
1. Title:
KIMI K1.5: SCALING REINFORCEMENT
LEARNING WITH LLMS
Link:
https://github.com/MoonshotAI/kimi-k1.5
2. Authors and Key Points:
1- Authors
The paper was published by: Kimi Team of the Dark Side of the Moon
2- Key Points
1. Core Content • Background and Motivation: • Traditional language model pre-training methods (based on next-word prediction) perform well in scaling computational resources but are limited by the amount of high-quality training data available. • Reinforcement Learning (RL) provides a new direction for the continuous improvement of language models, guiding model exploration through a reward mechanism, thus breaking through the limitations of static datasets. • Introduction of Kimi k1.5 Model: • Kimi k1.5 is a multimodal language model (LLM) trained through reinforcement learning, aiming to enhance model performance on complex reasoning tasks. • Model training includes pre-training, supervised fine-tuning (SFT), long reasoning path (long-CoT) supervised fine-tuning, and reinforcement learning (RL) phases. • Key Methods and Techniques: • Long Context Scaling: Extends the context window for reinforcement learning to 128k, improving training efficiency through partial rollouts. • Improved Policy Optimization Method: Proposes a policy optimization algorithm based on online mirror descent, incorporating length penalties and data recipe optimization. • Simplistic Framework Design: Achieves efficient reasoning capabilities without relying on complex techniques (such as Monte Carlo tree search, value functions, and process reward models) through long context scaling. • Multimodal Capability: The model is trained on both text and visual data, supporting cross-modal reasoning. • Long to Short Reasoning Path Conversion: • Proposes various methods (such as model merging, shortest rejection sampling, DPO, and long to short RL) to transfer knowledge from long reasoning path models to short reasoning path models, significantly improving the performance of short reasoning path models. • Experiments and Results: • Kimi k1.5 performs excellently in multiple benchmarks, including AIME, MATH 500, Codeforces, and MathVista, comparable to OpenAI’s o1 model. • Short reasoning path models outperform existing models (such as GPT-4o and Claude Sonnet 3.5) in tasks like LiveCodeBench, AIME, and MATH 500, with performance improvements of up to +550%. • Infrastructure Optimization: • Proposes partial rollouts and hybrid deployment strategies to optimize the efficiency and scalability of long context reinforcement learning. 2. Main Contributions
• Proposes an efficient reinforcement learning framework that significantly enhances the performance of multimodal language models on complex reasoning tasks through long context scaling and improved policy optimization methods. • Demonstrates the effectiveness of long to short reasoning path conversion, enhancing the performance and efficiency of short reasoning path models by transferring knowledge from long reasoning path models. • Designs a simplistic reinforcement learning framework that achieves efficient reasoning capabilities without relying on complex techniques (such as Monte Carlo tree search and value functions). • Optimizes the infrastructure of reinforcement learning, improving the efficiency and scalability of long context reinforcement learning through partial rollouts and hybrid deployment strategies. • Achieves state-of-the-art (SOTA) performance in multiple benchmarks, validating the effectiveness of the methods and the superiority of the model.
3. Summary of Paper Information:
Abstract
Kimi k1.5 is our latest developed multimodal large language model (LLM), trained through reinforcement learning (RL). Traditional language model pre-training methods rely on next-word prediction, and their performance improvement is limited by the amount of training data available. Reinforcement learning opens new directions for continuous improvement in artificial intelligence, allowing models to expand training data through a reward mechanism. However, previous studies have failed to achieve competitive results. The training practices of Kimi k1.5 include its reinforcement learning techniques, multimodal data recipes, and infrastructure optimization. By expanding context length (long context scaling) and improving policy optimization methods, we established a simple and effective reinforcement learning framework without relying on complex techniques such as Monte Carlo tree search, value functions, and process reward models. Our system achieved state-of-the-art reasoning performance in multiple benchmarks, such as reaching 77.5 on AIME, 96.2 on MATH 500, and 94 percentile on Codeforces, comparable to OpenAI’s o1 model. Additionally, we proposed effective long to short reasoning path (long2short) methods to enhance the performance of short reasoning path models, reaching 60.8 on AIME, 94.6 on MATH 500, and 47.3 on LiveCodeBench, significantly outperforming existing short reasoning path models (such as GPT-4o and Claude Sonnet 3.5) with performance improvements of up to +550%.
1. Introduction 1.1 Research Background and Motivation The pre-training methods of language models, especially those based on next word prediction tasks, have proven to be very effective in scaling computational resources to improve model performance. However, the performance improvement of this method is limited by the availability of high-quality training data. As the model scale increases, the scarcity of high-quality data becomes increasingly apparent, becoming a bottleneck for further performance enhancement (Kaplan et al., 2020; Hoffmann et al., 2022; Villalobos et al., 2024). Furthermore, traditional pre-training methods rely on static datasets, and the model’s exploration ability is limited by the diversity and coverage of the data. Reinforcement Learning (RL) provides new possibilities for the continuous improvement of language models. By introducing a reward mechanism, models can actively explore during training, thereby breaking through the limitations of static datasets (Muennighoff et al., 2023). However, despite the theoretical potential of reinforcement learning, previous studies have failed to achieve competitive results in practical applications. To address this issue, this research proposes Kimi k1.5, a multimodal large language model (LLM) trained through reinforcement learning, aiming to explore a new expansion axis to continuously enhance the performance of artificial intelligence. 1.2 Design and Training of Kimi k1.5 The design and training of Kimi k1.5 include several key elements, which together form the basis of its efficient reasoning and multimodal understanding capabilities. 1.2.1 Long Context Scaling Long context scaling is one of the core designs of Kimi k1.5. By extending the context window of reinforcement learning to 128k, the model can handle longer input and output sequences, significantly enhancing its reasoning capabilities. This extension not only improves the model’s performance but also provides richer contextual information for complex reasoning tasks. Additionally, to improve training efficiency, we introduced the partial rollouts technique, generating new trajectories by reusing large chunks of previous trajectories, avoiding the high computational cost of regenerating trajectories from scratch. This technique significantly improves the efficiency of long context reinforcement learning, allowing the model to utilize computational resources more effectively. 1.2.2 Improved Policy Optimization Method In reinforcement learning, policy optimization is a key step to improve model performance. Kimi k1.5 adopts an improved policy optimization method based on the online mirror descent algorithm. This algorithm ensures the stability and robustness of the model during the optimization process by introducing relative entropy regularization. Moreover, we further enhance the effectiveness of policy optimization through effective sampling strategies, length penalties, and data recipe optimization. These improvements enable the model to perform excellently in complex reasoning tasks, generating more detailed and logically coherent reasoning paths. 1.2.3 Simplistic Framework Design Kimi k1.5’s design emphasizes simplicity and efficiency. By leveraging long context scaling and improved policy optimization methods, the model can achieve efficient reasoning capabilities without relying on complex Monte Carlo tree search (MCTS), value functions, and process reward models. This simplistic framework design not only reduces the complexity of the model but also enhances its scalability and efficiency in practical applications. By increasing the context length, the model can simulate more search steps, thus displaying planning, reflection, and correction capabilities during reasoning. 1.2.4 Multimodal Capability Kimi k1.5 is a multimodal model capable of processing both text and visual data simultaneously. This multimodal capability enables the model to jointly reason about text and image information, resulting in excellent performance in multimodal tasks. For example, in visual question answering (VQA) and mathematical reasoning tasks, the model can generate accurate answers by understanding and analyzing image content. This multimodal design not only expands the model’s application scope but also enhances its performance in complex tasks. 1.3 Main Contributions and Experimental Results Kimi k1.5 achieved significant performance improvements in multiple benchmark tests, validating the effectiveness of its design and training methods. The following is a detailed description of the main contributions and experimental results: 1.3.1 Performance of Long Reasoning Path (Long-CoT) Model Kimi k1.5’s long reasoning path model achieved state-of-the-art performance in multiple complex reasoning tasks, comparable to OpenAI’s o1 model. Specific results are as follows: • In AIME 2024, Kimi k1.5’s long reasoning path model achieved an accuracy of 77.5, surpassing OpenAI’s o1-mini (70.3) and QwQ-32B (50.0). • In MATH 500, Kimi k1.5’s long reasoning path model achieved an accuracy of 96.2, surpassing OpenAI’s o1 (94.8) and QwQ-32B (90.6). • In Codeforces percentile ranking, Kimi k1.5’s long reasoning path model achieved a 94 percentile, comparable to OpenAI’s o1 (94), far exceeding QwQ-32B (62). • In MathVista, Kimi k1.5’s long reasoning path model achieved an accuracy of 74.9, surpassing OpenAI’s o1-mini (71.0) and QwQ-32B (71.4). These results indicate that Kimi k1.5’s long reasoning path model has significant advantages in handling complex reasoning tasks, capable of generating more detailed and logically coherent reasoning paths. 1.3.2 Performance of Short Reasoning Path (Short-CoT) Model Kimi k1.5’s short reasoning path model significantly improved performance through long to short reasoning path conversion (Long2Short) technology, surpassing existing short reasoning path models. Specific results are as follows: • In AIME 2024, Kimi k1.5’s short reasoning path model achieved an accuracy of 60.8, significantly surpassing GPT-4o (16.0) and Claude Sonnet 3.5 (9.3). • In MATH 500, Kimi k1.5’s short reasoning path model achieved an accuracy of 94.6, surpassing GPT-4o (74.6) and Claude Sonnet 3.5 (73.8). • In LiveCodeBench, Kimi k1.5’s short reasoning path model achieved an accuracy of 47.3, surpassing GPT-4o (33.4) and Claude Sonnet 3.5 (36.3). These results indicate that Kimi k1.5’s short reasoning path model, through long to short reasoning path conversion technology, not only retains the reasoning capabilities of the long reasoning path model but also significantly improves reasoning efficiency, making it more advantageous in practical applications. 1.3.3 Long to Short Reasoning Path Conversion (Long2Short) Technology The long to short reasoning path conversion technology proposed by Kimi k1.5, including model merging, shortest rejection sampling, DPO, and long to short RL methods, significantly enhances the performance of short reasoning path models. These methods effectively transfer knowledge from long reasoning path models to short reasoning path models, allowing them to perform excellently under limited testing time token budgets. For example: • In AIME 2024, the short reasoning path model trained with long to short RL achieved an accuracy of 60.8, while other methods (such as DPO and model merging) achieved accuracies of 55.0 and 50.0, respectively. • In MATH 500, the short reasoning path model trained with long to short RL achieved an accuracy of 94.6, while other methods achieved accuracies of 90.0 and 85.0. These results indicate that long to short reasoning path conversion technology not only effectively enhances the performance of short reasoning path models but also provides new ideas for the design and optimization of multimodal language models. 1.3.4 Performance Comparison and Summary Kimi k1.5, through long context scaling and improved policy optimization methods, significantly enhances the reasoning capabilities of multimodal language models. Compared to existing language models, Kimi k1.5 performs excellently in multiple benchmark tests, especially in complex reasoning tasks. For example, in tasks like AIME 2024 and MATH 500, Kimi k1.5’s long reasoning path model is comparable to OpenAI’s o1 model, while the short reasoning path model significantly surpasses existing short reasoning path models. Additionally, Kimi k1.5’s multimodal capability also demonstrates excellent performance in visual question answering and mathematical reasoning tasks, further validating the effectiveness and practicality of its design.
