1 Algorithm Introduction
LightGBM (Light Gradient Boosting Machine, hereinafter referred to as LGBM) is an efficient and scalable machine learning algorithm based on Gradient Boosted Decision Trees (GBDT). As a member of the GBDT framework algorithms and a successor to the XGB algorithm, LGBM effectively integrates a series of advantages from previous GBDT algorithms, including XGB, and has made further optimizations based on this foundation.
Before the introduction of LightGBM, the most famous GBDT tool was XGBoost, which is a decision tree algorithm based on the pre-sorting method. Its basic idea is to pre-sort all features by their values, and during the traversal of split points, find the best split point on a feature with a cost of O(#data). After finding the best split point on a feature, the data is split into left and right child nodes. The advantage of this pre-sorting algorithm is that it can accurately find split points. However, it consumes a lot of space and has significant time overhead. To avoid the shortcomings of XGBoost and accelerate the training speed of the GBDT model without compromising accuracy, LightGBM fully borrows a series of optimization strategies proposed by XGB to improve precision, and further proposes a series of optimization strategies for data compression and decision tree modeling processes, including histogram-based decision tree algorithms, one-sided gradient sampling, and direct support for categorical features. This enables efficient parallel training, resulting in faster training speeds, lower memory consumption, better accuracy, and the ability to quickly process massive data in a distributed manner.
2 Algorithm Principles
The optimization components of LightGBM include the following: histogram-based decision tree algorithms, depth-limited leaf-wise growth strategies, histogram difference acceleration, direct support for categorical features, cache hit rate optimization, histogram-based sparse feature optimization, and multi-thread optimization. Below, we mainly introduce the histogram algorithm, depth-limited leaf-wise growth strategy, and histogram difference acceleration.
(1) Histogram-based Decision Tree Algorithm
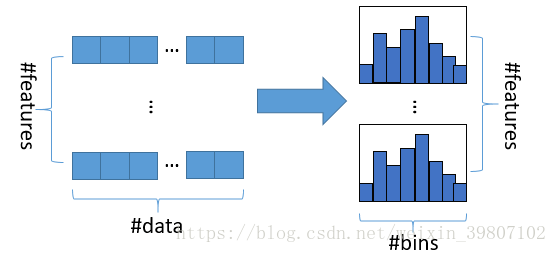
The histogram algorithm’s basic idea is to first discretize continuous floating-point feature values into integers and simultaneously construct a histogram with a width of k. When traversing the data, the accumulated statistics are indexed in the histogram based on the discretized values. After traversing the data once, the histogram accumulates the required statistics, and then the optimal split point is found by traversing the histogram’s discretized values. This algorithm occupies less memory, does not require extra storage for pre-sorted results, and can save only the discretized values of features; it incurs lower computational costs.
Figure 1 Histogram Algorithm
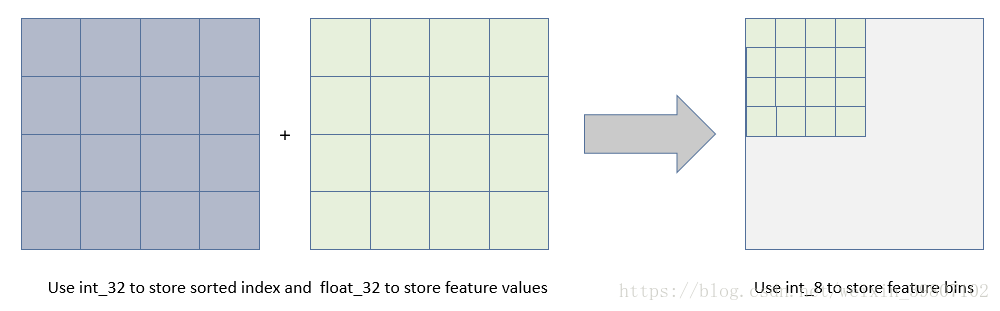
Figure 2 Memory Consumption Diagram of Histogram Algorithm
(2) Depth-Limited Leaf-wise Algorithm
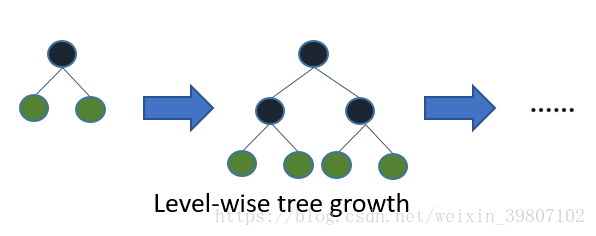
LightGBM adopts a leaf-wise growth strategy, which finds the leaf with the highest split gain from all current leaves and then splits it, repeating this process. Therefore, compared to level-wise, the advantage of leaf-wise is that it can reduce more errors and achieve better accuracy with the same number of splits. The disadvantage of leaf-wise is that it may lead to deeper decision trees, causing overfitting. To prevent overfitting while ensuring high efficiency, LightGBM adds a maximum depth limit on top of the leaf-wise strategy.
