Originally published on Data Analysis and Applications
This article provides a comprehensive review of the current state-of-the-art RAG technology, including Naive RAG, Advanced RAG, and Modular RAG paradigms, all within the context of LLMs. The article discusses core technologies in the RAG process such as “retrieval,” “generation,” and “enhancement,” and delves into their synergistic effects. Additionally, a comprehensive evaluation framework is constructed, outlining evaluation objectives and metrics, and conducting comparative analysis to clarify the advantages and disadvantages of RAG. Finally, the article predicts future directions for RAG, emphasizing potential enhancements to address current challenges, the expansion of multimodal settings, and the development of its ecosystem.
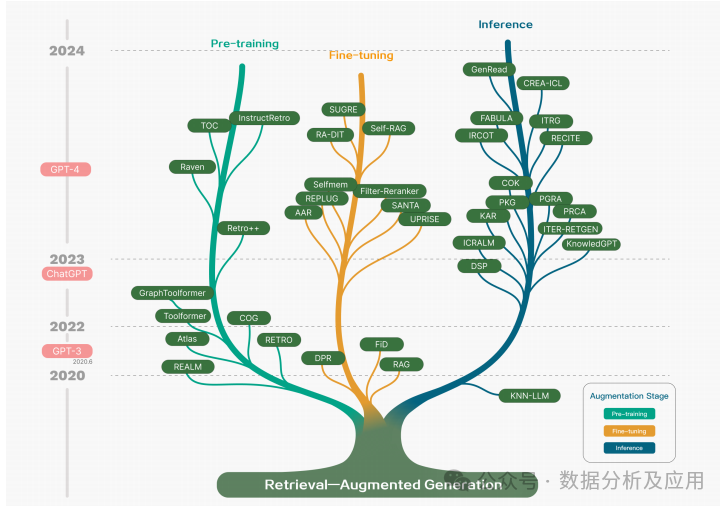
Figure 1 RAG Technology Development Technology Tree
RAG is a paradigm that enhances the performance of LLMs by integrating external knowledge bases, employing a collaborative approach that combines information retrieval mechanisms with contextual learning to improve LLM performance. Its workflow includes three key steps: partitioning the corpus into discrete chunks, constructing a vector index, and identifying and retrieving chunks based on vector similarity to queries and index chunks. These steps support its information retrieval and context-aware generation capabilities. RAG has become one of the most popular architectures in LLM systems, with many conversational products built almost entirely on RAG.
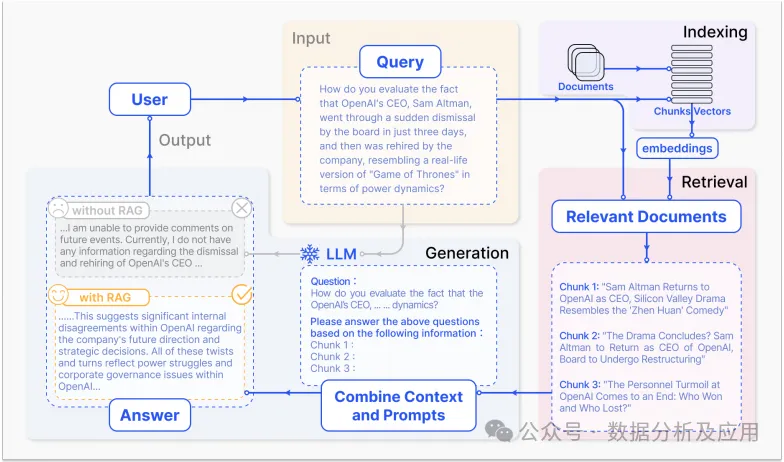
Figure 2 RAG Technology Case in QA Problems
In the technological evolution of RAG, based on considerations of technical paradigms, we classify its development into the following stages: Naive RAG, Advanced RAG, and Modular RAG.
