
Machine Heart Column
Machine Heart Editorial Team
Fusion of multiple heterogeneous large language models, Sun Yat-sen University and Tencent AI Lab introduce FuseLLM
With the success of large language models like LLaMA and Mistral, many major companies and startups have created their own large language models. However, the cost of training new large language models from scratch is extremely high, and there may be redundancy in capabilities between old and new models.
Recently, researchers from Sun Yat-sen University and Tencent AI Lab proposed FuseLLM for “fusion of multiple heterogeneous large models.”
Unlike previous model ensembles and weight merges, the former requires multiple large language models to be deployed simultaneously during inference, while the latter requires merging models that yield the same results. FuseLLM can externalize knowledge from multiple heterogeneous large language models and transfer their knowledge and capabilities to a fused large language model through lightweight continuous training.
The paper has garnered significant attention and shares since its recent release on arXiv.

Some believe, “Using this method when training models in another language is very interesting,” and “I have been thinking about this matter.”
The paper has now been accepted by ICLR 2024.

-
Paper Title: Knowledge Fusion of Large Language Models
-
Paper Link: https://arxiv.org/abs/2401.10491
-
Paper Repository: https://github.com/fanqiwan/FuseLLM
Method Introduction
The key to FuseLLM lies in exploring the fusion of large language models from the perspective of probability distribution representation. For the same input text, the authors believe that the representations generated by different large language models can reflect their inherent knowledge in understanding these texts. Therefore, FuseLLM first utilizes multiple source large language models to generate representations, externalizing their collective knowledge and respective advantages, and then fuses the generated representations to complement each other, finally transferring to the target large language model through lightweight continuous training. The following diagram illustrates an overview of the FuseLLM method.
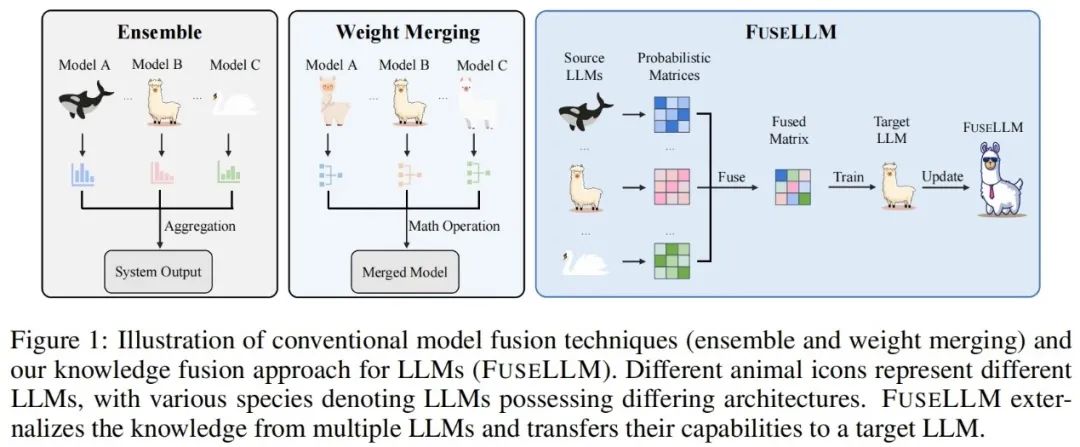
Considering the differences in tokenizers and vocabularies among multiple heterogeneous large language models, aligning tokenization results during representation fusion is crucial: FuseLLM, on top of complete matching at the token level, additionally designs vocabulary-level alignment based on the minimum edit distance, maximizing the retention of usable information in the representations.
To maintain the respective advantages of the large language models while combining their collective knowledge, a careful strategy for generating representations for the fusion model must be designed. Specifically, FuseLLM assesses the understanding of the text by different large language models by calculating the cross-entropy between the generated representations and the label text, and then introduces two cross-entropy based fusion functions:
-
MinCE: Inputs the representations generated by multiple large models for the current text and outputs the representation with the minimum cross-entropy;
-
AvgCE: Inputs the representations generated by multiple large models for the current text and outputs the weighted average representation based on cross-entropy obtained weights;
During the continuous training phase, FuseLLM uses the fused representations as targets to compute fusion loss, while also retaining the language model loss. The final loss function is the sum of the fusion loss and the language model loss.
Experimental Results
In the experimental section, the authors considered a general yet challenging scenario for large language model fusion, where source models have minimal commonality in structure or capability. Specifically, experiments were conducted at a scale of 7B, selecting three representative open-source models: Llama-2, OpenLLaMA, and MPT as the large models to be fused.
The authors evaluated FuseLLM in scenarios such as general reasoning, commonsense reasoning, code generation, text generation, and instruction following, finding significant performance improvements compared to all source models and continued training baseline models.
