
Introduction
Knowledge engineering is a typical representative of symbolic artificial intelligence, and knowledge graphs are the next generation of knowledge engineering technology. How will knowledge engineering influence the future development of artificial intelligence, and even enable computers to possess cognitive abilities similar to those of humans?Professor Xiao Yanghua from Fudan University and founder of Knowledge Factory was invited to give a speech titled“Knowledge Graphs and Cognitive Intelligence” at the Tencent Research Institute × Collective Intelligence Club AI & Society salon. Inspired by Professor Xiao’s lecture, I have organized a review of the development of knowledge engineering and knowledge graphs.
Large language models represented by ChatGPT are widely used in text generation, machine translation, keyword extraction, and other fields. However, the authenticity and consistency of the content generated by large language models are still difficult to guarantee. Can we use knowledge graphs with higher data quality as their knowledge source? Can the rich knowledge contained within large language models help improve the quality and breadth of knowledge graphs? This Friday, at the Collective Intelligence Club’s “Post-ChatGPT” reading session, we will discuss the possible forms of mutual promotion between large language models and knowledge graphs, as well as existing practices. Interested friends are welcome to participate!

Cao Yu | Author
Wang Yilin | Editor
What is intelligence? For more than half a century, countless scientists have researched it, and various factions have emerged, yet everyone’s focus seems to always be on the currently “victorious” side. In recent years, connectionism, represented by deep learning, has achieved fruitful results. Nowadays, when artificial intelligence is mentioned, it is generally assumed to be based on deep learning and machine learning methods, while other research directions seem to be forgotten.
As the dividends of big data are exhausted and the ceiling of deep learning model performance approaches, people are seeking new breakthroughs everywhere. The momentum of “those who possess knowledge will dominate the world” is growing. The symbolism represented by knowledge graphs is gaining attention; this treasure trove containing a large amount of prior knowledge has yet to be effectively mined.
For decades, symbolism and connectionism have alternated in prominence. Will this opposition continue in the future, or will we find an organic combination of the two, moving towards a path of cooperative development?
Knowledge engineering is a typical representative of symbolic artificial intelligence, and the increasingly popular knowledge graph is a new generation of knowledge engineering technology. How will knowledge engineering influence the future development of artificial intelligence, even enabling computers to possess cognitive abilities similar to those of humans? This article will systematically review the development of knowledge engineering over the past 40 years, considering the technological and social background of the internet big data era, and look forward to the future prospects of knowledge engineering and knowledge graphs.
Breakthroughs in Intelligence: Knowledge Engineering
Breakthroughs in Intelligence: Knowledge Engineering
Artificial intelligence is generally considered to consist of three levels: computational intelligence, perceptual intelligence, and cognitive intelligence. In brief, computational intelligence refers to rapid computation, memory, and storage capabilities; perceptual intelligence refers to sensory capabilities such as vision, hearing, and touch, with current popular technologies including speech recognition, speech synthesis, and image recognition; cognitive intelligence refers to the ability to understand and explain.

At present, computational intelligence, aimed at rapid computation and storage, has basically been achieved. In recent years, driven by deep learning, perceptual intelligence targeting recognition technologies such as vision and hearing has also achieved good results. However, compared to the former two, the realization of cognitive abilities is much more challenging. For example, a kitten can “recognize” its owner, which is a perceptual ability that most animals possess, whereas cognitive intelligence is a unique human ability. One of the research goals of artificial intelligence is to enable machines to possess cognitive intelligence, allowing them to “think” like humans.
This human-like thinking ability is specifically reflected in the machine’s ability to understand, reason, explain, generalize, and deduce data and language, embodying all the unique cognitive abilities of humans. Both academia and industry hope to simulate human-like wisdom in machines to tackle practical problems such as precise analysis, intelligent search, natural human-computer interaction, and deep relationship reasoning in the age of intelligence.
Having established that cognitive intelligence is the key to machine intelligence, we must further consider how to achieve cognitive intelligence—how to enable machines to possess the cognitive ability to understand and explain.
In recent years, due to the disappearance of the big data dividend, deep learning has faced significant bottlenecks, necessitating the search for new breakthroughs. Statistical learning methods represented by deep learning heavily rely on samples and can only learn information from data. Some researchers have noted that another important breakthrough direction lies in knowledge, especially symbolic knowledge.
Professor Xiao Yanghua believes that knowledge graphs and the series of knowledge engineering technologies represented by knowledge graphs are at the core of cognitive intelligence. Knowledge engineering mainly includes knowledge acquisition, knowledge representation, and knowledge application. The direction we can attempt to break through lies in the utilization of knowledge, particularly in the application of combining symbolic knowledge and numerical models. The ultimate result of these efforts is to enable machines to possess the ability to understand and explain.