2. Method: Using RL for LLM
2.1 Building RL Prompt Set The quality and diversity of the reinforcement learning prompt set are crucial for the model’s training effectiveness. A high-quality prompt set can not only guide the model to robust reasoning but also reduce the risks of reward hacking and overfitting. The following are three key attributes for constructing the prompt set: 2.1.1 Diverse Coverage The prompt set should cover a wide range of subject areas, including but not limited to STEM, programming, and general reasoning tasks, to enhance the model’s adaptability and generalization capabilities. To achieve this, researchers employ automatic filters to select questions that require rich reasoning processes and are easy to evaluate, combined with text and image-text question-answering data to ensure the diversity and practicality of the prompt set. 2.1.2 Balanced Difficulty The prompt set should include questions of varying difficulty levels to support the model’s progressive learning. Researchers developed a difficulty assessment method based on the model’s own capabilities: by generating multiple answers with high sampling temperature, the pass rate is calculated as a proxy indicator of difficulty. The lower the pass rate, the higher the difficulty of the prompt. This method effectively filters out challenging questions while avoiding overfitting to specific difficulty levels during training. 2.1.3 Accurate Evaluability To ensure that both the model’s reasoning process and final answers can be accurately validated, researchers exclude question types that are easily susceptible to “reward hacking,” such as multiple-choice questions, true/false questions, and proof questions. Additionally, researchers propose a simple yet effective method to identify and remove prompts that can be easily guessed by the model: if the model can guess the correct answer within N attempts, the prompt is flagged as easily hackable and removed. Experiments show that setting N=8 can effectively remove most easily hackable prompts. 2.2 Long Reasoning Path Supervised Fine-Tuning To further enhance the model’s reasoning capabilities, researchers constructed a high-quality long reasoning path (long-CoT) dataset through prompt engineering. This dataset contains accurately validated reasoning paths that cover key cognitive processes of human reasoning, such as planning, evaluation, reflection, and exploration. Through lightweight supervised fine-tuning (SFT), the model can internalize these reasoning strategies, thus performing excellently in diverse reasoning tasks. 2.2.1 Prompt Engineering and Dataset Construction Researchers use prompt engineering methods to generate long reasoning path datasets, similar to rejection sampling, but focusing on generating detailed reasoning paths. These paths contain not only the questions and answers but also intermediate reasoning steps, enabling the model to learn how to systematically plan and evaluate the steps to solve problems. 2.2.2 Fine-Tuning Effects After long reasoning path supervised fine-tuning, the model shows significant improvement in generating detailed and logically coherent responses. This improvement is not limited to reasoning tasks but extends to the model’s overall reasoning capabilities, making it more adaptable and accurate in complex problems. 2.3 Reinforcement Learning Reinforcement learning is a core phase of training the Kimi k1.5 model, aiming to optimize the model’s reasoning capabilities through reward signals. The following are specific implementation methods and key strategies for reinforcement learning: 2.3.1 Problem Setting The goal of reinforcement learning is to train a policy model that can accurately solve test questions. In complex reasoning tasks, the mapping from questions to solutions is non-trivial. To this end, researchers introduce the Chain of Thought (CoT) method, connecting questions and answers through intermediate steps. Specifically, the model samples intermediate reasoning steps autoregressively while generating the final answer, with these steps serving as important intermediates in solving the problem. 2.3.2 Policy Optimization Researchers adopt an improved online mirror descent algorithm for policy optimization. This algorithm optimizes policies through relative entropy regularization, ensuring stability and robustness during training. Specifically, the optimization goal is to maximize the expected reward of the model generating correct answers while limiting the magnitude of policy updates through a relative entropy regularization term. 2.3.2.1 Optimization Algorithm The core of the optimization algorithm is to optimize the model’s policy using sampling and reward signals. Researchers achieve optimization through the following steps: • Use the current policy model as a reference model to sample and generate a series of responses. • Calculate the rewards of the sampled responses and optimize the policy through the relative entropy regularization term. • Iteratively update model parameters to gradually enhance the model’s reasoning capabilities. 2.3.2.2 Length Penalty During training, the length of the model’s responses may significantly increase, which, while helping to enhance performance, can lead to inefficient reasoning. To address this, researchers introduce a length penalty mechanism that restricts response length through reward signals. Specifically, the length penalty mechanism provides different rewards based on the length and correctness of the responses, thus encouraging the model to generate shorter responses. 2.3.3 Sampling Strategies To improve training efficiency, researchers propose two sampling strategies: curriculum sampling and prioritized sampling. 2.3.3.1 Curriculum Sampling The curriculum sampling strategy optimizes the training process by gradually transitioning from simple tasks to complex tasks. This method utilizes the difficulty labels in the dataset, allowing the model to focus on simple tasks in the early training stages, gradually increasing the difficulty. Experiments show that curriculum sampling can significantly improve training efficiency, enabling the model to adapt to complex tasks more quickly. 2.3.3.2 Prioritized Sampling The prioritized sampling strategy optimizes the training process by focusing on tasks where the model performs poorly. Researchers track the success rates of each question and prioritize sampling those with lower success rates. This method allows the model to concentrate on addressing its weak points, achieving faster learning and better overall performance. 2.3.4 Training Details During the reinforcement learning training process, researchers also focused on several key details: 2.3.4.1 Test Case Generation for Coding Due to the lack of test cases for many online coding problems, researchers designed an automatic test case generation method. By leveraging the CYaRon test case generation library and the model’s own generation capabilities, researchers generated high-quality test cases for coding problems. These test cases serve as reward signals for training the model to solve coding issues. 2.3.4.2 Reward Modeling for Math Assessing mathematical problems poses a challenge: different expressions can represent the same answer. To address this, researchers adopted two reward modeling methods: • Classic Reward Model (Classic RM): A reward model based on a value head that outputs a scalar value to judge whether the response is correct based on the input question, reference answer, and response. • Chain-of-Thought RM: Enhances the accuracy of the reward model by introducing reasoning paths (CoT). This model explicitly generates the reasoning process before making the final judgment, thereby providing more accurate reward signals. Experiments show that the accuracy of the reasoning path reward model reached 98.5%, significantly higher than the classic reward model’s 84.4%. 2.3.4.3 Vision Data To enhance the model’s performance in visual tasks, researchers obtained visual reinforcement learning data from three categories: • Real-world data: Covers scientific questions, location guessing tasks, and data analysis, enhancing the model’s visual reasoning capabilities in real-world scenarios. • Synthetic visual reasoning data: Programmatically generated images and scenes to enhance the model’s understanding of spatial relationships, geometric patterns, and object interactions. • Text rendering data: Converts textual content into visual formats, ensuring consistency when processing text and image inputs. 2.4 Long to Short Reasoning Path Conversion (Long2Short: Context Compression for Short-CoT Models) Although long reasoning path models perform excellently, short reasoning path models are more advantageous in practical applications due to limited testing time token budgets. To address this, researchers proposed a series of long to short reasoning path conversion methods to transfer knowledge from long reasoning path models to short reasoning path models, significantly improving the performance of short reasoning path models. 2.4.1 Model Merging Model merging is a simple yet effective method that generates a new model by averaging the weights of the long reasoning path model and the short reasoning path model. This method not only retains the reasoning capabilities of the long reasoning path model but also enhances the efficiency of the short reasoning path model. 2.4.2 Shortest Rejection Sampling
Researchers observed that there is significant variation in the response lengths generated by the model for the same question. Based on this phenomenon, the shortest rejection sampling method samples multiple times and selects the shortest correct response for supervised fine-tuning. This method can significantly improve the efficiency of short reasoning path models.