General Reasoning & Commonsense Reasoning
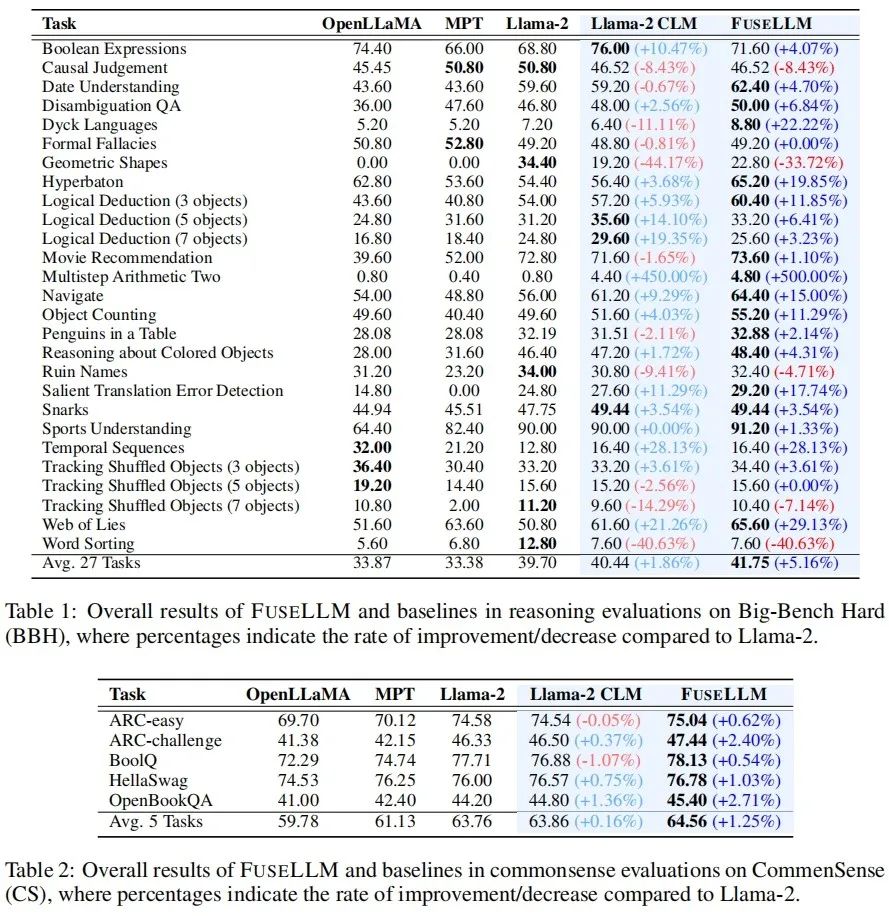
In the Big-Bench Hard Benchmark testing general reasoning ability, after continuous training, Llama-2 CLM achieved an average improvement of 1.86% over Llama-2 across 27 tasks, while FuseLLM achieved a 5.16% improvement over Llama-2, significantly outperforming Llama-2 CLM, indicating that FuseLLM can leverage the advantages of multiple large language models to enhance performance.
In testing commonsense reasoning ability on the Common Sense Benchmark, FuseLLM surpassed all source models and baseline models, achieving the best performance across all tasks.
Code Generation & Text Generation
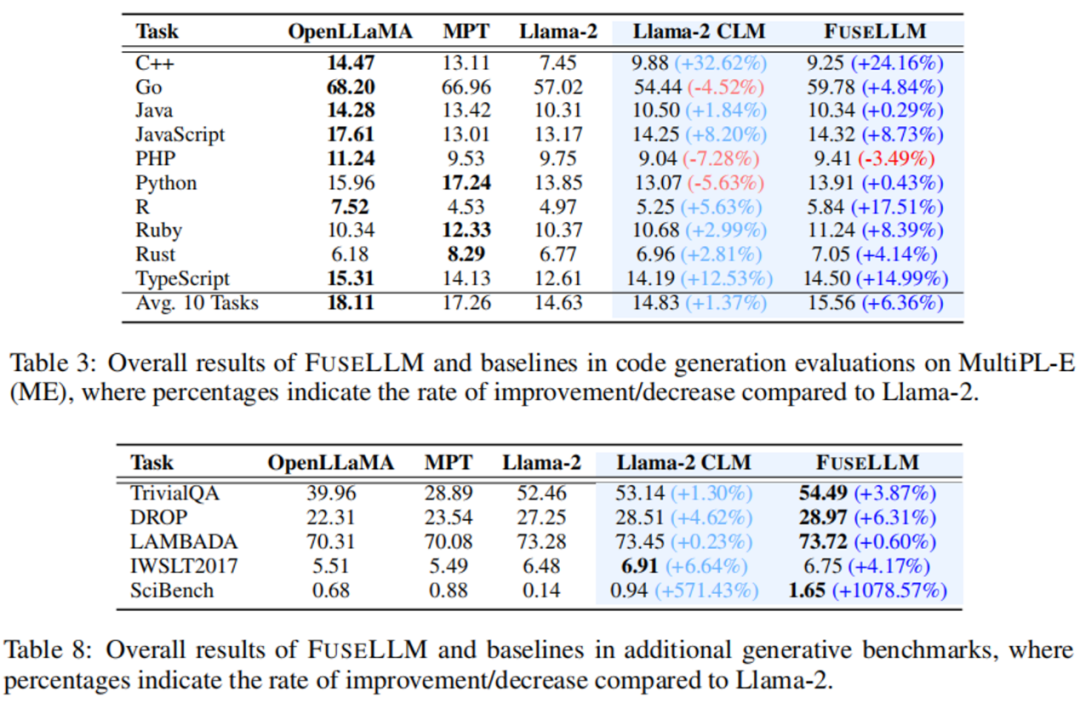
In testing code generation ability on the MultiPL-E Benchmark, FuseLLM exceeded Llama-2 in 9 out of 10 tasks, achieving an average performance improvement of 6.36%. The reason FuseLLM did not surpass MPT and OpenLLaMA may be due to using Llama-2 as the target large language model, which has weaker code generation capabilities, and the proportion of code data in the continuous training corpus is relatively low, only about 7.59%.
