Reprinted with permission from AI TIME Discussion
Author: Liu Zhiyuan
Editor: Gege
“Language is like amber, preserving many precious and wonderful thoughts safely inside.” Since the dawn of humanity, natural language has carried the wisdom of generations, accumulating endless knowledge. This rich treasure of knowledge has attracted many curious AI researchers to cultivate, explore, and reconstruct.
On September 25, 2020, at the “2020 China Science and Technology Summit Series Youth Scientist Salon – Artificial Intelligence Academic Ecology and Industrial Innovation” hosted by the China Association for Science and Technology and organized by the Department of Computer Science and Technology at Tsinghua University and AI TIME Discussion, Associate Professor Liu Zhiyuan from Tsinghua University delivered an academic report titled “Knowledge-Guided Natural Language Processing,” which provides a new perspective on the importance of language knowledge and world knowledge for natural language processing in the era of deep learning.
1. NLP Research Needs to Start from the Characteristics of Language Itself
Natural Language Processing (NLP) aims to enable computers to understand and use human language. From part-of-speech tagging, named entity recognition, coreference resolution, to semantic and syntactic dependency analysis, NLP practitioners strive to extract structured information from unstructured sequences of speech or text. It is like searching for order in chaos, whether in semantic or syntactic structures, which is not simple.
Language, as a symbolic system, contains various language units of different granularities. For example, Chinese characters, words, phrases, sentences, documents, and the World Wide Web formed by interconnected documents, with increasing granularity from bottom to top.
Many tasks in natural language processing involve calculating semantic relevance across different levels of language units. For instance, information retrieval is about finding which documents are semantically most relevant to a given query or phrase. Due to the varying sizes of language granularity, this adds complexity to the calculations.
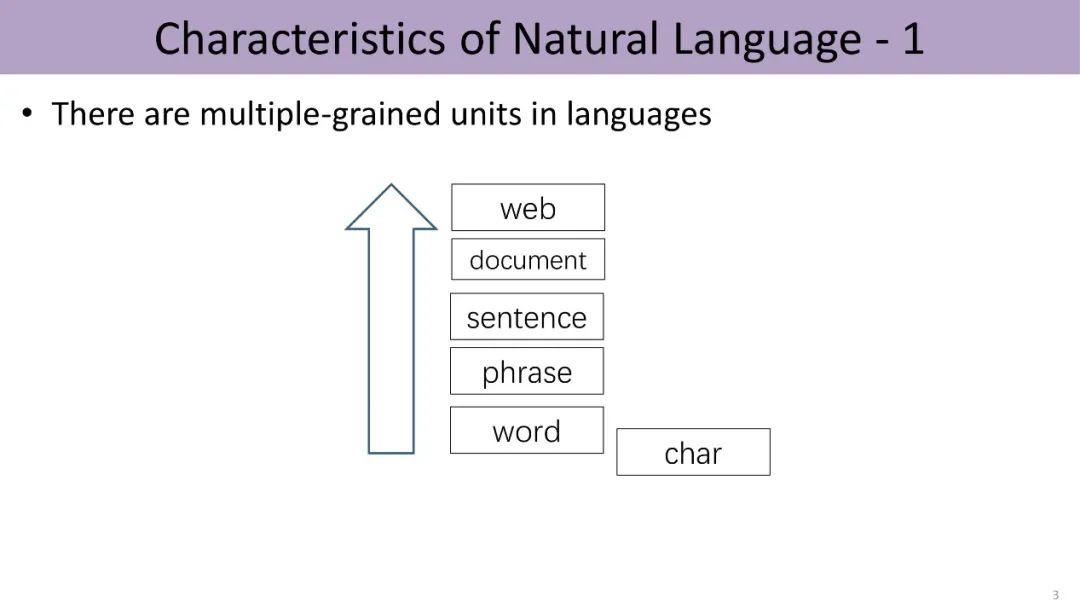
Fortunately, we can establish multi-granularity language associations through deep learning distributed representations.
