Source: Deep Learning and Large Models LLM
This article is approximately 3500 words long and is recommended for a 9-minute read.
This article delves into the development of Retrieval-Augmented Generation (RAG), from basic concepts to the latest technologies.
All subfields of LLM + ACL25/ICML25/NAACL25 submission groups -> Enter from here for all subfields and submission groups of LLM!
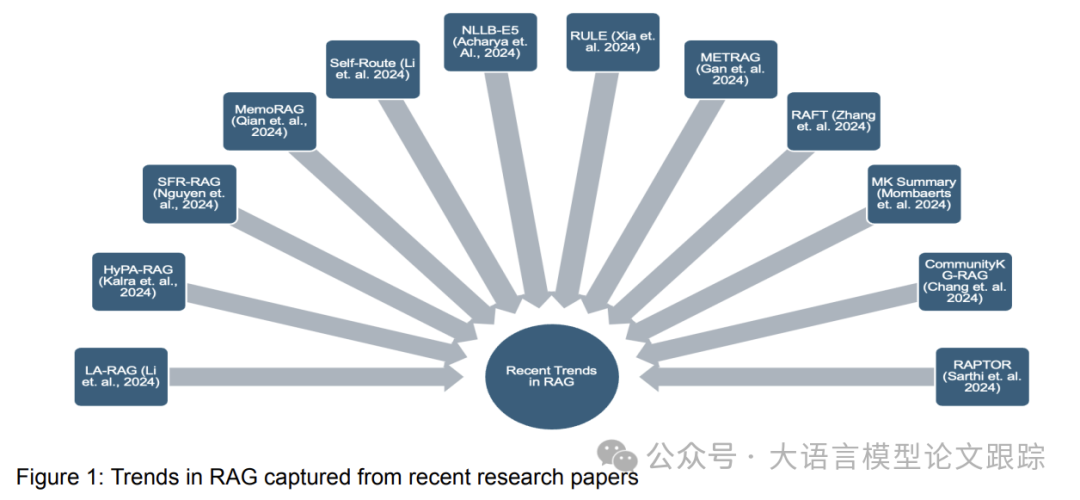
15 Typical RAG Frameworks: Latest RAG Overview from Carnegie Mellon University
A Comprehensive Survey of Retrieval-Augmented Generation (RAG): Evolution, Current Landscape and Future Directions
This article delves into the development of Retrieval-Augmented Generation (RAG), from basic concepts to the latest technologies. RAG effectively improves output accuracy by combining retrieval and generation models, overcoming the limitations of LLMs. The research provides a detailed analysis of RAG’s architecture, illustrating how retrieval and generation collaboratively handle knowledge-intensive tasks. Furthermore, this article reviews key technological advancements of RAG in fields such as question answering and summarization, and discusses new methods to enhance retrieval efficiency. Additionally, the article highlights challenges in scalability, bias, and ethics within RAG and proposes future research directions to enhance model robustness, expand application scope, and address social impacts. This survey aims to provide a foundational guide for researchers and practitioners in the NLP field to better understand the potential and development path of RAG.
https://arxiv.org/abs/2410.12837
1. Introduction
1.1 Overview of Retrieval-Augmented Generation (RAG)
RAG (Retrieval-Augmented Generation) integrates two core components:
– (ii) The generation module, which processes this information to produce human-like text. The retrieved documents are then sent to the generation module, which is typically built on a transformer architecture.
RAG helps to reduce the phenomenon of “hallucination” in generated content, ensuring that the text is more factual and contextually appropriate. RAG has been widely applied in various fields, including:
-
Open-domain question answering -
Conversational agents -
Personalized recommendations.
1.2 New Systems of Hybrid Retrieval and Generation
Before the advent of RAG, natural language processing (NLP) primarily relied on either retrieval or generation methods.
-
Retrieval-based systems: For example, traditional information retrieval engines that efficiently provide relevant documents or snippets based on queries but cannot synthesize new information or present results in a coherent narrative form. -
Generation-based systems: With the rise of transformer architectures, pure generation models have gained popularity for their fluency and creativity, yet often fall short in factual accuracy.