The Naive RAG research paradigm is an early methodology for handling natural language generation tasks. It consists of three phases: indexing, retrieval, and generation. The indexing phase extracts text from raw data and transforms it into vector representations for easier retrieval and generation. The retrieval phase computes similarity scores between the query vector and the vectorized chunks in the indexed corpus, prioritizing the retrieval of the most similar chunks as the basis for extended context. The generation phase synthesizes the query and selected documents into a coherent prompt and requires the large language model to formulate a response based on that prompt. This approach allows the model to leverage its inherent parameter knowledge or restrict its responses to the information contained in the provided documents.
Naive RAG faces challenges in the three key areas of retrieval, generation, and enhancement, including low accuracy, low recall, hallucination challenges, difficulties in contextual integration, redundancy, balancing paragraph value, coordinating writing style and tone, and over-reliance on augmented information. These issues affect model performance and output quality.
Advanced RAG addresses the shortcomings of Naive RAG by enhancing targeted retrieval strategies and improving indexing methods. It implements pre-retrieval and post-retrieval strategies and employs techniques such as sliding windows, fine-grained segmentation, and metadata to improve indexing methods. Additionally, various methods are introduced to optimize the retrieval process, such as ILIN. During the retrieval phase, appropriate context is determined by calculating the similarity between queries and chunks, and embedding models are fine-tuned to enhance retrieval relevance in specific domain contexts. In the post-retrieval phase, challenges posed by contextual window limitations are addressed, and the retrieved content is re-ranked and prompt-compressed.
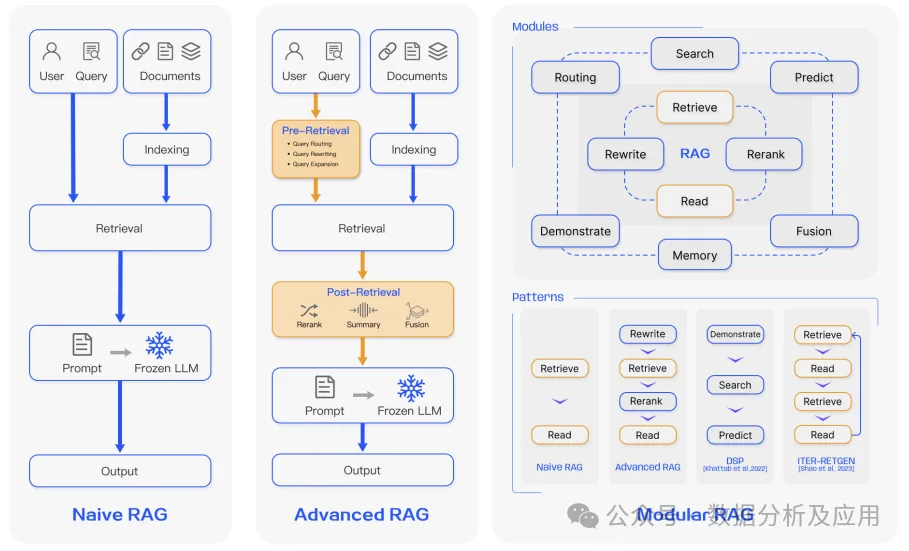
Figure 3 Comparison of RAG Paradigms
The Modular RAG structure is a new framework with great flexibility and adaptability, capable of integrating various methods to enhance functional modules that address specific problems. This paradigm is gradually becoming the norm, supporting serial pipelines between multiple modules or end-to-end training methods. Advanced RAG is a specialized form of Modular RAG, while Naive RAG is a special case of Advanced RAG. The relationships among the three are one of inheritance and development.
The new module search module achieves customization for specific scenarios and direct search of additional corpora by integrating code generated by LLMs, query languages, and other customized tools. The memory module utilizes the memory capabilities of LLMs to guide retrieval, creating an infinite memory pool iteratively and combining “original questions” and “dual questions.” RAG-Fusion enhances traditional search systems by adopting multi-query methods, revealing deeper transformational knowledge. Query routing determines the subsequent actions for the user’s query, selecting appropriate data storage for the query, and ensuring that search results closely match the user’s explicit and implicit intentions. Task adapters focus on adapting RAG for various downstream tasks and enhance cross-task and model generality.