Professor Xiao Yanghua is delivering a speech on knowledge graphs at the AI & Society salon, Issue 15.
The Past and Present of Knowledge Engineering
The Past and Present of Knowledge Engineering
-
1950s—Early 1970s
The Early Artificial Intelligence Before Knowledge Engineering’s Birth
So how exactly will knowledge graphs assist artificial intelligence? Looking back at history can help us better understand the future. Let’s roll back the wheel of time to August 1956, when several psychologists, mathematicians, computer scientists, and information theorists gathered at the tranquil Dartmouth College in Hanover, USA, for a two-month seminar to earnestly and passionately discuss the issue of using machines to simulate human intelligence. They gave the content of the conference a resounding name: artificial intelligence. (artificial intelligence).
Thus, the discipline of artificial intelligence was born.
 Representative Figures and Achievements of Traditional Knowledge Engineering
Representative Figures and Achievements of Traditional Knowledge EngineeringAfter the Dartmouth Conference, the participants achieved a series of remarkable research results. A representative achievement was the logical machine LT developed by A. Newell, J. Shaw, and H. Simon, which proved 38 mathematical theorems; in 1960, they defined the logical reasoning framework of GPS and proposed the idea of heuristic search; in 1956, Samuel developed a checkers program that had self-learning capabilities and could continuously summarize experiences to improve its game skills. There were many other exciting achievements, which sparked the first peak of artificial intelligence development.

Among them, the symbolism school represented by Newell and Simon first achieved fruitful results, with the most famous representative being the logical machine LT.
What is the core idea of symbolism? Symbolism believes that artificial intelligence originates from mathematical logic and that the essence of intelligence is the operation and computation of symbols. Symbolism has long stood out among the various factions and has made significant contributions to the development of artificial intelligence. Of course, it also laid the foundation for the later flourishing knowledge engineering.
Next, let’s shift our focus to the early 1960s to early 1970s. While academia was still celebrating the victories achieved in the early development of artificial intelligence, unrealistic research goals led to a series of project failures and unmet expectations. Overly high expectations always bring more destructive disappointment, and finally, artificial intelligence entered its first cold winter.
-
1977
The Birth of Knowledge Engineering
After experiencing setbacks in the field of artificial intelligence, researchers had to calm down and rethink the future path. At this time, Edward A. Feigenbaum, a student of Simon, stepped forward. He analyzed that traditional artificial intelligence overlooked specific knowledge and that artificial intelligence must incorporate knowledge.