Deep learning has been a technological revolution sweeping the AI community in the past decade, and one important reason for its great success in the field of natural language processing is distributed representation. From vocabulary, word meanings, phrases, entities to documents, deep learning maps different granularities of language units into a unified low-dimensional vector distributed representation space, achieving a unified implicit representation, which facilitates the integration and computation of semantic information across different language units. This provides a unified representation foundation for NLP tasks, avoiding the need for different similarity calculation methods for different tasks, and can better solve the problem of data sparsity in large-scale long-tail distribution.
From 2015 to 2017, Liu Zhiyuan’s laboratory conducted a lot of related work on distributed representations in deep learning. This includes: unified representation of Chinese characters and words, representations of English and Chinese word meanings, phrase representations, entity and document representations, etc.
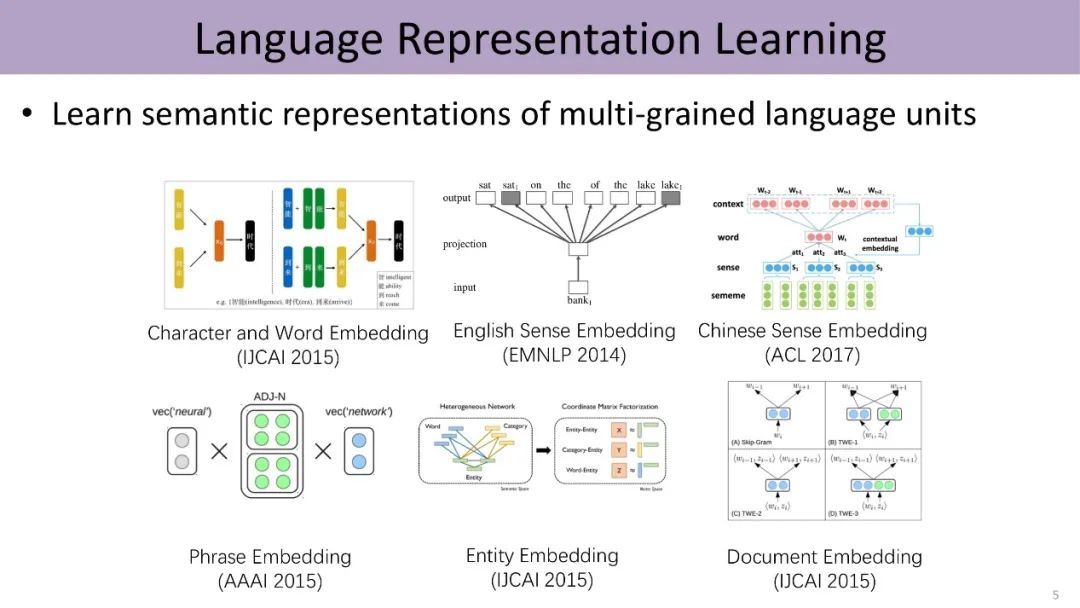
2. Integrating Language Knowledge Base HowNet
Although deep learning has achieved remarkable results today, natural language processing has not been thoroughly solved. A review of NLP published in Science in 2015 mentioned that despite the fruitful results of machine learning and deep learning, tackling the real challenges, including semantic, context, and knowledge modeling, still requires more research and discovery.

This involves another characteristic of language: the phenomenon of polysemy. In daily communication, we regard words or characters as the smallest units of use. However, these are not the smallest semantic units, as there are finer levels of word meanings behind them, for example, the word “apple” has at least two interpretations: fruit and company product. So is sense the smallest unit? Probably not.
