
(For algorithm enthusiasts, master your programming skills)
Source: cnbeta
www.cnbeta.com/articles/tech/858123.htm
According to foreign media reports, a new technology now allows you to add, delete, or edit the words spoken by a speaker in a video, and all of this is as easy as editing text in a word processor. A new deepfake algorithm has been developed that can process audio and video into a new file.

The algorithm was developed by a research team from Stanford University, the Max Planck Institute for Informatics, Princeton University, and Adobe Research.
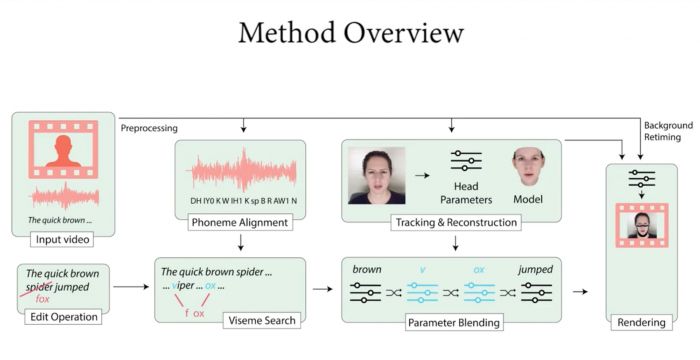
To learn the facial movements of the speaker, the algorithm requires about 40 minutes of training video and the speaker’s transcript, so to achieve good results, you cannot just use a short video. Forty minutes allows the algorithm to accurately calculate the facial shapes the subject makes for each phoneme in the original script.
Based on this, when people edit the script, the algorithm can create a 3D model of the face and generate the desired new shapes. A machine learning technique called Neural Rendering can render the 3D model with realistic textures, making it look almost indistinguishable from a real object.
However, the research team is also aware of the potential unethical uses of this algorithm. Although there has not yet been a deepfake scandal in the world, it is not hard to imagine that deepfakes are an extremely effective deception tool in front of uneducated audiences. More concerning is that their existence could lead dishonest public figures to deny or question real videos that might affect their personal image.
In response, the research team proposed a solution where anyone using the software can optionally add a watermark and provide the complete editing file, but this is clearly not the most effective way to prevent misuse.
Additionally, the team also suggested that other researchers develop better forensic technologies to determine whether a video has been altered by malicious individuals. In fact, blockchain-style permanent records have some potential here, allowing any video to revert to its original state for comparison. However, such technology is not yet in place, and it is unclear how to implement it globally.
In terms of non-fingerprint recognition, many deep learning applications are already researching how to identify counterfeits. By using Generative Adversarial Networks, two networks compete against each other—one generates a counterfeit product while the other tries to identify the fake from the genuine article. Through continuous learning, the identification network starts to improve in recognizing counterfeits, and as it gets better, the network generating counterfeits must also improve to achieve its deceptive goals.
Therefore, as these systems get better at automatically identifying fake videos, the fake videos will also become better. It is clear that identifying forged videos is a complex and serious issue that will almost certainly have a significant impact on news reporting in the coming decades.
Recommended Reading
(Click the title to jump to read)
Plain Language Explanation of Simulated Annealing Algorithm
Classification Algorithm: Bayesian Networks
If you find this article helpful, please share it with more people.
Follow ‘Algorithm Enthusiasts’ and bookmark to master your programming skills

Good article, I’m reading it ❤️