
Recently, the LLM community has been immersed in the shock brought by DeepSeek-V3. This model is not only open-source but also performs well. However, such a large-scale LLM is beyond our reach (the GPU memory can’t handle it). If we can’t afford that, let’s take a look at Microsoft’s open-source smaller LLM, Phi-4. With only 14B parameters, it boldly claims to excel in reasoning capabilities, making it not just a ‘little cannon’ but practically an ‘Italian cannon’. Let’s briefly discuss it.
Phi-4 is the latest member of Microsoft’s Phi series of SLMs, outperforming similar and larger models in mathematical reasoning, thanks to the data used during training and the strategies before and after training. The training data mainly consists of synthetic data, which is created using techniques like multi-agent prompting, self-modification workflows, and instruction inversion. This approach enhances the LLM’s reasoning and problem-solving abilities while addressing some shortcomings of traditional unsupervised datasets.
From a brief understanding of the Phi-4 technical report, we can see that the model architecture follows that of Phi-3, with the core still being the production and ratio of data, as well as the data training strategies. Below, we will briefly explain the data production methods and training features of Phi-4.
Data
The training data includes synthetic data and high-quality web data, with the production of synthetic data coming mainly from the following aspects.
Seed Management: First, high-quality seed data is obtained from multiple domains. These selected seeds provide the foundation for generating synthetic data, allowing the creation of exercises, discussions, and reasoning tasks aimed at the model’s training objectives. The extraction methods mainly include the following three:
Extracting seeds from the web and code repositories: Extracting snippets and code from web pages, books, and code repositories, focusing on content complexity, depth of reasoning, and educational value. This process employs a two-stage filtering to screen these data: first identifying pages with strong educational potential, then segmenting the selected pages into paragraphs and scoring each paragraph based on factual accuracy and reasoning content.
Collecting questions from Q&A datasets: Gathering a large number of questions from websites, forums, and Q&A platforms, and using voting filtering techniques to balance the difficulty of these questions.
Creating Q&A pairs from various sources: Using LM to extract Q&A pairs from organic sources such as books, scientific papers, and code. This is done through a pipeline designed to detect reasoning chains or logic within the text. [A brief introduction to organic data refers to human-generated or non-synthetic data]
Rewriting and Expanding: Next, the seeds are transformed into synthetic data through a multi-step prompting workflow. This includes rewriting most of the useful content in the given paragraphs into exercises, discussions, or structured reasoning tasks.
Self-Modification: Then, through feedback loops, the initial responses are iteratively refined, where the model critically evaluates its own output based on standards focused on reasoning and factual accuracy, and subsequently improves.
Instruction Inversion for Code and Other Tasks: Additionally, to enhance the model’s ability to follow instructions to generate outputs, instruction inversion techniques are used.
For example, existing code snippets are obtained from code data repositories and used to generate corresponding instructions, including problem descriptions or task prompts. The structure of the generated synthetic data pairs places the instruction before the code. Only high-fidelity data between the original and regenerated code is retained to ensure consistency between instructions and outputs. This method can be generalized to other target use cases.
Validation of Code and Other Scientific Data: Where appropriate, tests are combined to validate the reasoning-intensive synthetic datasets. Synthetic code data is validated through execution loops and testing. For scientific datasets, questions are extracted from scientific materials, and the methods used aim to ensure high relevance, foundational quality, and balanced difficulty.
Training
The training process can be divided into three main phases: pre-training, mid-training, and post-training.
Pre-Training Phase
The pre-training phase of Phi-4 primarily relies on synthetic data, supplemented by high-quality organic data.
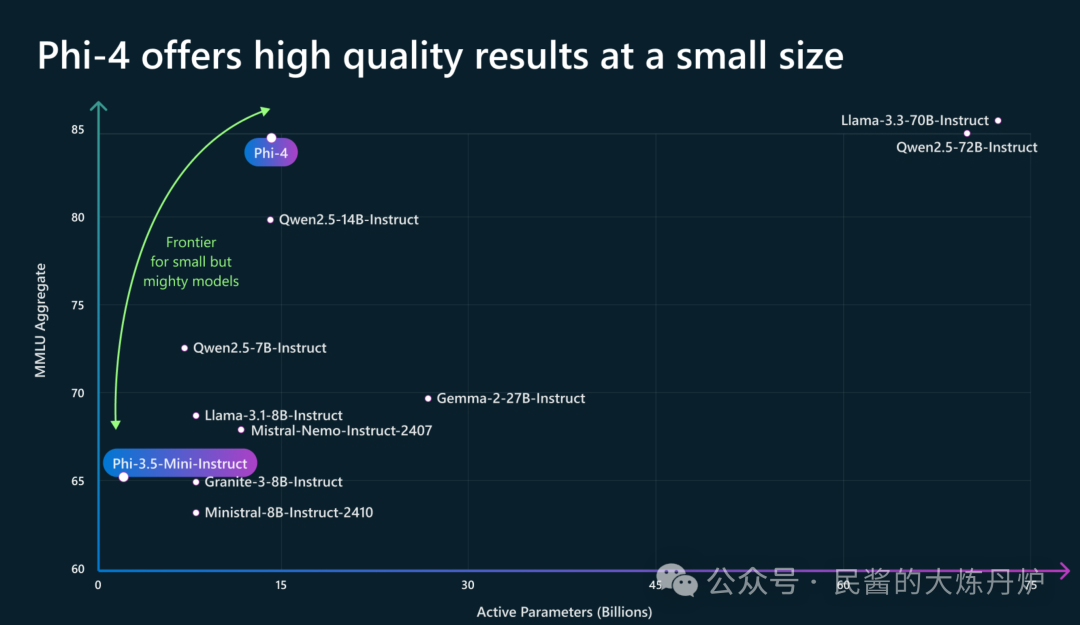
Data Composition: The mixed data includes the following sources: synthetic data, web-rewritten data, filtered web data (divided into reasoning and knowledge-intensive parts), target acquisition, and organic data (e.g., academic data, books, and forums) as well as code data.
