
Crecy from Aofeisi Quantum Bit | WeChat Official Account QbitAI
No fine-tuning is required; just four lines of code can triple the context length of large models!
Moreover, it is “plug-and-play” and theoretically adaptable to any large model, successfully tested on Mistral and Llama2.
With this technology, large models (LargeLM) can transform into LongLM.

Recently, Chinese scholars from Texas A&M University and other institutions released a new method for extending the context window of large models called SelfExtended (abbreviated as SE).
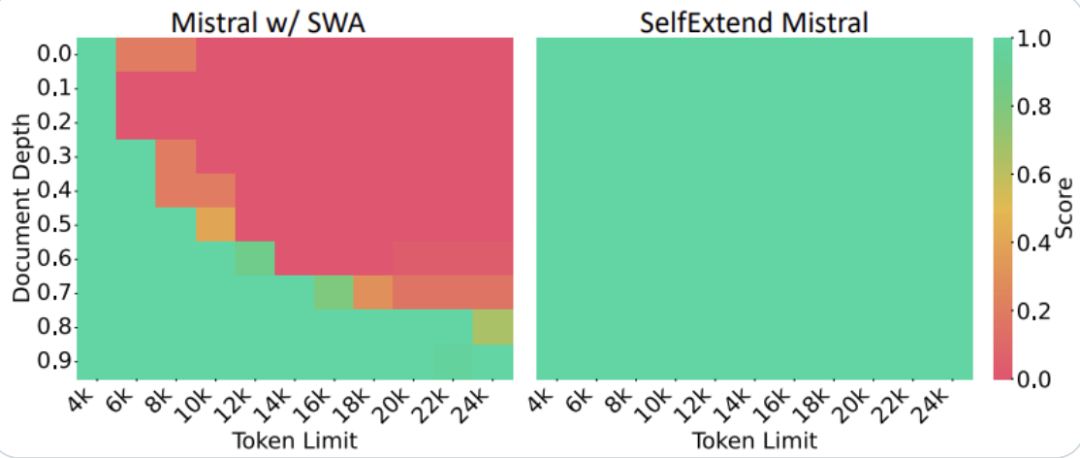
On Mistral, researchers randomly inserted five digits into a 24k length text for the model to search, and the results processed by SE showed a fully green (pass) test result.
In contrast, the unprocessed version began to show “red” at a length of 6k.
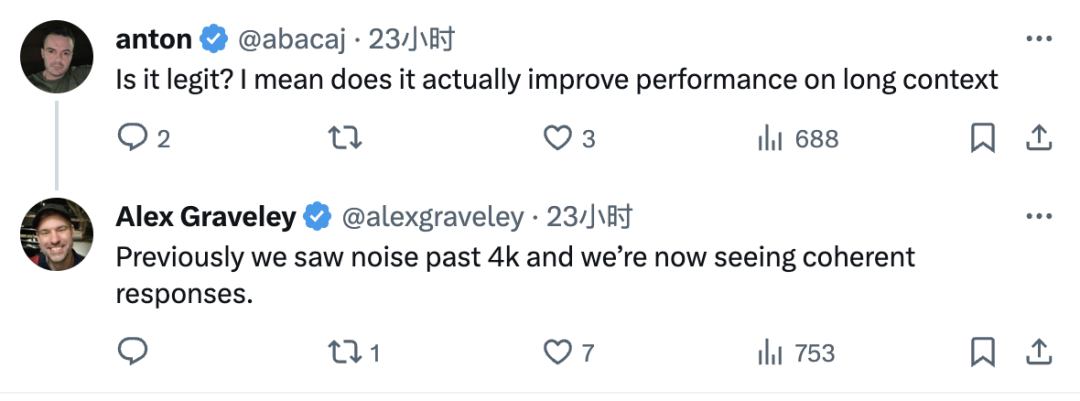
Alex Graveley, the creator of GitHub Copilot, also excitedly announced that experiments on Llama2 have also been successful.

In response to further inquiries from netizens, Alex explained the specific meaning of “work” in the tweet: the noise that originally appeared at a length of 4k has now disappeared.
As for the theoretical limit of SE’s window length, a prominent individual who reproduced the SE code based on the paper stated that, theoretically (as long as computational power is sufficient), it could reach infinite length.

So, what kind of effects can SE achieve?
Significant Enhancement of Long Text Capability
During the process of increasing the window length from 4096 to 16384, the perplexity of Llama 2 skyrocketed by two orders of magnitude from the start.
However, after using SE, the text length became four times the original, but the perplexity only increased by 0.4.
On Mistral, SE brought a lower perplexity than the sliding window (SWA) mechanism used by Mistral itself.