2.4.3 DPO Training
DPO (Direct Preference Optimization) method generates multiple response samples, selecting the shortest correct response as the positive sample, while longer responses (including incorrect long responses and correct but overly long responses) are treated as negative samples. These positive and negative sample pairs are used to train the model, enabling it to maintain reasoning accuracy while significantly reducing response length. Experiments show that the DPO method can effectively enhance the performance and efficiency of short reasoning path models.
2.4.4 Long to Short Reinforcement Learning (Long2Short RL)
After completing standard reinforcement learning training, researchers select a model that balances performance and token efficiency as the base model and conduct specialized long to short reinforcement learning training. At this stage, researchers introduce the length penalty mechanism and significantly reduce the maximum unfolding length to further penalize responses that exceed the expected length, even if these responses are correct. This method not only enhances the performance of short reasoning path models but also significantly improves their efficiency under limited token budgets.
2.5 Other Training Details
In addition to the aforementioned reinforcement learning and long to short reasoning path conversion methods, Kimi k1.5’s training also includes the following key components:
2.5.1 Pretraining
Kimi k1.5’s base model is pretrained on various high-quality multimodal corpora covering English, Chinese, code, mathematical reasoning, and knowledge domains. Pretraining is divided into three stages:
• Visual-Language Pretraining Stage: The model first establishes a strong language foundation on pure language data, then gradually introduces visual-language data to gain multimodal capabilities.
• Cooldown Stage: Further consolidates the model’s capabilities through high-quality language and visual-language data, particularly in reasoning and knowledge tasks.
• Long Context Activation Stage: Extends sequence processing capabilities to 131,072 tokens to support long text tasks.
2.5.2 Supervised Fine-Tuning
After pretraining, the model further enhances performance through supervised fine-tuning. Researchers constructed a fine-tuning dataset covering multiple domains, including:
• Non-reasoning tasks: Such as question answering, writing, and text processing, generating high-quality data through human labeling and rejection sampling.
• Reasoning tasks: Such as mathematical and programming problems, verifying answers through rules and reward modeling to ensure data accuracy and efficiency.
The fine-tuning dataset contains approximately 1 million text examples and 1 million text-visual examples, covering various tasks and domains. The model is trained for one epoch at 32k and 128k token lengths, with learning rates decreasing from 2×10⁻⁵ to 2×10⁻⁶ and from 1×10⁻⁵ to 1×10⁻⁶ in the two stages, respectively. Additionally, by packing multiple training samples into a single training sequence, training efficiency is further improved.
2.6 Reinforcement Learning Infrastructure
To support large-scale reinforcement learning training, Kimi k1.5 adopts an efficient training infrastructure, including the following key components:
2.6.1 Large Scale RL Training System
Kimi k1.5’s reinforcement learning training system employs an iterative synchronous framework, optimizing the training efficiency of long reasoning paths through partial rollouts technology. The system includes the following components:
• Rollout Workers: Responsible for generating response trajectories of the model and storing these trajectories in the replay buffer.
• Trainer Workers: Retrieve data from the replay buffer to update model weights.
• Master: Coordinates the work of Rollout Workers and Trainer Workers, managing data flow and communication.
• Reward Models: Evaluate the quality of model outputs, providing feedback for the training process.
2.6.2 Partial Rollouts
The partial rollouts technique avoids excessive computational resource consumption by limiting the length of responses generated at each iteration. When a trajectory exceeds the length limit, the unfinished part is saved to the replay buffer and processed in subsequent iterations. This method not only improves training efficiency but also ensures all Rollout Workers remain efficient through asynchronous operations.
2.6.3 Hybrid Deployment Strategy
To achieve efficient sharing of training and inference resources, Kimi k1.5 employs a hybrid deployment strategy. By sharing GPU resources through Kubernetes Sidecar containers, training and inference tasks are deployed on the same node. This method not only avoids idle time for training nodes while waiting for inference nodes but also supports dynamic expansion of the number of inference nodes to meet different task requirements.
2.6.4 Code Sandbox
To support reinforcement learning training for coding tasks, Kimi k1.5 developed a secure code execution environment—the code sandbox. This environment supports multiple programming languages and tools through dynamic switching of container images, ensuring the reliability and consistency of training data through a multi-stage evaluation mechanism. The code sandbox also significantly improves execution efficiency and resource utilization through optimization techniques (such as using Crun as the container runtime, pre-creating cgroups, and optimizing disk usage).
3. Experiments 3.1 Evaluation
To comprehensively evaluate the performance of the Kimi k1.5 model, researchers conducted experiments across multiple benchmark tests covering text, reasoning, and visual tasks. These benchmark tests include not only unimodal tasks but also multimodal tasks to validate the model’s performance in different scenarios. The detailed evaluation setup is as follows: 3.1.1 Text Benchmark Tests The text benchmark tests primarily evaluate the model’s performance in natural language understanding, commonsense reasoning, and multilingual tasks. Specific benchmark tests include: • MMLU (Massive Multitask Language Understanding): Covers 57 subject areas, testing the model’s knowledge and reasoning abilities at different difficulty levels. • IF-Eval (Instruction Following Evaluation): Evaluates the model’s ability to follow complex instructions, such as generating lengthy articles. • CLUEWSC (Chinese Language Understanding Evaluation): Chinese coreference resolution task, testing the model’s understanding of referential relationships in Chinese texts. • C-Eval (Chinese Evaluation Suite): A comprehensive Chinese evaluation suite containing 13,948 multiple-choice questions across 52 subjects, testing the model’s advanced knowledge and reasoning abilities. 3.1.2 Reasoning Benchmark Tests The reasoning benchmark tests focus on evaluating the model’s performance in mathematical, programming, and logical reasoning tasks. Specific benchmark tests include: • HumanEval-Mul: Multilingual programming tasks testing the model’s code generation capabilities across various programming languages. • LiveCodeBench: A contamination-free programming task benchmark assessing the model’s performance in different programming scenarios. • AIME 2024: A set of problems from the American Mathematics Invitation Exam (AIME) testing the model’s reasoning capabilities in advanced mathematics. • MATH-500: A comprehensive benchmark test containing 500 math problems covering algebra, calculus, probability, and more. • Codeforces: An online programming competition platform testing the model’s performance in programming competitions. 3.1.3 Visual Benchmark Tests The visual benchmark tests evaluate the model’s performance in visual understanding and multimodal tasks. Specific benchmark tests include: • MMMU (Massive Multimodal Understanding): Contains 11.5K multimodal questions covering multiple disciplines such as art design, business, science, and medicine. • MATH-Vision: A visual benchmark test containing 3,040 math problems, testing the model’s mathematical reasoning capabilities in visual contexts. • MathVista: A benchmark test combining mathematical and visual tasks, assessing the model’s performance in visual understanding and reasoning tasks. 3.2 Main Results The Kimi k1.5 model achieved significant performance improvements across multiple benchmark tests, validating the effectiveness of its design and training methods. 3.2.1 Performance of Long Reasoning Path Model (Long-CoT) Kimi k1.5’s long reasoning path model achieved state-of-the-art performance in multiple complex reasoning tasks, comparable to OpenAI’s o1 model. Specific results are as follows: • AIME 2024: Kimi k1.5’s long reasoning path model achieved an accuracy of 77.5, surpassing OpenAI’s o1-mini (70.3) and QwQ-32B (50.0). • MATH-500: Kimi k1.5’s long reasoning path model achieved an accuracy of 96.2, surpassing OpenAI’s o1 (94.8) and QwQ-32B (90.6). • Codeforces: Kimi k1.5’s long reasoning path model achieved 94 percentile ranking, comparable to OpenAI’s o1 (94), far exceeding QwQ-32B (62). • MathVista: Kimi k1.5’s long reasoning path model achieved an accuracy of 74.9, surpassing OpenAI’s o1-mini (71.0) and QwQ-32B (71.4). These results indicate that Kimi k1.5’s long reasoning path model has significant advantages in handling complex reasoning tasks, capable of generating more detailed and logically coherent reasoning paths. 3.2.2 Performance of Short Reasoning Path Model (Short-CoT) Kimi k1.5’s short reasoning path model significantly improved performance through long to short reasoning path conversion technology, surpassing existing short reasoning path models. Specific results are as follows: • AIME 2024: Kimi k1.5’s short reasoning path model achieved an accuracy of 60.8, significantly surpassing GPT-4o (16.0) and Claude Sonnet 3.5 (9.3). • MATH-500: Kimi k1.5’s short reasoning path model achieved an accuracy of 94.6, surpassing GPT-4o (74.6) and Claude Sonnet 3.5 (73.8). • LiveCodeBench: Kimi k1.5’s short reasoning path model achieved an accuracy of 47.3, surpassing GPT-4o (33.4) and Claude Sonnet 3.5 (36.3). These results indicate that Kimi k1.5’s short reasoning path model, through long to short reasoning path conversion technology, not only retains the reasoning capabilities of the long reasoning path model but also significantly improves reasoning efficiency, making it more advantageous in practical applications. 3.3 Long Context Scaling Researchers validated the impact of long context scaling on model performance through experiments. The experiments indicated that as context length increases, the model’s performance in complex reasoning tasks significantly improves. Specific results are as follows: • Relationship between context length and performance: In multiple benchmark tests, the model’s performance improves with increasing context length. For instance, in tasks like MATH-500 and AIME 2024, as the context length increases from 32k to 128k, the model’s accuracy significantly improves. • Efficiency of long context scaling: Through partial rollouts technology, the model’s efficiency in long context training significantly improved. Experiments show that partial rollouts technology can effectively reduce waste of computational resources while maintaining performance improvements. These results indicate that long context scaling is one of the key factors in enhancing the model’s reasoning capabilities, while partial rollouts technology provides an efficient solution for long context training. 3.4 Long to Short Reasoning Path Conversion (Long2Short) The long to short reasoning path conversion technology proposed by Kimi k1.5 significantly enhances the performance of short reasoning path models. Researchers compared various methods, including model merging, shortest rejection sampling, DPO, and long to short RL. Specific results are as follows: • Performance of long to short RL: In tasks like AIME 2024 and MATH-500, the short reasoning path model trained with long to short RL performed best. For example, in AIME 2024, the long to short RL method achieved an accuracy of 60.8, while other methods (such as DPO and model merging) achieved accuracies of 55.0 and 50.0, respectively. • Efficiency comparison: The long to short RL method not only enhances the performance of short reasoning path models but also significantly improves their efficiency under limited token budgets. Experiments indicate that short reasoning path models generated by the long to short RL method maintain high performance while significantly reducing the number of tokens used. These results indicate that long to short reasoning path conversion technology effectively enhances the performance of short reasoning path models and provides new ideas for the design and optimization of multimodal language models. 3.5 Ablation Studies To further validate the effectiveness of Kimi k1.5’s design and training methods, researchers conducted ablation studies comparing the performance of different model sizes, context length expansions, and policy optimization algorithms.