Under Feigenbaum’s leadership, expert systems were born. Expert systems, as an important branch of early artificial intelligence, are program systems capable of solving problems at an expert level within specific domains.
Expert systems generally consist of two parts: a knowledge base and an inference engine. They use knowledge and experience provided by one or more experts to actively reason and make judgments to solve problems by simulating the thought processes of experts. The first successful expert system, DENDRAL, was launched in 1968. In 1977, Feigenbaum officially named it knowledge engineering.
The goal of knowledge engineering is to integrate knowledge into machines, enabling machines to utilize our human knowledge and expert knowledge to solve problems..
The Rise and Development of Knowledge Engineering
-
1970s—1990s
The Flourishing Development of Knowledge Engineering
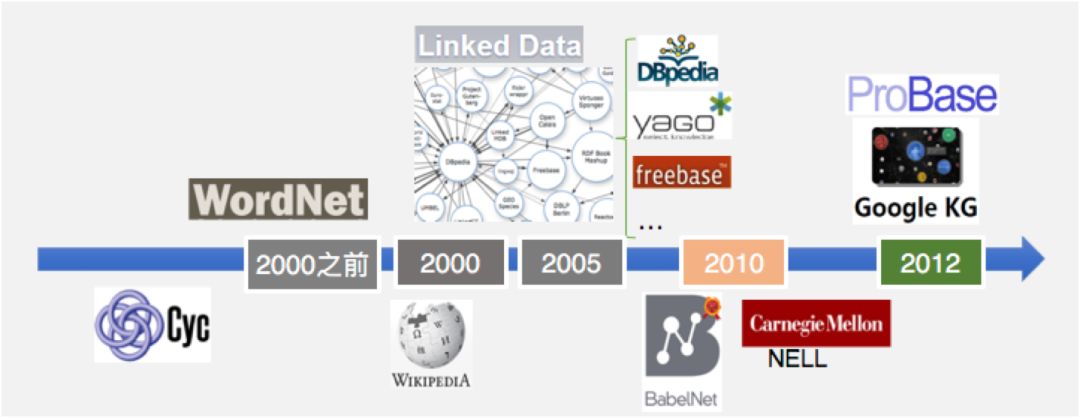
After the birth of knowledge engineering in 1977, this field continued to develop, producing new logical languages and methods. Among them, one node is particularly important.
As mentioned earlier, expert systems were formed, but how did expert systems develop? Could knowledge engineering be effectively implemented in industry? The expert configuration system XCON from American DEC company provided a preliminary answer. When customers ordered DEC’s VAX series computers, the expert configuration system XCON could automatically configure components according to demand. In the six years of its use, it handled eighty thousand orders, saving funds.
At this point, artificial intelligence began to gradually enter commercial applications.
Other notable expert systems include Cyc, established by Douglas Lenat in 1984, aimed at collecting a knowledge base of common knowledge in life. Cyc not only contains knowledge but also provides many reasoning engines, covering 500,000 concepts and 5 million pieces of knowledge. Additionally, there are dictionaries such as WordNet maintained by a psychology professor from Princeton University. Similarly, in Chinese, there are synonyms dictionaries and their extended versions, as well as HowNet. Unfortunately, with the demise of Japan’s fifth-generation computers, expert systems, after a decade of golden period, gradually declined due to their inability to overcome high costs of manual construction and difficulties in knowledge acquisition.
-
1998
The World Wide Web and Linked Data
The emergence of the World Wide Web greatly facilitated knowledge acquisition. In 1998, Tim Berners-Lee, the father of the World Wide Web, proposed the semantic web again. Its core is: The semantic web can directly provide machines with knowledge that can be processed by programs. By transforming documents on the web into semantics that computers can understand, the internet becomes a medium for information exchange. However, the semantic web is a relatively macro concept that requires a “top-down” design, making it difficult to implement.
 Semantic Analysis and Knowledge Networks
Semantic Analysis and Knowledge Networks
Due to the difficulties in implementing top-down designs, scholars shifted their focus to the data itself, proposing the concept of linked data. Linked data aims to not only publish data on the semantic web but also establish links between the data itself to form a vast network of linked data. Among them, the DBpedia project is currently known as the first large-scale open domain linked data. Similar projects include Wikipedia, Yago, and other structured knowledge databases.
-
2012 – Knowledge Graphs
A New Development Era for Knowledge Engineering
Alongside Wikipedia, Freebase also existed. While Wikipedia is aimed at humans, Freebase emphasizes machine readability. Freebase has 40 million entities and was acquired by Google, which gave it the catchy name “Knowledge Graph.”
Why Traditional Knowledge Engineering Faces Numerous Challenges?
In the 1970s and 1980s, traditional knowledge engineering did solve many problems, but these problems shared a distinct characteristic: most of them achieved success in scenarios with clear rules, defined boundaries, and closed applications. Once open problems were involved, success became nearly impossible, such as proving mathematical theorems or playing chess.
Why did traditional knowledge engineering have such stringent conditions? Because traditional knowledge engineering is a typical top-down approach that heavily relies on expert intervention. The fundamental goal of knowledge engineering is to impart expert knowledge to machines, hoping that machines can utilize expert knowledge to solve problems. In traditional knowledge engineering, it is first necessary to have domain experts who can express their knowledge; further, knowledge engineers must convert the expert-expressed knowledge into a format that computers can process.
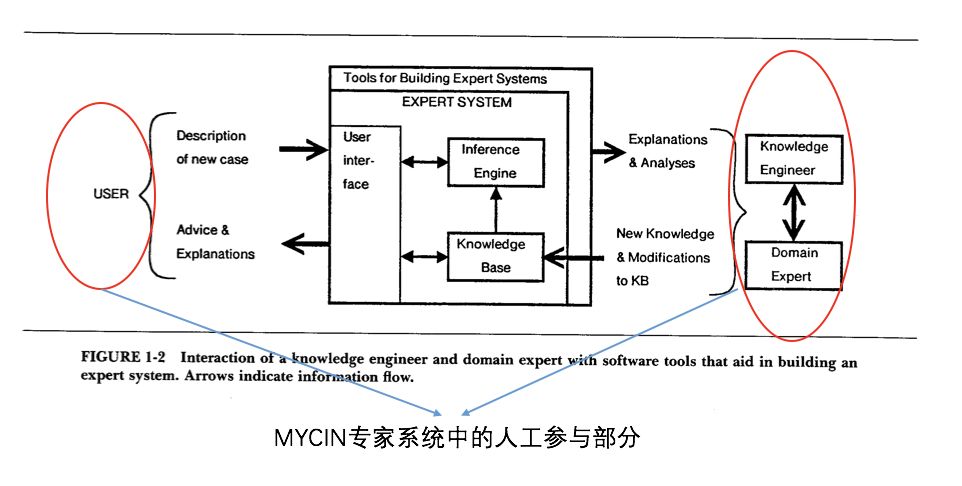
Such reliance on experts to express, acquire, and apply knowledge leads to many issues. On one hand, the knowledge base behind the machine is very limited in scale, and on the other hand, its quality also raises many questions. This is why we say traditional knowledge engineering faces numerous challenges.
In addition to the aforementioned issues, traditional knowledge engineering faces two major difficulties:
First: Difficulty in Knowledge Acquisition
Implicit knowledge, procedural knowledge, and other types are hard to express. For example, how to express the knowledge used by a traditional Chinese medicine doctor in diagnosing patients; different experts may have subjectivity. For example, very few diseases have clearly defined treatment protocols in our country, and most depend on the doctor’s subjectivity.
Second: Difficulty in Knowledge Application
Many applications, especially many open applications, easily exceed the pre-set knowledge boundaries; many applications also require common sense support, and the biggest fear of artificial intelligence is precisely common sense. Why? Because common sense is difficult to define, express, and represent; knowledge updating is challenging, heavily reliant on domain experts, and there are many anomalies or difficult-to-handle situations.
The Internet Applications StimulateThe Era of Big Data Knowledge Engineering
Due to the various reasons mentioned in the previous section, knowledge engineering became silent after the 1980s.
Although the problem-solving ideas of knowledge engineering are highly forward-looking, the limited scale of traditional knowledge representation cannot meet the demands of large-scale open applications in the internet era. To address these issues, researchers in knowledge engineering from academia and industry have attempted to find new solutions.
Under such demands, Google launched its own knowledge graph, using semantic search to gather information from various sources to improve search quality. The introduction of the knowledge graph essentially declared the entry of knowledge engineering into a new era, which we call the era of big data knowledge engineering.

