

Paper link:
https://arxiv.org/abs/2204.02849

Showcasing some text-to-image generation results of KNN-Diffusion:

The left side of the image shows the text-to-image effect of KNN-Diffusion, while the right side shows the effect of text-driven local semantic editing. It can be seen that when we input the model with “With a bow tie”, the model can very precisely put a cartoon bow tie on the pea person. In addition, to prove the robustness of the method proposed in this paper, the author also applied the kNN method to two currently advanced diffusion backbone models, achieving very satisfactory results.
1.Introduction
Although current large-scale text-image diffusion models exhibit excellent creativity in tasks such as image generation, image editing, and even video generation, it is time to consider how to reduce the difficulty of using diffusion models for their continuous development. Currently, diffusion models still face several major challenges:
1. The demand for large-scale paired data. To achieve high-quality generation results, current diffusion models are still limited by existing large-scale text-image paired datasets.
2. High computational cost and efficiency. Training diffusion models on highly complex natural image distributions usually requires very large model capacity, data, batch size, and training time, which is not friendly to general researchers, limiting the growth of the diffusion model community.
To address the above issues, this paper proposes a KNN-Diffusion model that combines traditional retrieval methods. KNN-Diffusion can utilize the kNN method to obtain data through large-scale retrieval, allowing the model to be trained without any textual data. Specifically, KNN-Diffusion has two forms of input:
1. Image embeddings (during training) or text embeddings (during inference), obtained using a multimodal CLIP[1] encoder;
2. kNN embeddings, representing k most similar images in the CLIP latent space. This allows for text-image pair training using only the embeddings generated by CLIP in the absence of text.
During the model inference phase, it is sufficient to convert the input text into kNN embeddings to complete image generation inference in new domains. Additionally, the author proposes a text-driven local semantic operation method using the CLIP model, without the need for masks specified manually in previous methods, significantly improving image editing efficiency. The following figure demonstrates the example effects of this method. After specifying modification commands to the model, KNN-Diffusion can automatically locate the target area to be modified, synthesizing a high-resolution image while preserving the identity semantics of the original image, whereas other comparative methods such as Text2Live[2] and Textual Inversion[3] may alter the identity information of the original image.

2.Method of This Paper
The KNN-Diffusion model mainly consists of three key modules, as shown in the figure below: (1) a multimodal text-image encoder, directly using the CLIP model; (2) a retrieval model, consisting of a data structure that can contain image embeddings, which can serve as index vectors for the kNN search algorithm; (3) an image generation network, which conditions on the retrieval vectors and uses a diffusion-based image generation model as the backbone. During the training and inference phases, the image generation network conditions on k image embeddings and uses the retrieval model to search and select to ensure the conditional distribution is similar in training and inference. Below we will detail the implementation details of these modules.