3.5.1 Model Size and Context Length Researchers compared the performance of different-sized models on fixed datasets. The experimental results indicate: • Small Models with Long Context: Small models can achieve performance comparable to large models by extending context length. For instance, in the MATH-500 task, the small model achieved an accuracy of 95.0% after long context expansion, close to the large model’s 96.2%. • Efficiency Advantage of Large Models: Although small models can enhance performance through context length expansion, large models perform better in terms of token efficiency. For example, in the AIME 2024 task, the large model achieved an accuracy of 77.5% after long context expansion, while the small model required more context length to achieve similar performance. This suggests that if the goal is to achieve optimal performance within a limited testing time token budget, extending the context length of large models may be a more efficient choice.
3.5.2 Use of Negative Rewards Researchers compared the reinforcement learning methods using negative rewards with methods that do not use negative rewards (such as ReST, Reinforced Self-Training). The experimental results indicate: • Effectiveness of Negative Rewards: In Kimi k1.5’s training, reinforcement learning methods using negative rewards significantly outperform the ReST method. For example, in the MATH-500 task, the method using negative rewards achieved an accuracy of 96.2% within 50 training steps, while the ReST method only reached 90.6%. This indicates that negative rewards can more effectively guide the model to learn complex reasoning paths. • Comparison of Sample Complexity: The method using negative rewards also shows advantages in sample complexity. For instance, in the AIME 2024 task, the method using negative rewards required only 30 training steps to achieve an accuracy of 77.5%, while the ReST method needed 50 steps to reach similar performance. This suggests that negative rewards can accelerate the model’s learning process and reduce the number of training samples required.
3.5.3 Comparison of Sampling Strategies Researchers compared the impact of different sampling strategies on model performance, including curriculum sampling and prioritized sampling.
3.5.3.1 Curriculum Sampling The curriculum sampling strategy optimizes the training process by gradually transitioning from simple tasks to complex tasks. Experimental results indicate: • Performance Improvement: The curriculum sampling strategy significantly enhances the model’s performance on complex tasks. For instance, in the MATH-500 task, the model using curriculum sampling achieved an accuracy of 96.2% within 30 training steps, while the model not using curriculum sampling only reached 90.6%. • Training Efficiency: The curriculum sampling strategy also improves training efficiency, allowing the model to adapt to complex tasks more quickly. For example, in the AIME 2024 task, the model using curriculum sampling achieved an accuracy of 77.5% within 20 training steps, while the model not using curriculum sampling required 30 steps to reach similar performance.
3.5.3.2 Prioritized Sampling The prioritized sampling strategy optimizes the training process by focusing on tasks where the model performs poorly. Experimental results indicate: • Performance Improvement: The prioritized sampling strategy significantly enhances the model’s performance on weak points. For instance, in the LiveCodeBench task, the model using prioritized sampling achieved an accuracy of 47.3% within 40 training steps, while the model not using prioritized sampling only reached 33.4%. • Training Efficiency: The prioritized sampling strategy also improves training efficiency, allowing the model to resolve its weak points more quickly. For example, in the HumanEval-Mul task, the model using prioritized sampling achieved an accuracy of 81.5% within 30 training steps, while the model not using prioritized sampling needed 40 steps to reach similar performance.
3.5.4 Summary Through ablation studies, the design and training methods of Kimi k1.5 have been validated in multiple aspects: • Long context scaling: Significantly improves the model’s performance in complex reasoning tasks, especially in long reasoning path tasks. • Use of negative rewards: By introducing negative rewards, the model can learn complex reasoning paths more efficiently, reducing the number of training samples required. • Sampling strategies: Curriculum sampling and prioritized sampling strategies significantly enhance the model’s training efficiency and final performance, especially in handling complex tasks. These experimental results indicate that Kimi k1.5’s design and training methods have significant advantages in enhancing model performance and efficiency, providing important references for the future development of multimodal language models.
4. Conclusion 4.1 Research Summary This research proposes Kimi k1.5, a multimodal large language model (LLM), trained through reinforcement learning (RL), aiming to explore a new expansion axis to continuously enhance the performance of artificial intelligence. The design and training methods of Kimi k1.5 have achieved significant performance improvements in multiple benchmark tests, validating its effectiveness and superiority. 4.1.1 Importance of Long Context Scaling One of the core contributions of the research is to enhance the model’s reasoning capabilities by extending context length. Experimental results indicate that long context scaling is a key factor in improving model performance. For example, in the MATH-500 task, Kimi k1.5’s long reasoning path model achieved an accuracy of 96.2%, significantly higher than other models (e.g., OpenAI’s o1 at 94.8%). In the AIME 2024 task, the long reasoning path model achieved an accuracy of 77.5%, surpassing OpenAI’s o1-mini (70.3%) and QwQ-32B (50.0%). These results indicate that long context scaling not only enhances the model’s reasoning capabilities but also enables it to perform excellently in complex tasks. 4.1.2 Improved Policy Optimization Method Kimi k1.5 adopts an improved policy optimization method based on the online mirror descent algorithm and incorporates a length penalty mechanism. This method optimizes policies through relative entropy regularization, ensuring stability and robustness during training. Experimental results indicate that the improved policy optimization method significantly enhances the model’s performance. For example, in the LiveCodeBench task, Kimi k1.5’s short reasoning path model achieved an accuracy of 47.3%, far exceeding GPT-4o (33.4%) and Claude Sonnet 3.5 (36.3%). These results indicate that the improved policy optimization method not only enhances the model’s reasoning capabilities but also significantly improves its efficiency under limited token budgets. 4.1.3 Effectiveness of Long to Short Reasoning Path Conversion Kimi k1.5’s proposed long to short reasoning path conversion technology (Long2Short) significantly enhances the performance of short reasoning path models. By employing model merging, shortest rejection sampling, DPO, and long to short RL methods, Kimi k1.5 transfers knowledge from long reasoning path models to short reasoning path models, making them more advantageous in practical applications. For instance, in the AIME 2024 task, the short reasoning path model trained with long to short RL achieved an accuracy of 60.8%, significantly exceeding other methods (such as DPO’s 55.0% and model merging’s 50.0%). These results indicate that long to short reasoning path conversion technology not only effectively enhances the performance of short reasoning path models but also provides new ideas for the design and optimization of multimodal language models. 