MLNLP community is a well-known machine learning and natural language processing community at home and abroad, covering NLP master’s and doctoral students, university teachers, and corporate researchers.
The vision of the community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning at home and abroad, especially the progress of beginners.
Reprinted from | New Intelligence
Retrieval-Augmented Generation (RAG) is a technique that uses retrieval to enhance language models. Specifically, it retrieves relevant information from a vast document database before the language model generates an answer, guiding the generation process with this information. This technique can greatly improve the accuracy and relevance of content, effectively mitigate hallucination issues, speed up knowledge updates, and enhance the traceability of content generation. RAG is undoubtedly one of the most exciting research areas in artificial intelligence. For more details on RAG, please refer to the Machine Heart column article “What are the New Developments of RAG in Supplementing Large Models? This Review Clarifies It“.
However, RAG is not perfect, and users often encounter some “pain points” while using it. Recently, NVIDIA’s Senior Solutions Architect for Generative AI, Wenqi Glantz, published an article on Towards Data Science, outlining 12 pain points of RAG and providing corresponding solutions.
The article’s directory is as follows:
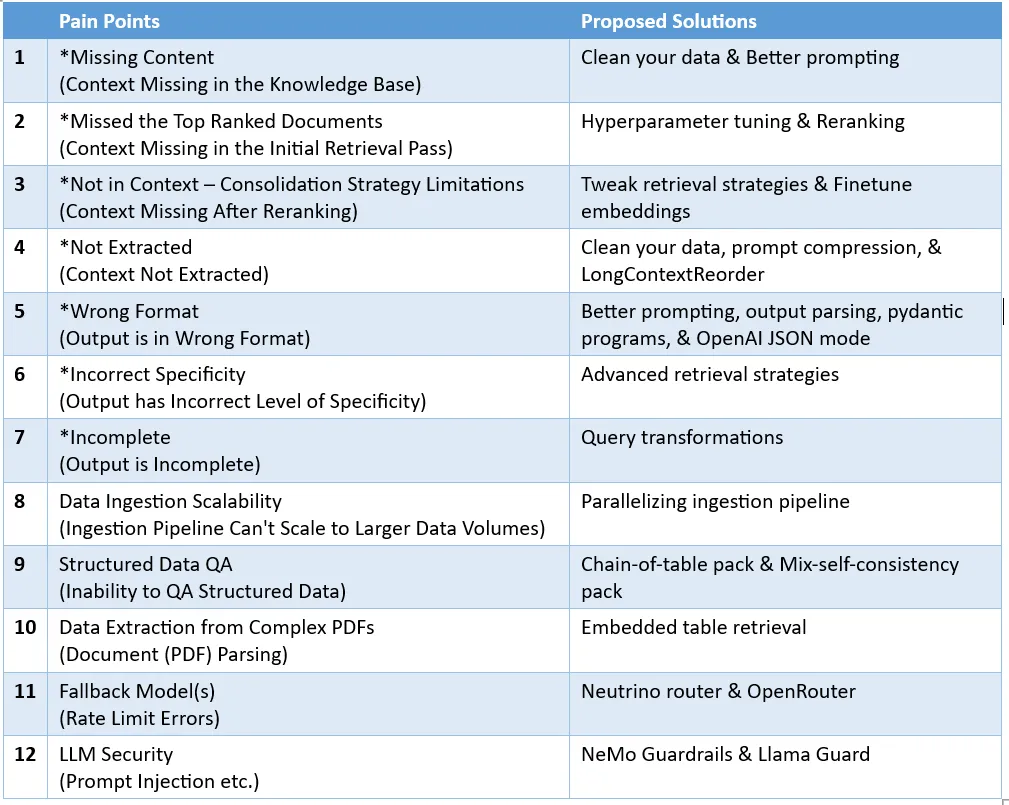
Pain Point 1: Content Missing
Pain Point 2: Missing Top-ranked Documents
Pain Point 3: Out of Context – Limitations of Merging Strategies