Figure 3 Level-wise Growth Strategy Diagram
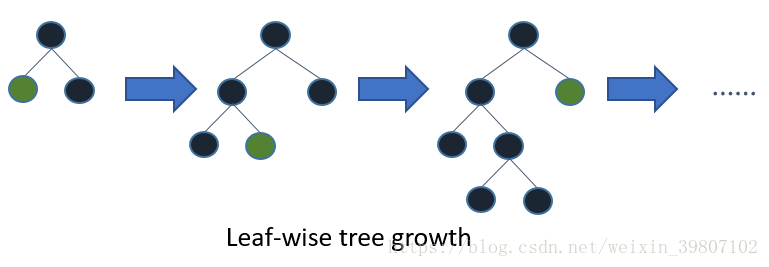
Figure 4 Leaf-wise Growth Strategy Diagram
(3) Histogram Difference Acceleration
The histogram of a leaf can be obtained by taking the difference between the histogram of its parent node and that of its sibling, which can double the speed. Typically, constructing a histogram requires traversing all data on the leaf, but histogram difference only needs to traverse k buckets in the histogram. During the actual tree construction process, LightGBM can first calculate the histogram of the smaller leaf nodes and then use histogram difference to obtain the histogram of the larger leaf nodes, achieving this with minimal cost by retrieving the histogram of its sibling leaf.

Figure 5 Histogram Difference Acceleration Diagram
3 Algorithm Applications
As an efficient machine learning algorithm, LightGBM has a broad application prospect in scientific research, industrial applications, business decision-making, and traditional Chinese medicine (TCM). It can handle large-scale data and has a fast training speed and low memory consumption, which is very beneficial for the complex datasets commonly encountered in TCM research.
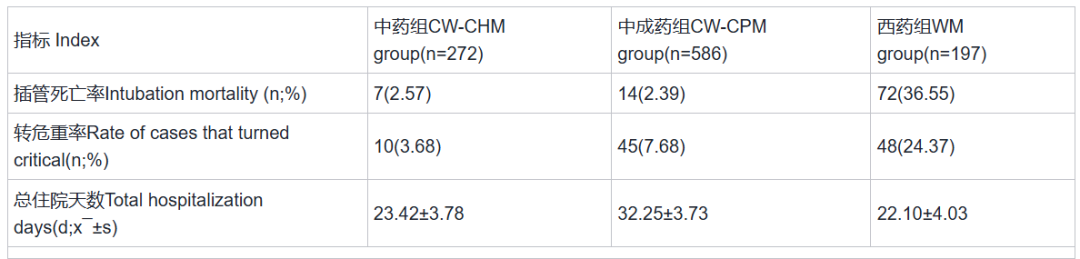
In practical cases, LightGBM has been used to analyze and predict the efficacy of TCM. For example, through retrospective analysis, Lu Yun and other scholars compared the efficacy of integrated traditional Chinese and Western medicine treatment with purely Western medicine treatment for severe COVID-19. The LightGBM model was used to identify risk prediction factors affecting the prognosis of severe COVID-19 patients and to evaluate the significance of TCM in treatment. The specific research process involved using interpretable machine learning methods to retrospectively analyze the clinical treatment processes of a total of 1,055 severe COVID-19 patients admitted to the main hospital area, Optics Valley area, and TCM area of Tongji Hospital affiliated with Huazhong University of Science and Technology. The patients’ laboratory test results and medication were used as features to train a machine learning model to predict whether patients would experience adverse outcome indicators. The model’s performance was evaluated using classification model evaluation metrics such as sensitivity and specificity. According to the treatment plan, patients were divided into three groups: TCM combined with Western medicine – TCM group (referred to as “TCM group”), TCM combined with Western medicine – Chinese patent medicine group (referred to as “Chinese patent medicine group”), and Western medicine group. The Western medicine group received routine treatments based on COVID-19 treatment protocols, including antiviral therapy, oxygen support, and symptomatic treatment. The TCM and Chinese patent medicine groups received TCM decoctions and TCM decoctions combined with Chinese patent medicines, respectively, in addition to the routine Western medicine treatments. The clinical efficacy indicators (total hospitalization days, severe conversion rate, intubation mortality rate) and laboratory-related indicators of the three groups were compared. The results showed: (1) patients with lower albumin to globulin ratios, white blood cell counts, and lymphocyte counts in the TCM or Chinese patent medicine groups had lower intubation mortality rates and severe conversion rates compared to the Western medicine group; (2) the total hospitalization days for the TCM and Western medicine groups were lower than that of the Chinese patent medicine group (results are shown in Table 1). This indicates that adding TCM decoctions or Chinese patent medicine treatments to routine Western medicine treatments for severe COVID-19 patients can enhance patients’ immune functions, reduce intubation mortality rates, and improve prognoses.
