
 If you missed the previous article, you can click the title to review.
If you missed the previous article, you can click the title to review.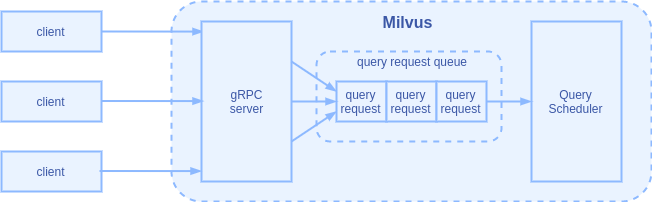
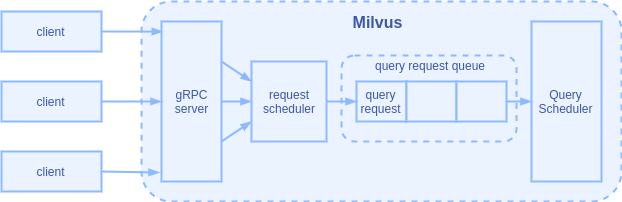
-
The query target is the same collection and queries within the same partition -
The topk parameter difference does not exceed 200 -
The number of target vectors for merging does not exceed 200 -
Other index-related query parameters must be the same, such as nprobe
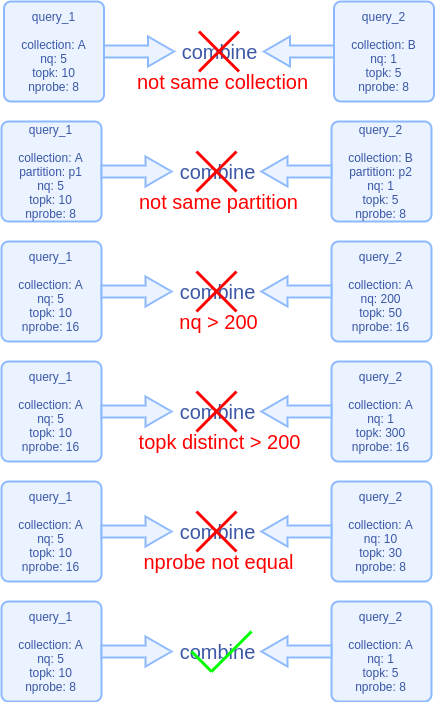
-
The same collection and the same partition limit the search scope, allowing multiple queries to avoid interference only within the same range. -
nq less than 200 ensures that the computation time is not too long, preventing individual requests from waiting too long. -
The topk difference of less than 200 is for the convenience of processing the result set. -
Index-related query parameters must be the same, so that the same process can be followed in the internal ANNS library calculation.
| Hardware Environment | Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz 12 Cores |
| Milvus Version | 0.9.1 GPU version |
| Test Dataset | 10 million 128-dimensional randomly generated vectors |
| Index | IVFSQ8, nlist is 2048 |
| Query Parameters | Execute 1000 queries, nq is 1, topk is 10, nprobe is 16 |
import time
import threading
import numpy as np
from milvus import Milvus, IndexType
from milvus.client.types import MetricType
SERVER_ADDR = "127.0.0.1"
SERVER_PORT = '19530'
COLLECTION_DIMENSION = 128
COLLECTION_NAME = "TEST"
INDEX_TYPE = IndexType.IVF_SQ8
INDEX_PARAM = {'nlist': 2048}
SEARCH_PARAM = {'nprobe': 16}
TOPK = 10
MILVUS = Milvus(host=SERVER_ADDR, port=SERVER_PORT)
def gen_vec_list(nb, seed=np.random.RandomState(1234)):
xb = seed.rand(nb, COLLECTION_DIMENSION).astype("float32")
vec_list = xb.tolist()
return vec_list
def search(vec_list):
status, result = MILVUS.search(collection_name=COLLECTION_NAME, top_k=TOPK,
query_records=vec_list, params=SEARCH_PARAM)
def multi_search():
time_start = time.time()
SEARCH_COUNT = 1000
vec_list = gen_vec_list(1)
for k in range(SEARCH_COUNT):
search(vec_list=vec_list)
time_end = time.time()
total_cost = time_end - time_start
print("search total cost", total_cost, 'sec')
print('QPS = ', SEARCH_COUNT/total_cost)
if __name__ == "__main__":
multi_search()-
Total time for 1000 queries: 7.18 seconds
-
QPS: 139.24
import time
import threading
import numpy as np
from milvus import Milvus, IndexType
from milvus.client.types import MetricType
SERVER_ADDR = "127.0.0.1"
SERVER_PORT = '19530'
COLLECTION_DIMENSION = 128
COLLECTION_NAME = "TEST"
INDEX_TYPE = IndexType.IVF_SQ8
INDEX_PARAM = {'nlist': 2048}
SEARCH_PARAM = {'nprobe': 16}
TOPK = 10
MILVUS = Milvus(host=SERVER_ADDR, port=SERVER_PORT)
def gen_vec_list(nb, seed=np.random.RandomState(1234)):
xb = seed.rand(nb, COLLECTION_DIMENSION).astype("float32")
vec_list = xb.tolist()
return vec_list
def search(vec_list):
status, result = MILVUS.search(collection_name=COLLECTION_NAME, top_k=TOPK,
query_records=vec_list, params=SEARCH_PARAM)
def multi_search():
time_start = time.time()
SEARCH_COUNT = 1000
threads = []
vec_list = gen_vec_list(1)
for k in range(SEARCH_COUNT):
x = threading.Thread(target=search, args=(vec_list,))
threads.append(x)
x.start()
for th in threads:
th.join()
time_end = time.time()
total_cost = time_end - time_start
print("search total cost", total_cost, 'sec')
print('QPS = ', SEARCH_COUNT/total_cost)
if __name__ == "__main__":
multi_search()-
Total time for 1000 queries:4.93 seconds
-
QPS:202.79
