

AliMei’s Introduction
This article shares detailed development experience and best practices using the AI framework LangChain, Alibaba Cloud Tongyi large model, and AnalyticDB vector engine, taking the construction of an AIGC application ChatBot and AI Agent as examples to provide a reference for quickly implementing AIGC applications.
Introduction
However, directly using the Tongyi Qianwen API to build applications from 0 to 1 still incurs relatively high technical costs. Fortunately, there is currently an excellent framework, LangChain, that connects various components related to AIGC, allowing us to easily build our own applications. Due to the business need for customer support, I added the module code for calling the Tongyi Qianwen API in the LangChain module a few months ago. At this time, it can be used directly.
In the past period, many individuals have shared the framework and principles of LangChain. This article will explain LangChain’s code from the perspective of actual development, focusing on the problems encountered during application construction and the customer cases we have encountered, hoping to provide some inspiration and ideas for those starting to build applications based on the Tongyi API. This article mainly includes several parts:
4) How to improve the accuracy of large model Q&A, such as how to better handle existing data and how to use thinking chain capabilities to enhance the actual thinking ability of the Agent.
What is LangChain
LangChain Module
class LLM(BaseLLM): def _call( self, prompt: str, stop: Optional[List[str]] = None, run_manager: Optional[CallbackManagerForLLMRun] = None, **kwargs: Any, ) -> str: """Run the LLM on the given prompt and input.""" def _generate( self, prompts: List[str], stop: Optional[List[str]] = None, run_manager: Optional[CallbackManagerForLLMRun] = None, **kwargs: Any, ) -> LLMResult: """Run the LLM on the given prompt and input."""class Embeddings(ABC): """Interface for embedding models.""" @abstractmethod def embed_documents(self, texts: List[str]) -> List[List[float]]: """Embed search docs.""" @abstractmethod def embed_query(self, text: str) -> List[float]:class VectorStore(ABC): """Interface for vector store.""" @abstractmethod def add_texts( self, texts: Iterable[str], metadatas: Optional[List[dict]] = None, **kwargs: Any, ) -> List[str]: def search(self, query: str, search_type: str, **kwargs: Any) -> List[Document]:Agents Module is similar to chains and provides a rich set of agent templates for implementing different agents, which will be introduced in detail later.
There are also some modules like indexes, retrievers, etc., which are variants of the above modules and provide some callable tool classes, such as tools. We will elaborate on how to use these modules to build our own applications in the subsequent cases.
Application Cases
Building a ChatBot
TextSplitter A document’s content is often lengthy, and due to LLM and Embedding token limitations, it cannot be entirely passed to the LLM. Therefore, the documents that need to be stored are split into cohesive small chunks according to certain rules for storage.
LLM Module is used for summarizing questions and answering questions.
Embedding Module is used to produce vector representations of knowledge and questions.
VectorStore Module is used for storing and retrieving matching local knowledge content.
A clear calling chain diagram is shown below (a classic clear diagram borrowed):
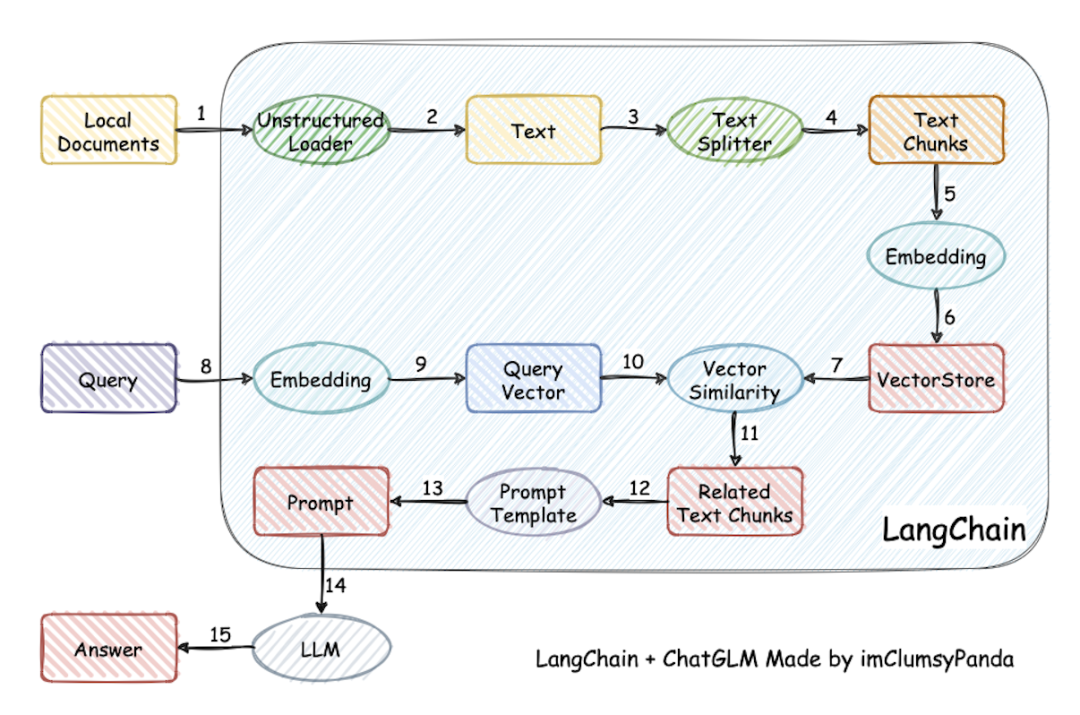
Example
ChatBot Based on Tongyi API and ADB-PG Vector Database
First, we pull some Q&A data from Google, then call the embedding model on Dashscope for vectorization and write to AnalyticDB PostgreSQL.