Table 1 Intubation Mortality Rate, Severe Conversion Rate, and Total Hospitalization Days of Three Groups of Severe COVID-19 Patients
In addition, LightGBM can also be applied to other aspects of TCM, such as drug component analysis, disease treatment recommendations, and efficacy predictions. Its efficiency, accuracy, and scalability make it highly promising in the modernization research of TCM. In the future, with the continuous accumulation of TCM data and the ongoing advancements in artificial intelligence technology, LightGBM is expected to play a larger role in the TCM field, promoting the modernization and internationalization of TCM.
4 Conclusion
As an efficient gradient boosting decision tree framework, LightGBM has become an important component of modern machine learning toolkits due to its excellent training speed, memory efficiency, and predictive performance. Despite facing issues such as numerous parameters and less friendly handling of missing values, through reasonable parameter adjustment, data preprocessing, and integration with other models, LightGBM demonstrates strong competitiveness in practical applications. With continuous technological advancements and innovations, LightGBM will achieve more progress in automation and intelligence, lowering the barriers for user adoption and improving model usability. At the same time, by integrating advanced technologies such as deep learning and automated machine learning, LightGBM will continue to drive advancements in machine learning technology, providing strong support for data-driven decision-making across various industries.
[1] Lu Yun, Zhang Mengyue, Xia He, et al. A Multicenter Retrospective Study Based on LightGBM and SHAP on the Integrated Traditional Chinese and Western Medicine Treatment of 1055 Severe COVID-19 Patients [J]. Journal of Beijing University of Chinese Medicine, 2021, 44(12): 1098-1107.
[2] In-depth Exploration: The Principles and Applications of Machine Learning LightGBM Algorithm – lightgbm Regression – CSDN Blog. Accessed on September 18, 2024.
https://blog.csdn.net/qq_51320133/article/details/137589078.
[3] Summary of LightGBM Algorithm – CSDN Blog. Accessed on September 18, 2024.
https://blog.csdn.net/weixin_39807102/article/details/81912566.
[4] Ensemble Learning VI – LightGBM – Zhihu (zhihu.com). Accessed on September 18, 2024.
https://zhuanlan.zhihu.com/p/627313748.
XGBoost: Optimized Gradient Boosting Trees to Improve Machine Learning Task Accuracy
CLIP Model: Building Universal Representations of Vision and Language
Prompt Learning: A New Tool for Language Models to Maintain Good Performance in Low-Resource Scenarios

Ancient and Modern Medical Cases Cloud Platform
Providing over 500,000 Ancient and Modern Medical Case Search Services
Supports manual, voice, OCR, and batch structured entry of medical cases
Designed with nine analysis modules, close to clinical practical needs
Supports collaborative analysis of massive medical cases and personal cases on the platform
EDC Traditional Chinese Medicine Research Case Collection System
Supports multi-center, online random grouping, data entry
SDV, audit trails, SMS reminders, data statistics
Analysis and other functions
Supports customized form design
Users can log in at: https://www.yiankb.com/edc
Free Trial!
Institute of Chinese Medical Sciences, Chinese Academy of Traditional Chinese Medicine
Intelligent R&D Center for Health and Wellness in Traditional Chinese Medicine
Big Data R&D Department
Phone: 010-64089619
13522583261
QQ: 2778196938
https://www.yiankb.com