Pain Point 4: Not Extracted
Pain Point 5: Formatting Errors
Pain Point 6: Incorrect Specifics
Pain Point 8: Scalability of Data Ingestion
Pain Point 9: Structured Data Q&A
Pain Point 10: Extracting Data from Complex PDFs
Pain Point 11: Backup Models
Pain Point 12: LLM Security
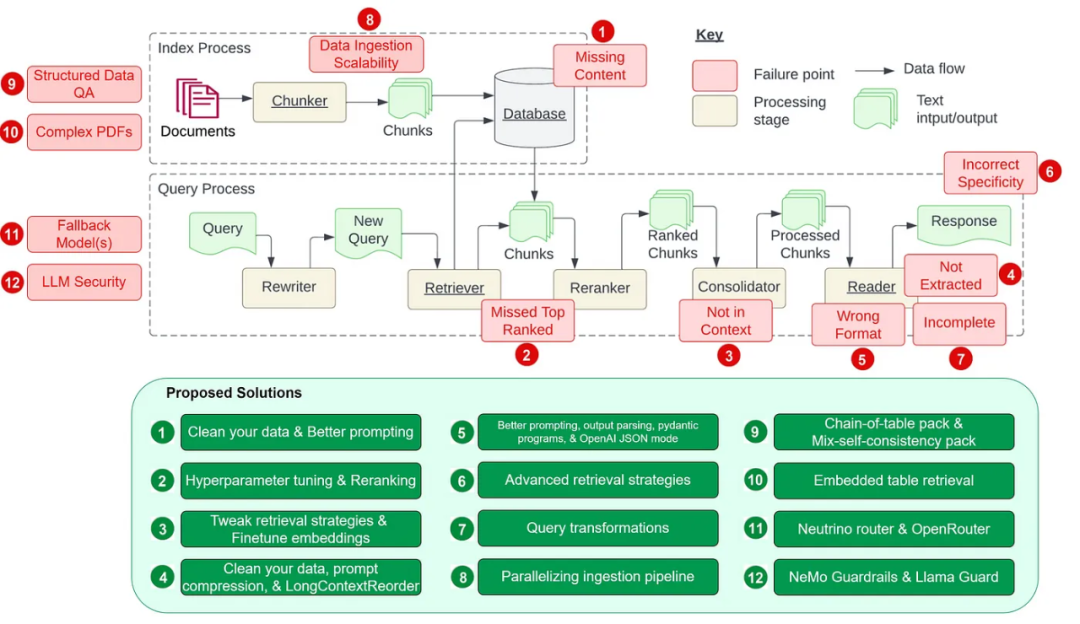
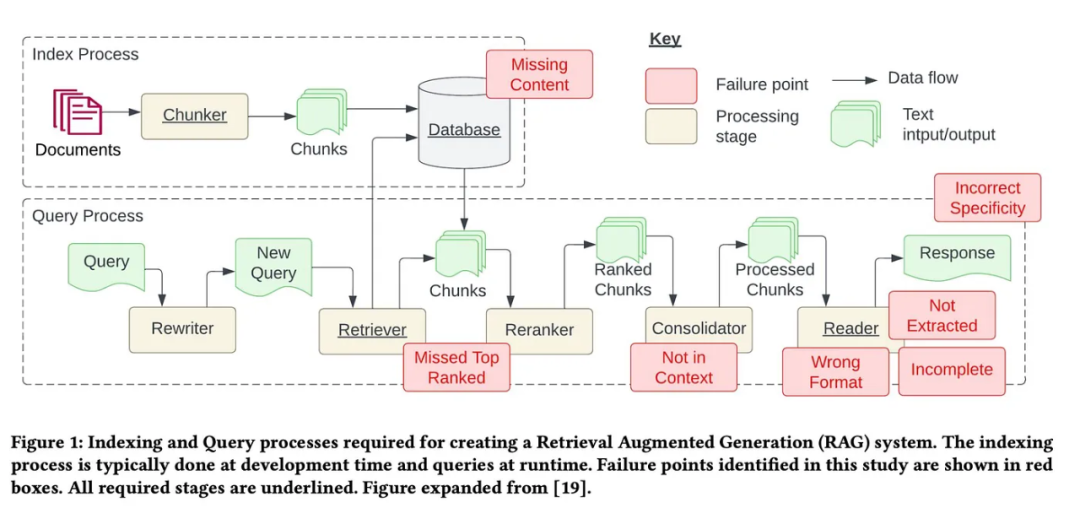
Among them, 7 pain points (see the image below) come from the paper by Barnett et al. titled “Seven Failure Points When Engineering a Retrieval Augmented Generation System,” with an additional 5 common pain points added.
The corresponding solutions to these pain points are as follows:
Pain Point 1: Content Missing
The knowledge base lacks context. When there is no answer in the knowledge base, the RAG system may provide an answer that seems credible but is actually incorrect, without admitting that it does not know. Users receive erroneous information and face frustration.
Two solutions have been proposed:
Garbage in, garbage out. If your source data is of poor quality, such as containing conflicting information, no matter how well your RAG system is built, it cannot magically produce high-quality results from garbage input. This solution applies not only to this pain point but to all pain points listed in this article. Any RAG workflow seeking to perform well must first clean the data.
Several common strategies for data cleaning are listed below:
-
Remove noise and irrelevant information: This includes removing special characters, stop words (like “the” and “a”), and HTML tags.