The Modular RAG under the new paradigm exhibits high adaptability, allowing modules to be replaced or rearranged during the RAG process to suit specific problem contexts. Optimizing the RAG pipeline can enhance information efficiency and information quality by integrating various search technologies, improving retrieval steps, incorporating cognitive backtracking, implementing multifunctional query strategies, and utilizing embedding similarity to achieve a balance between retrieval efficiency and contextual information depth. These methods help generate responses to backtracking prompts and the final answer generation process. However, this approach may not always yield satisfactory results, especially when the language model is unfamiliar with the topic.
In RAG, precise semantic representation, coordination of query and document semantic spaces, and alignment of retriever output with large language model preferences are core issues for efficiently retrieving relevant documents.
4.1 Enhanced Semantic Representation
The semantic space in RAG is crucial for the multi-dimensional mapping of queries and documents. Methods for establishing accurate semantic spaces include chunk optimization and fine-tuning embedding models that manage external documents. Chunk optimization needs to consider the nature of indexed content, embedding models, the expected length and complexity of user queries, and application usage, while fine-tuning embedding models requires specialized domain datasets to enhance the model’s ability to accurately capture specific domain information. Recent studies have introduced diversified methods such as summary embedding techniques, metadata filtering techniques, and graph indexing techniques to improve retrieval results and RAG performance.
4.2 Aligning Queries and Documents
In RAG applications, the retriever can achieve semantic alignment of queries and documents through two fundamental techniques: query rewriting and embedding transformation. Query rewriting creates pseudo-documents or generates “hypothetical” documents by combining the original query with additional guidance, while embedding transformation optimizes the representation of query embeddings and maps them to a latent space more closely aligned with the intended task. Both techniques enhance the retriever’s ability to identify structured information.
4.3 Aligning Retriever and LLM
In the RAG pipeline, improving retrieval hit rates does not necessarily enhance final outcomes, as the retrieved documents may not meet the needs of LLMs. To improve retrieval performance and respond more accurately to user queries, two methods are proposed to align the retriever output with LLM preferences: fine-tuning the retriever and using adapters. Fine-tuning the retriever can use LLM feedback signals to refine the retrieval model and train with supervised signals. Adapters help align by integrating API functionalities or addressing limited local computing resources. Additionally, four methods for supervised fine-tuning embedding models are introduced to enhance the synergy between the retriever and LLM. These methods aid in improving retrieval performance and responding more accurately to user queries.
A crucial component of RAG is the generator, responsible for converting retrieved information into coherent text. It increases accuracy by integrating data, guided by the retrieved text to ensure consistency. This comprehensive input allows the generator to gain a deeper understanding of the problem context, providing more informative and contextually relevant responses. The generator helps enhance the adaptability of large models to input data.
5.1 Using Frozen LLM for Post-Retrieval
Using large language models for post-retrieval processing can optimize the quality of retrieval results, making them more aligned with user needs or subsequent tasks. Information compression and re-ranking are two common operations that enhance the accuracy of model responses by reducing noise, addressing contextual length limitations, and enhancing generation effects. Re-ranking models play a vital role in optimizing the set of documents retrieved by the retriever by rearranging document records, prioritizing the most relevant items, thus limiting the total number of documents and improving retrieval efficiency and response speed. This approach also incorporates context compression to provide more precise retrieval information.
5.2 Fine-Tuning LLM for RAG
The key to optimizing RAG models lies in enhancing the generator’s performance, which receives retrieved information and generates relevant text. To improve the generator’s performance, the model needs fine-tuning, exploring data and optimization functions with representative work. The overall optimization process typically includes training data comprising input-output pairs, aimed at training the model to generate outputs based on inputs. Utilizing contrastive learning and implementing structured data training schemes can also enhance model performance.