Screenshot of Google Knowledge Graph
Knowledge Graphs Leading the Renaissance of Knowledge Engineering
Knowledge Graphs Leading the Renaissance of Knowledge Engineering
Unlike traditional knowledge acquisition, which relied on experts in a top-down manner, the current approach is to utilize data in a bottom-up manner to mine and extract knowledge from the data. Additionally, crowdsourcing and collective intelligence have become a new path for large-scale knowledge acquisition. High-quality UGC content provides a high-quality data source for automated knowledge mining.
In summary, knowledge engineering has entered a new stage under the leadership of knowledge graph technology, referred to as the big data era of knowledge engineering. Professor Xiao Yanghua proposed a simple formula to illustrate the relationship and differences between traditional knowledge engineering and the new generation of knowledge engineering represented by knowledge graphs:
Small knowledge + Big data = Big knowledge
The term big data knowledge engineering is BigKE, which will significantly enhance the level of machine cognitive intelligence. So, what is the fundamental significance of big data knowledge engineering for our artificial intelligence? It is to enhance the level of machine cognitive intelligence. We are experiencing a transitional phase from perceptual intelligence to cognitive intelligence, and the most important technology in the future is to achieve cognitive intelligence.
In the era of big data, what unique charm do knowledge graphs hold? Why are they receiving such widespread attention?
Knowledge graphs make machine language cognition possible. For machines to recognize and understand language, they need the support of background knowledge. Knowledge graphs, rich in entities and relationships between concepts, can serve as background knowledge to support machines in understanding natural language.
Knowledge graphs enable explainable artificial intelligence. At any stage of artificial intelligence development, we require the explainability of things; current deep learning is often criticized for lacking explainability. The concepts, attributes, and relationships contained in knowledge graphs are inherently suitable for explanation.
Through prior knowledge such as knowledge graphs, we empower machine learning to reduce its dependence on samples and enhance its capabilities.
Knowledge will significantly enhance machine learning capabilities. Traditional machine learning learns knowledge through a large number of samples. As the big data dividend gradually disappears, it encounters developmental bottlenecks. However, empowering machine learning with prior knowledge such as knowledge graphs may lead to a symbiotic development between connectionism and symbolism in the new era.
In addition to the aforementioned advantages, knowledge graphs are also very useful in a range of practical applications, such as search, precise recommendations, risk identification, and deepening understanding and insights into industry data, playing roles in various application scenarios.
The information technology revolution continues, and data will continue to evolve towards larger scales and more connections. Against this backdrop, knowledge graphs will lead knowledge engineering towards revival, promoting the realization of cognitive intelligence in machines.
References
[1] Xiao Yanghua: Knowledge Graphs and Cognitive Intelligence
[2] Collective Intelligence Club. The Ultimate of Science: A Discussion on Artificial Intelligence [M]. People’s Posts and Telecommunications Press, 2015-07
[3] Nick. A Brief History of Artificial Intelligence [M]. People’s Posts and Telecommunications Press, 2017
[4] An Overview of the Development of Knowledge Graphs
“Post-ChatGPT” Reading Session Launched

Recommended Reading