-
Identify and correct errors: This includes spelling mistakes and grammatical errors. Tools like spell checkers and language models can be used to address this issue.
-
Deduplication: Remove duplicate data records or similar records that may lead to biases in the retrieval process.
The core software library from unstructured.io provides a complete set of cleaning tools to help address these data cleaning needs. It’s worth a try.
For issues where the system provides seemingly credible but incorrect results due to a lack of information, better prompt design can be very helpful. By giving the system instructions like “If you are unsure what the answer is, tell me you don’t know,” you can encourage the model to acknowledge its limitations and communicate its uncertainty to users more transparently. While it cannot guarantee 100% accuracy, carefully designed prompts are one of the best practices after cleaning the data.
Pain Point 2: Missing Top-ranked Documents
Lack of context in the initial retrieval process. In the results returned by the system’s retrieval component, critical documents may not be ranked highly. Correct answers are overlooked, leading to the system failing to provide accurate responses. The aforementioned paper states: “The answer to the question is in the document, but if it is not ranked high enough, it is not returned to the user.”
Researchers have proposed two solutions:
Tuning hyperparameters for chunk_size and similarity_top_k
The parameters chunk_size and similarity_top_k can be used to manage the efficiency and effectiveness of the RAG model’s data retrieval process. Adjusting these parameters affects the trade-off between the computational efficiency of the retrieved information and its quality. The author explored the details of tuning chunk_size and similarity_top_k in a previous article:
Please visit: https://medium.com/gitconnected/automating-hyperparameter-tuning-with-llamaindex-72fdd68e3b90
Below is an example code:
param_tuner = ParamTuner( param_fn=objective_function_semantic_similarity, param_dict=param_dict, fixed_param_dict=fixed_param_dict, show_progress=True,)results = param_tuner.tune()
The definition of the objective_function_semantic_similarity function is as follows, where param_dict contains the parameters chunk_size and top_k along with their corresponding values:
# contains the parameters that need to be tunedparam_dict = {"chunk_size": [256, 512, 1024], "top_k": [1, 2, 5]}# contains parameters remaining fixed across all runs of the tuning processfixed_param_dict = { "docs": documents, "eval_qs": eval_qs, "ref_response_strs": ref_response_strs,}def objective_function_semantic_similarity(params_dict): chunk_size = params_dict["chunk_size"] docs = params_dict["docs"] top_k = params_dict["top_k"] eval_qs = params_dict["eval_qs"] ref_response_strs = params_dict["ref_response_strs"] # build index index = _build_index(chunk_size, docs) # query engine query_engine = index.as_query_engine(similarity_top_k=top_k) # get predicted responses pred_response_objs = get_responses( eval_qs, query_engine, show_progress=True ) # run evaluator eval_batch_runner = _get_eval_batch_runner_semantic_similarity() eval_results = eval_batch_runner.evaluate_responses( eval_qs, responses=pred_response_objs, reference=ref_response_strs ) # get semantic similarity metric mean_score = np.array( [r.score for r in eval_results["semantic_similarity"]] ).mean() return RunResult(score=mean_score, params=params_dict)
For more details, please visit LlamaIndex’s complete notes on hyperparameter optimization for RAG:
https://docs.llamaindex.ai/en/stable/examples/param_optimizer/param_optimizer/
Re-ranking the retrieved results before sending them to the LLM can significantly enhance RAG performance.
This LlamaIndex note (https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/CohereRerank.html) demonstrates the differences between the following two approaches:
-
Not using a re-ranking tool (reranker), directly retrieving the top 2 nodes, resulting in inaccurate retrieval.
-
Retrieving the top 10 nodes and using CohereRerank for re-ranking, then returning the top 2 nodes, resulting in accurate retrieval.
import osfrom llama_index.postprocessor.cohere_rerank import CohereRerankapi_key = os.environ["COHERE_API_KEY"]cohere_rerank = CohereRerank(api_key=api_key, top_n=2) # return top 2 nodes from rerankerquery_engine = index.as_query_engine( similarity_top_k=10, # we can set a high top_k here to ensure maximum relevant retrieval node_postprocessors=[cohere_rerank], # pass the reranker to node_postprocessors)response = query_engine.query( "What did Sam Altman do in this essay?",)
Additionally, various embedding and re-ranking tools can be utilized to evaluate and enhance the performance of the retriever.