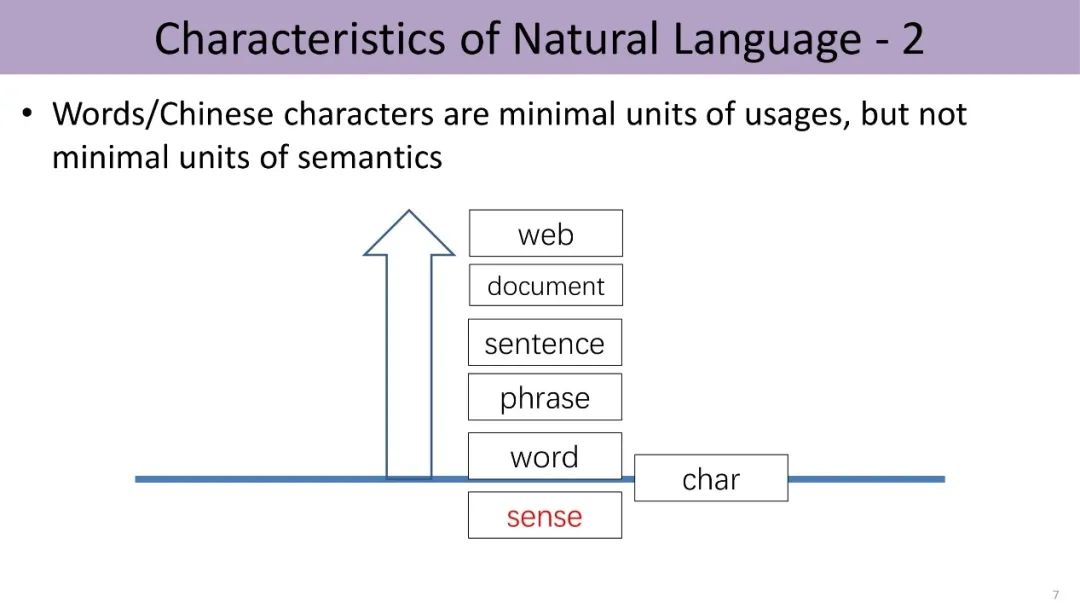
Linguists point out that word meanings can be infinitely subdivided to find a set of semantic “atoms” to describe all concepts in language. This set of atoms is called sememes, which are the smallest semantic units. For example, the word “vertex” may have two meanings, each represented by finer sememes. As shown, the left meaning refers to the highest point of something, represented by a combination of four sememes.
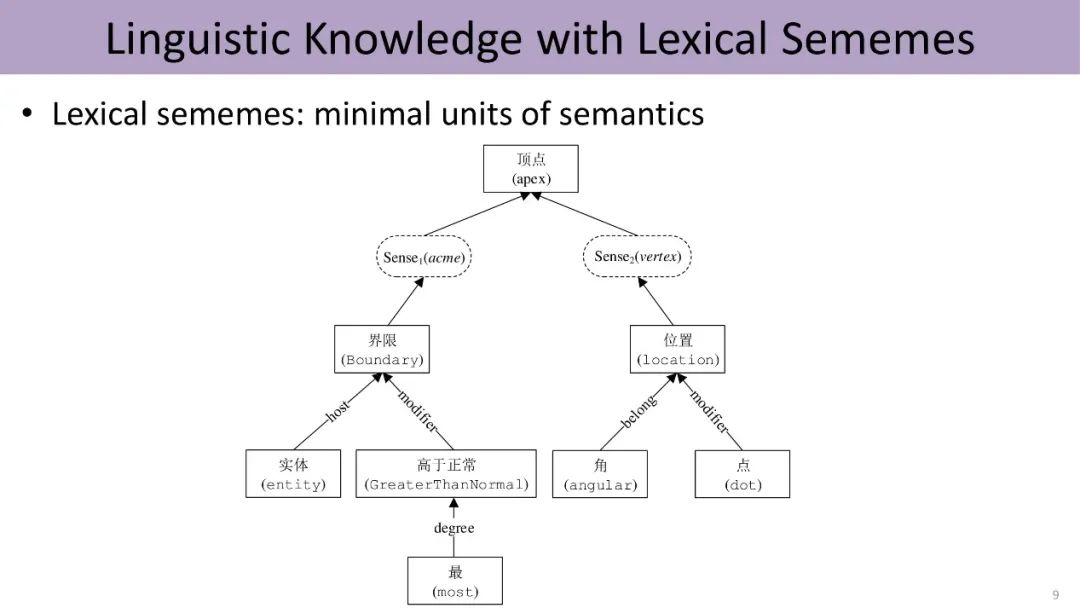
In the area of manually annotating sememes, linguist Dong Zhendong has worked tirelessly for decades to manually annotate a knowledge base called HowNet, released in 1999. After several iterations, it now includes about 2000 different sememes and uses these sememes to annotate the meanings of hundreds of thousands of words in Chinese and English.

