

From DETR to ViT, various works have validated the potential of Transformers in the field of computer vision. Naturally, this raises a new question: which is better for image feature extraction, CNN or Transformer?
The advantage of CNN lies in parameter sharing and focusing on the aggregation of local information, while the advantage of Transformer lies in its global receptive field, focusing on the aggregation of global information. Intuitively, both global and local information aggregation are useful, and effectively combining global and local information aggregation may be the right direction for designing the best network architecture.
How to effectively combine global and local information has recently been categorized into two main approaches: CNN based and Transformer based. The following mainly analyzes the network architecture design of CNN based and Transformer based, where CNN based involves ResNet and BoTNet, and Transformer based involves ViT and T2T-ViT.
01
Interrelationship of Network Architecture Design
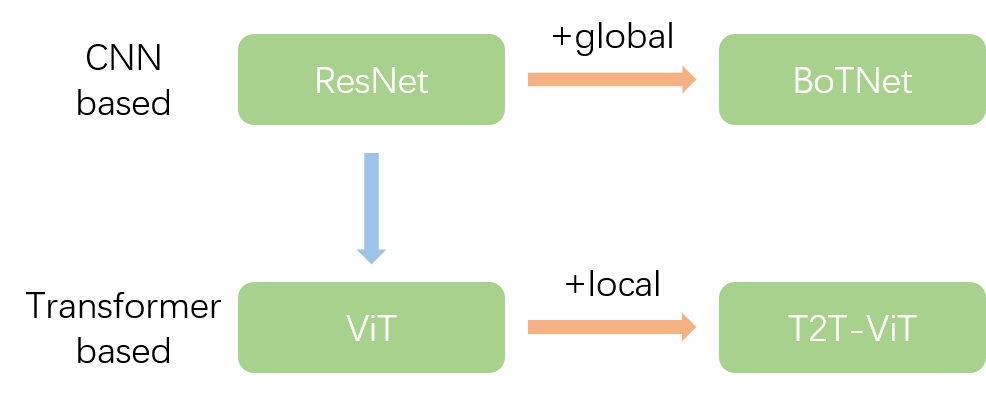
BoTNet replaces the 3×3 convolution in the Bottleneck structure of ResNet with MHSA, enhancing the global information aggregation capability of the CNN based network architecture. T2T-ViT replaces the patch’s linear projection in ViT with T2T, enhancing the local information aggregation capability of the Transformer based network architecture.
02
ResNet & BoTNet
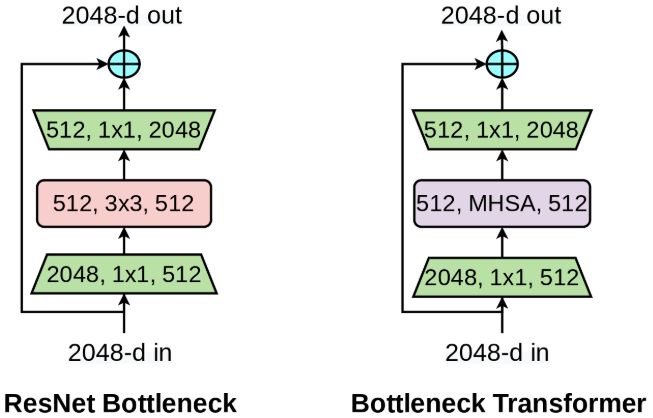
The structural design of ResNet consists mainly of a stack of Bottleneck structures. Each Bottleneck layer is composed of a residual branch formed by stacking 1×1 conv, 3×3 conv, and 1×1 conv, which is then added to the skip connect branch. BoTNet replaces the middle 3×3 conv in the Bottleneck structure with the MHSA structure, which is very similar to previous works like Non-local, essentially introducing global information aggregation into CNN.