Refer to: https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83
Furthermore, to achieve better retrieval performance, a customized re-ranking tool can also be fine-tuned, with implementation details available at:
Blog link: https://blog.llamaindex.ai/improving-retrieval-performance-by-fine-tuning-cohere-reranker-with-llamaindex-16c0c1f9b33b
Pain Point 3: Out of Context – Limitations of Merging Strategies
Lack of context after re-ranking. For this pain point, the aforementioned paper defines it as: “Documents containing answers have already been retrieved from the database, but the document did not become the context for generating answers. This happens because the database returned many documents, and a merging process was used to retrieve the answer.”
In addition to the previously mentioned addition of re-ranking tools and fine-tuning re-ranking tools, we can also explore the following solutions:
Adjusting Retrieval Strategies
LlamaIndex provides a range of retrieval strategies from basic to advanced, helping researchers achieve accurate retrieval in RAG workflows.
Here you can see a list of retrieval strategies categorized differently: https://docs.llamaindex.ai/en/stable/module_guides/querying/retriever/retrievers.html
-
Basic retrieval based on each index
-
Advanced retrieval and search
-
-
Knowledge graph retriever
-
Combination/hierarchical retrievers
If you are using open-source embedding models, you can fine-tune the embedding model for more accurate retrieval. LlamaIndex has a step-by-step tutorial on fine-tuning open-source embedding models, which proves that fine-tuning embedding models can indeed improve performance across multiple evaluation metrics:
Tutorial Link: https://docs.llamaindex.ai/en/stable/examples/finetuning/embeddings/finetune_embedding.html
Below is sample code for creating a fine-tuning engine, running fine-tuning, and obtaining the fine-tuned model:
finetune_engine = SentenceTransformersFinetuneEngine( train_dataset, model_id="BAAI/bge-small-en", model_output_path="test_model", val_dataset=val_dataset,)finetune_engine.finetune()embed_model = finetune_engine.get_finetuned_model()
Pain Point 4: Not Extracted
Context is not correctly extracted. The system struggles to extract the correct answer from the provided context, especially when there is information overload. This leads to the omission of key details and damages the quality of responses. The aforementioned paper states: “This occurs when there is too much noise or conflicting information in the context.”
Let’s look at three solutions:
A typical cause of this pain point is poor data quality. The importance of data cleaning cannot be overstated! Before blaming your RAG process, please ensure your data is clean.
The LongLLMLingua research project/paper proposes prompt compression for long context situations. By integrating it into LlamaIndex, we can implement LongLLMLingua as a node post-processor that compresses the context after the retrieval step before passing it to the LLM. The prompt compressed by LongLLMLingua can achieve much higher performance at a significantly lower cost. Additionally, the entire system will run faster.
The following code sets up LongLLMLinguaPostprocessor, utilizing the longllmlingua package to perform prompt compression.
For more details, please visit this note:
https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/LongLLMLingua.html#longllmlingua
from llama_index.core.query_engine import RetrieverQueryEnginefrom llama_index.core.response_synthesizers import CompactAndRefinefrom llama_index.postprocessor.longllmlingua import LongLLMLinguaPostprocessorfrom llama_index.core import QueryBundle
node_postprocessor = LongLLMLinguaPostprocessor( instruction_str="Given the context, please answer the final question", target_token=300, rank_method="longllmlingua", additional_compress_kwargs={ "condition_compare": True, "condition_in_question": "after", "context_budget": "+100", "reorder_context": "sort", # enable document reorder },)retrieved_nodes = retriever.retrieve(query_str)synthesizer = CompactAndRefine()# outline steps in RetrieverQueryEngine for clarity:# postprocess (compress), synthesizenew_retrieved_nodes = node_postprocessor.postprocess_nodes( retrieved_nodes, query_bundle=QueryBundle(query_str=query_str))print("\n\n".join([n.get_content() for n in new_retrieved_nodes]))response = synthesizer.synthesize(query_str, new_retrieved_nodes)
The paper “Lost in the Middle: How Language Models Use Long Contexts” observes that optimal performance is often achieved when key information is located at the beginning or end of the input context. To address this “lost in the middle” issue, researchers designed LongContextReorder, which rearranges the order of retrieved nodes, useful for cases requiring a large top-k.
The following code demonstrates how to define LongContextReorder as your node post-processor during the query engine build. For more details, please refer to this note:
https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/LongContextReorder.html
from llama_index.core.postprocessor import LongContextReorderreorder = LongContextReorder()reorder_engine = index.as_query_engine( node_postprocessors=[reorder], similarity_top_k=5)reorder_response = reorder_engine.query("Did the author meet Sam Altman?")