However, in the era of deep learning, data-driven methods represented by word2vec have become mainstream, gradually pushing traditional linguistically annotated large-scale knowledge bases into the historical corner, with citations of knowledge bases like HowNet and WordNet significantly declining.
So, is data-driven the ultimate AI solution?
Intuitively, it is not. Data is merely external information, a product of human wisdom, but cannot reflect the deep structure of human intelligence, especially high-level cognition. Can we teach computers language knowledge?
The Fusion of HowNet and Word2Vec
In 2017, Liu Zhiyuan and others attempted to integrate HowNet into a milestone work in deep learning natural language processing, Word2Vec, achieving exciting experimental results.
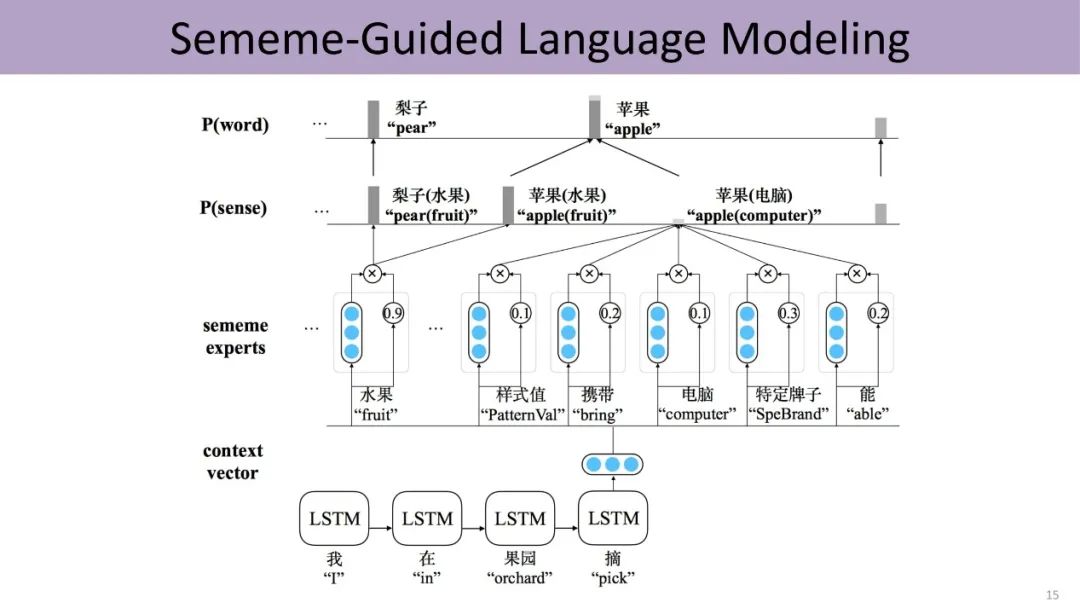
The following figure shows sememe-guided word embedding, where the model calculates the attention of different meanings of the same word based on context, obtaining weights for different meanings to disambiguate, and further learns the representation of that meaning using context. Although it utilizes the skip-gram method from traditional Word2Vec, where the center word Wt predicts the words in the sliding window context, the center word’s embedding is composed of the embeddings of annotated sememes. Therefore, this research integrates the three-layer structure of word, sense, and sememe from HowNet into word embedding, making comprehensive use of information from both the knowledge base and data.