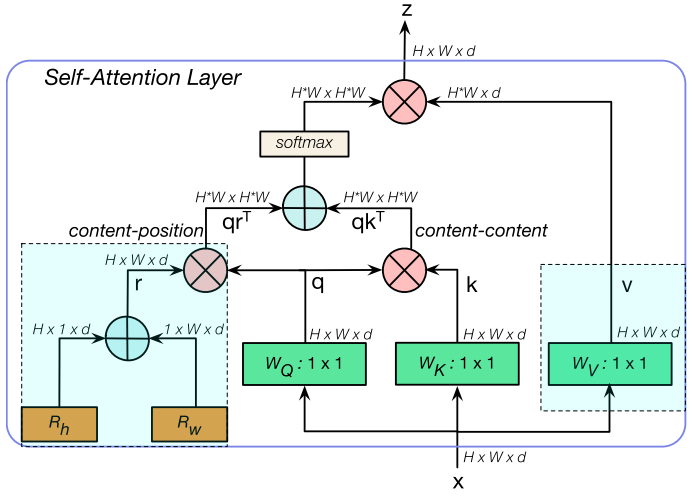
The MHSA structure is shown in the above image, and the code is as follows.
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14):
super(MHSA, self).__init__()
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.rel_h = nn.Parameter(torch.randn([1, n_dims, 1, height]), requires_grad=True)
self.rel_w = nn.Parameter(torch.randn([1, n_dims, width, 1]), requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, C, -1)
k = self.key(x).view(n_batch, C, -1)
v = self.value(x).view(n_batch, C, -1)
content_content = torch.bmm(q.permute(0, 2, 1), k)
content_position = (self.rel_h + self.rel_w).view(1, C, -1).permute(0, 2, 1)
content_position = torch.matmul(content_position, q)
energy = content_content + content_position
attention = self.softmax(energy)
out = torch.bmm(v, attention.permute(0, 2, 1))
out = out.view(n_batch, C, width, height)
return outSimilar to the multi-head self-attention in Transformers, the difference lies in that MHSA treats position encoding as spatial attention, embedding two learnable vectors as spatial attention across the two dimensions, and then multiplying the fused spatial vector with q to obtain content-position (essentially introducing spatial priors), allowing MHSA to focus on appropriate areas, making it easier to converge. Another difference is that MHSA introduces multi-head only in the blue block section.
03
ViT
ViT is the first paper to purely apply Transformers for image feature extraction.
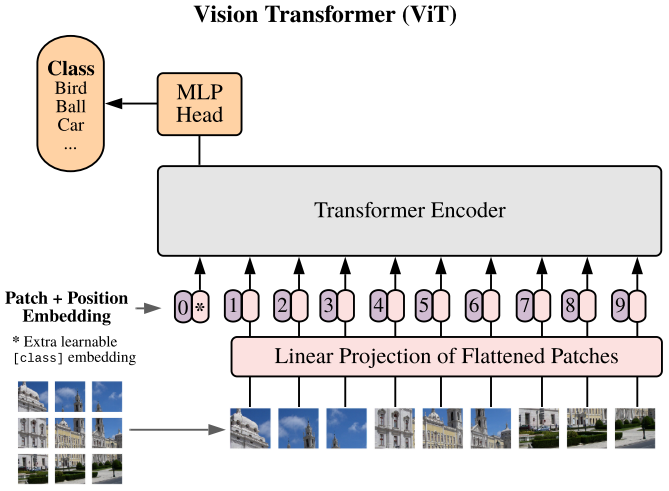
The Vision Transformer (ViT) splits the input image into 16×16 patches, performs a linear transformation for dimensionality reduction while embedding positional information for each patch, and then feeds it into the Transformer. Similar to the [class] token setting in BERT, ViT adds an extra learnable [class] token at the beginning of the Transformer input sequence, and the output of the Transformer Encoder at this position serves as the image feature.
Assuming the input image size is 256×256, and we plan to split it into 64 patches, each patch being 32×32 pixels.
