
It can generate realistic portrait videos based on a character image and motion signals (such as pure audio, pure video, or a combination of audio and video). OmniHuman employs a novel multimodal motion condition mixing training strategy, allowing the model to leverage larger-scale data for training, thus addressing the previous shortcomings of end-to-end methods due to the scarcity of high-quality data. Compared to existing end-to-end audio-driven methods, OmniHuman not only generates more realistic images but also offers richer input methods and greater flexibility..
01 Technical Principles
—
The OmniHuman framework consists of two core parts:
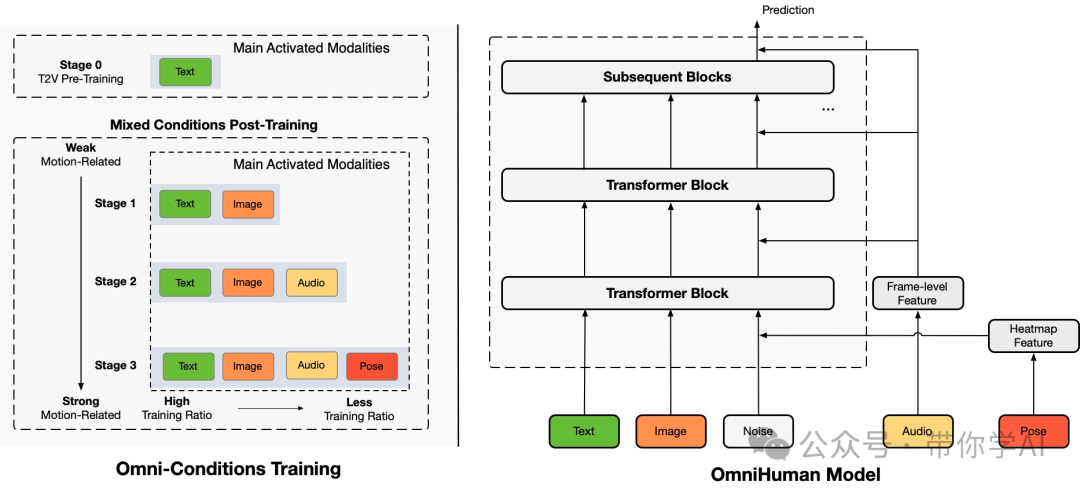
OmniHuman Model: Based on the DiT (Diffusion Transformer) architecture, it can simultaneously receive multiple modal inputs for control, including text, images, audio, and poses, thereby generating realistic portrait videos.
Comprehensive Conditional Training Strategy: Adopts a progressive, multi-stage training approach, training in stages based on the degree of influence of different conditions on motion. Through this mixed conditional training, the OmniHuman model can fully utilize large-scale, diverse data, enhancing generation quality and making videos more natural and smooth.
OmniHuman supports various visual and audio styles, capable of generating portrait videos of various proportions and body shapes (such as headshots, half-length, full-length, etc.), unrestricted by image size. Its realistic effects come from optimizations in multiple aspects, including character motion, lighting effects, and texture details, making the generated videos more natural and vivid.
02 Demonstration Effects
—
Singing Function: OmniHuman supports various music styles, adapting to different body postures and singing methods. It can handle high-pitched songs and display differing motion styles based on different types of music.
OmniHuman supports any proportion of images in voice input and significantly improves gesture handling, which is a challenge for existing methods. It can generate highly realistic effects.
Diversity In terms of input diversity, OmniHuman supports cartoon characters, artificial objects, animals, and complex poses, ensuring that the generated motion features match the unique characteristics of each style.
Compatibility with Video Driving: Because OmniHuman uses mixed conditional training, it not only supports audio-driven, but also video-driven, mimicking actions from specific videos, and can combine audio and video driving, controlling specific body parts.
https://arxiv.org/abs/2502.01061
Welcome to discuss~ Let’s learn about AI and understand AI
Let’s learn about AI and understand AI
