu Yuxuan
Recommended Reading:
The Differences and Connections Between Fully Connected Graph Convolutional Networks (GCN) and Self-Attention Mechanisms
Complete Guide for Beginners on Graph Convolutional Networks (GCN)
Paper Review [ACL18] Component Syntax Analysis Based on Self-Attentive
