
Persisting with originality, click the blue text above to followme!
Computer Vision is an important field of artificial intelligence technology. To put it metaphorically (though not necessarily accurately), I believe computer vision is the eye of the artificial intelligence era, highlighting its significance. Computer vision is actually a grand concept, and the image below summarizes the skill tree needed for computer vision.
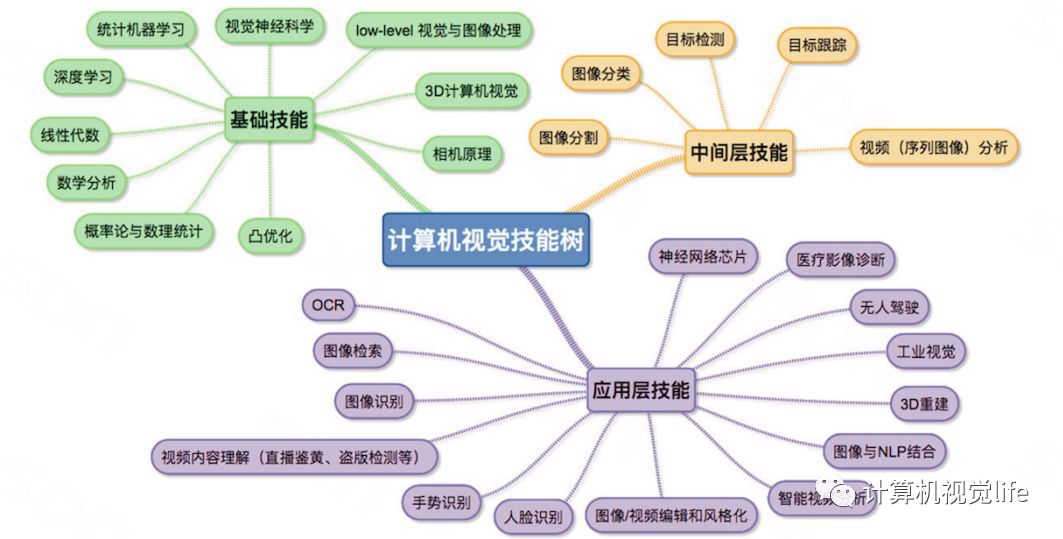
If you are a complete novice to computer vision, don’t be intimidated by this skill tree. No one can master all the skills listed above simultaneously; this tree merely provides a superficial understanding of computer vision.
Let’s get motivated and see what computer vision can do. The video below showcases the practical applications of computer vision in autonomous driving, involving key technologies such as stereo vision, optical flow estimation, visual odometry, 3D object detection and recognition, and 3D object tracking.
Here, I present a relatively easy approach to getting started with computer vision from a beginner’s perspective.
Macro Understanding
Beginners often feel overwhelmed when they see so many subfields. Should they learn facial recognition, object tracking, computational photography, or 3D reconstruction? It’s hard to know where to start. In fact, many of these subfields share common knowledge. My advice is that only by having a preliminary and comprehensive understanding of the field of computer vision can you find a research direction that interests you based on practical problems, and interest can help a self-taught novice overcome difficulties and keep going.
1
Introductory Books
Since we are discussing getting started, I won’t recommend classics like “Multiple View Geometry in Computer Vision” that might discourage beginners.
Pixel-level image processing knowledge is the foundational knowledge of computer vision. Regardless of which subfield of computer vision you pursue, these foundational concepts are essential. Even for an eager beginner, this stage must be approached with diligence. Some online sources suggest starting directly with a project and learning as you go, which can be quick. I partially agree with this, as it overlooks the importance of foundational knowledge. Without basic terminology and conceptual knowledge, many problems cannot be expressed properly, and when encountering issues, one wouldn’t know how to search for solutions, significantly slowing progress and hindering deeper research; haste makes waste.
To learn the basics of image processing, one should not dive straight into textbooks; otherwise, a few formulas and terms might overwhelm a novice. I recommend two approaches that are practical and theory-combined: one is OpenCV, and the other is MATLAB.
OpenCV is based on C++, requires some programming background, is highly portable, and runs quickly, making it suitable for practical engineering projects and widely used in companies; MATLAB only requires a very basic programming background to get started quickly, is convenient for implementation, has concise code, and offers a wealth of reference materials, making it easy to quickly test the effects of certain algorithms, suitable for academic research. Of course, using both together is even better. Below, I will introduce each one.
Learning Image Processing with MATLAB
I recommend using Gonzalez’s “Digital Image Processing (MATLAB Edition)” (originally published in English in 2001, translated into Chinese in 2005). You don’t need to go through the entire book at once; just learn the basic principles, image transformations, morphological processing, and image segmentation using MATLAB. It is strongly recommended to manually type the code for the above chapters (the effect is completely different from just reading), while the other chapters can be skimmed. However, this book focuses more on practice and provides less theoretical explanation, so if you find the theoretical parts unclear, you can refer to Gonzalez’s “Digital Image Processing (Second Edition)” as a supplementary tool, which is mainly for reference to know where to look for related terminology in the future.