The complementarity of these two approaches has led to attempts at hybrid systems that combine retrieval and generation. The earliest hybrid systems can be traced back to DrQA, which used retrieval techniques to obtain relevant documents for question-answering tasks.
1.3 Limitations of RAG
-
There may still be errors when facing ambiguous queries or retrieving in specific knowledge domains. Depending on dense vector representations, such as those used by DPR (Dense Passage Retrieval), can sometimes retrieve irrelevant or off-topic documents. Therefore, it is necessary to enhance the precision of retrieval techniques through the introduction of more refined query expansion and context disambiguation techniques. Theoretically, the combination of retrieval and generation should be seamless, but in practice, the generation module sometimes struggles to effectively integrate the retrieved information into responses, leading to inconsistencies or incoherence between the retrieved facts and generated text. -
Computational cost is also a significant concern since it requires executing both retrieval and generation steps for each query, which is particularly resource-intensive for large-scale applications. Techniques such as model pruning or knowledge distillation may help reduce computational burdens without sacrificing performance. -
Ethical issues, especially regarding bias and transparency. Bias in AI and LLMs is a widely studied and evolving field, with researchers identifying various types of biases, including those related to gender, socioeconomic status, and educational background. While RAG has the potential to reduce bias by retrieving more balanced information, there remains a risk of amplifying biases present in the retrieval sources. Moreover, ensuring transparency in the selection and use of retrieval results is crucial for maintaining trust in these systems.
2. Core Components and Architectural Overview of RAG Systems
2.1 Overview of RAG Models
RAG models consist of two core components:
-
Retriever: Utilizes techniques such as Dense Passage Retrieval (DPR) or traditional BM25 algorithms to retrieve the most relevant documents from a corpus. -
Generator: Integrates the retrieved documents into coherent, contextually relevant answers.
The strength of RAG lies in its ability to dynamically utilize external knowledge, outperforming generation models that rely on static datasets like GPT-3.
2.2 Retrievers in RAG Systems
2.2.1 BM25
BM25 is a commonly used information retrieval algorithm that utilizes term frequency-inverse document frequency (TF-IDF) to rank documents based on relevance. Despite being a classic method, it remains a standard algorithm in many modern retrieval systems, including those used in RAG models.
BM25 calculates the relevance score of documents based on the frequency of query terms within the documents while considering document length and term frequency across the entire corpus. Although BM25 performs excellently in keyword matching, it has limitations in understanding semantic meanings. For instance, BM25 cannot capture the relationships between words and performs poorly in handling complex natural language queries that require contextual understanding.
Nonetheless, BM25 is widely adopted due to its simplicity and efficiency. It is suitable for simple keyword-based query tasks, although modern retrieval models like DPR often perform better in handling semantically complex tasks.
2.2.2 Dense Passage Retrieval (DPR)
Dense Passage Retrieval (DPR) is a novel information retrieval method. It utilizes a high-dimensional vector space, where both queries and documents are encoded into high-dimensional vectors.
Employing a dual-encoder architecture, it encodes queries and documents separately to facilitate efficient nearest neighbor searches.
Unlike BM25, DPR excels at capturing semantic similarities between queries and documents, making it highly effective for open-domain question answering tasks.
The advantage of DPR lies in its ability to retrieve relevant information based on semantic meaning rather than keyword matching. By training the retriever on a large corpus of question-answer pairs, DPR can find documents relevant to the query context, even if the query and documents do not use the exact same vocabulary. Recent studies have further optimized DPR by combining it with pre-trained language models.
2.2.3 REALM (Retrieval-Augmented Language Model)
REALM integrates the retrieval process into the pre-training of the language model, ensuring that the retriever and generator are optimized collaboratively for subsequent tasks.
The innovation of REALM lies in its ability to learn to retrieve documents that enhance the model’s performance on specific tasks, such as question answering or document summarization.
During training, REALM synchronously updates both the retriever and generator, optimizing the retrieval process to better serve text generation tasks.
The retriever in REALM is trained to identify documents that are both relevant to the query and helpful in generating accurate, coherent answers. As a result, REALM significantly improves the quality of generated answers, especially in tasks that rely on external knowledge.
Recent research indicates that in certain knowledge-intensive tasks, REALM outperforms BM25 and DPR, particularly in scenarios where retrieval and generation are closely integrated.
