
Finally, Kimi has been updated! I’ve been looking forward to this.
It is said to be in grayscale:  but my interface still looks like this. Let’s wait a bit and try later~
but my interface still looks like this. Let’s wait a bit and try later~ 
Let’s read the paper together and see what technical details have changed.
Address: https://github.com/MoonshotAI/Kimi-k1.5/blob/main/Kimi_k1.5.pdf
The pre-training methods of large language models (LLMs) have proven effective in scaling computation, but are limited by the amount of available training data.
Reinforcement learning (RL) provides a new direction for the continuous improvement of AI, allowing LLMs to explore more data through reward mechanisms, but previous research results have not been ideal.
The Kimi k1.5 team has taken a different approach, proposing a concise and effective RL framework that does not rely on complex techniques such as Monte Carlo tree search, value functions, and process reward models.
Through long text context expansion and improved policy optimization methods, Kimi k1.5 has achieved reasoning performance comparable to OpenAI’s o1 in multiple benchmark tests, 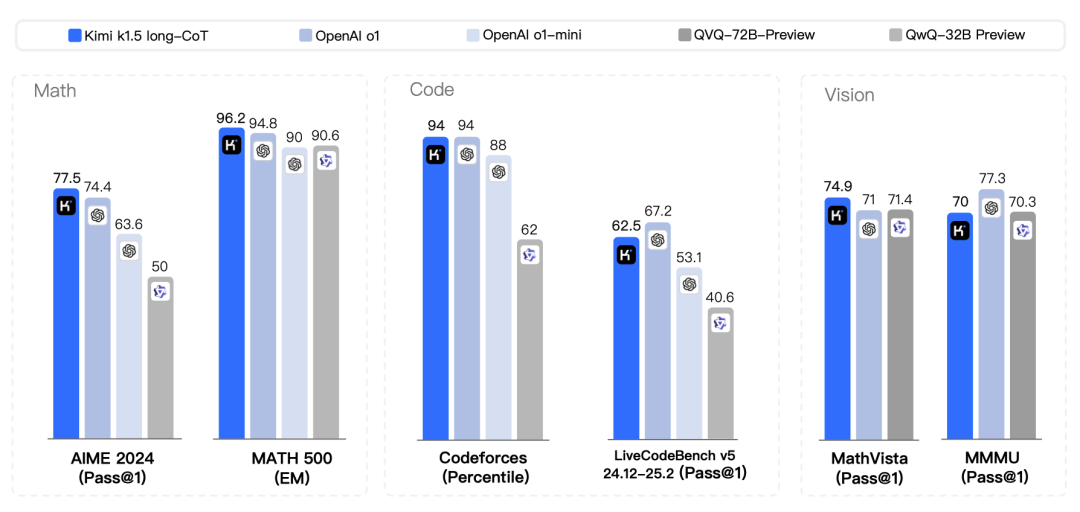 and has improved the performance of short text reasoning models by up to 550% through the ‘long-to-short’ method.
