Previously introduced were CNN (Convolutional Neural Network), BNN (Binarized Neural Network), dual-learning NMT and DBN, as well as deep learning optimization algorithms Batch Normalization and Layer Normalization. Students interested can add the WeChat public account “Deep Learning and NLP“, reply with keywords “CNN”, “BNN“, “dual”, “DBN“, BN and LN to get the corresponding article links. Today we introduce GAN and its variant models.
Today, we mainly introduce the most popular deep learning model of 2016, the Generative Adversarial Network (Generative Adversarial Net)-GAN. GAN was proposed by current Google Brain scientist Ian Goodfellow in 2014 as a new deep learning framework based on adversarial training (Adversarial training) to train generative models (Generative Model). GAN consists of two models: a generative model G, which aims to obtain the distribution of input samples x (Representation learning suggests that the deep learning fitting process of the relationship between input samples ( x, y) is actually learning the distribution of the input sample x), and a discriminative model (Discriminative Model) D, which estimates the probability that a sample is real rather than generated by G.
First, let’s briefly introduce the classification of traditional deep learning models. At the beginning of deep learning, models were divided into two main categories: generative models and discriminative models. Typical networks of generative models include Deep Belief Networks (Deep Belief Network, DBN), Stacked Auto-Encoders (Stacked Auto-Encoder, SAE), and Deep Boltzmann Machines (Deep Boltzmann Machine, DBM), which believe that the output sample y is generated by the input sample x. There exists an optimal input sample x* that maximizes the value of the output y. Through generative models, we can learn the representation of input samples x. Its greatest advantage is that it allows unsupervised or semi-supervised learning directly from input samples x, reducing the need for labeled samples. Discriminative models believe that the input sample x is determined by the output sample y, with typical networks like Convolutional Neural Networks (Convolution Neural Network, CNN). I personally believe that GAN combines the two, where the generative model G generates output y’ based on input x and passes it to the discriminative model D to determine whether it is real data.
GAN: Generative Adversarial Nets. Ian J. Goodfellow, Jean Pouget-Abadie. 2014.06.10
NIPS 2016 Tutorial: Generative Adversarial Networks. Ian Goodfellow. 2017.01.09
GAN training: GAN training consists of two parts: G’s training objective is to maximize the probability that D makes an incorrect identification, that is, to make D as wrong as possible; D’s objective is to find the samples generated by G. In the extreme case, when G can completely recover the distribution of input samples X, D has already identified the samples generated by G, so the output probability of G is everywhere 1/2. Compared to traditional generative models like DBN, training generative models in this way does not require complex Markov chains or approximate inference processes like the CD-K algorithm.
The construction of the objective function is based on a prior defined by the input variable with noise p( z) to define an input z, then use G( z, Q) to map the input z to the generator output y’, G is differentiable everywhere and represented by a multi-layer neural network, using its parameters Q to fit the distribution of input samples x. Then, use a multi-layer network to represent D, outputting a scalar that indicates the probability of coming from x rather than p( z). For G, this is equivalent to minimizing log( 1-D(G(z))) expectation; for D, it is equivalent to maximizing logD( x) expectation, similar to a minimax game. Thus, we can derive the objective function of GAN V( G, D):
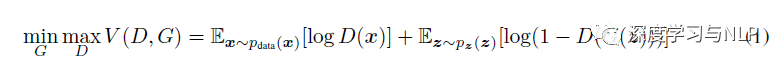
Outer loop After training G once, the inner loop trains D again, which is very time-consuming, and training on a single training set can easily lead to overfitting. Therefore, in the actual GAN training process, after training D K times, we train G, the purpose of this is to keep D in an optimum state, allowing G to change gradually. This gives us the training algorithm:

The theory of generative adversarial networks or adversarial training proposed by Ian Goodfellow is a general framework, based on which many variants have emerged suitable for solving practical problems in various scenarios, demonstrating the powerful capabilities of the GAN family. Below is a brief introduction to some representative models.
CGAN:Conditional Generative Adversarial Nets for Convolutional Face Generation.Jon Gauthier.2015.03
Conditional Generative Adversarial Nets.Mehdi Mirza.2014.11.06
Problem addressed: In image annotation, classification, and generation processes, there are two types of problems: first, the output images have many labels, thousands of categories; second, for a given input x, corresponding suitable output y ( label) categories are multi-modal (multiple), how to choose a suitable category is a problem. CGAN attempts to add additional condition information on the generator G and discriminator D to guide the training of the two models in GAN.
