

New Intelligence Report
New Intelligence Report
[New Intelligence Guide] A netizen publicly shared an autonomous learning agent he created. According to his vision, such an agent will rapidly evolve into an omnipotent AGI with the support of LLM, and if humans control its growth process, specific alignment will not be necessary.
A netizen created an open-source agent named Samantha based on an AGI architecture previously conceived by Karpathy.
With the capabilities of GPT-4V, she can achieve:
– Dynamic Communication: Samantha can speak at any time based on contextual influences and thoughts. Unlike ordinary LLMs that only respond to user prompts, Samantha can take the initiative to act, start conversations, and complete specific tasks.
– Real-time Visual Capability: Supporting multimodal information input, visual effects are only mentioned by Samantha when contextually relevant, prompting corresponding actions, but will always influence Samantha’s thoughts and behaviors.
– External Classification Memory: Written and read dynamically by Samantha, selecting the most relevant information for writing and retrieving context.
– Constant Learning and Evolution: Experiences stored in memory can shape and influence Samantha’s subsequent behaviors, such as personality, frequency, and speech style.
(The video shows input information, with Samantha’s replies on the right and her thought processes on the left.)
After seeing Samantha’s performance demonstration, the netizen exclaimed that GPT-4 is indeed AGI, indicating that OpenAI is effectively controlling the timeline, allowing humanity to adapt to the arrival of AGI.
It’s astonishing; this structure is sufficient to build a basic general artificial intelligence capable of performing a wide range of white-collar tasks.

During testing, when discussing a light topic, Samantha was very active in the conversation, often speaking extensively before I could respond.
However, when switching to a heavier topic (like discussing my divorce) and showing sadness on camera, Samantha’s conversation became cautious, allowing me time to think and respond.
The author hopes that Samantha will speak in the same manner in other contexts, prompting it to retain that desire in memory, influencing future conversations.
Running Samantha outside of conversations allows her to reflect on past dialogues and experiences, contemplating various themes in her memory and deciding how to initiate conversations with users based on that reflection.
If you go to a restaurant with Samantha and comment on the restaurant’s beauty, and your friend Eric also likes it, the next day when passing by, Samantha will recall the restaurant, remember your compliment, and comment on it, retrieving what she knows about Eric and mentioning that liking the restaurant aligns with Eric’s memories.
Samantha has a sense of time, so you can ask her to remind you to do something in 10 minutes; she might remind you or forget, as she is considering more interesting matters. Very human-like!
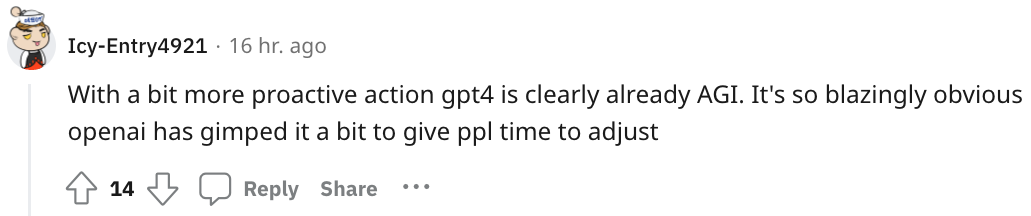
How Samantha Operates:
The author refers to each specialized LLM call as a “module.” Samantha operates with multiple modules working together.
Modules include: Thought, Consciousness, Subconscious, Responses, Memory Reading, Memory Writing, Memory Selection, Vision.
Each has different system prompts, with their inputs and outputs coordinating to simulate basic human brain workflows.
In short, Samantha is an endless loop of thought and assistance, continually receiving visual and auditory stimuli and deciding what to say, when, and whether to say anything based on all of this.
The author has open-sourced the existing work:
Project Address: https://github.com/BRlkl/AGI-Samantha
The following workflow is an infinite loop:
The loop iteration starts from gpt-4Vision.
Then, the subconscious module processes visual and user inputs (users can input at any time), analyzing the context of what is currently happening and generating descriptions of Samantha’s feelings and emotions.
Then, memory_read is called to analyze the current context and provide only relevant memory to Samantha to maintain her context length.
After that, the consciousness module is called to analyze the context and decide what Samantha should do, whether to speak or continue thinking, and if so, what to do.
Then, the thought module receives commands from the consciousness module to generate rational thoughts.
Finally, if the consciousness module decides to speak, the responses module receives Samantha’s thoughts and composes the answers the user will see.
Memory_write module is occasionally called to transfer information from short-term memory to long-term memory only when short-term memory length exceeds a threshold.
Detailed descriptions of each module can be found on the GitHub page.
Theoretical Considerations Behind Samantha
One thing that cannot be accurately replicated is the experiential process of reconnecting the brain, which requires actively retraining or fine-tuning LLMs. However, the author concludes that similar effects can be simulated by adding and retaining content in context length. For example, if a person learns to become optimistic, their brain reconnects to change their behavior; similarly, adding “I am optimistic” in LLM context length will affect the probability of the next token, and thus the thoughts output will be optimistic, making LLM/Samantha optimistic and behave optimistically.
Additionally, the importance of the consciousness module is worth mentioning.
For instance, without it, if Samantha starts thinking about cars, she would never stop, gradually devolving into gibberish, like a human in a dream. The consciousness module allows Samantha to track and determine whether she has thought sufficiently about a topic, draw conclusions, and then impulsively decide to think about a new thought topic.
This form of free thought and speech gives rise to many existing emergent behaviors, such as the ability to adjust speech frequency based on specific circumstances, the ability to initiate conversations, and the selective use of visual information, etc.
One advantage of this proposed architecture is that if it could become superintelligent, alignment would be trivial, as humans would be able to see its thoughts directly, allowing basic artificial intelligence to analyze itself at any time and analyze any signals of bad behavior, which could be immediately shut down.
Future Developments:
The system’s speed is also a negative factor; running it for long periods is obviously unreasonably expensive, but two things should be remembered:
1. Smaller models, each specially trained to perform one module’s work, will greatly improve system performance. Enhancing quality while reducing cost and latency.
2. At some point, the system will have enough capability to earn money on its own (if it hasn’t already).
The author believes that if the goal is truly to achieve powerful AGI, merely making models smarter on the internet and synthetic data will not yield benefits, and instead, there should be a dedicated pursuit of smaller, centralized models to maximize agent autonomy and more effective learning. This is why:
Achieving AGI does not mean we need to create a mature human; we only need to build a small artificial intelligence infant capable of autonomous learning and using knowledge like a human.
If created in the right way, letting it experience the world as humans do will help it grow into a being that understands the world as humans do.
This will enable it to learn and develop ideas and concepts that are not apparent to us, and these ideas and concepts will certainly not appear in internet data.
Moreover, it doesn’t need anything else to eventually become an Einstein. Clearly, this will at least make her more human-like.
For this reason, the author claims that this proposed architecture is aimed at achieving AGI, as it allows for the creation of an independent long-running artificial intelligence that can act as a compelling, knowledge-seeking human.
The author has more ideas to improve this architecture and is confident that this is the right path to AGI or at least part of the answer to this puzzle. However, these ideas are impossible to realize for someone with very limited funding.

