Click the above “Getting Started with Vision” to add a Star or “Pin”
Important content delivered immediately
Important content delivered immediately
Due to work requirements, I have recently been supplementing my knowledge in distributed training. After some theoretical study, I still feel unsatisfied, as many knowledge points cannot be accurately grasped (for example: what should the code-level distributed primitives like scatter, all reduce, etc. look like, how the ring all reduce algorithm is used during gradient synchronization, and how the parameter server parameters are partially updated).
The famous physicist and Nobel laureate Richard Feynman wrote on the blackboard in his office: “What I cannot create, I do not understand.” In the programming community, there is often the slogan “show me the code.” Therefore, I plan to write a series of articles on distributed training, presenting previously abstract concepts of distributed training in the form of code, ensuring that each code is executable, verifiable, and reproducible, and contributing the source code for mutual exchange.
Through research, I found that Pytorch has done a great job in abstracting distributed training with a complete interface, so this series of articles will primarily use Pytorch as the framework, and many examples in the article come from Pytorch’s documentation, which have been debugged and expanded upon.
Finally, since there are already many theoretical introductions to distributed training available online, the theoretical part will not be the focus of this series of articles; I will place emphasis on the code-level introduction.
Pytorch – Minimal Experience of Distributed Training: https://zhuanlan.zhihu.com/p/477073906
Pytorch – Distributed Communication Primitives (with source code): https://zhuanlan.zhihu.com/p/478953028
Pytorch – Handwritten allreduce distributed training (with source code): https://zhuanlan.zhihu.com/p/482557067
Pytorch – Minimal Implementation of Operator Parallelism (with source code): https://zhuanlan.zhihu.com/p/483640235
Pytorch – Minimal Implementation of Multi-Machine Multi-Card (with source code): https://zhuanlan.zhihu.com/p/486130584
1. Introduction
Pytorch introduced torchrun in version 1.9.0 to replace torch.distributed.launch from versions prior to 1.9.0. Torchrun mainly adds two functionalities based on torch.distributed.launch:
-
Failover: When a worker fails during training, all workers will automatically restart to continue training; -
Elastic: Nodes can be dynamically added or removed, and this article will illustrate how to use Elastic Training through an example;
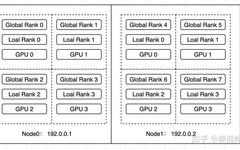
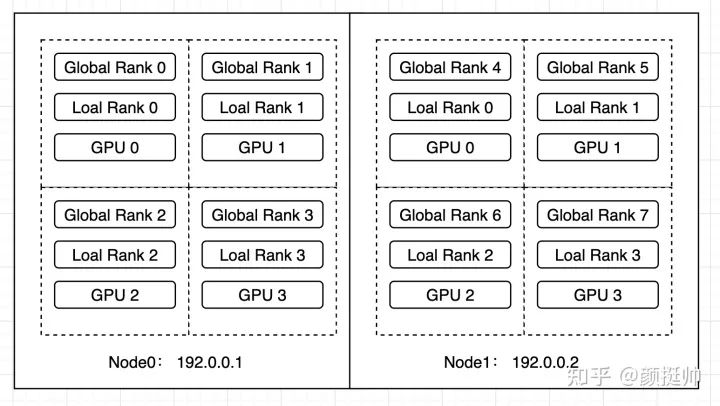
In this example, a worker group of 4 GPUs will first be started on Node0, and after training for a while, another worker group of 4 GPUs will be started on Node1, forming a new worker group together with the workers on Node1, ultimately creating a distributed training environment of 2 machines and 8 cards.
2. Model Construction
A simple fully connected neural network model
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
3. Checkpoint Handling
Since every time a node is added or removed, all workers will be killed and then restarted for training. Therefore, the training state must be saved in the training code to ensure that training can continue from the last state after restarting.
