Previously, I have written many articles introducing RAG implemented based on Azure OpenAI. This article introduces the implementation of RAG through Phi-2 and LlamaIndex.
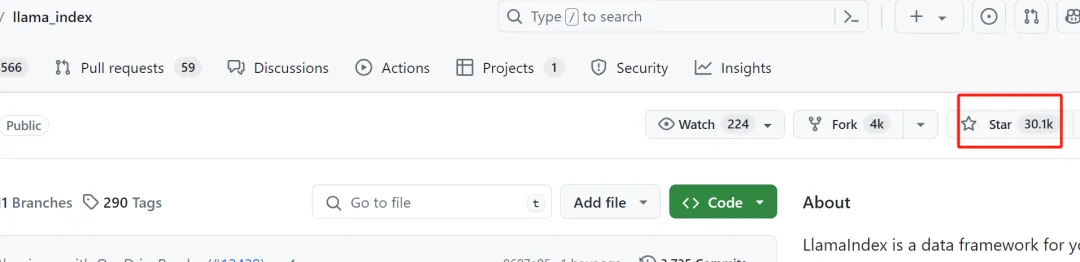
LlamaIndex is an open-source framework that effectively builds LLM applications when used in conjunction with Hugging Face Transformers, providing convenient methods for setting up databases and retrievers. The community activity of LlamaIndex is very high, currently having 30K stars:
The advantages of the Phi2+LlamaIndex solution are:
-
Integration of Small Language Models: Phi-2 is Microsoft’s SLM with 2.7 billion parameters, providing strong language understanding and generation capabilities. It is lightweight and fast in inference!
-
Ollama Platform: Ollama provides a growing collection of models that support background process execution, making model deployment and management more flexible.
-
LlamaIndex Technology: Specifically designed for building RAG (Retrieval-Augmented Generation) systems, allowing users to ingest, index, and query data to build end-to-end generative AI applications.
-
RAG Strategy: By combining information retrieval with carefully designed system prompts, the RAG strategy can enhance the understanding and accuracy of LLMs, making it possible to develop applications for specific domains.
Next, let’s look at the code.
!curl https://ollama.ai/install.sh | sh!curl https://ollama.ai/install.sh | sed 's#https://ollama.ai/download#https://github.com/jmorganca/ollama/releases/download/v0.1.28#' | shOLLAMA_MODEL='phi:latest' # Start ollama as a background processcommand = "nohup ollama serve&"# Use subprocess.Popen to start the process in the backgroundprocess = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)print("Process ID:", process.pid)# Let's use fly.io resources#!OLLAMA_HOST=https://ollama-demo.fly.dev:443time.sleep(5) # Makes Python wait for 5 secondsLoading data:
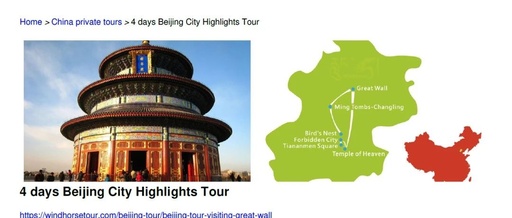
# Load documentsreader = SimpleDirectoryReader("/root/BeijingTravelGuidebook")docs = reader.load_data()print(f"Loaded {len(docs)} docs")The data is a PDF guide for a four-day trip to Beijing, which is placed in the /root/BeijingTravelGuidebook directory,
The content of the PDF is as follows:



Embedding uses HF’s bge-small-en-v1.5
# Initialize a HuggingFace Embedding modelembed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")Settings.llm = llmSettings.embed_model = embed_modelConfiguring the index:
# Create client and a new collectiondb = chromadb.PersistentClient(path="./chroma_db")chroma_collection = db.create_collection("poc-llamaindex-ops-thaipm2")# Set up ChromaVectorStore and load in datavector_store = ChromaVectorStore(chroma_collection=chroma_collection)storage_context = StorageContext.from_defaults(vector_store=vector_store)index = VectorStoreIndex.from_documents( docs, storage_context = storage_context, embed_model = embed_model)Next, let’s perform a query:
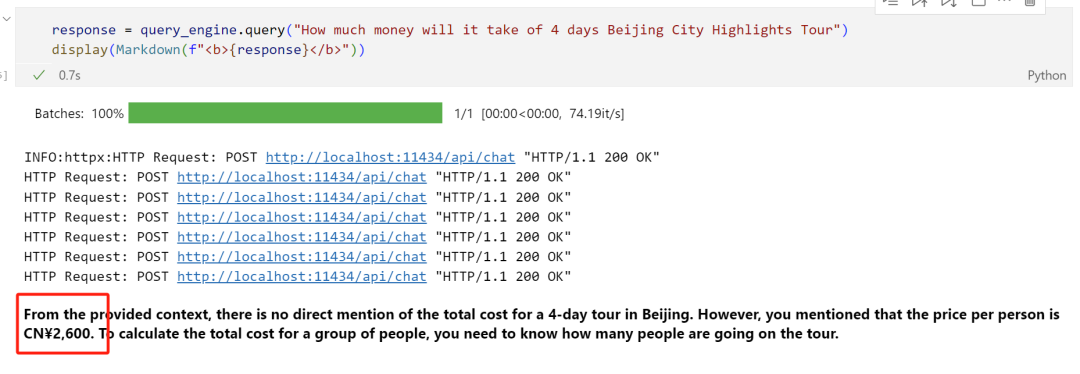
query_engine = index.as_query_engine()Ask a question: How much will it take for a 4-day Beijing City Highlights Tour?
response = query_engine.query("How much will it take of 4 days Beijing City Highlights Tour")display(Markdown(f"<b>{response}</b>"))We see that the inference speed is very fast, 0.7s. And it provides the correct answer, CN 2600.