The key technologies in the development of RAG primarily revolve around the enhancement phase, enhancement data sources, and enhancement processes. Figure 4 illustrates the classification of core components of RAG.
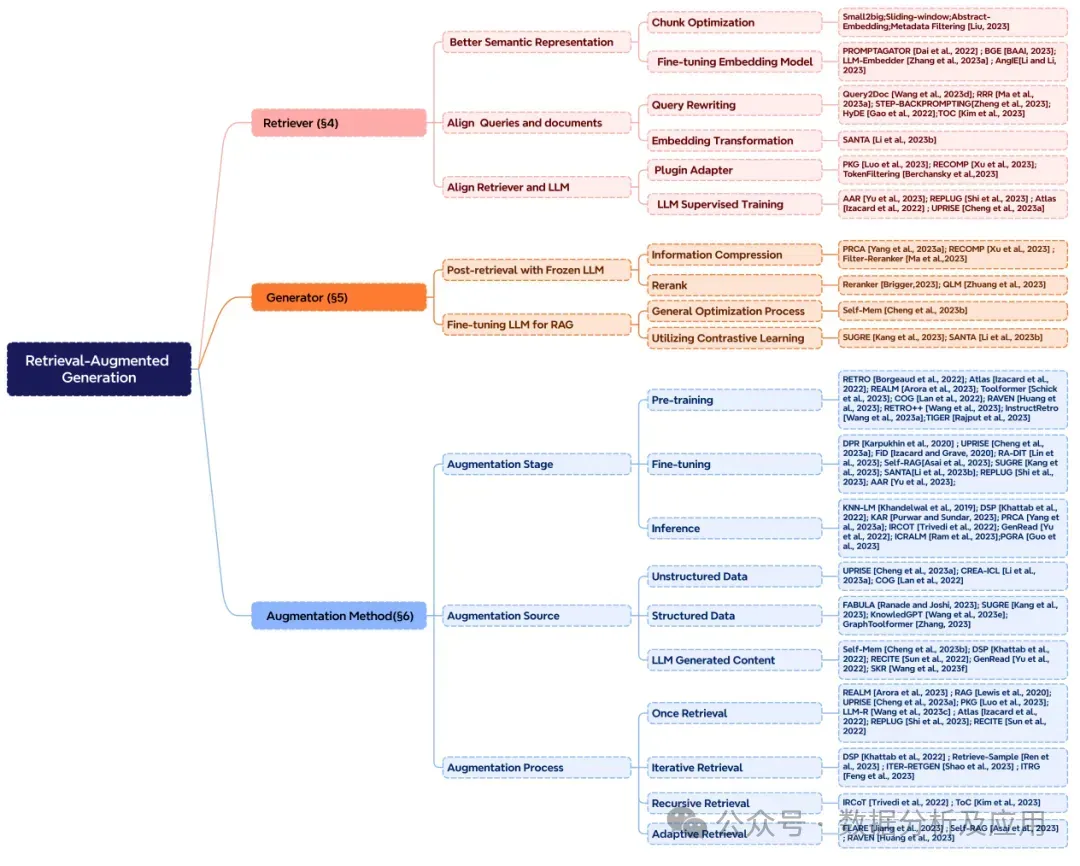
Figure 4 Classification System of Core Components of RAG
6.1 Enhancement Phase of RAG
The enhancement phase of RAG includes pre-training, fine-tuning, and inference stages. The pre-training phase strengthens open-domain QA PTMs based on retrieval strategies, such as the REALM and RETRO models. In the fine-tuning phase, RAG combined with fine-tuning can better meet specific scenario needs, optimizing semantic representation, coordinating retrieval and generation models, and enhancing generality and adaptability. The inference phase of RAG models is crucial, with extensive integration with LLMs, such as DSP framework, PKG method, CREAICL, RECITE, and ITRG. These enhancement phases leverage the capabilities of pre-trained models without further training.