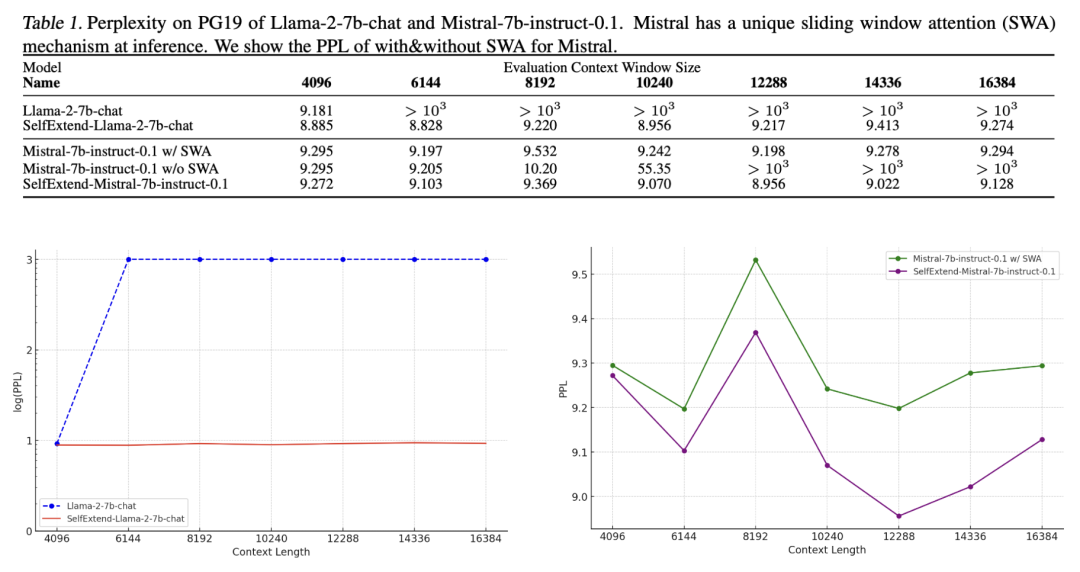
△ The lower left image uses a logarithmic scale
In the LongBench dataset designed for long text models, the models processed with SE scored better than the original version in single/multiple document question answering, summarization, few-shot learning, coding, and other tasks.
Especially on a model named SOLAR, the processed model performed better at a length of 16k than the original version at a length of 4k.
SOLAR is formed by splicing two Llama models with their heads and tails cut off, which creates certain differences in its attention layer structure compared to other Transformer-based models.
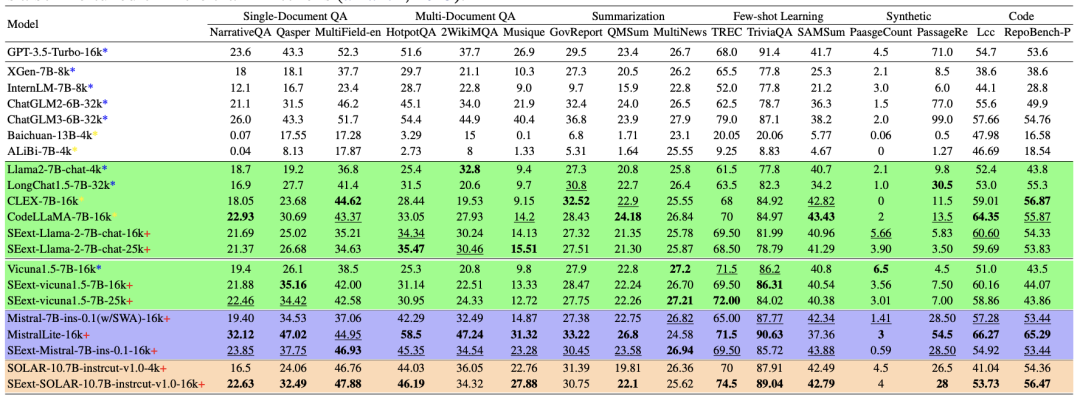
At the same time, in closed-domain question answering tasks composed of exam questions like GSM, the SE-optimized models also achieved higher average scores compared to the original version, slightly inferior to Mistral’s own SWA method.