4.2 Comparison of Experimental Results Through comparative experiments, Kimi k1.5 performs excellently in multiple benchmark tests, significantly outperforming existing language models. The following are the main comparative results: 4.2.1 Comparison of Long Reasoning Path Model with Existing Models • MATH-500: Kimi k1.5’s long reasoning path model achieved an accuracy of 96.2%, significantly higher than OpenAI’s o1 (94.8%) and QwQ-32B (90.6%). • AIME 2024: Kimi k1.5’s long reasoning path model achieved an accuracy of 77.5%, significantly higher than OpenAI’s o1-mini (70.3%) and QwQ-32B (50.0%). • Codeforces: Kimi k1.5’s long reasoning path model achieved a 94 percentile ranking, comparable to OpenAI’s o1 (94), far exceeding QwQ-32B (62). • MathVista: Kimi k1.5’s long reasoning path model achieved an accuracy of 74.9%, significantly higher than OpenAI’s o1-mini (71.0%) and QwQ-32B (71.4%). 4.2.2 Comparison of Short Reasoning Path Model with Existing Models • AIME 2024: Kimi k1.5’s short reasoning path model achieved an accuracy of 60.8%, significantly higher than GPT-4o (16.0%) and Claude Sonnet 3.5 (9.3%). • MATH-500: Kimi k1.5’s short reasoning path model achieved an accuracy of 94.6%, significantly higher than GPT-4o (74.6%) and Claude Sonnet 3.5 (73.8%). • LiveCodeBench: Kimi k1.5’s short reasoning path model achieved an accuracy of 47.3%, significantly higher than GPT-4o (33.4%) and Claude Sonnet 3.5 (36.3%). 4.2.3 Comparison of Long to Short Reasoning Path Conversion Technology • AIME 2024: The short reasoning path model trained with long to short RL achieved an accuracy of 60.8%, significantly higher than DPO method (55.0%) and model merging method (50.0%). • MATH-500: The short reasoning path model trained with long to short RL achieved an accuracy of 94.6%, significantly higher than DPO method (90.0%) and model merging method (85.0%). 4.3 Future Work Directions Although Kimi k1.5 has achieved significant performance improvements in multiple benchmark tests, researchers point out that further optimizing the efficiency and scalability of long context reinforcement learning remains an important future research direction. Specifically, future work will focus on the following aspects: 4.3.1 Improving Efficiency of Long Context Training Currently, the computational cost of long context training remains high, especially when dealing with complex reasoning tasks. Researchers plan to explore more efficient training strategies, such as further optimizing partial rollouts technology to reduce waste of computational resources while maintaining performance improvements. 4.3.2 Improving Reward Distribution Mechanisms In reinforcement learning, the reward distribution mechanism is crucial for the training effectiveness of the model. Researchers plan to explore more advanced reward distribution methods to reduce the model’s “overthinking” phenomenon while not compromising its exploration capabilities. For example, by introducing more complex reward models, the model can more accurately assess the quality of its reasoning paths during training. 4.3.3 Iteratively Applying Long to Short Reasoning Path Conversion Technology The long to short reasoning path conversion technology has proven effective in enhancing the performance of short reasoning path models. In the future, researchers plan to combine this technology with long context reinforcement learning to iteratively further enhance the model’s performance and efficiency. For example, by applying long to short conversion technology multiple times, the model can extract the best reasoning paths within a limited context length budget. 4.3.4 Exploring New Application Scenarios in Multimodal Tasks Kimi k1.5’s multimodal capabilities allow it to perform excellently in tasks like visual question answering and mathematical reasoning. In the future, researchers plan to explore more application scenarios in multimodal tasks, such as validating the model’s capabilities in more complex visual-language reasoning tasks. Additionally, researchers will study how to combine multimodal capabilities with long context reasoning to further enhance the model’s performance in multimodal tasks. 4.4 Summary Kimi k1.5 significantly enhances the reasoning capabilities of multimodal language models through long context scaling and improved policy optimization methods. Experimental results indicate that Kimi k1.5 achieves state-of-the-art performance in multiple benchmark tests, especially in complex reasoning tasks. Furthermore, the long to short reasoning path conversion technology not only effectively enhances the performance of short reasoning path models but also provides new ideas for the design and optimization of multimodal language models. Future work will focus on further optimizing the efficiency and scalability of long context reinforcement learning, exploring more advanced reward distribution mechanisms, and iteratively applying long to short reasoning path conversion technology to further enhance the model’s performance and efficiency.
## Figures and Tables
Figure 1: Kimi k1.5 long-CoT results
Source Section: 1 Introduction
Content Description: Shows the performance results of Kimi k1.5 long reasoning path (long-CoT) model in multiple benchmark tests. The chart lists the performance of Kimi k1.5 compared to other models (such as OpenAI o1, QwQ-32B, QVQ-72B, etc.) in different tasks, including AIME, MATH 500, Codeforces, and MathVista.
Key Findings: Kimi k1.5 achieved performance comparable to OpenAI o1 in multiple tasks, such as 77.5% on AIME, 96.2% on MATH 500, 94 percentile on Codeforces, and 74.9% on MathVista. These results demonstrate Kimi k1.5’s excellent performance in complex reasoning tasks.
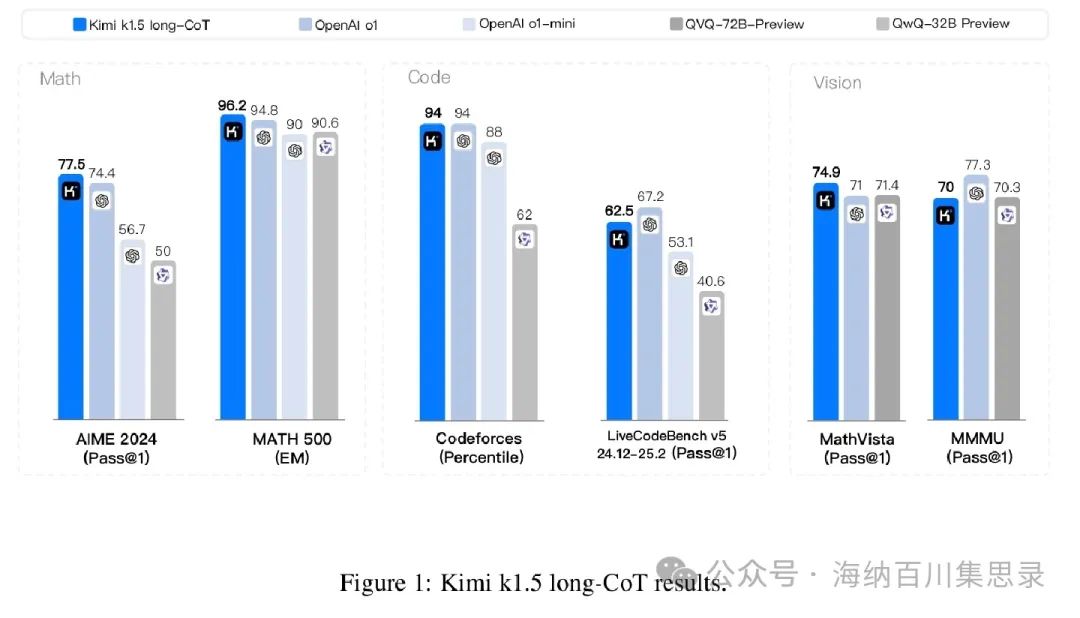
Figure 2: Kimi k1.5 short-CoT results
Source Section: 1 Introduction
Content Description: Shows the performance results of Kimi k1.5 short reasoning path (short-CoT) model in multiple benchmark tests. The chart lists the performance of Kimi k1.5 compared to other models (such as GPT-4o, Claude Sonnet 3.5, etc.) in different tasks, including AIME, MATH 500, LiveCodeBench, etc.
Key Findings: Kimi k1.5’s short reasoning path model significantly outperformed existing models in multiple tasks, such as achieving 60.8% on AIME, 94.6% on MATH 500, and 47.3% on LiveCodeBench. These results demonstrate that Kimi k1.5’s short reasoning path model significantly enhances performance through long to short reasoning path conversion technology.
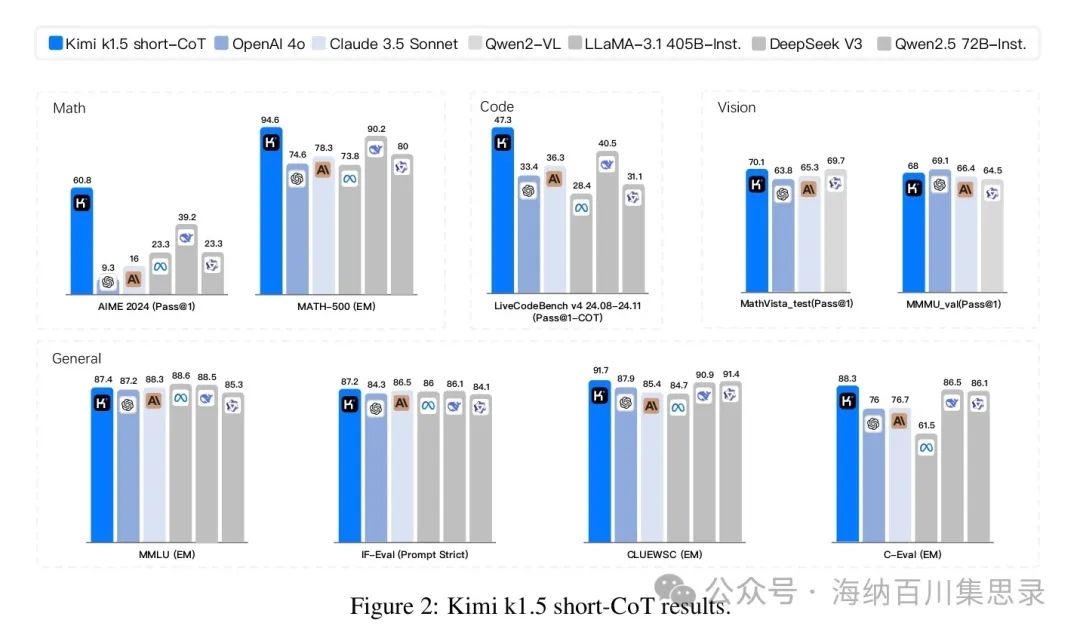
Figure 3: Large Scale Reinforcement Learning Training System for LLM
Source Section: 2.6.1 Large Scale RL Training System
Content Description: Shows the architecture diagram of Kimi k1.5’s large-scale reinforcement learning training system. The diagram includes components such as Rollout Workers, Master, Reward Models, Replay Buffer, and Trainer Workers, detailing the data flow and workflow of the training system.