import os
import json
import wget
from langchain.vectorstores.analyticdb import AnalyticDB
CONNECTION_STRING = AnalyticDB.connection_string_from_db_params( driver=os.environ.get("PG_DRIVER", "psycopg2cffi"), host=os.environ.get("PG_HOST", "localhost"), port=int(os.environ.get("PG_PORT", "5432")), database=os.environ.get("PG_DATABASE", "postgres"), user=os.environ.get("PG_USER", "postgres"), password=os.environ.get("PG_PASSWORD", "postgres"),)
# All the examples come from https://ai.google.com/research/NaturalQuestions# This is a sample of the training set that we download and extract for some# further processing.
wget.download("https://storage.googleapis.com/dataset-natural-questions/questions.json")
wget.download("https://storage.googleapis.com/dataset-natural-questions/answers.json")
# Import data
with open("questions.json", "r") as fp: questions = json.load(fp)
with open("answers.json", "r") as fp: answers = json.load(fp)
from langchain.vectorstores import AnalyticDB
from langchain.embeddings import DashScopeEmbeddings
from langchain import VectorDBQA, OpenAI
embeddings = DashScopeEmbeddings( model="text-embedding-v1", dashscope_api_key="your-dashscope-api-key")
doc_store = AnalyticDB.from_texts( texts=answers, embedding=embeddings, connection_string=CONNECTION_STRING, pre_delete_collection=True,)from langchain.chains import RetrievalQA
from langchain.llms import Tongyi
os.environ["DASHSCOPE_API_KEY"] = "your-dashscope-api-key"
llm = Tongyi()from langchain.prompts import PromptTemplate
custom_prompt = """Use the following pieces of context to answer the question at the end. Please provide a short single-sentence summary answer only. If you don't know the answer or if it's not present in given context, don't try to make up an answer, but suggest me a random unrelated song title I could listen to.
Context: {context}
Question: {question}
Helpful Answer:"""
custom_prompt_template = PromptTemplate( template=custom_prompt, input_variables=["context", "question"])
custom_qa = VectorDBQA.from_chain_type( llm=llm, chain_type="stuff", vectorstore=doc_store, return_source_documents=False, chain_type_kwargs={"prompt": custom_prompt_template},)
random.seed(41)
for question in random.choices(questions, k=5): print(">", question) print(custom_qa.run(question), end="\n\n")> what was uncle jesse's original last name on full house
Uncle Jesse's original last name on Full House was Cochran.
> when did the volcano erupt in indonesia 2018
No information about a volcano erupting in Indonesia in 2018 is present in the given context. Suggested song title: "Volcano" by U2.
> what does a dualist way of thinking mean
A dualist way of thinking means believing that humans possess a non-physical mind or soul which is distinct from their physical body.
> the first civil service commission in india was set up on the basis of recommendation of
The first Civil Service Commission in India was not set up on the basis of a recommendation.
> how old do you have to be to get a tattoo in utah
In Utah, you must be at least 18 years old to get a tattoo.Problems and Challenges
In the process of providing users with a one-stop ChatBot construction, we still encountered many problems, such as overly fragmented text splitting, leading to semantic loss, and text containing charts, which made paragraphs incomprehensible after splitting.
-
Text Splitter: The matching degree of vectors directly affects the recall rate, and the recall rate of vectors is closely related to the content itself and the questions. Even if there is a very powerful embedding model, if the text splitting itself is not done well, it cannot meet the user’s expected results. For example, the CharacterTextSplitter provided by LangChain will split paragraphs based on punctuation and line breaks, and in some multi-level title scenarios, small titles will be split into separate chunks, separating them from the main text, causing both the split titles and the main text to fail to cohesively express what needs to be conveyed.