The information that needs to be saved generally includes the following:
-
model: Model parameter information -
optimizer: Optimizer parameter information -
epoch: The current epoch number
The save and load code is as follows:
-
torch.save: Uses Python’s pickle to serialize Python objects and save them to a local file; -
torch.load: Deserializes the local file saved bytorch.saveand loads it into memory; -
model.state_dict():Stores the parameter information of each layer in the model -
optimizer.state_dict():: Stores the parameter information of the optimizer
def save_checkpoint(epoch, model, optimizer, path):
torch.save({
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimize_state_dict": optimizer.state_dict(),
}, path)
def load_checkpoint(path):
checkpoint = torch.load(path)
return checkpoint
4. Training Code
The initialization logic is as follows:
-
Lines 1-3: Output key environment variables of the current worker for subsequent result display -
Lines 5-8: Create model, optimizer, and loss function -
Lines 10-12: Initialize parameter information -
Lines 14-19: If a checkpoint exists, load the checkpoint and assign values to model, optimizer, and first_epoch
local_rank = int(os.environ["LOCAL_RANK"])
rank = int(os.environ["RANK"])
print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) train worker starting...")
model = ToyModel().cuda(local_rank)
ddp_model = DDP(model, [local_rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
max_epoch = 100
first_epoch = 0
ckp_path = "checkpoint.pt"
if os.path.exists(ckp_path):
print(f"load checkpoint from {ckp_path}")
checkpoint = load_checkpoint(ckp_path)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimize_state_dict"])
first_epoch = checkpoint["epoch"]
Training logic:
-
Line 1: The number of epochs executed is from first_epoch to max_epoch, to allow continuing training from the original epoch after the worker is restarted; -
Line 2: To demonstrate the effect of dynamically adding nodes, a sleep function is added to slow down training; -
Lines 3-8: Model training process; -
Line 9: For simplicity, save a checkpoint at the end of each epoch; save the current epoch, model, and optimizer to the checkpoint;
for i in range(first_epoch, max_epoch):
time.sleep(1) # To demonstrate the effect of dynamically adding nodes, a sleep function is added to slow down training
outputs = ddp_model(torch.randn(20, 10).to(local_rank))
labels = torch.randn(20, 5).to(local_rank)
loss = loss_fn(outputs, labels)
loss.backward()
print(f"[{os.getpid()}] epoch {i} (rank = {rank}, local_rank = {local_rank}) loss = {loss.item()}
")
optimizer.step()
save_checkpoint(i, model, optimizer, ckp_path)
5. Startup Method
Since we use torchrun to start multi-machine multi-card tasks, there is no need to use the spawn interface to start multiple processes (torchrun will be responsible for starting our Python script as a process), so we can directly call the train function written above, adding initialization and effect functions of DistributedDataParallel before and after.
The code below describes the call to the train interface written above.
def run():
env_dict = {
key: os.environ[key]
for key in ("MASTER_ADDR", "MASTER_PORT", "WORLD_SIZE", "LOCAL_WORLD_SIZE")
}
print(f"[{os.getpid()}] Initializing process group with: {env_dict}")
dist.init_process_group(backend="nccl")
train()
dist.destroy_process_group()
if __name__ == "__main__":
run()
In this example, torchrun is used to execute the distributed training task of multiple machines and multiple cards (note: torch.distributed.launch has been eliminated by Pytorch, and it is best not to use it anymore). The startup script is described as follows (note: both node0 and node1 are started using this script)
-
--nnodes=1:3: Indicates that the current training task accepts at least 1 node and at most 3 nodes to participate in distributed training; -
--nproc_per_node=4: Indicates that each node has 4 processes; -
--max_restarts=3: The maximum number of restarts for the worker group; note that node fail, node scale down, and node scale up will all cause a restart; -
--rdzv_id=1: A unique job id, all nodes use the same job id; -
--rdzv_backend: The backend implementation for rendezvous, supporting c10d and etcd by default; rendezvous is used for communication and coordination between multiple nodes; -
--rdzv_endpoint: The address for rendezvous, which should be the host IP and port of one node;
torchrun \
--nnodes=1:3 \
--nproc_per_node=4 \
--max_restarts=3 \
--rdzv_id=1 \
--rdzv_backend=c10d \
--rdzv_endpoint="192.0.0.1:1234" \
train_elastic.py
6. Result Analysis
Code: BetterDL – train_elastic.py: https://github.com/tingshua-yts/BetterDL/blob/master/test/pytorch/DDP/train_elastic.py
Running environment: 2 machines with 4 V100 cards each
image: pytorch/pytorch:1.11.0-cuda11.3-cudnn8-runtime
gpu: v100
First, execute the startup script on node0
torchrun \
--nnodes=1:3 \
--nproc_per_node=4 \
--max_restarts=3 \
--rdzv_id=1 \
--rdzv_backend=c10d \
--rdzv_endpoint="192.0.0.1:1234" \
train_elastic.py
The following results are obtained
-
Lines 2-5: The current task started is a single machine with 4 cards, so WORLD_SIZE is 4, and LOCAL_WORLD_SIZE is also 4 -
Lines 6-9: A total of 4 ranks participated in distributed training, rank0~rank3 -
Lines 10-18: rank0~rank3 all start training from epoch=0
r/workspace/DDP# sh run_elastic.sh
[4031] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4029] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4030] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4032] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4029] (rank = 0, local_rank = 0) train worker starting...