Learning Image Processing with OpenCV
OpenCV (Open Source Computer Vision Library) is an open-source cross-platform computer vision library primarily written in C++, containing over 500 general algorithms for image/video processing and computer vision.
For learning OpenCV, you can refer to either “Learning OpenCV” or “OpenCV 2 Computer Vision Programming Handbook.” Both of these are practice-oriented books with less theoretical knowledge. By following the steps outlined in the book, you can quickly grasp the power of OpenCV. To achieve a certain functionality, you just need to learn how to look up functions (on https://www.docs.opencv.org for the corresponding version) and call them, making it easy to get things done. Each example has very intuitive visual output, making learning fun and engaging.

2
Advanced Books
After learning the basics of image processing, beginners will have a grasp of foundational knowledge and be able to use OpenCV or MATLAB to implement simple functions. However, this knowledge is too thin and somewhat outdated; there is still a wealth of new knowledge in the field of computer vision waiting for you.
Again, I provide you with two options, and of course, choosing both is better. One book is “Computer Vision: Algorithms and Applications” written by Richard Szeliski from the University of Washington, published in 2010; the other is “Computer Vision: Algorithms and Applications” by Simon J.D. Prince from the University of Toronto, published in 2012. The two books focus on different aspects: the former emphasizes visual and geometric knowledge, while the latter focuses on machine learning models. Of course, both books have overlapping content. Although both have Chinese versions, if you have a certain level of English reading ability, I recommend reading the original English versions (see the end for acquisition methods). The foreign authors’ books are rich in illustrations and examples, which are beneficial for understanding.

“Computer Vision: Algorithms and Applications”
This book beautifully introduces many major directions in the field of computer vision. With the foundation from “Digital Image Processing,” you will find some content familiar and feel less intimidated. Compared to the previous foundational image processing, this book adds many new topics, such as feature detection and matching, structure from motion, dense motion estimation, image stitching, computational photography, stereo matching, 3D reconstruction, etc., which are currently very popular and practical directions. If you have time, you can browse the entire book; if time is limited, you can selectively read sections that interest you. The Chinese translation of this book is not very good, so it is advisable to refer to the original English version.
“Computer Vision: Models, Learning, and Inference”
This book starts with basic probabilistic models and covers commonly used probabilistic models, regression and classification models, graphical models, optimization methods, as well as lower-level image processing and multi-view geometric knowledge. It is richly illustrated and includes many examples and applications, making it very suitable for beginners. You can download the e-book for free from its homepage:
http://www.computervisionmodels.com/
Additionally, there are many rich learning resources, including PPTs for teachers, open-source projects corresponding to each chapter, code, and dataset links, all of which are very useful.

Deep Practical Engagement
Once you have a relatively macro understanding of the field of computer vision, the next step is to choose a specific area that interests you to delve into. This stage is specifically about programming practice. During practice, if you have questions, look up the relevant terminology in books and combine that with Google, which should help you solve most of your problems.
So, what specific direction should you choose?
If your lab or company has an actual project, it is best to choose to delve into the current project direction. If there is no specific direction, then keep reading.
I personally believe computer vision can be divided into two major directions: learning-based methods and geometry-based methods. Among them, the most popular learning-based method is deep learning, while the most popular geometry-based method is visual SLAM. Below, I will provide a relatively easy entry point for these two directions.
1
Deep Learning
The concept of Deep Learning was proposed by Hinton et al. in 2006, and its earliest and most successful application area is computer vision. The classic convolutional neural network was specifically designed for processing image data. Currently, deep learning is widely applied in computer vision, speech recognition, natural language processing, intelligent recommendation, and other fields.
Learning deep learning requires a certain level of mathematical foundation, including calculus and linear algebra. Many novices recall nightmares from these courses during university, but in reality, only very basic concepts are needed, so there’s no need to worry. However, if you dive straight into textbooks, you may feel overwhelmed and give up early.
Andrew Ng’s deep learning video course is an excellent entry resource, as he is a professor at Stanford University and understands students well. He explains concepts clearly and engagingly, starting from the basics of derivatives, which is quite rare.

This course can be watched for free on NetEase Cloud Courses, with Chinese subtitles, but no accompanying exercises. It is also available on Coursera, the online education platform founded by Andrew Ng, with accompanying exercises, limited time free access, and a certificate upon completion.
This course is very popular, so there’s no need to worry about not understanding it; there are countless study notes available online for reference. It’s truly an essential resource for beginners.
2
Visual SLAM
SLAM (Simultaneous Localization and Mapping) is a technology that creates a map and localizes the agent simultaneously. Visual SLAM uses cameras as the primary sensors and the video streams captured as input to implement SLAM. Visual SLAM is widely applied in cutting-edge fields such as VR/AR, autonomous driving, intelligent robotics, and drones.
The best introductory resource for visual SLAM is “Visual SLAM: Theory and Practice” by Gao Xiang (a PhD from Tsinghua University and a postdoc at the Technical University of Munich). Each chapter covers basic theory and code examples, making it very accessible and emphasizing the combination of theory and practice, greatly lowering the learning barrier for novices.

Alright, that’s the introduction to getting started. You can now begin your learning journey in computer vision!
Friendly reminder: For some of the books and materials mentioned in this article, “Computer Vision Life” has prepared them for you. Reply ‘Entry’ below the public account to obtain them.

Related Reading
2017 Computer Vision Startup Investment Status and Future Trends
Deep Learning + Geometric Structure: 1 + 1 > 2?
Introduction to SLAM
Note: Original work is not easy; please contact [email protected] for reprints, indicating the source. Infringement will be pursued.