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)
# Transform 3072 into dim, assuming it is 1024
self.patch_to_embedding = nn.Linear(patch_dim, dim)
x = self.patch_to_embedding(x)This implementation uses Einstein notation, specifically utilizing the einops library, which integrates various operators, with rearrange being one of them, making it very efficient. p represents the patch size; assuming the input is b,3,256,256, the rearrange operation first transforms it to (b,3,8×32,8×32), and finally to (b,8×8,32x32x3) or (b,64,3072), splitting each image into 64 small pieces, each of length 32x32x3=3072. This means that the input sequence of length 64 for the image is encoded with a length of 3072 for each element. Considering that 3072 is a bit large, ViT uses linear projection for dimensionality reduction of the image sequence encoding.
04
T2T-ViT
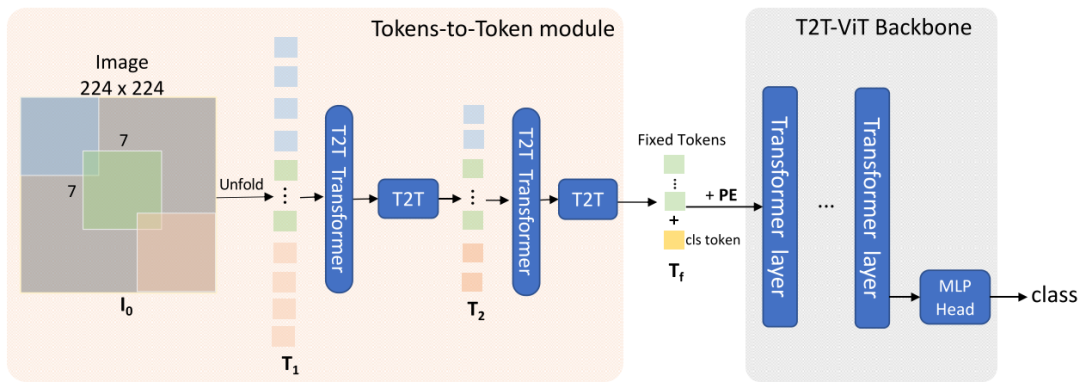
Although ViT has validated the potential of Transformers in image classification network architecture design, it requires additional large-scale data for pre-training, and its performance on medium-scale datasets like ImageNet is not ideal. T2T-ViT introduces local information aggregation to enhance ViT’s local structural modeling capability, allowing T2T-ViT to achieve higher accuracy when trained on medium-scale ImageNet.
In the T2T module, the input image is first soft-split into small blocks, which are then unfolded into a token sequence T0. The length of the tokens is gradually reduced in the T2T module (the article uses two iterations before outputting Tf). The subsequent process is basically consistent with ViT.
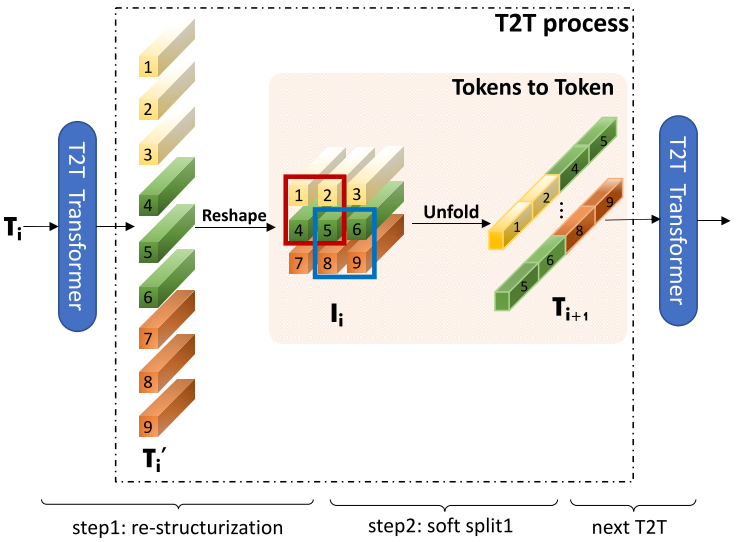
In one iteration, the T2T structure consists of re-structurization and soft split, where re-structurization reshapes the one-dimensional sequence into a two-dimensional image, and soft split performs a sliding window operation on the two-dimensional image to split it into overlapping blocks.
For example, in the token transformer, the input image is first split into overlapping blocks of 7×7, then processed through the token transformer for global information aggregation within the blocks, followed by re-structurization and soft split to reorganize and split into overlapping blocks of 3×3, resulting in a shorter token sequence. This process is iterated twice, and finally, linear projection further reduces the length of the token sequence.
class T2T_module(nn.Module):
"""
Tokens-to-Token encoding module
"""
def __init__(self, img_size=224, in_chans=3, embed_dim=768, token_dim=64):
super().__init__()
self.soft_split0 = nn.Unfold(kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))
self.soft_split1 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.soft_split2 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.attention1 = Token_transformer(dim=in_chans * 7 * 7, in_dim=token_dim, num_heads=1, mlp_ratio=1.0)
self.attention2 = Token_transformer(dim=token_dim * 3 * 3, in_dim=token_dim, num_heads=1, mlp_ratio=1.0)
self.project = nn.Linear(token_dim * 3 * 3, embed_dim)
self.num_patches = (img_size // (4 * 2 * 2)) * (img_size // (4 * 2 * 2)) # there are 3 soft split, stride are 4,2,2 separately
def forward(self, x):
# step0: soft split
x = self.soft_split0(x).transpose(1, 2)
# iteration1: restricturization/reconstruction
x = self.attention1(x)
B, new_HW, C = x.shape
x = x.transpose(1,2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
# iteration1: soft split
x = self.soft_split1(x).transpose(1, 2)
# iteration2: restricturization/reconstruction
x = self.attention2(x)
B, new_HW, C = x.shape
x = x.transpose(1, 2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
# iteration2: soft split
x = self.soft_split2(x).transpose(1, 2)
# final tokens
x = self.project(x)
return x05
Summary
1. The relationship between global and local information aggregation.
Global and local should complement each other to balance speed and accuracy, while improving the upper limits of both speed and accuracy.
2. The relationship between CNN based and Transformer based approaches, which is better?
Essentially, the question is whether the network architecture design should primarily focus on CNN or Transformer. CNN focuses on treating the input as a two-dimensional image signal, while Transformer treats the input as a one-dimensional sequence signal. Therefore, to clarify whether CNN or Transformer is better, it is necessary to explore which input signal has more advantages. Previous research has indicated that CNN’s padding might reveal positional information, while Transformers, lacking inductive bias, require position encoding to introduce positional information. Both CNN and Transformer have their pros and cons, and there is currently no conclusive answer; we will have to observe future developments.
References
[1] Deep Residual Learning for Image Recognition
[2] Bottleneck Transformers for Visual Recognition
[3] An image is worth 16×16 words: Transformers for image recognition at scale
[4] Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Download 1: Four Piece Set
Reply "Four Piece Set" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to obtain learning resources for TensorFlow, Pytorch, machine learning, and deep learning!
Download 2: Repository Address Sharing
Reply "Code" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to obtain 195 NAACL + 295 ACL2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Heavy! The Machine Learning Algorithms and Natural Language Processing exchange group has officially been established! There are plenty of resources in the group, and everyone is welcome to join for learning!
Extra benefits! Deep learning and neural networks, official Chinese tutorials for Pytorch, data analysis using Python, machine learning study notes, official Chinese documentation for pandas, effective java (Chinese version), and 20 other benefit resources.
How to get: After entering the group, click on the group announcement to get the download link. Please modify the remark when adding as [School/Company + Name + Direction] For example - Harbin Institute of Technology + Zhang San + Dialogue System. The account owner and WeChat sellers, please consciously avoid. Thank you!
Recommended Reading:
Implementation of NCE-Loss in Tensorflow and word2vec
Overview of Multimodal Deep Learning: Summary of Network Structure Design and Modal Fusion Methods
Awesome-Adversarial-Machine-Learning Resource List