Key Findings: Through the partial rollouts (Partial Rollouts) technology, the system can efficiently handle long reasoning paths, avoiding excessive computational resource consumption by individual long trajectories. The system supports asynchronous operations, ensuring all Rollout Workers remain efficiently operational.
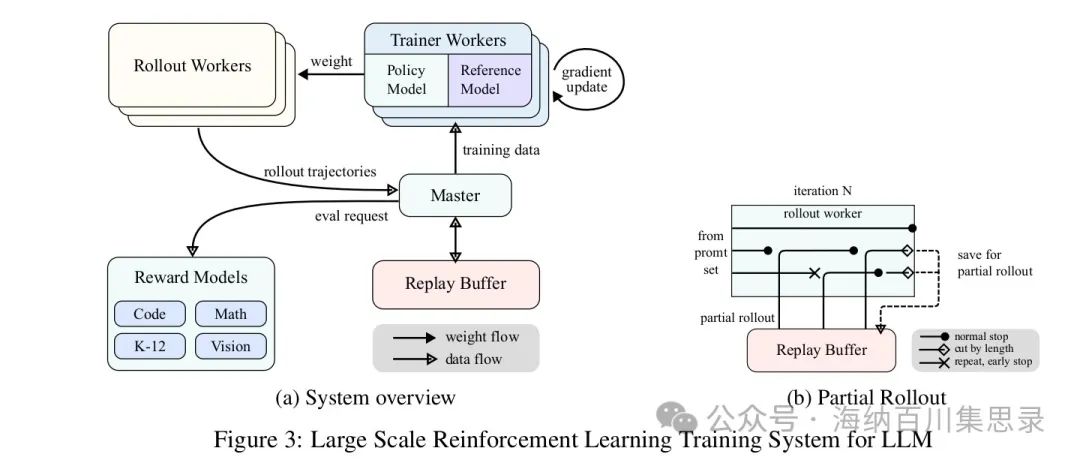
Figure 4: Hybrid Deployment Framework
Source Section: 2.6.3 Hybrid Deployment Strategy
Content Description: Shows the hybrid deployment framework diagram of Kimi k1.5. The diagram describes how to share GPU resources through Kubernetes Sidecar containers, deploying training and inference tasks on the same node to achieve efficient resource sharing and dynamic scaling.
Key Findings: The hybrid deployment strategy avoids idle time for training nodes while waiting for inference nodes and supports dynamic scaling of the number of inference nodes, significantly improving resource utilization.
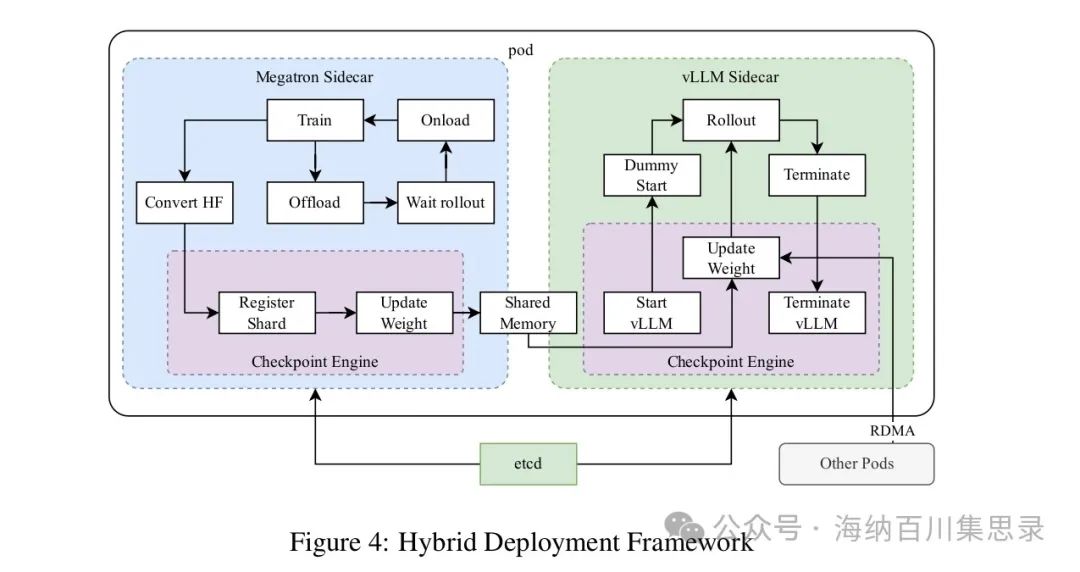
Figure 5: The changes on the training accuracy and length as train iterations grow
Source Section: 3.3 Long Context Scaling
Content Description: Shows the trend of Kimi k1.5’s training accuracy and response length as training iterations increase. The chart lists the accuracy and response length changes for multiple tasks (such as MATH-500, AIME 2024, etc.) as a function of iteration count.
Key Findings: As training iterations progress, both the model’s response length and accuracy significantly increase, especially in complex tasks. For instance, in the MATH-500 task, the response length increased from 5000 to 15000, and accuracy improved from 90.6% to 96.2%. This indicates that long context scaling significantly enhances the model’s reasoning capabilities.
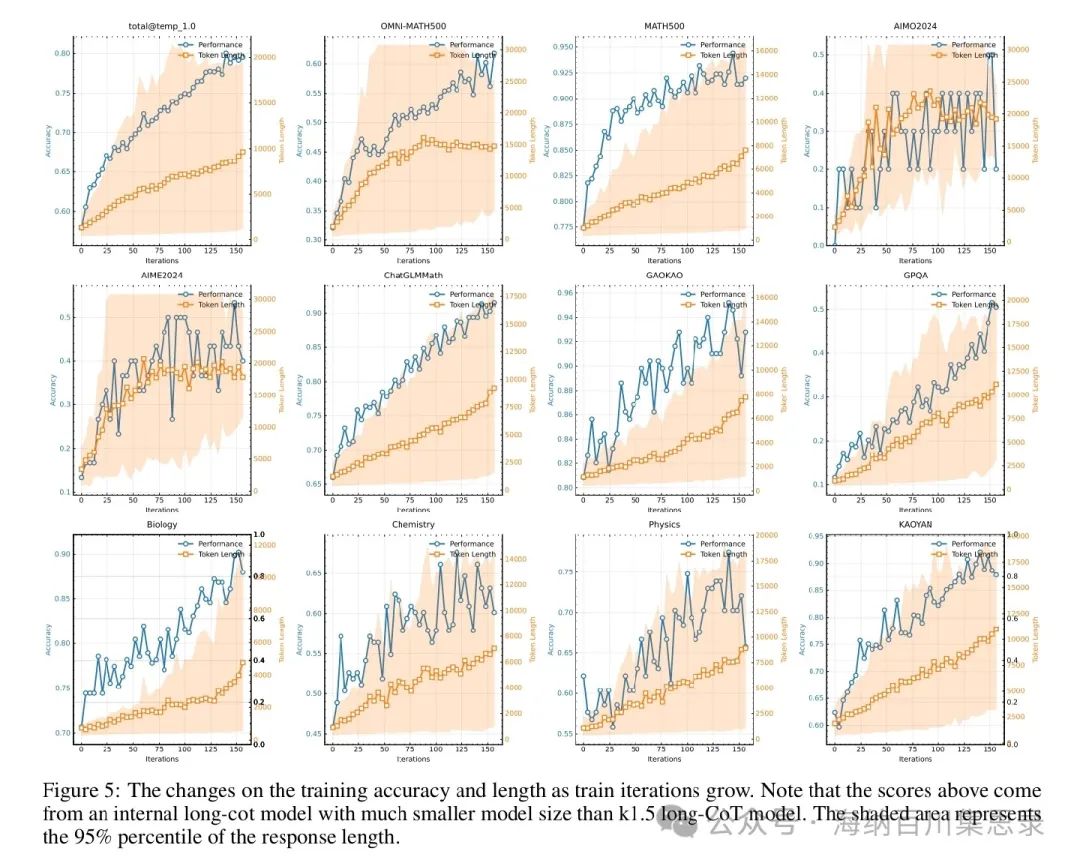
Figure 6: Model Performance Increases with Response Length
Source Section: 3.3 Long Context Scaling
Content Description: Shows the trend of model performance as response length increases. The chart lists the accuracy and response length relationships for multiple tasks (such as MATH-500, AIME 2024, etc.).
Key Findings: Model performance is positively correlated with response length, especially in complex tasks. For instance, in the MATH-500 task, as response length increased from 5000 to 15000, accuracy improved from 90.6% to 96.2%. This indicates that long context scaling is a key factor in enhancing the model’s reasoning capabilities.
Figure 7: Long2Short Performance
Source Section: 3.4 Long to Short Reasoning Path Conversion
Content Description: Shows the performance comparison of Kimi k1.5’s long to short reasoning path conversion technology. The chart lists the performance of different methods (such as DPO, model merging, long to short RL, etc.) in the AIME 2024 and MATH-500 tasks.
Key Findings: The long to short RL method performs best in terms of performance and efficiency. For example, in the AIME 2024 task, the long to short RL method achieved an accuracy of 60.8%, significantly exceeding the DPO method (55.0%) and model merging method (50.0%). This indicates that long to short reasoning path conversion technology significantly enhances the performance of short reasoning path models.