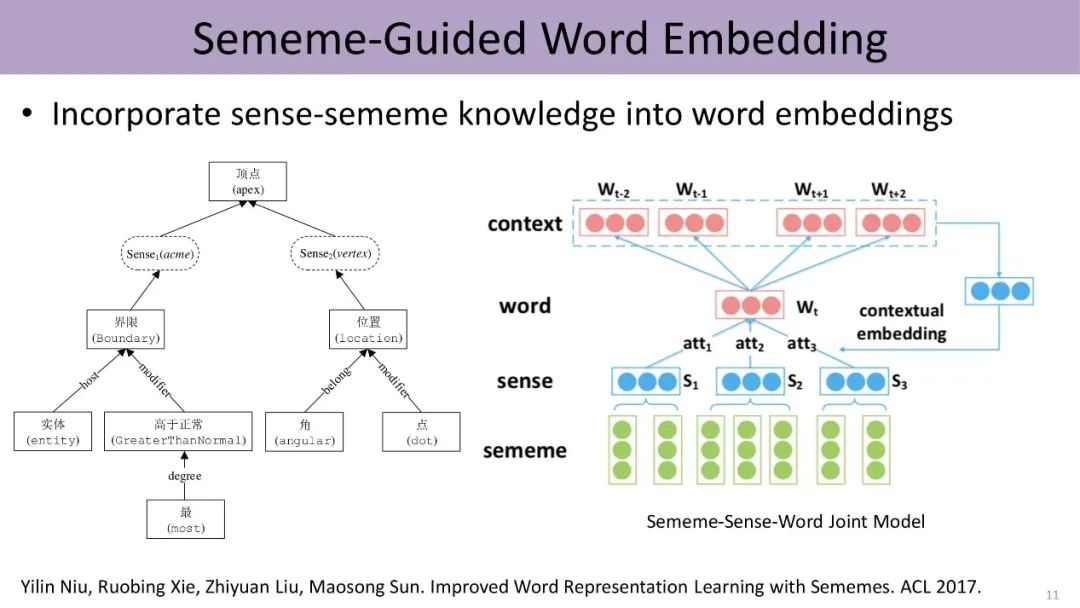
The experimental results prove that integrating knowledge from HowNet can significantly enhance model performance, especially in tasks involving cognitive reasoning, analogy reasoning, and other components. Moreover, we can automatically discover which meanings of ambiguous words belong to which meanings in specific contexts. Unlike previous supervised or semi-supervised methods, this model does not directly label the meanings corresponding to these words but utilizes the HowNet knowledge base to accomplish this. Therefore, it is evident that knowledge bases can provide meaningful information for text understanding.

Encouraged by this work, Liu Zhiyuan’s team extended the application of knowledge from the word level to the sentence level. In the past, deep learning directly utilized the semantics of the context to predict the next word. Now, the three-layer structure of word, sense, and sememe is embedded into the prediction process. First, the previous context predicts the sememe corresponding to the next word, then these sememes activate the corresponding senses, and finally, the senses activate the corresponding words. On one hand, this method introduces knowledge, training a relatively better language model with less data; on the other hand, the resulting language model has higher interpretability, clearly indicating which sememes led to the final prediction result.
HowNet, as a significant lifelong achievement of Mr. Dong Zhendong, has been open-sourced for everyone to download and use. It is hoped that more teachers and students will recognize the unique value of knowledge bases and carry out related work. Below is a reading list related to sememe knowledge.

3. World Knowledge: Understanding Implicit Meanings
In addition to linguistic knowledge, world knowledge is also important information carried by language.