Data Ratio: 30% of the training tokens are allocated to web and web-rewritten data sources, evenly distributed between the two. The remaining tokens mainly come from synthetic data, accounting for 40% of the data mix tokens. Finally, 20% of tokens are allocated to code data (a mix of synthetic and original code), and 10% of tokens are allocated to target acquisition sources such as academic data and books.
Model Architecture: Decoder-only architecture, with 14B parameters, and a default context length of 4k.
Training Duration: Approximately 10T tokens were used for training.
Mid-Training Phase
After the pre-training phase, the mid-training phase aims to increase the context length from 4K to 16K.
Data Composition: To accommodate longer contexts, samples longer than 8K are filtered from high-quality non-synthetic datasets, and the proportion of data longer than 16K is increased. Additionally, new synthetic datasets are created to meet the > 4K sequence requirements.
Data Ratio: Includes 30% newly filtered longer context data and 70% recall tokens from the pre-training phase.
Training Duration: A total of 2500B tokens were trained in the mid-training phase.
Post-Training Phase
The post-training phase aims to improve the model’s capabilities in mathematics, coding, reasoning, robustness, and safety.
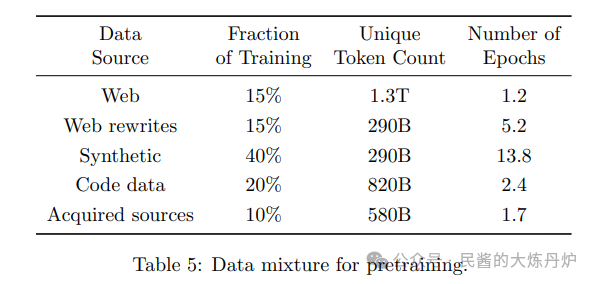
Tuning Methods: The post-training phase includes a round of supervised fine-tuning (SFT), a round of direct preference optimization (DPO) based on key token search methods (PTS), and a round of DPO based on full-length preference pairs.
Data Composition: The post-training data includes SFT datasets and DPO data, covering chat format data, reasoning data, and reliable AI (RAI) data.
In summary, models like DeepSeek-V3 are still a bit far from us ‘commoners’ (referring to self-deployment), but Phi-4 may be a good choice. Especially now that organic data has been nearly ‘eliminated’, it is quite remarkable that LLM pre-training can achieve such good results relying on synthetic data. The extensive use of synthetic data, careful management and filtering of organic data sources, and innovative post-training techniques have, without a doubt, injected new vitality into LLM pre-training.
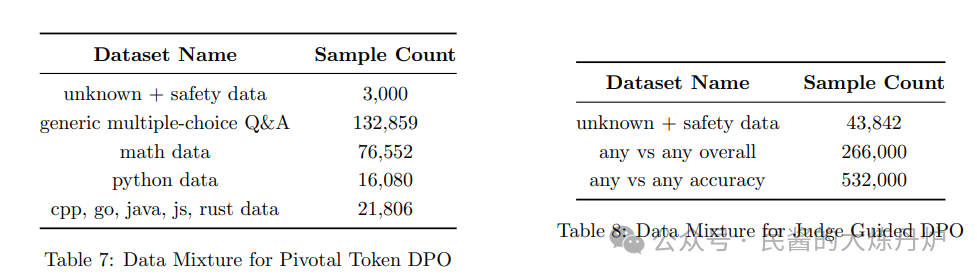
Having said so much, let’s take a look at its actual performance. Phi-4 performs excellently in STEM question-answering tasks, even surpassing its teacher model GPT-4o in GPQA (graduate-level STEM questions) and MATH (math competition) benchmarks. However, Phi-4 performs poorly in tasks requiring strict format adherence. [There are still few datasets for instruction-following tasks, haha.] I won’t elaborate on the specific evaluations; interested friends can check out the official technical report!
# Technical Report: https://arxiv.org/pdf/2412.08905
# Model Link: https://huggingface.co/microsoft/phi-4
Add the editor on WeChat, note “AI”, and join Free mutual aid group [No selling courses or goods], exploring AIGC-Future, let’s improve together!