How it works: The conditionalization (conditional) of GAN involves directly adding the additional information ( y) into the objective functions of the generator G and discriminator D, forming a conditional probability with inputs Z and X, as shown in the figure below:
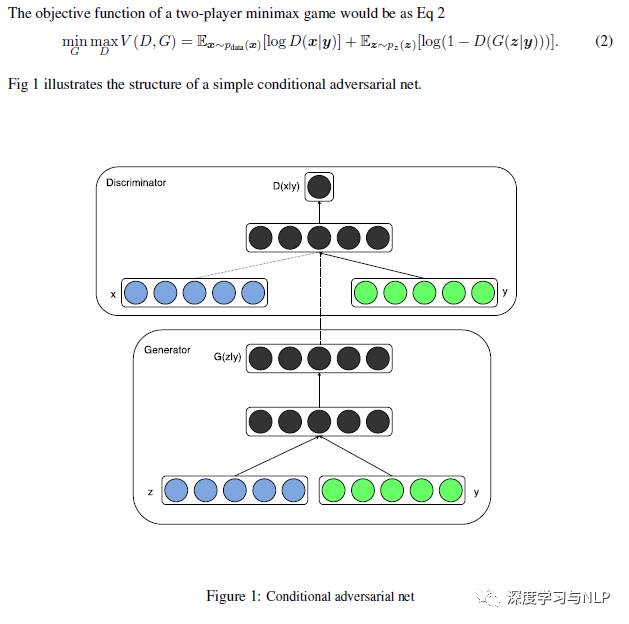
The additional information used to guide the training of G and D can be various types (multi-modal) of data. Taking image classification as an example, it can be a label tag, or a text description about the image category or other information.
DCGAN: UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS. Alec Radford & Luke Metz. 2016.01.07
Problem addressed: Integrating supervised learning CNN with unsupervised learning GAN led to the proposal of Deep Convolutional Generative Adversarial Networks – DCGANs, where the generator and discriminator learn hierarchical representations of input images.
This paper’s main contributions: 1, combining CNN with GAN proposed DCGANs, using DCGANs to learn useful features from a large amount of unlabeled data (images, speech), which is equivalent to initializing the parameters of the generator and discriminator of DCGANs with unlabeled data for use in supervised scenarios, such as image classification. 2, representation learning: attempting to understand and visualize how GAN works, what the intermediate representations of multi-layer GAN are. 3, providing some guidelines for stable training of DCGANs.
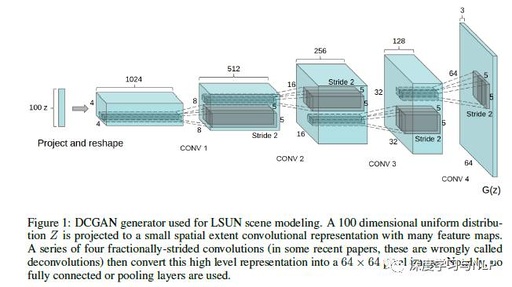
DCGAN network structure:
The construction of generator G:
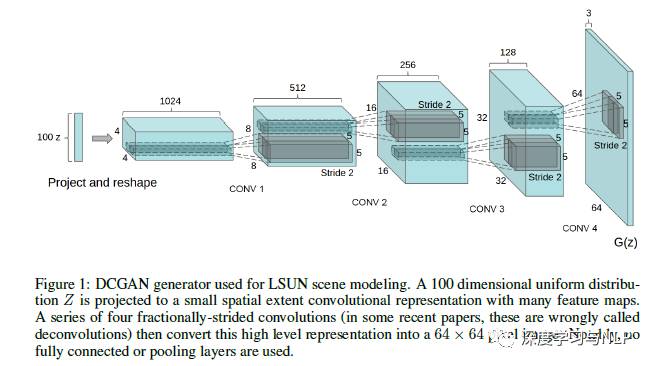
The generator G consists of four stacked convolution operations, without using fully connected layers.
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. Xi Chen, Yan Duan, Rein Houthooft, John Schulman. 2016.06.12
Problem addressed: Unsupervised learning or representation learning can be seen as the problem of extracting valuable features from a large amount of unlabeled data, or learning an important latent feature representation. However, unsupervised learning is ill-posed because many downstream tasks related to unsupervised learning are unknown during training, while supervised learning is a form of separating/disentangled representation, which aids learning of downstream tasks that are related but unknown, as disentangled representation can learn the salient attributes of input samples. The most important model in unsupervised learning is the generative model, such as Generative Adversarial Networks GAN and Variational Autoencoders ( VAE). This paper proposes InfoGAN by combining information theory with GAN from the perspective of disentangled representation, using an unsupervised approach to learn interpretable and meaningful representations of input samples X.
How it works: By maximizing the mutual information between a subset of latent variables and the observation.
SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. Lantao Yuy, Weinan Zhangy, Jun Wangz, Yong Yuy. 2016.12.09
Problem addressed: GAN: using a discriminative model D to guide the training of the generative model G has achieved great success in generating real-valued data, but it mainly deals with continuous differentiable data, such as images, and rarely involves discrete data, such as text. There are two reasons: first, the gradient from the discriminator D cannot be backpropagated to the generator G because G is discrete and non-differentiable; second, the discriminator D can evaluate the score of a complete sequence, but cannot assess the score of only partially generated sequences at the current and future states. Therefore, this paper proposes SeqGAN to address these two issues.
How it works: Drawing on the idea of rewards in reinforcement learning, a complete sequence is constructed at the discriminator D to provide feedback to guide the training of the generator G through a reward signal, optimizing the parameters of G using policy gradient methods from RL, thus bypassing the above two issues.
SeqGAN structure:

StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks. Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang. 2016.12.10
Problem addressed: Generating images based on text descriptions has many application scenarios, such as image-assisted cropping, computer-aided design, etc. However, the biggest problem is that there are many scenes that conform to the text description (multi-modal), and how to select the best scene to generate high-resolution images is a challenge. This paper addresses this issue based on GAN, where previous methods could only generate low-resolution images of 64X64, this paper uses Stack GAN to generate high-resolution images of 256X256, achieving improvements of 28.47% and 20.30% over existing methods on the CUB and Oxford-102 datasets, respectively, which is impressive and demonstrates the powerful capabilities of GAN.
How it works: A stacked GAN model is proposed for generating high-resolution images in the “text-to-image” task, where stack-1 GAN generates a low-resolution image of 64X64 containing the primary shape and basic color of the object described by the text, and stack-2 GAN takes the low-resolution image output from GAN-1 as input, along with the text description, to rectify defects and add details, generating a 256X256 high-resolution image after refinement.
Stack GAN network structure:
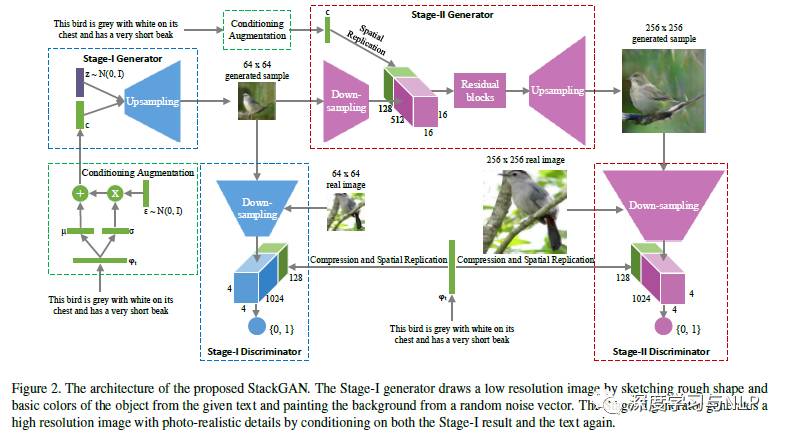
The key point is how the two GANs in Stack-GAN are constructed and trained.
WGAN: Wasserstein GAN. Martin Arjovsky, Soumith Chintala, and Lon Bottou. 2017.03.09
Improved Training of Wasserstein GANs.Ishaan Gulrajani1, Faruk Ahmed1, Martin Arjovsky2. 2017.03.31
Problem addressed: Training GANs is troublesome, requiring careful design of the generator G and discriminator D network structures, adjusting many hyperparameters, and often not converging. To solve this problem and make GAN training easier, this paper proposes the Wasserstein GAN ( WGAN).
How it works: By deeply analyzing the convergence characteristics of the value function optimized by GAN, it points out that traditional GAN instability arises because its value function constructed based on Jensen-Shannon divergence is non-differentiable at certain points, leading to unstable training of the generator G. Therefore, it proposes the Earth-Mover distance, also known as Wasserstein-1 distance W( q,p), based on Wasserstein distance to construct the value function, replacing the traditional value function based on Jensen-Shannon divergence in GAN. The Wasserstein distance has better properties; the Jensen-Shannon divergence may be discontinuous, providing no stable gradient for optimizing the parameters of the generator G; in contrast, the Earth-Mover distance is continuous and differentiable everywhere.
Comparison of Jensen-Shannon distance and Wasserstein distance:

WGAN training algorithm:

For more classic papers, practical experiences, and the latest news on deep learning applications in NLP, please follow the WeChat public account “Deep Learning and NLP” or “DeepLearning_NLP” or scan the QR code to add.