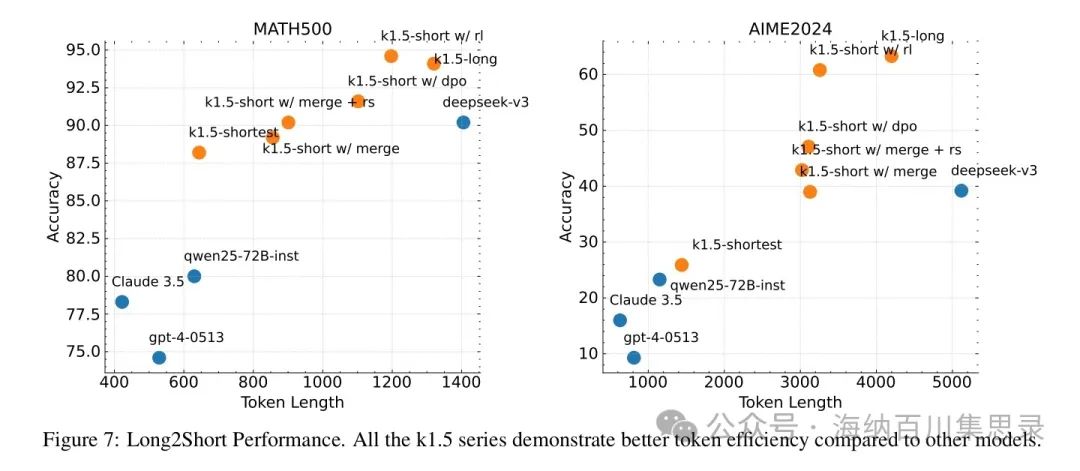
Figure 8: Model Performance vs Response Length of Different Model Sizes
Source Section: 3.5 Ablation Studies
Content Description: Shows the performance comparison of different model sizes in long context scaling training. The chart lists the accuracy and response length relationships for small and large models across different tasks (such as MATH-500, AIME 2024, etc.).
Key Findings: Small models can achieve performance comparable to large models by extending context length, but large models perform better in terms of token efficiency. For instance, in the MATH-500 task, the small model achieved an accuracy of 95.0% after long context expansion, close to the large model’s 96.2%. This indicates that long context scaling is a key factor in enhancing model performance, while large models have advantages under limited token budgets.
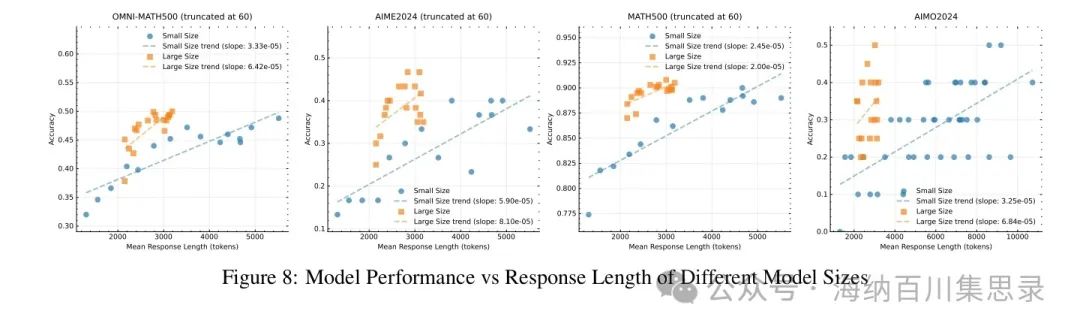
Figure 9: Analysis of curriculum learning approaches on model performance
Source Section: 3.5 Ablation Studies
Content Description: Shows the impact of the curriculum sampling strategy on model performance. The chart lists the performance comparison of models using curriculum sampling and uniform sampling strategies across different tasks (such as MATH-500, AIME 2024, etc.).
Key Findings: The curriculum sampling strategy significantly enhances the model’s performance on complex tasks. For instance, in the MATH-500 task, the model using curriculum sampling achieved an accuracy of 96.2% within 30 training steps, while the model not using curriculum sampling only reached 90.6%. This indicates that the curriculum sampling strategy can effectively improve the model’s training efficiency and final performance.
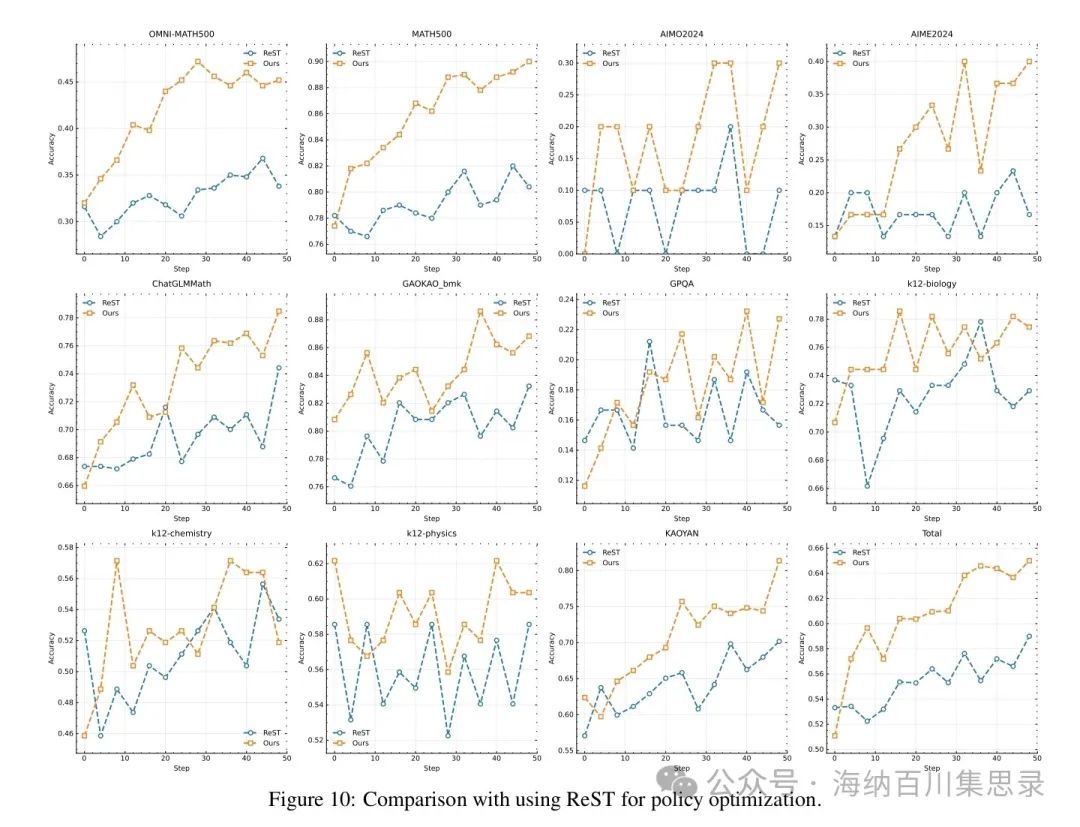
Figure 10: Comparison with using ReST for policy optimization
Source Section: 3.5 Ablation Studies
Content Description: Shows the performance comparison of reinforcement learning methods using negative rewards with the ReST method. The chart lists the model performance on different tasks (such as MATH-500, AIME 2024, etc.) for models using negative rewards and those using the ReST method.
Key Findings: The reinforcement learning method using negative rewards significantly outperforms the ReST method in terms of sample complexity and final performance. For instance, in the MATH-500 task, the method using negative rewards achieved an accuracy of 96.2% within 50 training steps, while the ReST method only reached 90.6%. This indicates that negative rewards can more effectively guide the model to learn complex reasoning paths.
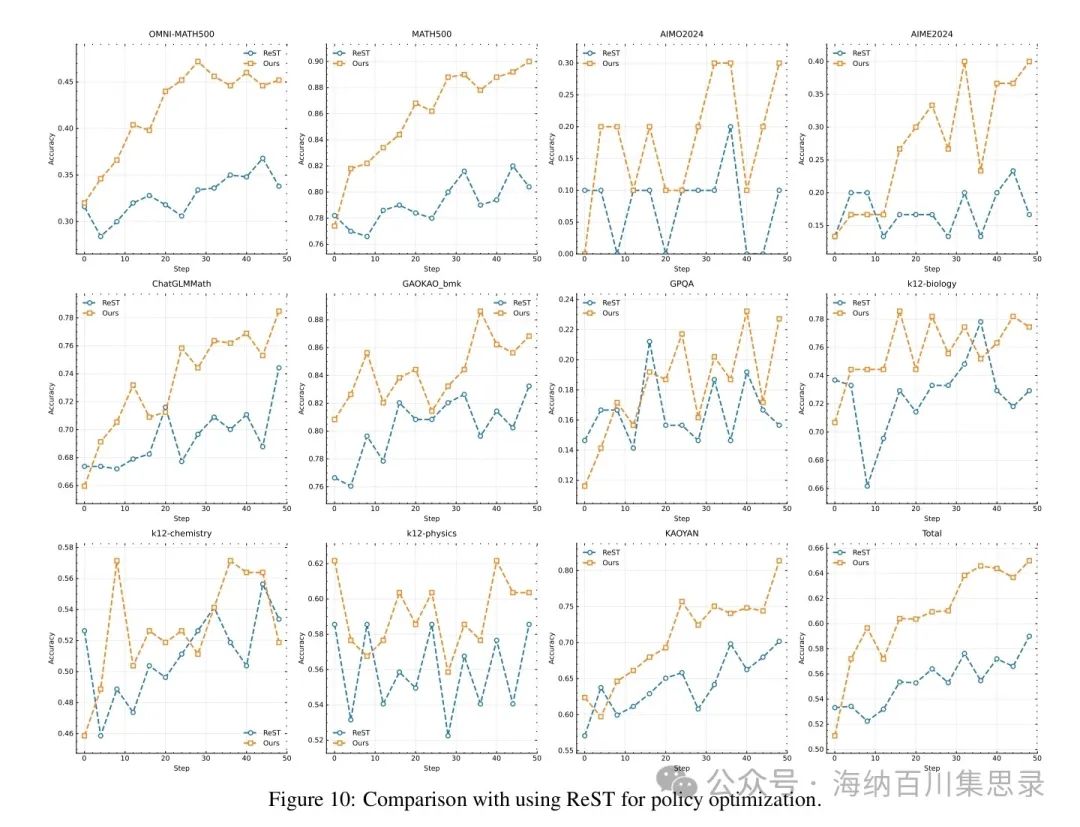
Table 2: Performance of Kimi k1.5 long-CoT and flagship open-source and proprietary models.