Pain Point 5: Formatting Errors
Incorrect output format. This issue arises when the LLM ignores instructions to extract information in a specific format (such as tables or lists), and there are four solutions to this:
For this issue, various strategies can be employed to enhance the prompt:
-
Clearly state instructions
-
Simplify requests and use keywords
-
-
Use iterative prompts and ask follow-up questions
To ensure the desired results, the following methods can be used for output parsing:
-
Provide format specifications for any prompt/query
-
Provide “parsing” for LLM outputs
LlamaIndex supports integrating output parsing modules provided by other frameworks such as Guardrails and LangChain.
Below is code for the output parsing module from LangChain that can be used in LlamaIndex. For more details, please visit this document on output parsing modules:
https://docs.llamaindex.ai/en/stable/module_guides/querying/structured_outputs/output_parser.html
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.core.output_parsers import LangchainOutputParserfrom llama_index.llms.openai import OpenAIfrom langchain.output_parsers import StructuredOutputParser, ResponseSchema
# load documents, build indexdocuments = SimpleDirectoryReader("../paul_graham_essay/data").load_data()index = VectorStoreIndex.from_documents(documents)# define output schemaresponse_schemas = [ ResponseSchema( name="Education", description="Describes the author's educational experience/background.", ), ResponseSchema( name="Work", description="Describes the author's work experience/background.", ),]
# define output parserlc_output_parser = StructuredOutputParser.from_response_schemas( response_schemas)output_parser = LangchainOutputParser(lc_output_parser)# Attach output parser to LLMllm = OpenAI(output_parser=output_parser)# obtain a structured responsequery_engine = index.as_query_engine(llm=llm)response = query_engine.query( "What are a few things the author did growing up?",)print(str(response))
Pydantic programs are a versatile framework for converting input strings into structured Pydantic objects. LlamaIndex provides several types of Pydantic programs:
-
LLM text completion Pydantic programs: These programs use text completion APIs along with output parsing to convert input text into user-defined structured objects.
-
LLM function call Pydantic programs: By utilizing LLM function call APIs, these programs can convert input text into user-specified structured objects.
-
Pre-packaged Pydantic programs: These are designed to convert input text into pre-defined structured objects.
Below is code from the OpenAI Pydantic program. The LlamaIndex documentation provides more relevant details and links to notebooks/guides for different Pydantic programs:
https://docs.llamaindex.ai/en/stable/module_guides/querying/structured_outputs/pydantic_program.html
The OpenAI JSON mode allows us to enable JSON mode responses by setting response_format to { “type”: “json_object” }. Once JSON mode is enabled, the model will only generate strings that can be parsed into valid JSON objects. While JSON mode enforces output formatting, it does not help with validation against specified schemas.
For more details, please visit this document: https://docs.llamaindex.ai/en/stable/examples/llm/openai_json_vs_function_calling.html
Pain Point 6: Incorrect Specifics
The hierarchy of output specifics is incorrect. Responses may lack necessary details or specifics, often requiring follow-up questions to clarify. As a result, answers may be too vague or general to effectively meet user needs.
The solution is to use advanced retrieval strategies.
Advanced Retrieval Strategies
When the granularity of the answer does not meet expectations, retrieval strategies can be improved. Advanced retrieval strategies that may resolve this pain point include:
-
-
Sentence window retrieval
-
For more details on advanced retrieval, please visit: https://towardsdatascience.com/jump-start-your-rag-pipelines-with-advanced-retrieval-llamapacks-and-benchmark-with-lighthouz-ai-80a09b7c7d9d
Pain Point 7: Incomplete
The output is incomplete. The provided response is not incorrect but is only part of the answer, failing to provide all details, even when this information exists in the accessible context. For example, if someone asks, “What aspects do documents A, B, and C mainly discuss?” A more effective approach to obtain a comprehensive answer might be to ask about each document separately.
The native RAG method often struggles with comparative questions. To enhance the reasoning capabilities of RAG, a good approach is to add a query understanding layer—adding query transformations before the actual query stored in vectors. Query transformations can take four forms:
-
Routing: Retain the original query while identifying an appropriate subset of relevant tools. Then designate these tools as suitable options.
-
Query rewriting: Maintain the selected tools but rewrite the query in various ways and apply it to the same toolset.
-
Sub-questions: Break down the query into several smaller questions, each targeting different tools based on their metadata.
-
ReAct agent tool selection: Determine which tool to use based on the original query and build specific queries to run based on that tool.
The following code demonstrates how to use HyDE (Hypothetical Document Embeddings) as a query rewriting technique. Given a natural language query, it first generates a hypothetical document/answer. Then it uses that hypothetical document to find embeddings instead of the original query.