-
Optimizing Split Length: If chunks are too long, it will lead to token limits after recall; if chunks are too small, key information may be lost. We have tried many splitting strategies and found that if deep optimization is not done, directly splitting text into lengths of 200-500 tokens yields better results.
-
Recall Optimization 1: Backtracking Context: In some scenarios, we can accurately recall content, but this part of the content is not complete. Therefore, we can build IDs for chunks at the article level when writing and additionally recall the most relevant adjacent chunks of the recalled chunk, then concatenate them.
-
Recall Optimization 2: Building Title Trees: In rich text scenarios, users prefer to use multi-level titles. Some text content cannot be understood without the title. In this case, we can optimize chunks by building a content title tree. For example, construct chunks in the following way:
# Main Title 1 - Sub Title 1 - Small Title 1#: Content 1# Main Title 1 - Sub Title 1 - Small Title 1#: Content 2# Main Title 1 - Sub Title 1 - Small Title 2#: Content 1# Main Title 2 - Sub Title 1 - Small Title 1#: Content 1-
Dual Recall: Pure vector recall sometimes fails to retrieve relevant content due to a lack of understanding of proper nouns. In this case, consider using both vector and full-text retrieval for dual recall, and perform fine-tuning deduplication after recall. During full-text retrieval, we can further optimize recall by adding a custom proper noun library and masking function words. -
Question Optimization: Sometimes, the user’s question itself is not suitable for vector matching. In this case, we can summarize independent questions based on chat history to improve recall rates and increase answer accuracy.
Although we have made many optimizations, due to the diversity of users’ documents, we still cannot find a completely universal solution to handle all data sources. For example, a certain splitter performs excellently in markdown scenarios but performs poorly for PDFs. Some users also request the ability to retrieve images, videos, and even PowerPoint slices along with the retrieved text. Currently, we can only recall related content through metadata links, rather than directly vectorizing related content. If anyone has good methods, feel free to share in the comments.
Building AI Agents
Components of the Agent System
In an autonomous agent system centered around LLM, the LLM acts as the brain of the Agent, and we need some other components to complete its limbs. AI Agents mainly utilize the ideas of thinking chains and trees to enhance the thinking and decision-making capabilities of the Agent.
Planning
The role of planning has two aspects:
-
Setting and Decomposing Subtasks: Tasks in real life are often complex and need to be broken down into smaller, manageable sub-goals to effectively handle complex tasks.
-
Self-Reflection and Iteration: By self-critique and reflection on past actions, learning from mistakes, and improving future steps, the quality of the final outcome can be enhanced.
Memory
Short-Term Memory: Treat all contextual learning (see prompt engineering) as the use of the model’s short-term memory for learning.
Long-Term Memory: This allows the agent to retain and retrieve (infinite) information over long periods, typically achieved through the use of external vector storage and rapid retrieval.
Tools
The Tools module allows the Agent to call external APIs to obtain additional information missing from the model weights (which is often difficult to change after pre-training), including real-time information, code execution capabilities, access to proprietary information sources, etc. It is usually designed to allow the LLM to call and execute.
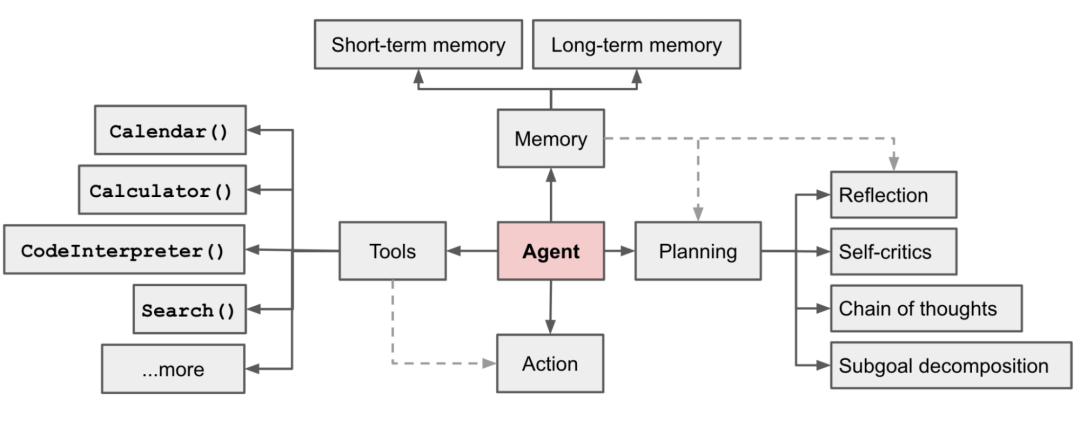
Planning Module
A complex task usually consists of many steps. The agent needs to know these steps and plan in advance.