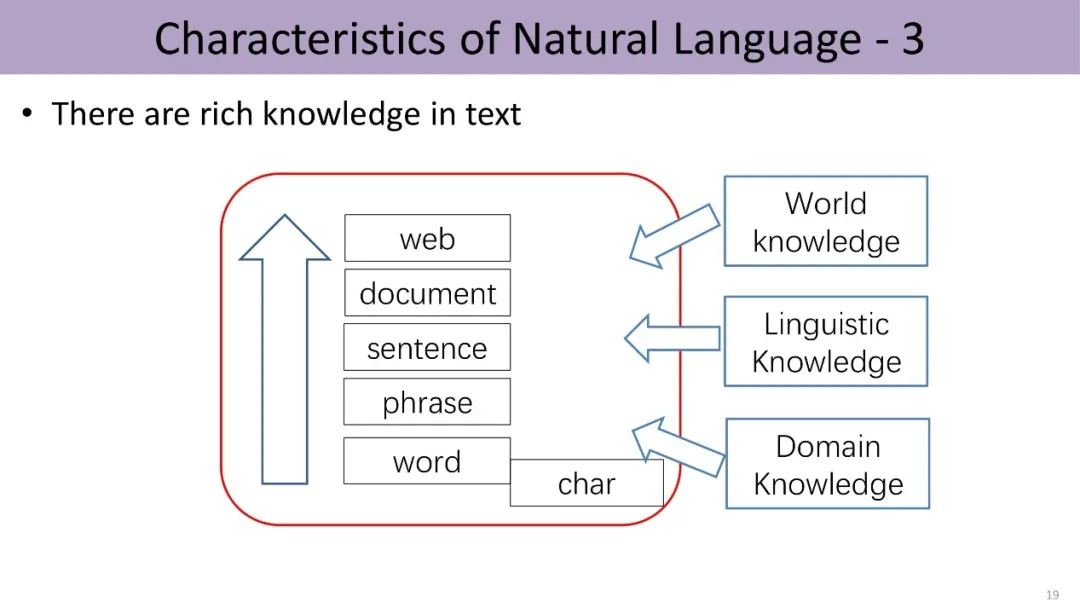
In the real world, there are various entities and their different relationships, such as Shakespeare created “Romeo and Juliet”; this world knowledge can constitute a knowledge graph. In a knowledge graph, each node can be seen as an entity, and the edges connecting them reflect the relationships between these entities. The graph is composed of several triples, each including a head entity, a tail entity, and the relationship between them.
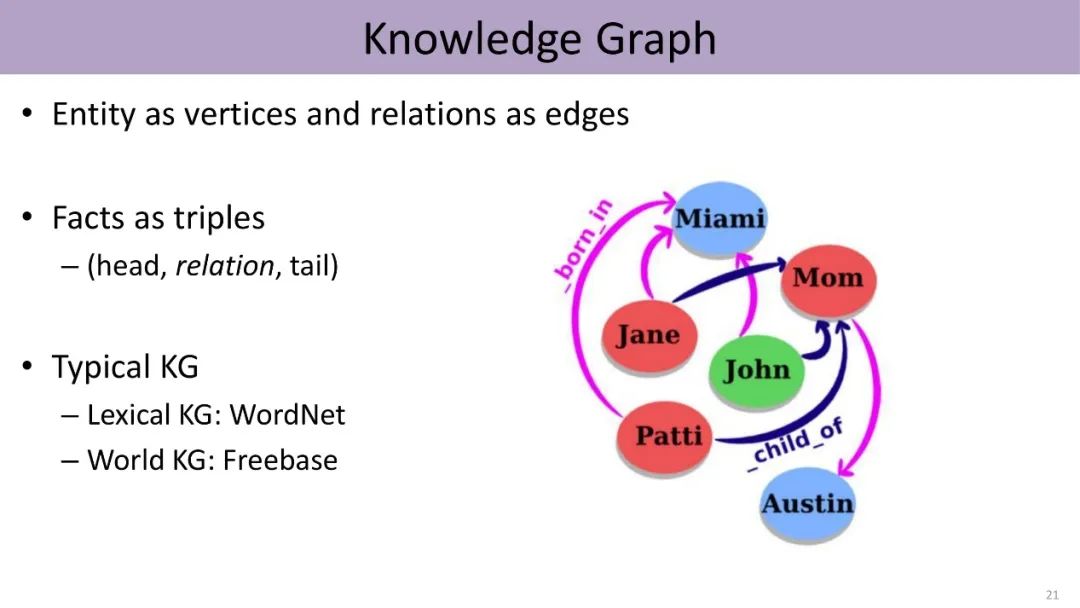
Because entities in knowledge graphs belong to different categories and have different connection information, we can use a knowledge attention mechanism to combine low-dimensional vector knowledge representations with text context representations for fine-grained entity classification.
