Selected from Mozilla
Translated by Machine Heart
Contributor: Liu Xiaokun
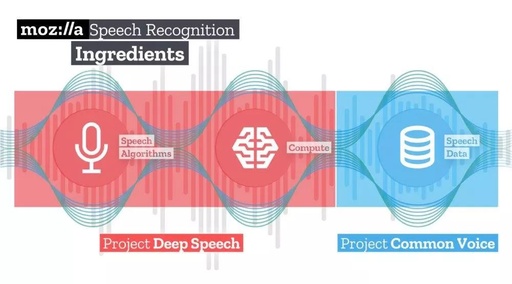
Mozilla has great expectations for the potential of speech recognition, but there are still significant barriers to innovation in this field. These challenges prompted the company to launch the DeepSpeech and Common Voice projects. Recently, they released their open-source speech recognition model for the first time, which boasts a high recognition accuracy. At the same time, the company also released the world’s second-largest public speech dataset, contributed by nearly 20,000 people globally.
-
Open-source speech recognition model: https://hacks.mozilla.org/2017/11/a-journey-to-10-word-error-rate/
-
Public speech dataset: https://medium.com/mozilla-open-innovation/sharing-our-common-
DeepSpeech: An open-source speech-to-text conversion engine that achieves high performance as expected by users
Currently, there are only a few commercial speech recognition services available, dominated by a handful of large companies. This limits the choices and optional features for startups, researchers, and even large companies looking to incorporate speech capabilities into their products and services.
This is also the reason why Mozilla initiated and made DeepSpeech an open-source project. Together with a group of like-minded developers, companies, and researchers, the company built a speech-to-text conversion engine using complex machine learning techniques and developed several new technologies, achieving only a 6.5% word error rate on the LibrSpeech test-clean dataset.
DeepSpeech project link: https://github.com/mozilla/DeepSpeech
Mozilla’s first release of the DeepSpeech product includes pre-built Python packages, NodeJS packages, and a command-line binary, allowing developers to immediately use and experiment with speech recognition.
Common Voice: Building the world’s most diverse public speech dataset and developing optimized speech training techniques

One reason for the scarcity of commercial services is the lack of data. Startups, researchers, or anyone wanting to build technology with speech capabilities need high-quality transcribed speech data to train machine learning algorithms. Currently, they can only access a limited dataset.
To address this issue, Mozilla launched the Common Voice project in July this year (https://voice.mozilla.org/). The goal of the project is to enable people to easily contribute their voice data to a public dataset, thereby creating a speech dataset that everyone can use to train new speech-enabled applications.
This time, Mozilla announced the first part of the contributed dataset: approximately 400,000 recordings, totaling 500 hours in length. Everyone can download it here: https://voice.mozilla.org/data
Mozilla believes that the most important contribution of this dataset is that it shows us the diversity of the entire world—it has over 20,000 contributors, and the new dataset reflects the speech diversity around the globe. Existing speech recognition services often struggle to understand different dialects, and many services perform better in recognizing male voices than female voices, a bias stemming from the training data. Mozilla hopes that the scale of contributors and their diverse backgrounds and dialects can help create a representative global dataset, leading to the development of more inclusive technology.
Although currently primarily in English data, the Common Voice will support contributions in multiple languages in the future, with plans to start in the first half of 2018.
Finally, Mozilla has also collected links to download all currently available large speech datasets to further alleviate the data scarcity issue. 
This article is translated by Machine Heart, please contact this public account for authorizationFor joining Machine Heart (full-time reporters/interns): [email protected]
✄————————————————
For submissions or seeking reports: [email protected]
Advertising & Business Cooperation: [email protected]