[4030] (rank = 1, local_rank = 1) train worker starting...
[4032] (rank = 3, local_rank = 3) train worker starting...
[4031] (rank = 2, local_rank = 2) train worker starting...
[4101] epoch 0 (rank = 1, local_rank = 1) loss = 0.9288564920425415
[4103] epoch 0 (rank = 3, local_rank = 3) loss = 0.9711472988128662
[4102] epoch 0 (rank = 2, local_rank = 2) loss = 1.0727070569992065
[4100] epoch 0 (rank = 0, local_rank = 0) loss = 0.9402943253517151
[4100] epoch 1 (rank = 0, local_rank = 0) loss = 1.0327017307281494
[4101] epoch 1 (rank = 1, local_rank = 1) loss = 1.4485043287277222
[4103] epoch 1 (rank = 3, local_rank = 3) loss = 1.0959293842315674
[4102] epoch 1 (rank = 2, local_rank = 2) loss = 1.0669530630111694
...Execute the same script on node1
torchrun \
--nnodes=1:3 \
--nproc_per_node=4 \
--max_restarts=3 \
--rdzv_id=1 \
--rdzv_backend=c10d \
--rdzv_endpoint="192.0.0.1:1234" \
train_elastic.py
The results on node1 are as follows:
-
Lines 2-5: With the addition of node1, the current task is a distributed training task of 2 machines with 8 cards, so WORLD_SIZE=8, LOCAL_WORLD_SIZE=4 -
Lines 6-9: The ranks of the workers on the current node1 are rank4~rank7 -
Lines 13-20: Since node1 joined the training when node0 was at epoch 35, it continues training from epoch 35
/workspace/DDP# sh run_elastic.sh
[696] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[697] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[695] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[694] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[697] (rank = 7, local_rank = 3) train worker starting...
[695] (rank = 5, local_rank = 1) train worker starting...
[694] (rank = 4, local_rank = 0) train worker starting...
[696] (rank = 6, local_rank = 2) train worker starting...
load checkpoint from checkpoint.ptload checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
[697] epoch 35 (rank = 7, local_rank = 3) loss = 1.1888569593429565
[694] epoch 35 (rank = 4, local_rank = 0) loss = 0.8916441202163696
[695] epoch 35 (rank = 5, local_rank = 1) loss = 1.5685604810714722
[696] epoch 35 (rank = 6, local_rank = 2) loss = 1.11683189868927
[696] epoch 36 (rank = 6, local_rank = 2) loss = 1.3724170923233032
[694] epoch 36 (rank = 4, local_rank = 0) loss = 1.061527967453003
[695] epoch 36 (rank = 5, local_rank = 1) loss = 0.96876460313797
[697] epoch 36 (rank = 7, local_rank = 3) loss = 0.8060566782951355
...The results on node0 are as follows:
-
Lines 6-9: On node0, when executing epoch 35, node1 executed the training script and requested to join the training task -
Lines 10-13: All workers restart; due to the addition of node1, the current task is a distributed training task of 2 machines with 8 cards, so WORLD_SIZE=8, LOCAL_WORLD_SIZE=4 -
Lines 14-17: The ranks of the workers on the current node1 are rank0~rank3 -
Lines 18-21: Loading checkpoint -
Lines 22-30: Continuing training from the checkpoint’s model, optimizer, and epoch
...Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Getting Started with Vision" public account to download the first Chinese version of the OpenCV extension module tutorial on the Internet, covering more than 20 chapters including extension module installation, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of the "Getting Started with Vision" public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, helping you quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the background of the "Getting Started with Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat account below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes, otherwise, you will not be allowed in. After successful addition, you will be invited to the relevant WeChat group based on research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~