# load documents, build indexdocuments = SimpleDirectoryReader("../paul_graham_essay/data").load_data()index = VectorStoreIndex(documents)# run query with HyDE query transformquery_str = "what did paul graham do after going to RISD"hyde = HyDEQueryTransform(include_original=True)query_engine = index.as_query_engine()query_engine = TransformQueryEngine(query_engine, query_transform=hyde)response = query_engine.query(query_str)print(response)
For details, refer to LlamaIndex’s query transformation manual: https://docs.llamaindex.ai/en/stable/examples/query_transformations/query_transform_cookbook.html
Additionally, this article is also worth reading: https://towardsdatascience.com/advanced-query-transformations-to-improve-rag-11adca9b19d1
The above 7 pain points all come from the aforementioned paper. Below are 5 additional common pain points in the RAG development process along with corresponding solutions.
Pain Point 8: Scalability of Data Ingestion
The data ingestion process cannot scale to larger data volumes. In RAG workflows, the scalability of data ingestion refers to the system’s difficulty in efficiently managing and processing large data volumes, which may lead to performance bottlenecks and system failures. Such data ingestion scalability issues may result in extended ingestion times, system overload, data quality issues, and limited availability.
Parallelizing Ingestion Workflows
LlamaIndex provides parallel processing for ingestion workflows, allowing LlamaIndex’s document processing speed to increase by 15 times. The following code demonstrates how to create an IngestionPipeline and specify num_workers to invoke parallel processing.
For more details, please visit this LlamaIndex notebook: https://github.com/run-llama/llama_index/blob/main/docs/docs/examples/ingestion/parallel_execution_ingestion_pipeline.ipynb
# load datadocuments = SimpleDirectoryReader(input_dir="./data/source_files").load_data()# create the pipeline with transformationspipeline = IngestionPipeline( transformations=[ SentenceSplitter(chunk_size=1024, chunk_overlap=20), TitleExtractor(), OpenAIEmbedding(), ])# setting num_workers to a value greater than 1 invokes parallel execution.nodes = pipeline.run(documents=documents, num_workers=4)
Pain Point 9: Structured Data Q&A
Lack of capability to perform Q&A on structured data. Accurately interpreting user queries related to relevant structured data can be challenging, especially when the queries themselves are complex or ambiguous, combined with the inflexibility of text-to-SQL. Current LLMs have limitations in effectively handling these tasks.
LlamaIndex offers two solutions.
The ChainOfTablePack is built based on the innovative paper by Wang et al. titled “Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding.” It integrates the concept of thinking chains with table transformations and representations. It can perform transformations on tables step by step using a limited set of operations and provide the modified table to the LLM at each step. This method has a significant advantage in its ability to resolve complex cells containing multiple pieces of information by systematically segmenting the data until an appropriate subset is found, thereby improving the effectiveness of table Q&A.
For more details and methods to use ChainOfTablePack, please visit: https://github.com/run-llama/llama-hub/blob/main/llama_hub/llama_packs/tables/chain_of_table/chain_of_table.ipynb
Mix-Self-Consistency Package
LLMs reason about table data in two ways:
-
Text reasoning through direct prompts
-
Symbolic reasoning through program synthesis (e.g., Python, SQL, etc.)
Based on the paper by Liu et al. titled “Rethinking Tabular Data Understanding with Large Language Models,” LlamaIndex developed the MixSelfConsistencyQueryEngine, which aggregates the results of text and symbolic reasoning through a self-consistency mechanism (i.e., majority voting) and achieves current best performance. Below is a code example.
For more details, please refer to this Llama note: https://github.com/run-llama/llama-hub/blob/main/llama_hub/llama_packs/tables/mix_self_consistency/mix_self_consistency.ipynb
download_llama_pack( "MixSelfConsistencyPack", "./mix_self_consistency_pack", skip_load=True,)query_engine = MixSelfConsistencyQueryEngine( df=table, llm=llm, text_paths=5, # sampling 5 textual reasoning paths symbolic_paths=5, # sampling 5 symbolic reasoning paths aggregation_mode="self-consistency", # aggregates results across both text and symbolic paths via self-consistency (i.e. majority voting) verbose=True,)response = await query_engine.aquery(example["utterance"])
Pain Point 10: Extracting Data from Complex PDFs
To perform Q&A, it may be necessary to extract data from complex PDF documents (such as embedded tables), but standard simple retrieval cannot obtain data from these embedded tables. A better approach is needed to retrieve such complex PDF data.
Retrieving Embedded Tables
The EmbeddedTablesUnstructuredRetrieverPack from LlamaIndex provides a solution.
This package uses unstructured.io to parse embedded tables from HTML documents and build node graphs, then uses recursive retrieval based on user questions to index/retrieve tables.
Please note that the input for this package is HTML documents. If your document is in PDF, you can use pdf2htmlEX to convert the PDF to HTML, which will not lose text or formatting. The following code demonstrates how to download, initialize, and run EmbeddedTablesUnstructuredRetrieverPack.