2.1 Retrieval Model
 , a pre-trained image encoder
, a pre-trained image encoder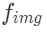 , and an index
, and an index . The encoders map text descriptions and image samples into a joint multimodalfeature space
. The encoders map text descriptions and image samples into a joint multimodalfeature space . The index
. The index stores valid image representations from an existing dataset
stores valid image representations from an existing dataset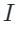 , where represents the dataset. During training, the author uses these indexes to effectively extract the nearest
, where represents the dataset. During training, the author uses these indexes to effectively extract the nearest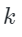 neighbors based on the given image embedding:
neighbors based on the given image embedding: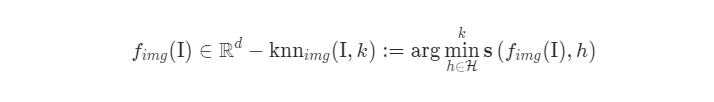
where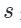 is a distance function. The set
is a distance function. The set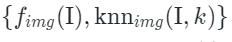 is then used as the condition for the generative model. During inference, simply provide a query text t, and the model will extract an embedding
is then used as the condition for the generative model. During inference, simply provide a query text t, and the model will extract an embedding 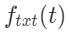 . At this point, the condition for the generative model is this embedding and its
. At this point, the condition for the generative model is this embedding and its k nearest neighbors in the dataset.
k nearest neighbors in the dataset.
2.2 Image Generation Network
To demonstrate the robustness of the method proposed in this paper, the author applied KNN-Diffusion to two different diffusion backbones. These are the discrete diffusion model[4] and continuous diffusion model[5], although these two models differ greatly in practical implementation, they share the same theoretical foundation. Assuming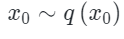 is a sample in our image distribution. The forward process of the diffusion model
is a sample in our image distribution. The forward process of the diffusion model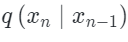 is a Markov chain that adds noise at each step. The reverse process
is a Markov chain that adds noise at each step. The reverse process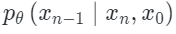 is a denoising process that removes noise from the initialized noisy state. During inference, the model can produce an output starting from noise and gradually
is a denoising process that removes noise from the initialized noisy state. During inference, the model can produce an output starting from noise and gradually eliminate the noise. The author experimentally proves that using the kNN method can achieve robust generation results in both diffusion model paradigms.
eliminate the noise. The author experimentally proves that using the kNN method can achieve robust generation results in both diffusion model paradigms.
2.3 Text-Driven Local Semantic Operations
Previous methods for achieving local semantic editing of images often relied on user-input region masks, limiting them to global edits. Moreover, these methods have other drawbacks, such as only being able to perform local texture editing without modifying complex image structures. Additionally, most methods tend to lose the identity information originally present in the image during editing.
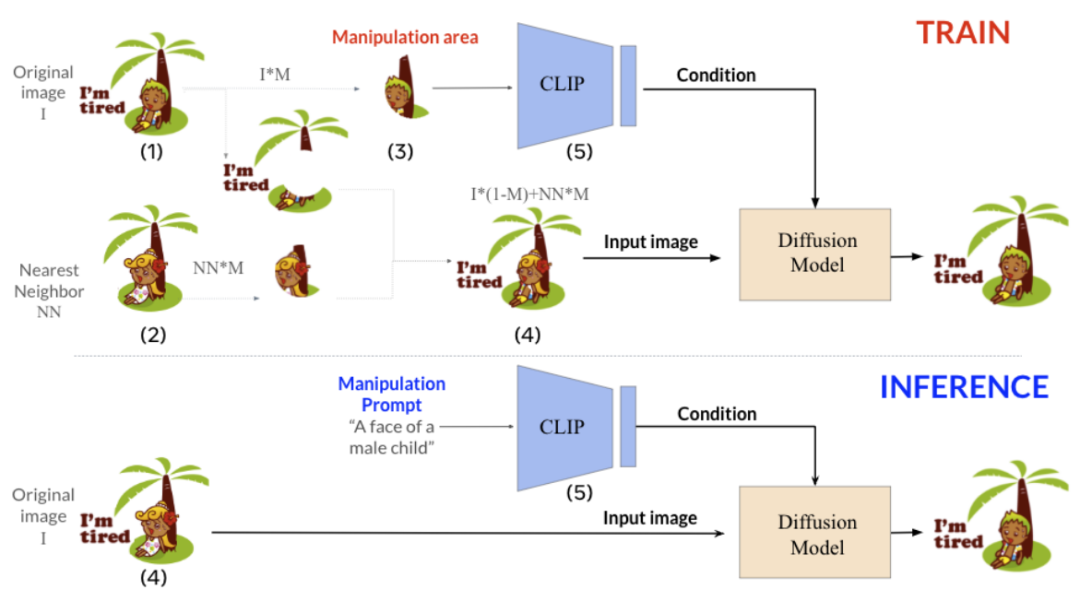
The author of this paper addresses these issues by extending KNN-Diffusion to perform local and semantically aware image editing operations without providing any masks. The above figure shows the overall process of this method. To achieve this task, the author adopts a reverse thinking approach, that is, training the model to generate back to the original image from the edited version. Specifically, they first create an edited version of the image that differs only in certain local areas from the original image. For example, given an image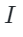 with a randomly selected local area
with a randomly selected local area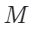 , they select the nearest neighbor area
, they select the nearest neighbor area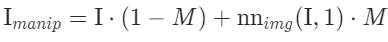 to replace that area to construct the edited version of the image
to replace that area to construct the edited version of the image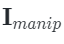 .
.
Where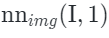 is obtained through alignment algorithms with
is obtained through alignment algorithms with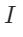 the nearest neighbor after alignment. The model then takes the edited version of the image along with the CLIP embeddings of the local area from the original image as joint inputs. This CLIP embedding contains the modification commands required for the current image and can be directly applied to the edited version of the image to backtrack to the original image. Through this kind of training, KNN-Diffusion can accurately locate the target area to be edited using the CLIP embeddings. During inference, the user’s input editing command text can be converted into CLIP embeddings as input to the model, with the edited version of the image and the local area CLIP embeddings serving as input conditions for the model to complete the editing operation.
the nearest neighbor after alignment. The model then takes the edited version of the image along with the CLIP embeddings of the local area from the original image as joint inputs. This CLIP embedding contains the modification commands required for the current image and can be directly applied to the edited version of the image to backtrack to the original image. Through this kind of training, KNN-Diffusion can accurately locate the target area to be edited using the CLIP embeddings. During inference, the user’s input editing command text can be converted into CLIP embeddings as input to the model, with the edited version of the image and the local area CLIP embeddings serving as input conditions for the model to complete the editing operation.
3.Experimental Results
The experimental section of this paper was conducted on multiple databases including MS-COCO, LN-COCO, CUB, and Public Multimodal Dataset (PMD). The first three datasets were used for ordinary qualitative and quantitative comparisons, while the PMD dataset was used for photo-realistic experiments. To demonstrate the advantages of the method proposed in this paper, the author first applied KNN-Diffusion to other two diffusion backbones to showcase the model’s handling of out-of-distribution images. The table below displays the experimental results of this method under zero-shot settings on three different datasets.
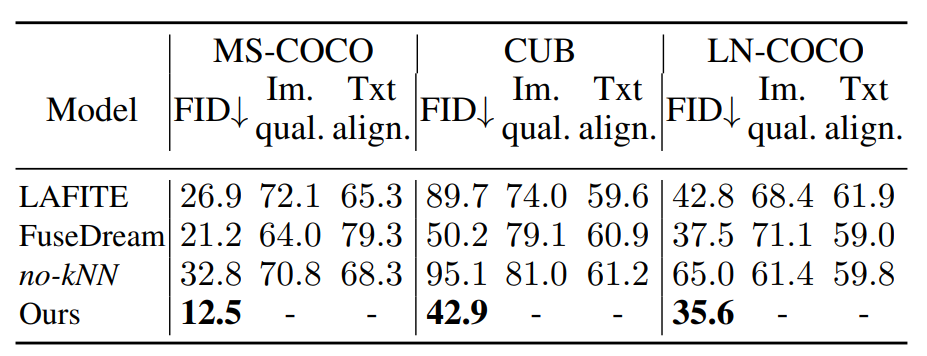
It can be seen that KNN-Diffusion achieved the lowest FID score in all experimental scenarios, while the other two comparative methods were LAFITE and FuseDream. To further demonstrate the advantages of using retrieval methods in text-to-image generation tasks, the author also trained a model variant called no-kNN, which was trained only on image embeddings (omitting kNN index embeddings), while during inference, the images were generated using text embeddings. It can be observed that in the absence of retrieval guidance, the model’s performance significantly declines.
In the following figure, the author illustrates the qualitative generation comparisons of this method with others, where the first row of images is the closest real images selected from the PMD dataset to the input text. It can be observed that the generation results of KNN-Diffusion are more realistic and better preserve the identity content information of the real images.