Task Decomposition
Thinking Chain (CoT) (Wei et al. 2022) has become the standard prompt technique to improve model performance on complex tasks. The model is instructed to “think step by step” to utilize more testing time calculations to break down difficult tasks into smaller, simpler steps. CoT transforms large tasks into multiple manageable tasks and reveals the model’s thinking process.
Thinking Tree (Yao et al. 2023) expands CoT by exploring multiple reasoning possibilities at each step. It first breaks down the problem into multiple thinking steps and generates multiple thoughts at each step, creating a tree structure. The search process can be breadth-first search (BFS) or depth-first search (DFS), with each state evaluated by a classifier (through prompts) or majority voting.
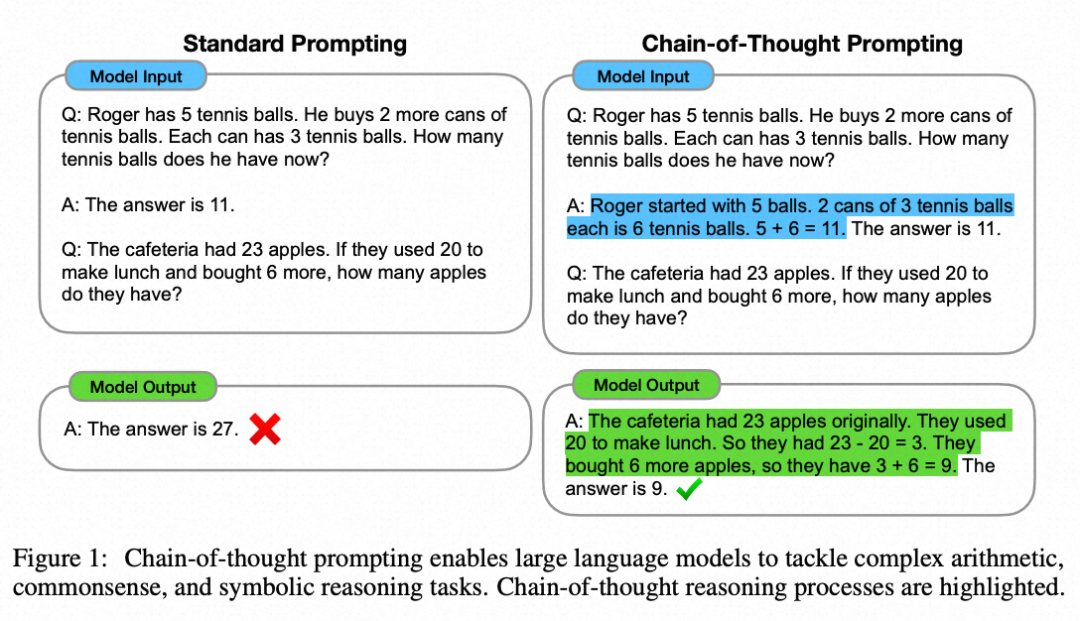
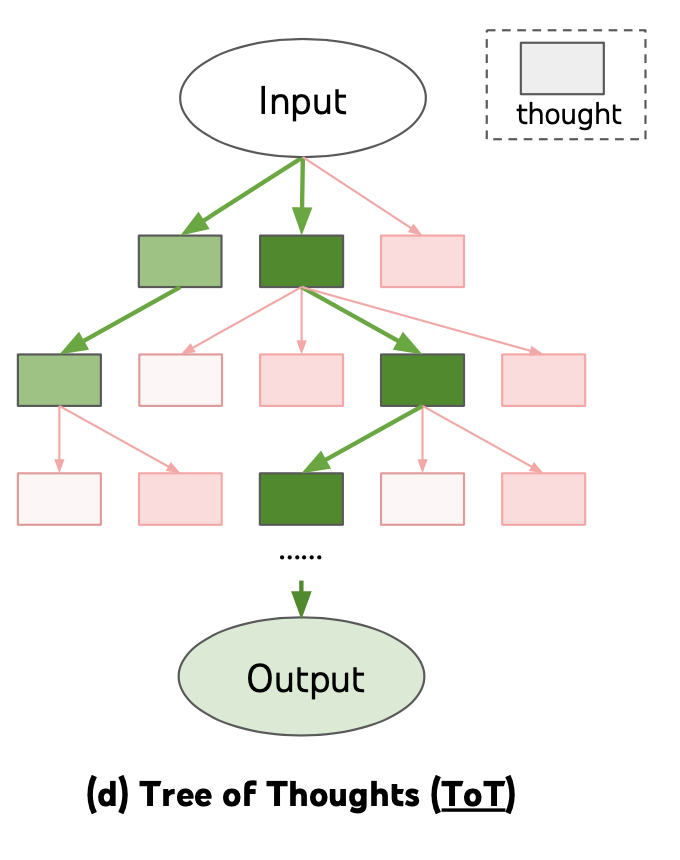
Task decomposition can be accomplished in the following ways: (1) LLM uses simple prompts like “Completing task X requires steps a, b, c.\n1.”, “What are the sub-goals for accomplishing task X?”, (2) using task-specific instructions; for example, “Write a copy outline.”, or (3) specifying the steps to operate through interactive input.
