
Source | Li rumor
Hello, fellow members, I am rumor.
Perhaps due to contrastive learning, the field of text representation has suddenly become competitive this year, with SOTA being updated rapidly. I am still at the stage of our ConSERT, while others have already surpassed it without fine-tuning. Yesterday, an intern sent me several submissions to ACL on Open Review, one of the models with the best performance stated in its abstract:
“Even a non-fine-tuned method can outperform fine-tuned methods like unsupervised ConSERT on STS tasks.”
Alright, you are impressive; can I not read it?

This article is called PromptBERT, which directly improves upon SimCSE with more than two points in an unsupervised manner:
PromptBERT: Improving BERT Sentence Embeddings with Prompts
https://openreview.net/forum?id=7I3KTEhKaAK
The core idea of the method is quite simple and consists of two steps:
-
Generate sentence representations using prompts, for example, [X] means [MASK], where [X] is the input sentence and [MASK] is the output representation, using this as the sentence representation.
-
Use different prompt templates to generate views for contrastive learning, continuing to train in a self-supervised manner.
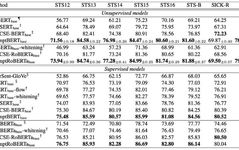
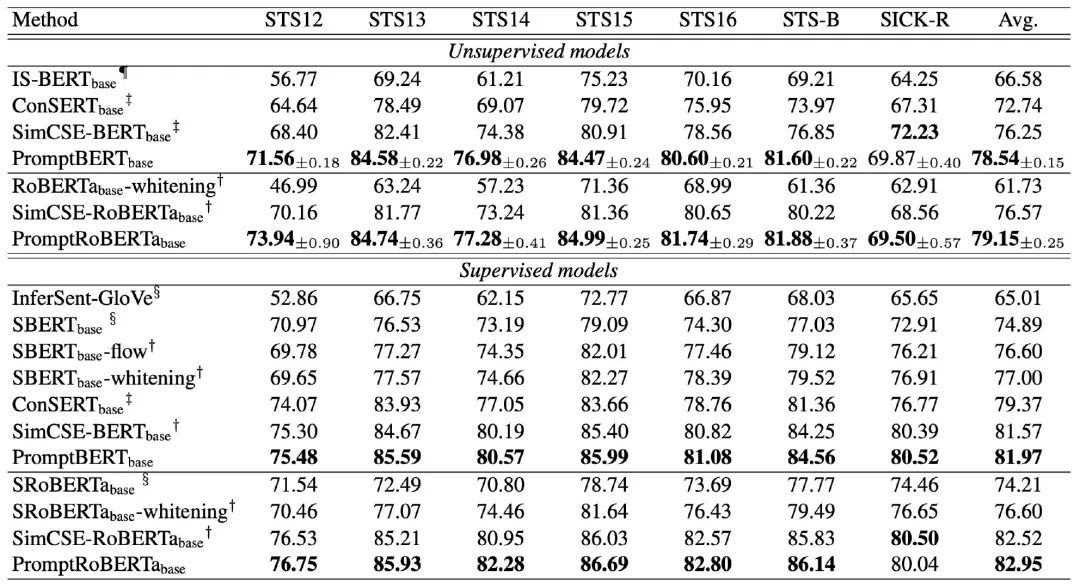
The improvements brought by the above two steps are complementary; first, the representations generated after adding prompts are better than BERT-flow, BERT-whitening, and ConSERT:
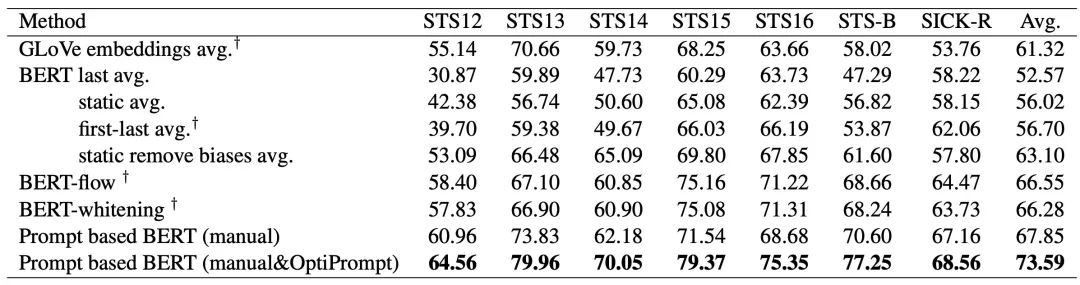
Note: OptiPrompt is a parameterized prompt, but the authors ultimately used a manual prompt in their final experiments.