In multiple benchmarks for knowledge question answering (TrivialQA), reading comprehension (DROP), content analysis (LAMBADA), machine translation (IWSLT2017), and theorem application (SciBench), FuseLLM also outperformed all source models in all tasks and exceeded Llama-2 CLM in 80% of the tasks.
Instruction Following
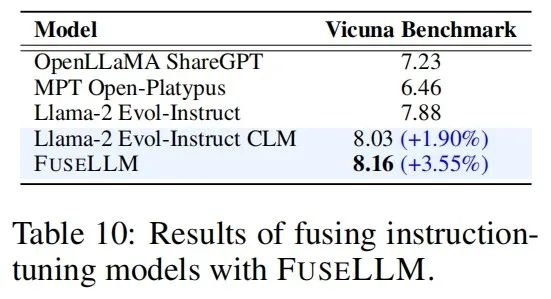
Since FuseLLM only needs to extract representations from multiple source models for fusion and then continuously train the target model, it is also applicable to the fusion of instruction-tuned large language models. In evaluating instruction following ability on the Vicuna Benchmark, FuseLLM also achieved outstanding performance, surpassing all source models and CLM.
FuseLLM vs. Knowledge Distillation & Model Integration & Weight Merging
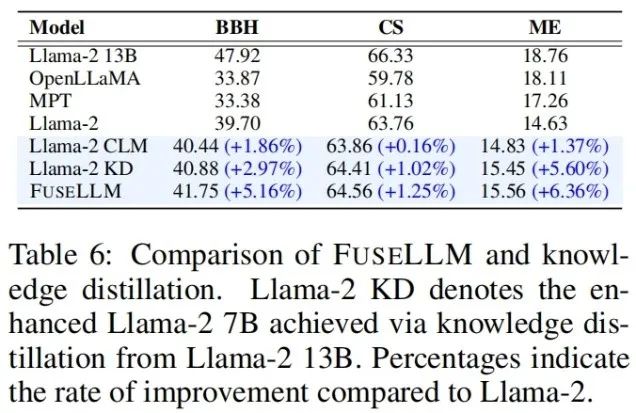
Considering that knowledge distillation is also a method to enhance large language model performance using representations, the authors compared FuseLLM with Llama-2 KD distilled from a single Llama-2 13B model. The results show that FuseLLM, by fusing three 7B models with different architectures, outperformed the effect of distilling from a single 13B model.
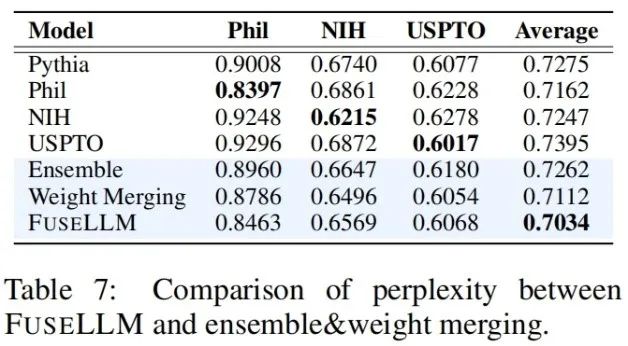
To compare FuseLLM with existing fusion methods (such as model integration and weight merging), the authors simulated scenarios where multiple source models come from the same structured base model but were continuously trained on different corpora, testing various methods on different benchmarks for perplexity. It can be seen that while all fusion techniques can leverage the advantages of multiple source models, FuseLLM achieves the lowest average perplexity, indicating its potential to more effectively combine the collective knowledge of source models than model integration and weight merging methods.
Finally, although the community is currently focused on the fusion of large models, most current practices are based on weight merging and cannot be extended to fusion scenarios of models with different structures and scales. Although FuseLLM is only a preliminary study on heterogeneous model fusion, considering the vast array of different structures and scales of language, vision, audio, and multimodal large models in the current technical community, what incredible performances might emerge from the fusion of these heterogeneous models in the future? Let us wait and see!

© THE END
For reprints, please contact this public account for authorization
Submissions or inquiries: [email protected]