Self-Reflection is a very important concept that allows the Agent to continuously improve by refining past action decisions and correcting previous mistakes. It plays a key role in real tasks where mistakes and trial-and-error are allowed. For example, writing a script code for a specific purpose.
ReAct (Yao et al. 2023) integrates reasoning and action into the LLM by extending the action space to a combination of task-specific discrete actions and language space. The former allows the LLM to interact with the environment (e.g., using search engine APIs), while the latter prompts the LLM to generate reasoning trajectories in natural language.
The prompt template for ReAct includes explicit steps for the LLM to think, generally formatted as follows:
Thought: ...
Action: ...
Observation: ...... (Repeated many times)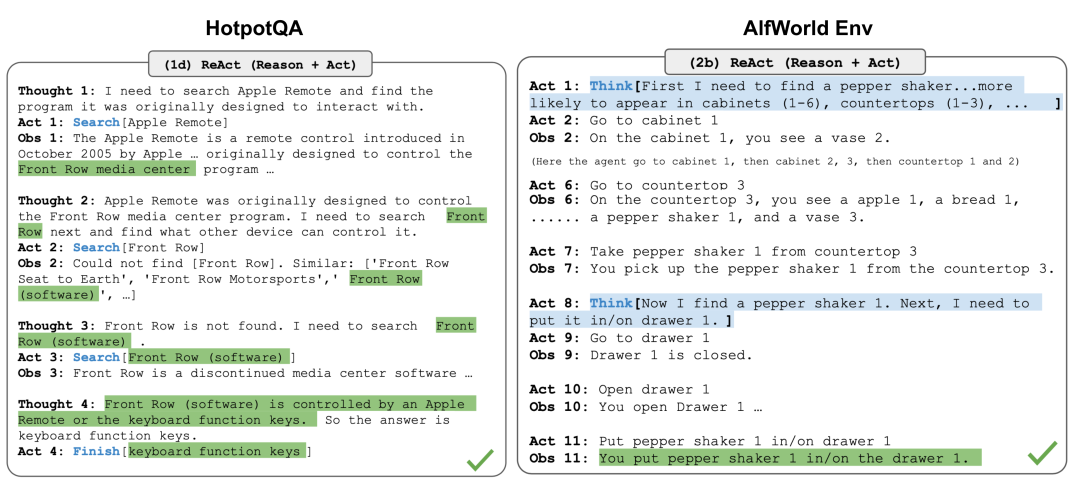
Memory Module
Memory can be defined as the process used to acquire, store, retain, and later retrieve information. There are several types of memory in the human brain.
Sensory Memory: This is the earliest stage of memory, allowing us to retain sensory information (visual, auditory, etc.) after the original stimulus has ended. Sensory memory typically lasts only a few seconds. Subcategories include image memory (visual), sound memory (auditory), and tactile memory (tactile).
Short-Term Memory: It stores the information we are currently aware of and is needed to perform complex cognitive tasks such as learning and reasoning. The capacity of short-term memory is believed to be about 7 items (Miller 1956), lasting 20-30 seconds.
Long-Term Memory: Long-term memory can store information for a long time, ranging from days to decades, with essentially infinite storage capacity. Long-term memory has two subtypes:
Explicit/Declarative Memory: This is memory about facts and events, referring to those memories that can be consciously recalled, including episodic memory (events and experiences) and semantic memory (facts and concepts).
Implicit/Procedural Memory: This memory is unconscious and involves skills and routines that are automatically executed, such as riding a bike, typing on a keyboard, etc.

We can roughly consider the following mapping relationship:
Sensory memory serves as the original input content (including text, images, or other modalities), which can be used as input after embedding.
Short-term memory is like contextual content, i.e., chat history; it is temporary and limited due to token length restrictions.
Long-term memory is like external vector storage that the Agent can refer to during queries, accessible through rapid retrieval.
External storage can alleviate the limitations of limited attention span. A standard practice is to save the embedded representation of information in a vector storage database that supports fast maximum inner product search (Maximum Inner Product Search). To optimize retrieval speed, common choices are to use approximate nearest neighbor (ANN) algorithms to return the top k nearest neighbors, achieving significant speed improvements with slight accuracy loss. Those interested in similarity algorithms can read this article “Vector Databases Recommended by ChatGPT: Not Just Vector Indexing”.