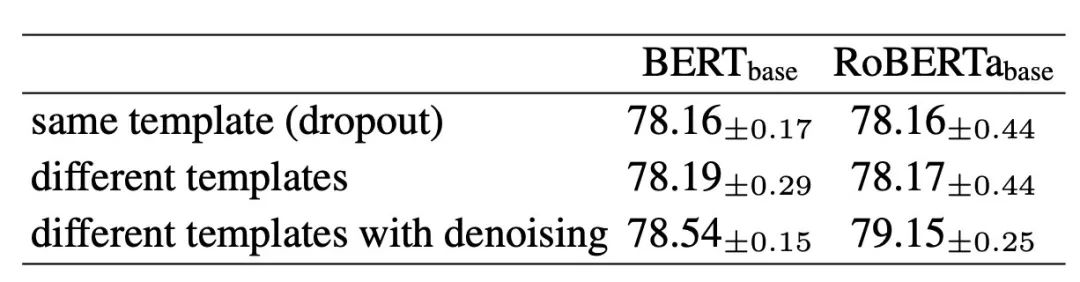
With the addition of unsupervised training via contrastive learning, the performance has improved even further (as shown in the image at the beginning). However, based on the ablation experiments of the training objectives, it can be inferred that the main improvement still comes from the method of generating sentence representations using prompts, while the enhancement from using different templates for contrastive learning is actually limited (first row SimCSE settings vs second row):
Why Prompt Works
The numerous experimental results listed above actually illustrate the core idea of this article, which is to use prompts to generate sentence representations. So why do the representations produced this way perform well?
The authors believe that the poor performance of native BERT is mainly due to biases caused by token frequency, case sensitivity, subwords, etc., and that BERT’s various layers of Transformers do not correct this issue. By utilizing prompts, it is possible to make more effective use of the knowledge contained in the various layers of BERT, and using [MASK] to represent embeddings can avoid the averaging of various tokens as done previously, thus avoiding biases introduced by tokens.
To validate this hypothesis, PromptBERT conducted a number of analyses at the beginning:
-
Through experiments, it was shown that the embedding layer performs even better than the last layer, proving that BERT’s various layers are inefficient for text representation tasks.
-
Previous works suggested that the poor performance of native BERT was mainly due to anisotropy in the representation space (cone-shaped), which is caused by biases such as word frequency. However, the authors, through some experiments, believe that anisotropy and bias are not related, so the issue of bias remains to be addressed.
Conclusion
Overall, the combination of Prompt and contrastive learning is quite ingenious. I previously wondered how to use prompts for representations, but I didn’t expect it to work this way. . Additionally, the author’s experiments regarding anisotropy and bias are quite enlightening. In the appendix, the authors also show through experiments that if the embedding layer and softMax layer do not undergo weight tying, it will significantly reduce bias.
. Additionally, the author’s experiments regarding anisotropy and bias are quite enlightening. In the appendix, the authors also show through experiments that if the embedding layer and softMax layer do not undergo weight tying, it will significantly reduce bias.
However, there is no direct experiment indicating that PromptBERT reduces bias. Moreover, although the authors’ exploration of prompts at the early stage was thorough (attempting templates generated by T5 and parameterized templates), it is unclear why they ultimately chose manual templates. Another question is that PromptBERT only conducted experiments on the base model, while we all know that prompts work better with larger models. Generally, the prompt papers I have seen start with large models, so it is quite surprising that such good results were achieved with the base model.
Technical Group Invitation

Scan the QR code to add the assistant on WeChat