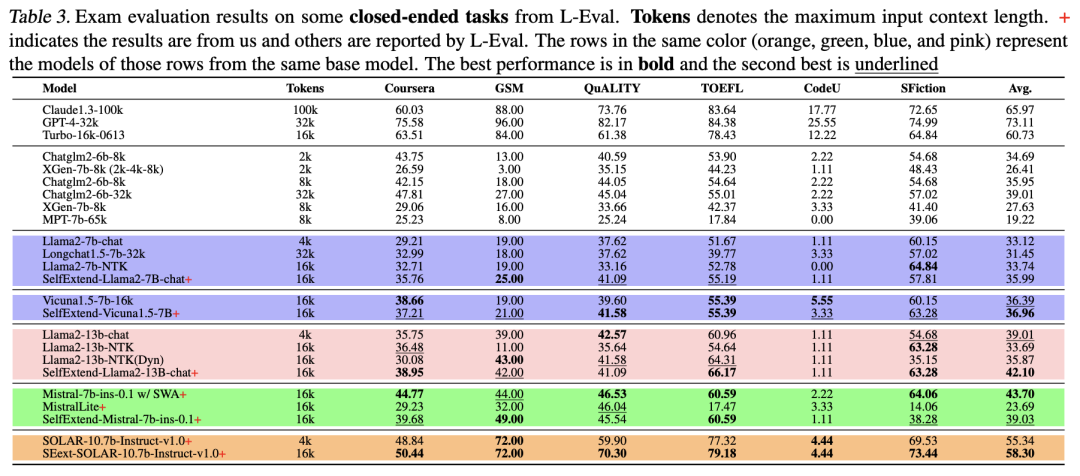
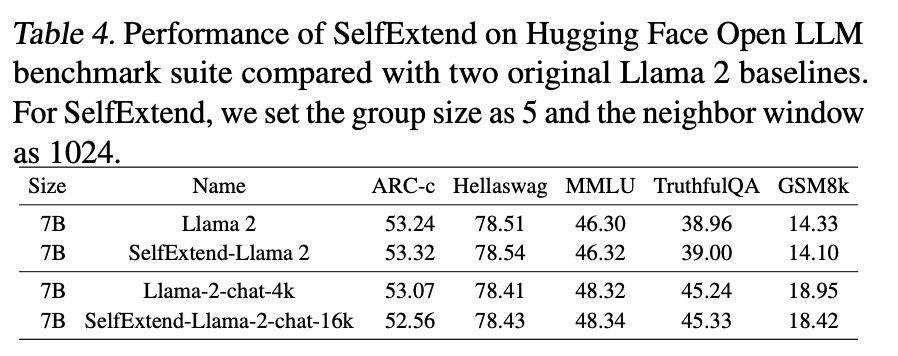
The enhancement of long text capability did not lead to a decline in the model’s ability with short texts.
Under the HuggingFace OpenLLM benchmark, the evaluation scores of the SE version of Llama2 were significantly lower compared to the original version.
Currently, the out-of-the-box version of SE supports three models: Phi, Llama, and Mistral, and can perform window expansion with just four lines of code on these three models.
For other models, some modifications to the code are required.
So, how does SE increase the window length for models?
Two Attention Mechanisms Working Together
The researchers believe that long text capability is inherently present in large models but needs to be activated through certain methods.
The main problem is that when large models handle long texts, they encounter situations where the relative position encoding exceeds the range seen during training.
To address this, the authors adopted the FLOOR attention mechanism as a solution.
FLOOR groups the input text sequences and then uses the group number to perform integer division on the absolute position of a token, effectively mapping long distances to a shorter range.
Then, attention calculations are performed on these mapped values, solving the problem of position encoding exceeding limits and enabling long text processing.
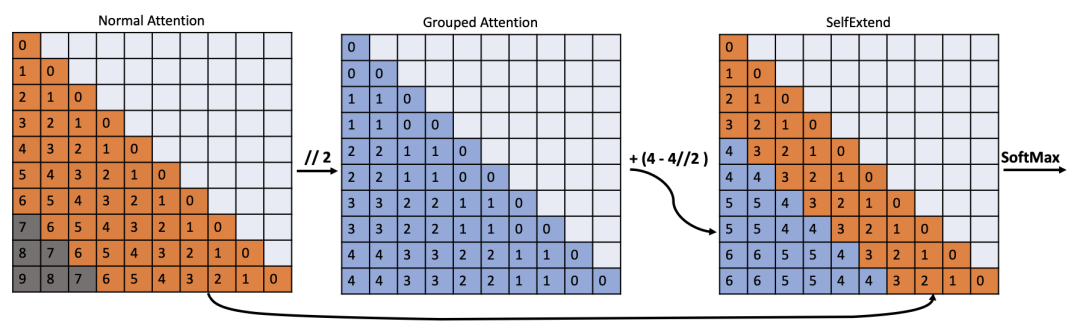
When processing medium and short-length texts, the original attention mechanism of the model is still used to ensure that the model does not “lose balance” and to avoid a decline in short text capabilities due to the increase in long text capabilities.
Additionally, the author who reproduced SE on Mistral admitted that the current model is not perfect and may have issues with a significant increase in computational load.
Furthermore, the original author of SE mentioned that the SE method has not yet been optimized for efficiency, with plans to introduce strategies like FlashAttention in the future to address this issue.

Paper Address: https://arxiv.org/abs/2401.01325
— The End —
Click here👇 to follow me, remember to star it~
One-click triple “Share”, “Like” and “See”
Daily updates on cutting-edge technology ~