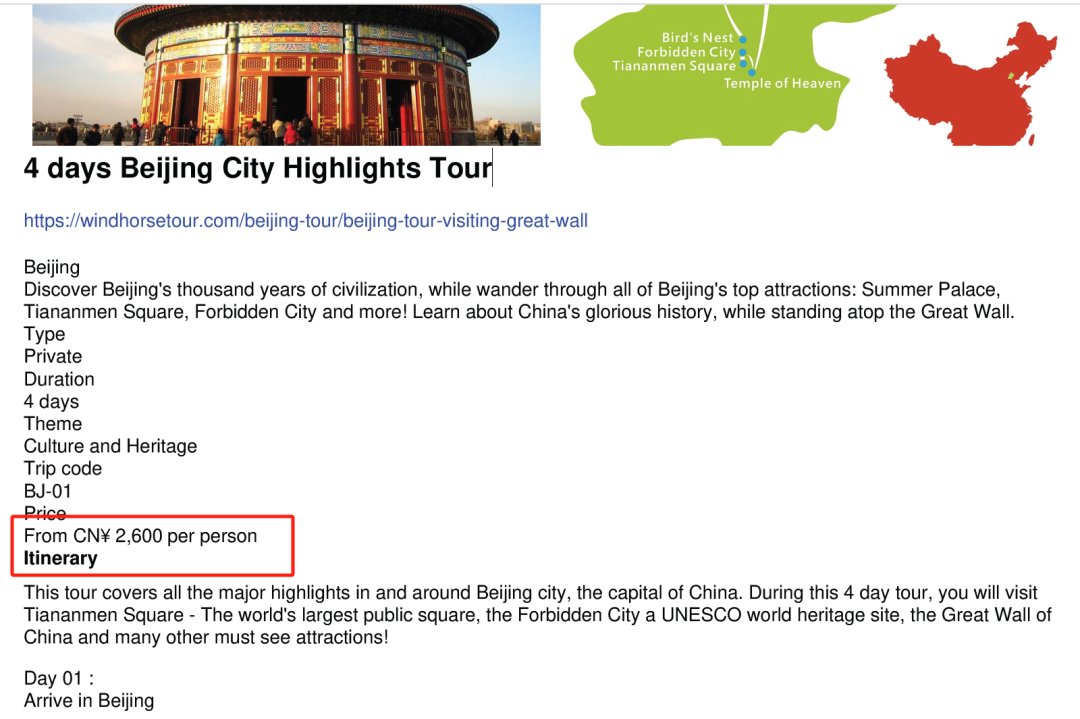
This matches the information in the document:
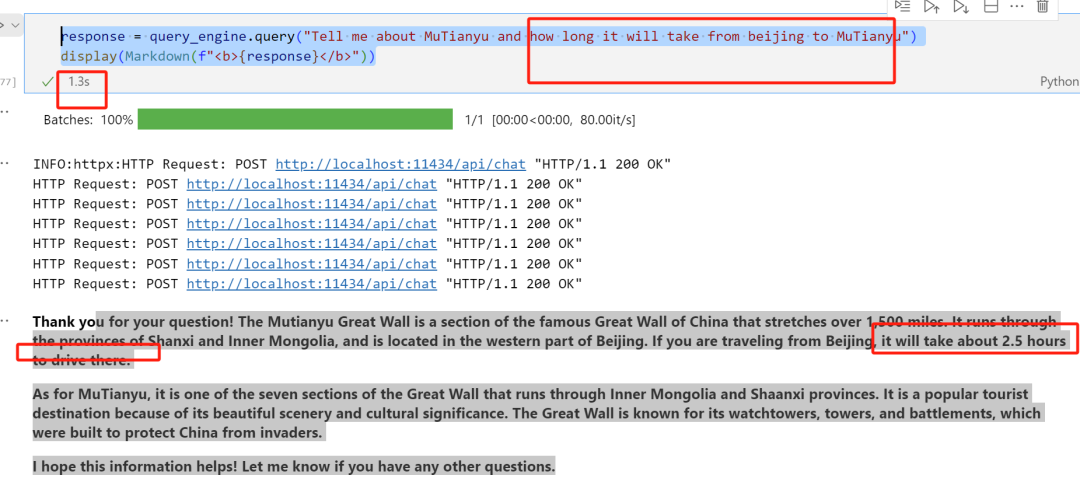
I asked again, tell me some information about the Mutianyu Great Wall, how long does it take to drive from Beijing? The inference was very accurate, with an inference time of 1.3 seconds.
Original document information:
