
Source: DeepHub IMBA
This article is approximately 2000 words long and is recommended to be read in 9 minutes.
Understanding and utilizing multiprocessing techniques are essential for optimizing performance in PyTorch.
PyTorch is a popular deep learning framework that is very convenient when using a single GPU for computation. However, when it comes to handling large-scale data and parallel processing, multiple GPUs need to be utilized. This is where PyTorch becomes less convenient, so in this article, we will introduce how to implement efficient multiprocessing in PyTorch using the torch.multiprocessing module.
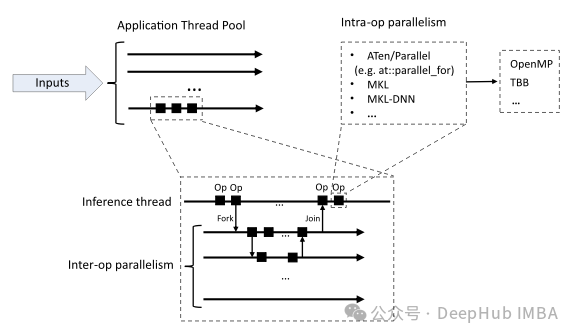
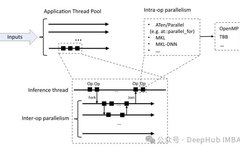
Multiprocessing is a method that allows multiple processes to run concurrently, utilizing multiple CPU cores and GPUs for parallel computation. This can significantly improve the performance of tasks such as data loading, model training, and inference. PyTorch provides the torch.multiprocessing module to address this issue.
Importing Libraries
import torch import torch.multiprocessing as mp from torch import nn, optim
For multiprocessing, we mainly need to address two aspects: 1. Data loading; 2. Distributed training.
Data Loading
Loading and preprocessing large datasets can be a bottleneck. Using torch.utils.data.DataLoader with multiple workers can alleviate this problem.
from torch.utils.data import DataLoader, Dataset class CustomDataset(Dataset): def __init__(self, data): self.data = data def __len__(self): return len(self.data) def __getitem__(self, idx): return self.data[idx] data = [i for i in range(1000)] dataset = CustomDataset(data) dataloader = DataLoader(dataset, batch_size=32, num_workers=4) for batch in dataloader: print(batch)
num_workers=4 means that four subprocesses will load data in parallel. This method can be used with a single GPU, and by increasing the number of data loading processes, the speed of data reading can be accelerated, improving training efficiency.
Distributed Training
Distributed training involves spreading the training process across multiple devices. torch.multiprocessing can be used to achieve this.
Our typical training process is as follows:
class SimpleModel(nn.Module): def __init__(self): super(SimpleModel, self).__init__() self.fc = nn.Linear(10, 1) def forward(self, x): return self.fc(x) def train(rank, model, data, target, optimizer, criterion, epochs): for epoch in range(epochs): optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() print(f"Process {rank}, Epoch {epoch}, Loss: {loss.item()}")
To modify this process, we first need to initialize and share the model:
def main(): num_processes = 4 data = torch.randn(100, 10) target = torch.randn(100, 1) model = SimpleModel() model.share_memory() # Share the model parameters among processes optimizer = optim.SGD(model.parameters(), lr=0.01) criterion = nn.MSELoss() processes = [] for rank in range(num_processes): p = mp.Process(target=train, args=(rank, model, data, target, optimizer, criterion, 10)) p.start() processes.append(p) for p in processes: p.join() if __name__ == '__main__': main()
In the example above, four processes run the training function simultaneously, sharing model parameters.
For multiple GPUs, distributed data parallel (DDP) training can be used.
For large-scale distributed training, PyTorch’s torch.nn.parallel.DistributedDataParallel (DDP) is highly efficient. DDP can wrap modules and distribute them across multiple processes and GPUs, providing near-linear scaling for training large models.
import torch.distributed as dist from torch.nn.parallel import DistributedDataParallel as DDP
Modify the train function to initialize the process group and wrap the model using DDP.
def train(rank, world_size, data, target, epochs): dist.init_process_group("gloo", rank=rank, world_size=world_size) model = SimpleModel().to(rank) ddp_model = DDP(model, device_ids=[rank]) optimizer = optim.SGD(ddp_model.parameters(), lr=0.01) criterion = nn.MSELoss() for epoch in range(epochs): optimizer.zero_grad() output = ddp_model(data.to(rank)) loss = criterion(output, target.to(rank)) loss.backward() optimizer.step() print(f"Process {rank}, Epoch {epoch}, Loss: {loss.item()}") dist.destroy_process_group()
Modify the main function to add the world_size parameter and adjust process initialization to pass the world_size.
def main(): num_processes = 4 world_size = num_processes data = torch.randn(100, 10) target = torch.randn(100, 1) mp.spawn(train, args=(world_size, data, target, 10), nprocs=num_processes, join=True) if __name__ == '__main__': mp.set_start_method('spawn') main()
This way, training can be conducted on multiple GPUs.
Common Issues and Solutions
1. Avoid Deadlocks
Use mp.set_start_method(‘spawn’) at the beginning of the script to avoid deadlocks.
if __name__ == '__main__': mp.set_start_method('spawn') main()
Because multithreading requires managing resources on its own, ensure to clean up resources to prevent memory leaks.
2. Asynchronous Execution
Asynchronous execution allows processes to run independently and concurrently, typically used for non-blocking operations.
def async_task(rank): print(f"Starting task in process {rank}") # Simulate some work with sleep torch.sleep(1) print(f"Ending task in process {rank}") def main_async(): num_processes = 4 processes = [] for rank in range(num_processes): p = mp.Process(target=async_task, args=(rank,)) p.start() processes.append(p) for p in processes: p.join() if __name__ == '__main__': main_async()
3. Shared Memory Management
Using shared memory allows different processes to handle the same data without copying it, reducing memory overhead and improving performance.
def shared_memory_task(shared_tensor, rank): shared_tensor[rank] = shared_tensor[rank] + rank def main_shared_memory(): shared_tensor = torch.zeros(4, 4).share_memory_() processes = [] for rank in range(4): p = mp.Process(target=shared_memory_task, args=(shared_tensor, rank)) p.start() processes.append(p) for p in processes: p.join() print(shared_tensor) if __name__ == '__main__': main_shared_memory()
The shared tensor shared_tensor can be modified by multiple processes.
Conclusion
Multiprocessing in PyTorch can significantly improve performance, especially when using the torch.multiprocessing module for data loading and distributed training, effectively utilizing multiple CPUs for faster and more efficient computation. Whether you are dealing with large datasets or training complex models, understanding and utilizing multiprocessing techniques are essential for optimizing performance in PyTorch. Using Distributed Data Parallel (DDP) further enhances the ability to scale training across multiple GPUs, making it a powerful tool for large-scale deep learning tasks.
About Us
Data Hub THU, as a data science public account, is backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, striving to build a data talent gathering platform, and creating the strongest group in China’s big data.

Sina Weibo: @Data Hub THU
WeChat Video Number: Data Hub THU
Today’s Headline: Data Hub THU