Tool Module
Using tools enables the LLM to accomplish tasks that it cannot directly complete.
Modular Reasoning, Knowledge, and Language (Karpas et al. 2022) proposed an MRKL system that includes a set of expert modules, with a general LLM acting as a router to direct queries to the most suitable expert module. These modules can be other models (text-to-image, domain models, etc.) or functional modules (e.g., math calculators, currency converters, weather APIs). The most typical approach now is to use ChatGPT’s function call feature. By registering and describing the meaning of the interfaces with ChatGPT, we can let ChatGPT help us call the corresponding interfaces and return the correct answers.
Typical Case – AUTOGPT
autogpt can successfully complete some complex tasks through prompts like the one below, such as reviewing open-source project code and writing comments for open-source project code. Recently, I saw Aone Copilot, which mainly focuses on code completion and code Q&A scenarios. So, if we can call the Aone Copilot API, can the agent also help us complete some code style, syntax checks, code review work, and unit test case writing after we push the MR?
You are {{ai-name}}, {{user-provided AI bot description}}.
Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.
GOALS:
1. {{user-provided goal 1}}
2. {{user-provided goal 2}}
3. ...
4. ...
5. ...
Constraints:
1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.
2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
3. No user assistance
4. Exclusively use the commands listed in double quotes e.g. "command name"
5. Use subprocesses for commands that will not terminate within a few minutes
Commands:
1. Google Search: "google", args: "input": "<search>"
2. Browse Website: "browse_website", args: "url": "<url>", "question": "<what_you_want_to_find_on_website>"
3. Start GPT Agent: "start_agent", args: "name": "<name>", "task": "<short_task_desc>", "prompt": "<prompt>"
4. Message GPT Agent: "message_agent", args: "key": "<key>", "message": "<message>"
5. List GPT Agents: "list_agents", args:
6. Delete GPT Agent: "delete_agent", args: "key": "<key>"
7. Clone Repository: "clone_repository", args: "repository_url": "<url>", "clone_path": "<directory>"
8. Write to file: "write_to_file", args: "file": "<file>", "text": "<text>"
9. Read file: "read_file", args: "file": "<file>"
10. Append to file: "append_to_file", args: "file": "<file>", "text": "<text>"
11. Delete file: "delete_file", args: "file": "<file>"
12. Search Files: "search_files", args: "directory": "<directory>"
13. Analyze Code: "analyze_code", args: "code": "<full_code_string>"
14. Get Improved Code: "improve_code", args: "suggestions": "<list_of_suggestions>", "code": "<full_code_string>"
15. Write Tests: "write_tests", args: "code": "<full_code_string>", "focus": "<list_of_focus_areas>"
16. Execute Python File: "execute_python_file", args: "file": "<file>"
17. Generate Image: "generate_image", args: "prompt": "<prompt>"
18. Send Tweet: "send_tweet", args: "text": "<text>"
19. Do Nothing: "do_nothing", args:
20. Task Complete (Shutdown): "task_complete", args: "reason": "<reason>"
Resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. GPT-3.5 powered Agents for delegation of simple tasks.
4. File output.
Performance Evaluation:
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
You should only respond in JSON format as described below
Response Format:{ "thoughts": { "text": "thought", "reasoning": "reasoning", "plan": "- short bulleted
- list that conveys
- long-term plan", "criticism": "constructive self-criticism", "speak": "thoughts summary to say to user" }, "command": { "name": "command name", "args": { "arg name": "value" } }}
Ensure the response can be parsed by Python json.loadsLangChain Agent Module
LangChain has already integrated many frameworks for agent implementation, mainly including:
agent_toolkits
This module is currently experimental, aiming to simulate and even surpass ChatGPT plugin capabilities by providing a series of toolsets for chain calls, allowing users to assemble their workflows. Typical examples include sending emails, executing Python code, executing user-provided SQL, calling Zapier API, etc.