The RAG model improves effectiveness by selecting enhancement data sources and employing different levels of knowledge processing techniques. Enhancement methods include using unstructured data such as plain text, structured data, and leveraging content generated by LLMs for retrieval and enhancement. When combining unstructured data, the model generates low-probability word triggers, creating temporary sentences and regenerating sentences with retrieved context to predict subsequent sentences. When combining structured data, the model uses knowledge graphs to provide high-quality contextual information, alleviating model hallucinations. When utilizing text generated by LLMs in RAG, the model categorizes questions as known or unknown, selectively applying retrieval enhancement or using the LLM generator to replace the retriever, creating an infinite memory pool iteratively with retrieval-augmented generators, using memory selectors to choose outputs as dual questions to the original question, thereby self-enhancing the generation model. These methods emphasize the broad use of innovative data sources in RAG, aiming to improve model performance and task effectiveness.
6.3 Enhancement Processes
In the RAG field, to address the inefficiencies that may arise from a single retrieval step and generation, methods have been proposed to improve the retrieval process, including iterative retrieval, recursive retrieval, and adaptive retrieval. Iterative retrieval provides additional contextual references through multiple iterations, enhancing the robustness of subsequent answer generation. Recursive retrieval improves the depth and relevance of search results by repeatedly refining search queries. Adaptive retrieval enhances the efficiency and relevance of retrieval information by allowing LLMs to actively determine the optimal timing and content for retrieval. These methods need to be chosen based on the specific requirements of the scenario and the inherent properties of each method.
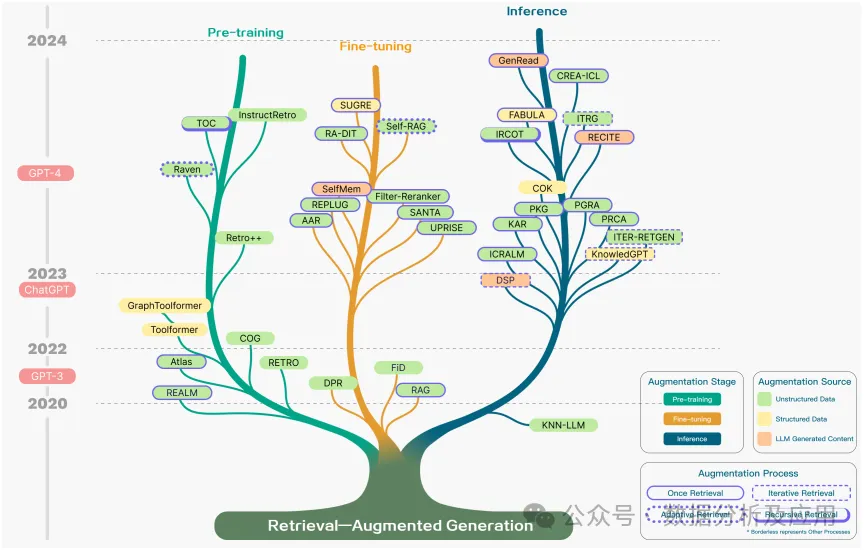
Figure 5 Technical Tree Map of Representative RAG Research with Different Enhancement Aspects
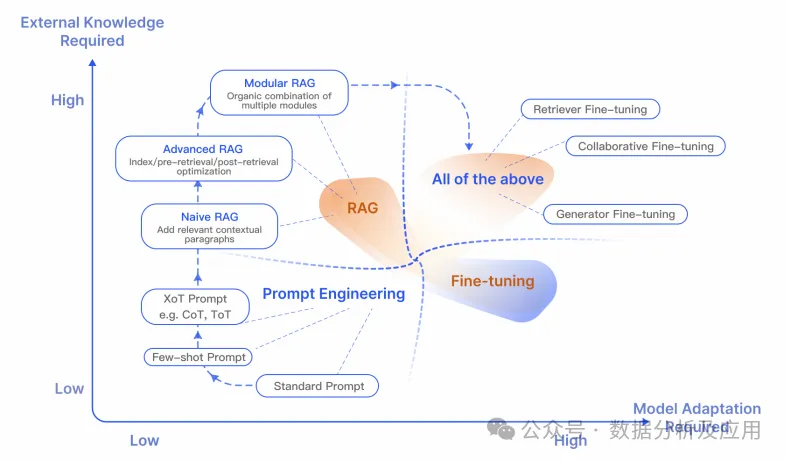
Figure 6 Comparison of RAG with Other Model Optimization Methods