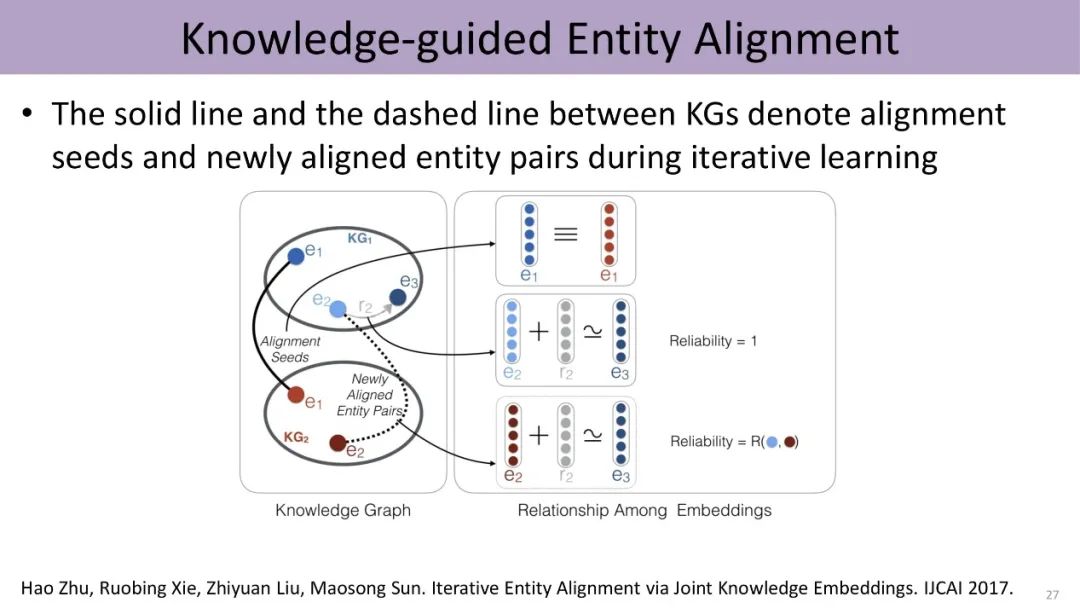
Another direction is the fusion of two different knowledge graphs, which is a typical entity alignment problem. In the past, complex algorithms were generally designed to discover various subtle connections between the two graphs. Now, the laboratory has proposed a simple method to perform knowledge embedding on both heterogeneous graphs to obtain two different spaces, and then use entity pairs with certain connections in these two graphs, which constitute seeds, to combine the spaces of the two graphs. This work has found that this method can better align entities.
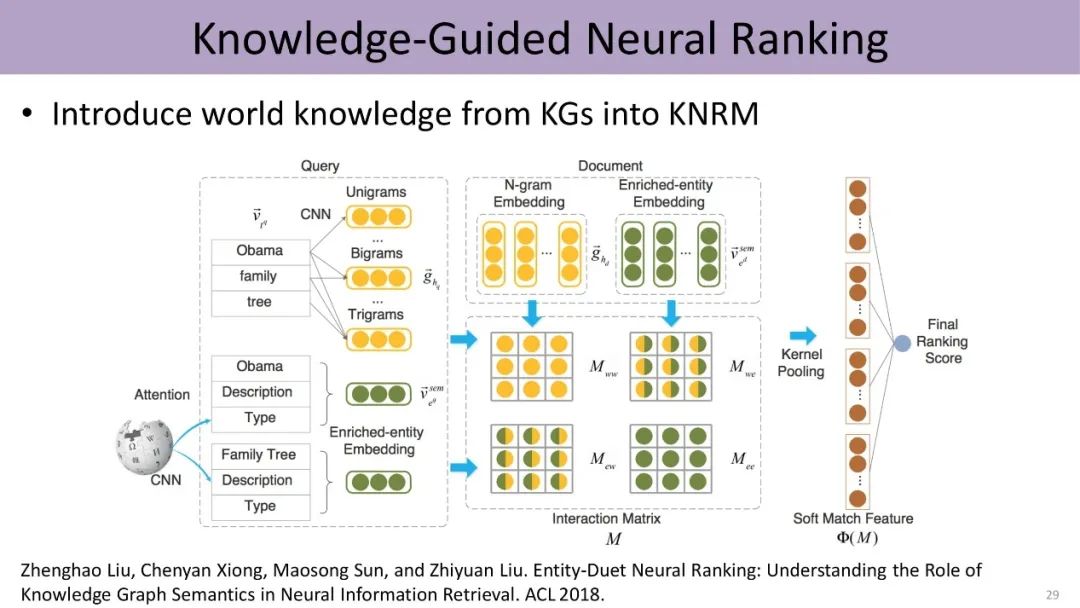
At the same time, knowledge can also guide us in information retrieval, calculating the similarity between queries and documents. In addition to considering the information of words in the query and document, we can form different matrices from entity information and the relationships between entities and words, thus supporting the training of ranking models.