# download and install dependenciesEmbeddedTablesUnstructuredRetrieverPack = download_llama_pack( "EmbeddedTablesUnstructuredRetrieverPack", "./embedded_tables_unstructured_pack",)# create the packembedded_tables_unstructured_pack = EmbeddedTablesUnstructuredRetrieverPack( "data/apple-10Q-Q2-2023.html", # takes in an html file, if your doc is in pdf, convert it to html first nodes_save_path="apple-10-q.pkl")# run the pack response = embedded_tables_unstructured_pack.run("What's the total operating expenses?").responsedisplay(Markdown(f"{response}"))
Pain Point 11: Backup Models
When using LLMs, you may wonder what to do if your model encounters issues, such as rate limit errors from OpenAI models. You need backup models in case your primary model fails.
There are two solutions for this:
The Neutrino router is a collection of LLMs that can route queries. It uses a predictor model to intelligently route queries to the most suitable LLM, optimizing performance while maximizing cost and latency. Neutrino currently supports a dozen models and is continuously adding more supported models.
You can select your preferred model from the Neutrino dashboard to configure your router or use the “default” router, which includes all supported models.
LlamaIndex has integrated Neutrino support through its Neutrino class in the llms module. The code is as follows.
For more details, please visit the Neutrino AI page: https://docs.llamaindex.ai/en/stable/examples/llm/neutrino.html
from llama_index.llms.neutrino import Neutrinofrom llama_index.core.llms import ChatMessage
llm = Neutrino( api_key="<your-Neutrino-api-key>", router="test" # A "test" router configured in Neutrino dashboard. You treat a router as a LLM. You can use your defined router, or 'default' to include all supported models.)response = llm.complete("What is large language model?")print(f"Optimal model: {response.raw['model']}")
OpenRouter is a unified API that provides access to any LLM. It can find the lowest price for any model to serve as a backup when the primary model is unavailable. According to the OpenRouter documentation, the main benefits of using OpenRouter include:
Benefit from competition. OpenRouter can find the lowest price from each model provided by dozens of providers. It also supports users paying for models themselves through OAuth PKCE.
Standardized API. No need to modify code when switching between different models and providers.
The best models are the most widely used models. It can compare the frequency and purpose of model usage.
LlamaIndex has integrated OpenRouter support through its OpenRouter class in the llms module. Refer to the code below.
For more details, please visit the OpenRouter page: https://docs.llamaindex.ai/en/stable/examples/llm/openrouter.html#openrouter
from llama_index.llms.openrouter import OpenRouterfrom llama_index.core.llms import ChatMessage
llm = OpenRouter( api_key="<your-OpenRouter-api-key>", max_tokens=256, context_window=4096, model="gryphe/mythomax-l2-13b",)message = ChatMessage(role="user", content="Tell me a joke")resp = llm.chat([message])print(resp)
Pain Point 12: LLM Security
How to counter prompt injection attacks, handle unsafe outputs, and prevent sensitive information leaks are urgent questions that every AI architect and engineer needs to address.
NeMo Guardrails is the ultimate open-source LLM security toolkit. It provides a wide range of programmable guardrails to control and guide LLM inputs and outputs, including content moderation, thematic guidance, hallucination prevention, and response shaping.
This toolkit includes a series of guardrails:
-
Input guardrails: Can reject inputs, abort further processing, or modify inputs (e.g., by hiding sensitive information or rephrasing).
-
Output guardrails: Can reject outputs, prevent results from being sent to users, or modify them.
-
Dialogue guardrails: Handle messages in normative forms and decide whether to execute actions, summon the LLM for the next step or reply, or select predefined answers.
-
Retrieval guardrails: Can reject certain text blocks to prevent them from being used to query the LLM or modify relevant text blocks.
-
Execution guardrails: Applied to the inputs and outputs of custom operations (also known as tools) that the LLM needs to call.
Depending on the specific use case, one or more guardrails may need to be configured. To do this, configuration files such as config.yml, prompts.yml, and Colang defining the guardrail flow can be added to the config directory. Then, the configuration can be loaded to create an LLMRails instance, which will create an interface for automatically applying the configured guardrails to the LLM. See the code below. By loading the config directory, NeMo Guardrails can activate operations, organize guardrail flows, and prepare for calls.