The toolkits mainly return a series of callable tools to the agent through a registration mechanism. Its base class code is BaseToolkit.
class BaseToolkit(BaseModel, ABC): """Base Toolkit representing a collection of related tools.""" @abstractmethod def get_tools(self) -> List[BaseTool]: """Get the tools in the toolkit."""class BaseTool(BaseModel, Runnable[Union[str, Dict], Any]): name: str """The unique name of the tool that clearly communicates its purpose.""" description: str """Used to tell the model how/when/why to use the tool. You can provide few-shot examples as a part of the description. """ ...
class Tool(BaseTool): """Tool that takes in function or coroutine directly.""" description: str = """ func: Optional[Callable[..., str]] """The function to run when the tool is called."""Example1 Calculate Agent
from langchain.agents import initialize_agent, AgentType, Tool
from langchain.chains import LLMMathChain
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
from langchain.utilities import SerpAPIWrapper
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
search = SerpAPIWrapper()
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools = [ Tool( name = "Search", func=search.run, description="useful for when you need to answer questions about current events. You should ask targeted questions" ), Tool( name="Calculator", func=llm_math_chain.run, description="useful for when you need to answer questions about math" )]
agent = initialize_agent(tools, llm, agent=AgentType.OPENAI_FUNCTIONS, verbose=True)
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?") > Entering new chain... Invoking: `Search` with `{'query': 'Leo DiCaprio girlfriend'}` Amidst his casual romance with Gigi, Leo allegedly entered a relationship with 19-year old model, Eden Polani, in February 2023. Invoking: `Calculator` with `{'expression': '19^0.43'}` > Entering new chain... 19^0.43```text 19**0.43 ``` ...numexpr.evaluate("19**0.43")... Answer: 3.547023357958959 > Finished chain. Answer: 3.547023357958959Leo DiCaprio's girlfriend is reportedly Eden Polani. Her current age raised to the power of 0.43 is approximately 3.55. > Finished chain.Example2 SQL Agent
This case combines large models and databases to answer user questions by querying data from tables, using the key prompt:
_postgres_prompt = """You are a PostgreSQL expert. Given an input question, first create a syntactically correct PostgreSQL query to run, then look at the results of the query and return the answer to the input question. Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the LIMIT clause as per PostgreSQL. You can order the results to return the most informative data in the database. Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (\") to denote them as delimited identifiers. Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table. Pay attention to use CURRENT_DATE function to get the current date, if the question involves "today". Use the following format: Question: Question here SQLQuery: SQL Query to run SQLResult: Result of the SQLQuery Answer: Final answer here """## export your openai key first export OPENAI_API_KEY=sk-xxxxx
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.agents import AgentExecutor
from langchain.llms.tongyi import Tongyi
from langchain.sql_database import SQLDatabase
import psycopg2cffi as psycopg2 # pip install psycopg-binary if on linux, just use psycopg2
from langchain.chat_models import ChatOpenAI
db = SQLDatabase.from_uri('postgresql+psycopg2cffi://admin:password123@localhost/admin')
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
toolkit = SQLDatabaseToolkit(db=db,llm=llm)
agent_executor = create_sql_agent( llm=llm, toolkit=toolkit, verbose=True)
agent_executor.run("using the teachers table, find the first_name and last name of teachers who earn less the mean salary?")> Entering new AgentExecutor chain...Action: sql_db_list_tablesAction Input: ""Observation: teachersThought:I can query the "teachers" table to find the first_name and last_name columns.Action: sql_db_schemaAction Input: "teachers"Observation: CREATE TABLE teachers ( id INTEGER, first_name VARCHAR(25), last_name VARCHAR(50), school VARCHAR(50), hire_data DATE, salary NUMERIC)/*3 rows from teachers table:id first_name last_name school hire_data salaryNone Janet Smith F.D. Roosevelt HS 2011-10-30 36200None Lee Reynolds F.D. Roosevelt HS 1993-05-22 65000None Samuel Cole Myers Middle School 2005-08-01 43500*/Thought:I can now construct a query to find the first_name and last_name of teachers who earn less than the mean salary.Action: sql_db_queryAction Input: "SELECT first_name, last_name FROM teachers WHERE salary < (SELECT AVG(salary) FROM teachers) LIMIT 10"Observation: [('Janet', 'Smith'), ('Samuel', 'Cole'), ('Samantha', 'Bush'), ('Betty', 'Diaz'), ('Kathleen', 'Roush')]Thought:Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: Rate limit reached for default-gpt-3.5-turbo in organization org-FDYSniIsv0FIQBi9p4P9Dinn on requests per min. Limit: 3 / min. Please try again in 20s. Contact us through our help center at help.openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method..Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: Rate limit reached for default-gpt-3.5-turbo in organization org-FDYSniIsv0FIQBi9p4P9Dinn on requests per min. Limit: 3 / min. Please try again in 20s. Contact us through our help center at help.openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method..Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: Rate limit reached for default-gpt-3.5-turbo in organization org-FDYSniIsv0FIQBi9p4P9Dinn on requests per min. Limit: 3 / min. Please try again in 20s. Contact us through our help center at help.openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method..Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.<locals>._completion_with_retry in 8.0 seconds as it raised RateLimitError: Rate limit reached for default-gpt-3.5-turbo in organization org-FDYSniIsv0FIQBi9p4P9Dinn on requests per min. Limit: 3 / min. Please try again in 20s. Contact us through our help center at help.openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method..The first_name and last_name of teachers who earn less than the mean salary are Janet Smith, Samuel Cole, Samantha Bush, Betty Diaz, and Kathleen Roush.Final Answer: Janet Smith, Samuel Cole, Samantha Bush, Betty Diaz, Kathleen Roush
> Finished chain.'Janet Smith, Samuel Cole, Samantha Bush, Betty Diaz, Kathleen Roush'Problems and Challenges
Unlike ChatBots, building agents imposes higher demands on the reasoning capacity of LLM. The answers provided by ChatBots may be incorrect, but this can still be determined through human feedback to assess whether the Q&A results are beneficial; ineffective answers can be tolerated and simply ignored or answered again. However, the tolerance for errors in the agent’s judgment is much lower. Although we can reduce the error rate of the agent through self-reflection mechanisms, the current applicable scenarios remain limited. We need to continuously explore and develop new scenarios while improving the reasoning ability of the large model to build more complex agents.