Finally, the emergence of pre-trained language models has expanded deep learning from supervised data to large-scale unsupervised data. In fact, every sentence in these large-scale texts contains numerous entities and their relationships. To understand a sentence, we often need support from external world knowledge.
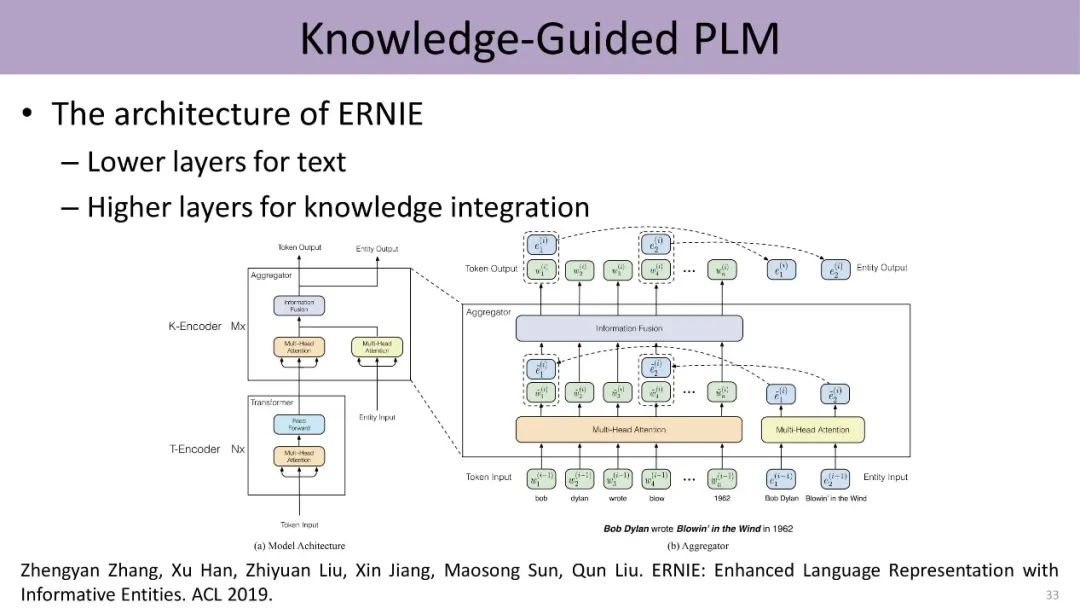
Can we incorporate external knowledge bases into pre-trained language models? In 2019, the team led by Liu Zhiyuan proposed the ERNIE model, using knowledge representation algorithms (transE) to represent entities in knowledge graphs as low-dimensional vectors, and utilizing a novel aggregator structure to bidirectionally integrate word-related information with entity-related information through a feedforward network, achieving the goal of incorporating structured knowledge into language representation models.
4. Conclusion
This report mainly discusses knowledge-guided natural language processing related work from the perspectives of sememe knowledge and world knowledge. An important direction for future natural language processing is to integrate various types of human knowledge to deeply understand language, read between the lines, and understand implicit meanings. Liu Zhiyuan and others have also published a monograph on representation learning for natural language processing, available for free download and study.


Related Links and References:




Intern/Full-time Editor Journalist Recruitment
Join us to experience every detail of writing for a professional technology media outlet, in the most promising industry, and grow alongside a group of the best people from around the world. Located in Beijing, Tsinghua East Gate, reply with “Recruitment” on the Big Data Digest homepage dialogue page for more details. Please send your resume directly to [email protected]