The essence of RAG lies in the quality of the retrieved paragraphs, although many existing methods rely on similarity-based retrieval (Mallen et al., 2022).
Self-RAG and REPLUG enhance retrieval capabilities by leveraging large language models (LLMs) to achieve more flexible retrieval.
After the initial retrieval, cross-encoder models re-rank the results by jointly encoding the query and retrieved documents to compute relevance scores. While these models provide richer context-aware retrieval, they come with higher computational costs.
RAG systems utilize the self-attention mechanism in LLMs to manage the context and relevance of different parts of the input and retrieved text. When integrating retrieval information into the generation model, a cross-attention mechanism is employed to ensure that the most relevant information segments are highlighted during the generation process.
2.3 Generators in RAG Systems
In RAG, the generator is a critical component that merges the retrieved information with the input query to produce the final output.
Once the retrieval component extracts relevant knowledge from external resources, the generator weaves this information into coherent, contextually appropriate responses. Large language models (LLMs) form the core of the generator, ensuring that the generated text is fluent, accurate, and consistent with the original query.
2.3.1 T5
T5 (Text-to-Text Transfer Transformer) is one of the commonly used models for generation tasks in RAG systems.
The flexibility of T5 lies in its approach of treating all NLP tasks as text-to-text tasks. This unified framework allows T5 to be fine-tuned for a wide range of tasks, including question answering, summarization, and dialogue generation.
By integrating retrieval and generation, T5-based RAG models have surpassed traditional generation models like GPT-3 and BART in multiple benchmark tests, particularly on the Natural Questions and TriviaQA datasets.
Moreover, T5’s capability to handle complex multi-task learning makes it a preferred choice for RAG systems that need to address diverse knowledge-intensive tasks.
2.3.2 BART
BART (Bidirectional and Auto-Regressive Transformer) is particularly well-suited for tasks that involve generating text from noisy inputs, such as summarization and open-domain question answering.
As a denoising autoencoder, BART can reconstruct damaged text sequences, making it excel in tasks that require generating coherent, factual outputs from incomplete or noisy data.
When combined with the retriever in RAG systems, BART has been shown to improve the factual accuracy of generated text through external knowledge.
3. Cross-Modal Retrieval-Augmented Generation Models
3.1 Text-based RAG Models
Text-based RAG models are currently the most mature and widely researched type.
Relying on text data, they perform retrieval and generation tasks, driving advancements in applications such as question answering, summarization, and conversational agents.
Transformer architectures like BERT and T5 form the foundation of text RAG models, utilizing self-attention mechanisms to capture contextual relationships within the text, thereby enhancing retrieval accuracy and generation fluency.
3.2 Audio-based RAG Models
Audio-based RAG models extend the concept of retrieval-augmented generation to the audio domain, opening new avenues for applications such as speech recognition, audio summarization, and conversational agents in audio interfaces. Audio data is often represented through embeddings derived from pre-trained models like Wav2Vec 2.0. These embeddings serve as inputs for the retrieval and generation components, enabling the model to effectively process audio data.
3.3 Video-based RAG Models
Video-based RAG models integrate visual and textual information, enhancing performance in tasks such as video understanding, subtitle generation, and retrieval. Video data is represented through embeddings from models like I3D TimeSformer. These embeddings capture temporal and spatial features, which are crucial for effective retrieval and generation.
3.4 Multimodal RAG Models
Multimodal RAG models integrate data from various modalities, including text, audio, video, and images, providing a more comprehensive approach to retrieval and generation tasks.
Models like Flamingo integrate different modalities into a unified framework, enabling simultaneous processing of text, images, and video. Cross-modal retrieval techniques involve retrieving relevant information across different modalities.
“Retrieval as Generation” extends the retrieval-augmented generation (RAG) framework to multimodal applications by combining text-to-image and image-to-text retrieval. By leveraging large-scale paired image and text description datasets, it can quickly generate images when user queries match stored text descriptions (“retrieval as generation”).
Note:Nickname – School/Company – Direction/Conference (e.g., ACL), Enter technical/submission group

id: DLNLPer, Remember to leave a note