
OmniHuman-1 is an end-to-end multimodal conditional human video generation framework proposed by ByteDance, capable of generating realistic human videos based on a single human image and motion signals (such as audio, video, or a combination of both). Currently, OmniHuman-1 does not provide a public API or download channel, only a paper.
Diverse Video Generation Capabilities
Its realism stems from the comprehensive enhancement of motion, lighting, and texture details, with the main features as follows:
-
Supports Various Visual and Audio Styles: Can generate human videos in different styles with just a single input image and audio (except for some video-driven examples). -
Adapts to Various Aspect Ratios: Can handle videos of different aspect ratios, such as portrait, half-body, full-body, suitable for various application scenarios.
Core Innovations
-
Multimodal Motion Condition Mixing Training Strategy:
-
Through a mixed training strategy, the model can utilize data from different modalities (audio, video, etc.) for training, improving data utilization efficiency. -
This method overcomes the limitations of previous end-to-end methods due to the scarcity of high-quality data.
More Realistic Video Generation:
-
Compared to existing methods, OmniHuman can generate highly realistic human videos based on weaker input signals (especially audio). -
It supports input images of any aspect ratio, including portrait, half-body, and full-body photos, adapting to different scene requirements.
Specific Function Demonstration
Voice-Driven (Talking)
-
Supports input images of any aspect ratio. -
Compared to existing methods, significantly improves gesture handling, allowing characters in the video to naturally coordinate gestures with speech. -
The test audio and image portions come from public datasets (such as TED, Pexels, AIGC).
Diversity
-
Can handle cartoon characters, artificial objects, animals, and even complex poses, ensuring motion matches the unique characteristics of each style.
More Half-body Cases with Hands
-
Additional demonstrations of half-body video cases with gestures, emphasizing the fluidity and realism of hand movements.
More Portrait Cases
-
This section focuses on the testing results of portrait aspect ratios, using samples from the CelebV-HQ dataset for experiments.
Singing
-
Applicable to various music styles, body postures, and singing methods, even able to adapt to high-pitched songs and adjust motion styles according to different music types. -
The generation quality is closely related to the quality of the reference image.
Video Driving Compatibility
-
Due to the mixed conditional training strategy, OmniHuman supports not only audio-driven but also video-driven, mimicking actions from specific videos. -
It even supports joint audio + video driving, controlling the movements of specific body parts.
Technical Architecture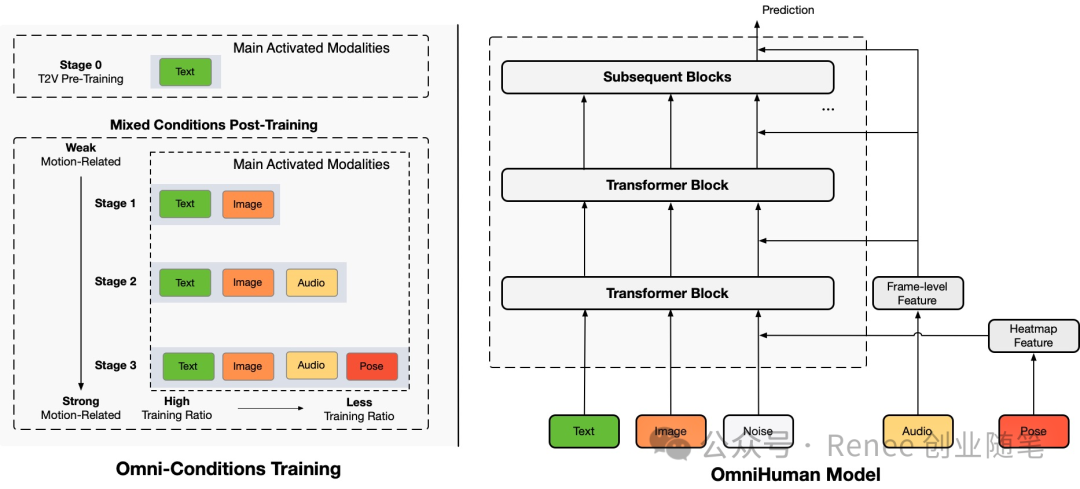
OmniHuman consists of two core components:
-
OmniHuman Model
-
Based on the DiT (Diffusion Transformer) architecture. -
Supports text, images, audio, poses, and other multimodal conditional inputs, and can simultaneously fuse multiple modalities for control.
Omni-conditions Training Strategy
-
Employs a progressive, multi-stage training approach, gradually optimizing model capabilities based on the complexity of motion-related conditions. -
Through mixed conditional training, utilizes large-scale multimodal data to enhance the model’s generalization ability, improving the realism and stability of generated videos.
This architecture ensures that OmniHuman can generate high-quality, naturally flowing human videos under various input conditions.