Source Section: 3.2 Main Results
Content Description: The table lists the performance comparison of Kimi k1.5 long reasoning path model with other flagship models (such as OpenAI o1, QwQ-32B, QVQ-72B, etc.) in multiple benchmark tests. The table includes accuracies for tasks such as AIME 2024, MATH 500, Codeforces, and MathVista.
Key Findings: Kimi k1.5 achieved performance comparable to OpenAI o1 in multiple tasks, such as 77.5% on AIME 2024, 96.2% on MATH 500, 94 percentile on Codeforces, and 74.9% on MathVista. These results indicate that Kimi k1.5’s long reasoning path model performs excellently in complex reasoning tasks, competing with state-of-the-art models.
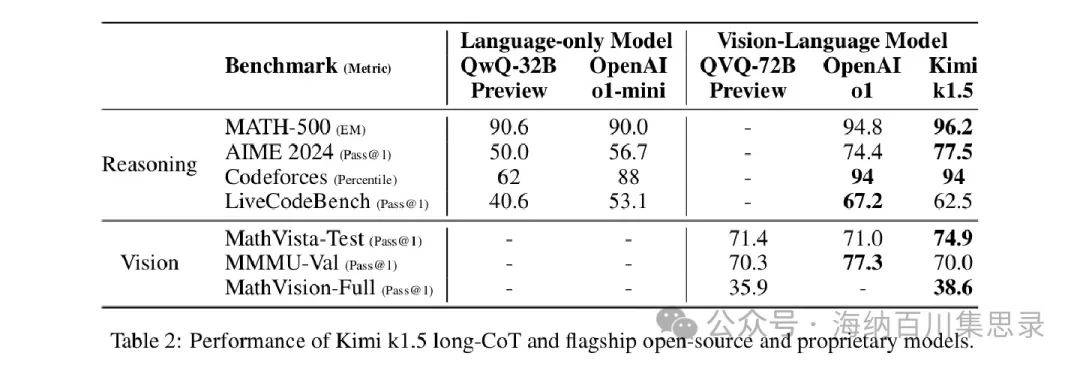
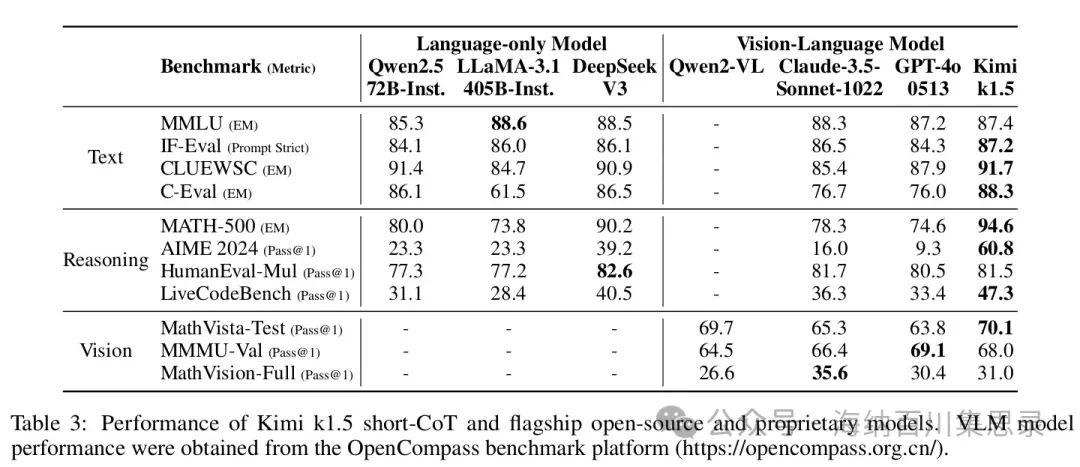
Table 3: Performance of Kimi k1.5 short-CoT and flagship open-source and proprietary models.
Source Section: 3.2 Main Results
Content Description: The table lists the performance comparison of Kimi k1.5 short reasoning path model with other flagship models (such as GPT-4o, Claude Sonnet 3.5, LLaMA-3.1, etc.) in multiple benchmark tests. The table includes accuracies for tasks such as MMLU, IF-Eval, CLUEWSC, C-Eval, LiveCodeBench, AIME 2024, and MATH 500.
Key Findings: Kimi k1.5’s short reasoning path model significantly outperformed existing models in multiple tasks, such as achieving 60.8% on AIME 2024, 94.6% on MATH 500, and 47.3% on LiveCodeBench. These results demonstrate that Kimi k1.5’s short reasoning path model significantly enhances performance, even under limited testing time token budgets.
## References
This paper cites a total of 43 references.
1- Reinforcement Learning and Policy Optimization
• “Politex: Regret bounds for policy iteration using expert prediction” (Abbasi-Yadkori et al. 2019): This literature studies the regret bounds for policy iteration using expert prediction, providing a theoretical basis for policy optimization in reinforcement learning.
• “Back to basics: Revisiting reinforce style optimization for learning from human feedback in LLMs” (Ahmadian et al. 2024): Discusses reinforcement learning optimization methods based on human feedback, which are of significant reference value for Kimi k1.5’s policy optimization.
• “Mirror descent policy optimization” (Tomar et al. 2020): Introduces a mirror descent policy optimization algorithm, providing technical reference for the improved policy optimization method in Kimi k1.5.
2- Language Model Pretraining and Scaling
• “Scaling Laws for Neural Language Models” (Kaplan et al. 2020): Investigates the scaling laws for neural language models, providing theoretical support for Kimi k1.5’s pretraining and context expansion.
• “Training Compute-Optimal Large Language Models” (Hoffmann et al. 2022): Discusses strategies for training compute-optimal large language models, offering important guidance for Kimi k1.5’s pretraining strategy.
• “Will we run out of data? Limits of LLM scaling based on human-generated data” (Villalobos et al. 2024): Analyzes the scaling limits of LLM based on human-generated data, providing reference for Kimi k1.5’s data strategy.
3- Reasoning and Multimodal Understanding
• “Chain-of-thought prompting elicits reasoning in large language models” (Wei et al. 2022): Studies the application of chain reasoning prompts in large language models, providing inspiration for the reasoning path design in Kimi k1.5.
• “Tree of thoughts: Deliberate problem solving with large language models” (Yao et al. 2024): Explores the use of large language models for deliberate problem solving, offering important reference value for enhancing Kimi k1.5’s reasoning capabilities.
• “Measuring multimodal mathematical reasoning with math-vision dataset” (Wang et al. 2024): Introduces the Math-Vision dataset for measuring multimodal mathematical reasoning, providing data support for Kimi k1.5’s multimodal reasoning evaluation.
4- Model Evaluation and Benchmark Testing
• “Measuring Massive Multitask Language Understanding” (Hendrycks et al. 2020): Proposes the MMLU benchmark test for evaluating multitask language understanding capabilities, providing important reference for Kimi k1.5’s performance evaluation.
• “C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models” (Huang et al. 2023): Introduces the C-Eval benchmark test for evaluating the multi-level multi-discipline capabilities of Chinese foundation models, offering important guidance for Kimi k1.5’s Chinese reasoning evaluation.
• “LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code” (Jain et al. 2024): Proposes the LiveCodeBench benchmark test for evaluating the coding capabilities of large language models, providing data support for Kimi k1.5’s code reasoning evaluation.
5- Model Deployment and Efficiency Optimization
• “Efficient Memory Management for Large Language Model Serving with PagedAttention” (Kwon et al. 2023): Studies efficient memory management in serving large language models, providing technical reference for Kimi k1.5’s deployment and inference efficiency optimization.
• “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism” (Shoeybi et al. 2020): Introduces methods for training multi-billion parameter language models using model parallelism, providing technical reference for Kimi k1.5’s training and deployment.
• “Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving” (Qin et al. 2024): Proposes the Mooncake architecture for optimizing the serving efficiency of large language models, providing technical support for Kimi k1.5’s hybrid deployment strategy.