Table 1 Comparison between RAG and Fine-Tuning
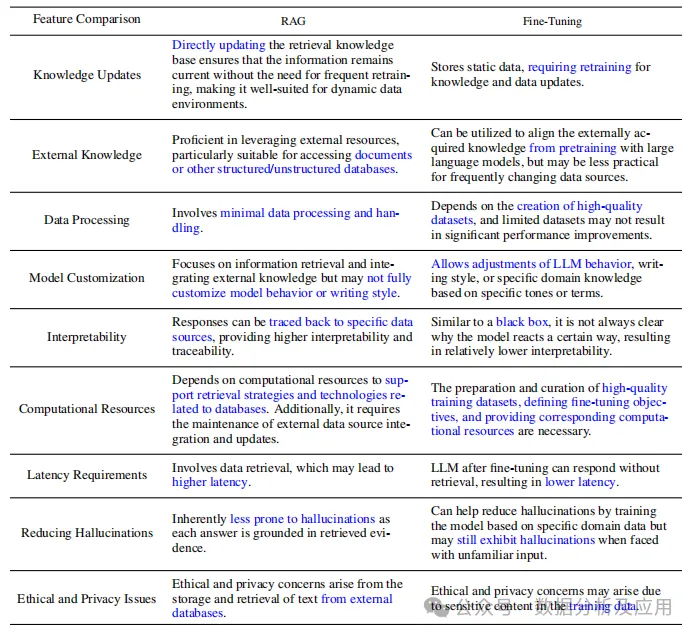
6.4 Comparison of RAG and Fine-Tuning
RAG and FT are two different approaches; RAG is suitable for specific queries, while FT is suitable for replicating specific structures, styles, or formats. FT can enhance model performance and efficiency but is not suitable for integrating new knowledge or rapidly iterating new uses. These two methods can complement each other, and combined use may yield optimal performance. The optimization process may require multiple iterations.
Evaluation of RAG models in natural language processing has garnered attention in the legal linguistics community, with the primary aim of understanding and optimizing model performance in different application scenarios. Historically, evaluation has focused on performance in specific downstream tasks, using established metrics suitable for the task at hand. Now, the objectives, aspects, benchmarks, and tools for evaluation have shifted to research based on the unique properties of RAG models to provide a comprehensive overview.
7.1 Evaluation Objectives
The evaluation of RAG models focuses on the retrieval and generation modules. Evaluating retrieval quality can use metrics such as hit rate, MRR, and NDCG, while evaluating generation quality includes authenticity, relevance, non-harmfulness, and accuracy, which can be assessed through manual or automated methods. For unannotated content, evaluation also includes contextually relevant answers. Evaluation methods can be used for assessing the quality of both retrieval and generation.
The evaluation of RAG models primarily focuses on three key quality scores (contextual relevance and answer accuracy, relevance) and four fundamental capabilities (noise robustness, negative rejection, information integration, counterfactual robustness). These factors collectively influence the two major objectives of retrieval and generation for the model. Quality scores assess the efficiency of the model from different angles in the information retrieval and generation processes, while capabilities are crucial for the model’s performance in various challenges and complex scenarios. Table 2 summarizes the specific metrics for each evaluation aspect.