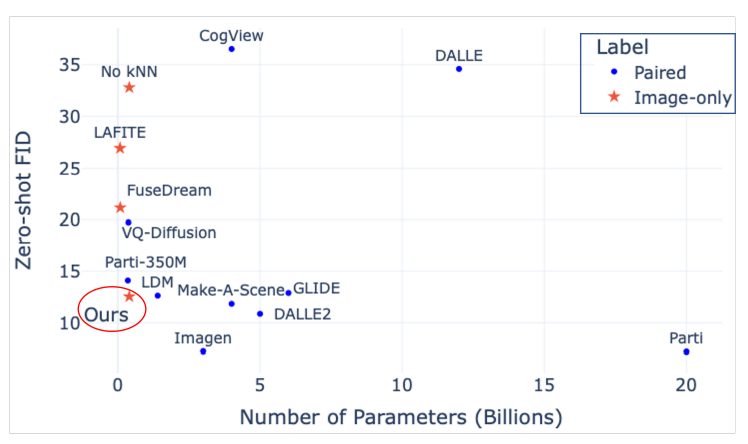
To further prove the effectiveness of this method, the author compares this model with nine currently popular text-image generation diffusion models, including DALL·E, CogView, VQ-Diffusion, GLIDE, Latent Diffusion (LDM), Make-A-Scene, DALL·E2, Parti, and Imagen. The experimental results are shown in the following figure, where the horizontal axis represents the parameter count of each model and the vertical axis represents the FID metrics of that model on the current experimental dataset. It can be seen that although KNN-Diffusion was trained on a dataset lacking text data, its computational cost is significantly lower than that of models trained using full text-image pairs (e.g., LDM, GLIDE). This indicates that utilizing external retrieval databases allows the method proposed in this paper to balance performance and model efficiency, especially in reducing the number of parameters in the model.
4.Conclusion
At the end of the paper, the author pays tribute to the Scottish philosopher David Hume, who proposed in 1748 that “We shall always find that every thought we have is a copy of similar impressions in our minds.” This can also be seen as the core inspiration for the method proposed in this paper. In this paper, the author suggests using large-scale retrieval methods to train a new text-to-image model without any textual data. The author demonstrates through extensive experiments that using external knowledge bases can alleviate the difficulty of the model learning new concepts, resulting in a relatively small and efficient model. Additionally, it provides the model with the capability to learn to adapt to new samples. Finally, the author proposes a new technique, utilizing retrieval methods for text-driven semantic operations without user-provided masks, which also has certain inspirations for the field of text-image editing. It is hoped that the introduction of KNN-Diffusion can inspire the community to pay more attention to how to quickly reduce the cost of using diffusion models and realize more practical applications.
References
The author: seven_
Illustration by Iconscout Store from IconScout
The author: seven_

Scan to watch!
New this week!