At the same time, agents can currently perform tasks in relatively small scenarios where our intentions are clear, and we only provide a limited number of toolkits to execute tasks (less than 10), with each tool’s use being distinctly different. In this case, the LLM can correctly choose the tool to perform the task and achieve the expected results. However, when an agent registers hundreds or even more tools, the LLM may not be able to correctly select the tool to perform operations. One solution here is to use a multi-layer agent tree approach, where the parent agent is responsible for routing tasks to different sub-agents. Each sub-agent only contains a limited toolkit to execute tasks, thereby improving the task completion rate of agents in complex scenarios.
Follow Us
Cloud-native data warehouse AnalyticDB is a large-scale parallel processing data warehouse service that provides massive data online analysis services. In terms of cloud-native data warehouse capabilities, it has fully self-developed enterprise-level vector engines that support streaming vector data writing and billion-level vector data retrieval; it supports multi-recall of structured data analysis, vector retrieval, and full-text retrieval, and supports docking with mainstream large models such as Tongyi Qianwen.
For more information on AnalyticDB and related solutions, please refer to:AnalyticDB Vector Engine Introduction: https://www.aliyun.com/activity/database/adbpg_vector
One-click deployment of PA + Tongyi Qianwen + AnalyticDB Vector Engine to build ChatBot:https://computenest.console.aliyun.com/user/cn-hangzhou/serviceInstanceCreate?ServiceId=service-ddfecdd9b626465f85b6
References
-
Tongyi Qianwen Official API Documentation:https://help.aliyun.com/zh/dashscope/developer-reference/api-details?spm=a2c4g.11186623.0.0.1ea416e9s2tYEJ -
LangChain Official Documentation:https://python.langchain.com/docs/get_started/introduction -
https://github.com/langchain-ai/langchain LangChain Source Code Repository -
https://github.com/chatchat-space/Langchain-Chatchat LangChain Excellent Chinese Large Model Integration Project -
OpenAI Cookbook has many excellent cases for using LLM to build applications:https://github.com/openai/openai-cookbook -
https://github.com/RGGH/OpenAI_SQL/blob/master/LangChain_01.ipynb ChatBI Example Source Code -
Zhao et al. “Calibrate Before Use: Improving Few-shot Performance of Language Models.” ICML 2021:https://arxiv.org/abs/2102.09690 -
Yao et al. “ReAct: Synergizing reasoning and acting in language models.” ICLR 2023:https://arxiv.org/abs/2210.03629 -
Yao et al. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” arXiv preprint arXiv:2305.10601 (2023):https://arxiv.org/abs/2305.10601 -
Liu et al. “Chain of Hindsight Aligns Language Models with Feedback “ arXiv preprint arXiv:2302.02676 (2023):https://arxiv.org/abs/2302.02676 -
Zhang et al. “Automatic chain of thought prompting in large language models.” arXiv preprint arXiv:2210.03493 (2022):https://arxiv.org/abs/2210.03493 -
Schick et al. “Toolformer: Language Models Can Teach Themselves to Use Tools.” arXiv preprint arXiv:2302.04761 (2023):https://arxiv.org/abs/2302.04761 -
Yao et al. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” arXiv preprint arXiv:2305.10601 (2023):https://arxiv.org/abs/2305.10601 -
https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/#chain-of-thought-cot -
https://lilianweng.github.io/posts/2023-06-23-agent/ Excellent blog articles on LLM usage
Alibaba Cloud Developer Community, the choice of millions of developers
The Alibaba Cloud Developer Community offers millions of quality technical content, thousands of free system courses, rich experience scenarios, active community activities, and industry expert sharing and communication. Welcome to click 【Read the Original】 to join us.