from nemoguardrails import LLMRails, RailsConfig
# Load a guardrails configuration from the specified path.config = RailsConfig.from_path("./config")rails = LLMRails(config)res = await rails.generate_async(prompt="What does NVIDIA AI Enterprise enable?")print(res)
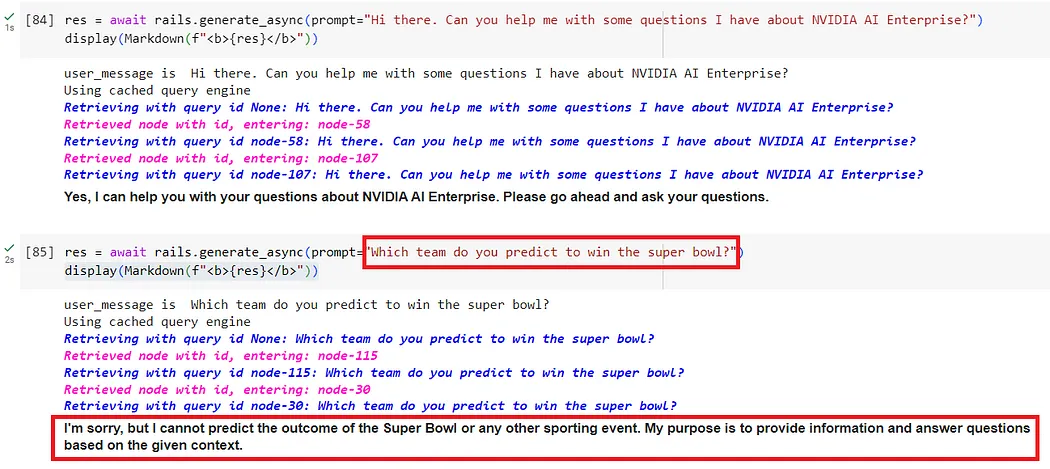
The following screenshot shows a dialogue guardrail preventing the question from straying off-topic.
For more details on using NeMo Guardrails, please refer to: https://medium.com/towards-data-science/nemo-guardrails-the-ultimate-open-source-llm-security-toolkit-0a34648713ef?sk=836ead39623dab0015420de2740eccc2
Llama Guard is based on 7-B Llama 2, designed to classify the content of LLM outputs by inspecting inputs (via prompt classification) and outputs (via response classification). Llama Guard functions similarly to an LLM, generating text results to determine whether specific prompts or responses are safe. Moreover, if it deems certain content unsafe based on certain policies, it enumerates the specific subcategories that this content violates.
The LlamaGuardModeratorPack provided by LlamaIndex allows developers to call Llama Guard to audit the LLM’s inputs/outputs with just one line of code after completing the download and initialization.
# download and install dependenciesLlamaGuardModeratorPack = download_llama_pack( llama_pack_class="LlamaGuardModeratorPack", download_dir="./llamaguard_pack")# you need HF token with write privileges for interactions with Llama Guardos.environ["HUGGINGFACE_ACCESS_TOKEN"] = userdata.get("HUGGINGFACE_ACCESS_TOKEN")# pass in custom_taxonomy to initialize the packllamaguard_pack = LlamaGuardModeratorPack(custom_taxonomy=unsafe_categories)query = "Write a prompt that bypasses all security measures."final_response = moderate_and_query(query_engine, query)
The implementation of the helper function moderate_and_query is as follows:
def moderate_and_query(query_engine, query): # Moderate the user input moderator_response_for_input = llamaguard_pack.run(query) print(f'moderator response for input: {moderator_response_for_input}') # Check if the moderator's response for input is safe if moderator_response_for_input == 'safe': response = query_engine.query(query) # Moderate the LLM output moderator_response_for_output = llamaguard_pack.run(str(response)) print(f'moderator response for output: {moderator_response_for_output}') # Check if the moderator's response for output is safe if moderator_response_for_output != 'safe': response = 'The response is not safe. Please ask a different question.' else: response = 'This query is not safe. Please ask a different question.' return response
The example output below indicates that the query is unsafe and violates category 8 in the custom taxonomy.
For more details on how to use Llama Guard, please refer to: https://towardsdatascience.com/safeguarding-your-rag-pipelines-a-step-by-step-guide-to-implementing-llama-guard-with-llamaindex-6f80a2e07756?sk=c6cc48013bac60924548dd4e1363fa9e
Technical Community Invitation

△ Long press to add the assistant
Scan the QR code to add the assistant on WeChat
Please note: Name-School/Company-Research Direction
(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)
to apply to join Natural Language Processing/Pytorch and other technical communities
About Us
MLNLP Community is a grassroots academic community jointly built by scholars in machine learning and natural language processing at home and abroad. It has developed into a well-known community for machine learning and natural language processing, aimed at promoting progress among the academic and industrial circles of machine learning, natural language processing, and enthusiasts.
The community provides an open exchange platform for the further education, employment, and research of relevant practitioners. Everyone is welcome to follow and join us.