Table 2 Summary of Metrics Applicable to Evaluation Aspects of RAG

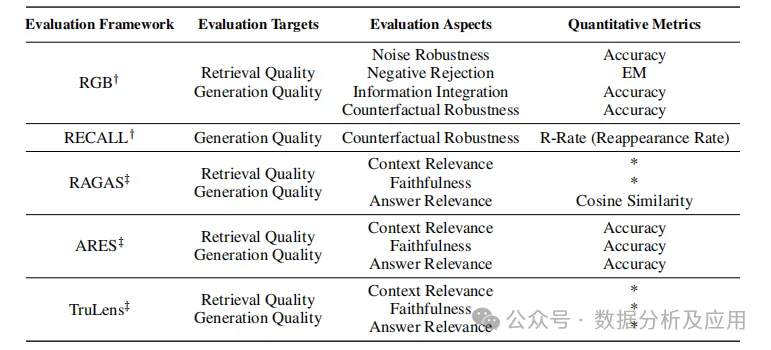
7.3 Evaluation Benchmarks and Tools
The evaluation framework for RAG models comprises benchmarking and automated evaluation tools, providing quantitative metrics to measure model performance and deepen understanding of its capabilities. Benchmarking evaluates the basic capabilities of the model, while automated tools utilize LLMs to adjudicate quality scores. These tools and benchmarks together form a robust evaluation framework for RAG models, as shown in Table 3.
Table 3 Summary of Evaluation Framework
This section discusses three future outlooks for RAG: future challenges, model expansion, and the RAG ecosystem.
8.1 Future Challenges for RAG
Although RAG technology has made significant progress, it still faces some challenges, such as expanding the role of LLMs, scaling laws, and production-ready RAG. RAG technology has transcended text-based Q&A, embracing multimodal data such as images, audio, and video, giving rise to innovative multimodal models. In the image domain, models like RA-CM3 and BLIP-2 have achieved retrieval and generation of text and images, as well as zero-shot image-to-text conversion. In the audio and video domains, methods such as GSS, UEOP, KNN-based attention fusion, and Vid2Seq have also made progress. In the code domain, RBPS excels in retrieving code examples aligned with developers’ goals through coding and frequency analysis. There is still considerable room for development in RAG technology.
The RAG ecosystem is a powerful language model capable of handling complex queries and producing detailed responses, excelling in fields such as medicine, law, and education. The development of the RAG ecosystem is influenced by advancements in technology stacks, such as the popularity of key tools and the unique contributions of emerging technology stacks. The co-growth of RAG models and technology stacks is evident, with technological advancements continuously setting new standards for existing infrastructures. RAG toolkits are coalescing into a foundational technology stack, laying the groundwork for advanced enterprise applications. However, the concept of fully integrated and comprehensive platforms still exists, awaiting further innovation and development.
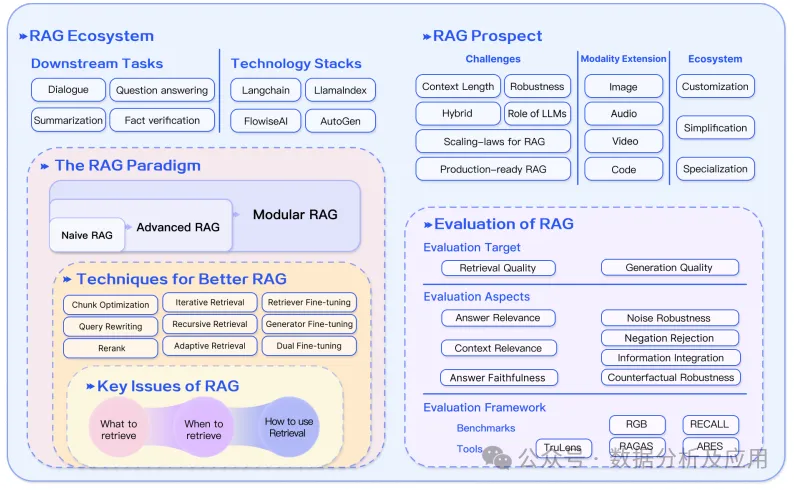
Figure 7 Overview of the RAG Ecosystem