and has improved the performance of short text reasoning models by up to 550% through the ‘long-to-short’ method. 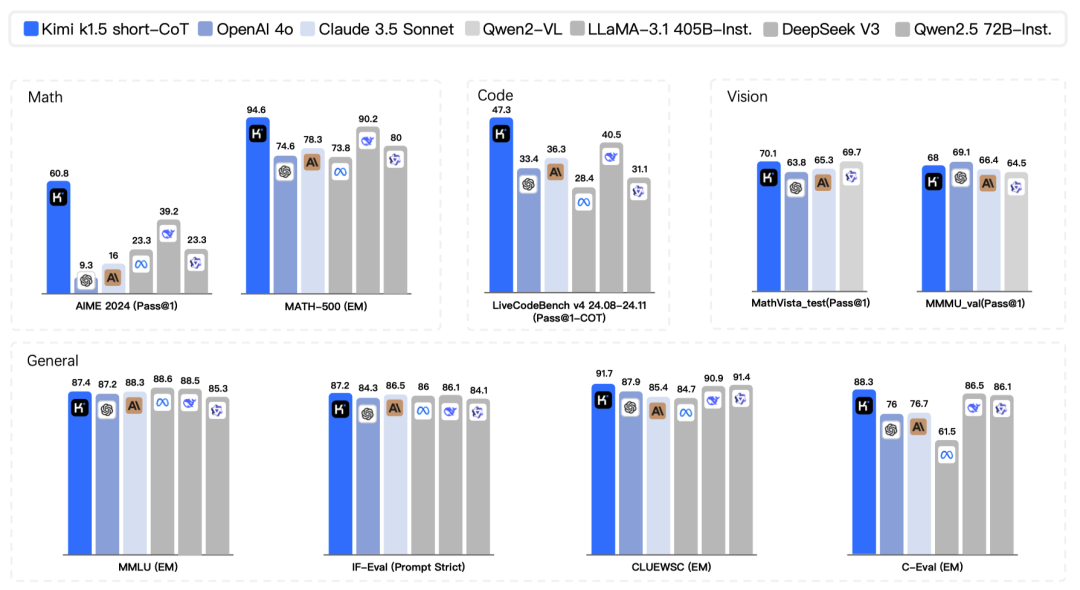
Method Details
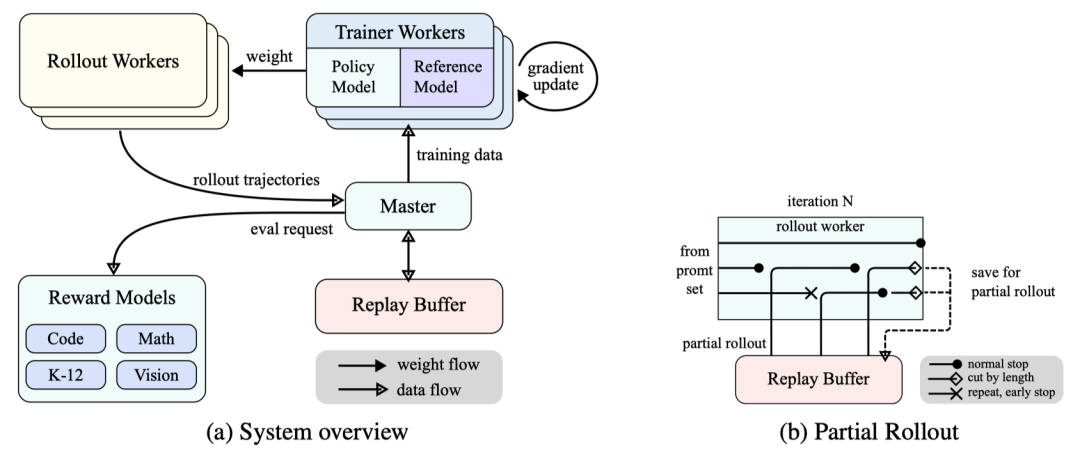
Long Context Expansion
Kimi k1.5 expands the context window of reinforcement learning to 128k, finding that as the context length increases, performance continues to improve. The team adopted partial trajectory replay technology to generate new trajectories by reusing large chunks of previous trajectories, avoiding the cost of generating new trajectories from scratch, effectively improving training efficiency. This long context expansion allows the model to better plan, reflect, and correct its reasoning process, as if equipping the model with ‘far-sighted vision’, enabling it to see a further ‘future’ and make more reasonable decisions.
Improved Policy Optimization
The team proposed a variant algorithm based on online mirror descent for robust policy optimization. This algorithm further enhances performance through effective sampling strategies, length penalties, and data recipe optimization. In simple terms, it makes the model ‘smarter’ during training, knowing which areas need to be focused on and which areas can be ‘lazy’, while avoiding generating overly lengthy reasoning processes, thus improving the model’s efficiency and accuracy.
Multimodal Training
Kimi k1.5 is a multimodal model capable of processing both text and visual data simultaneously. This multimodal training approach allows the model to consider various information when addressing problems. For instance, when answering a math question that includes a chart, the model can not only understand the textual description but also ‘comprehend’ the chart, thereby providing a more accurate answer. 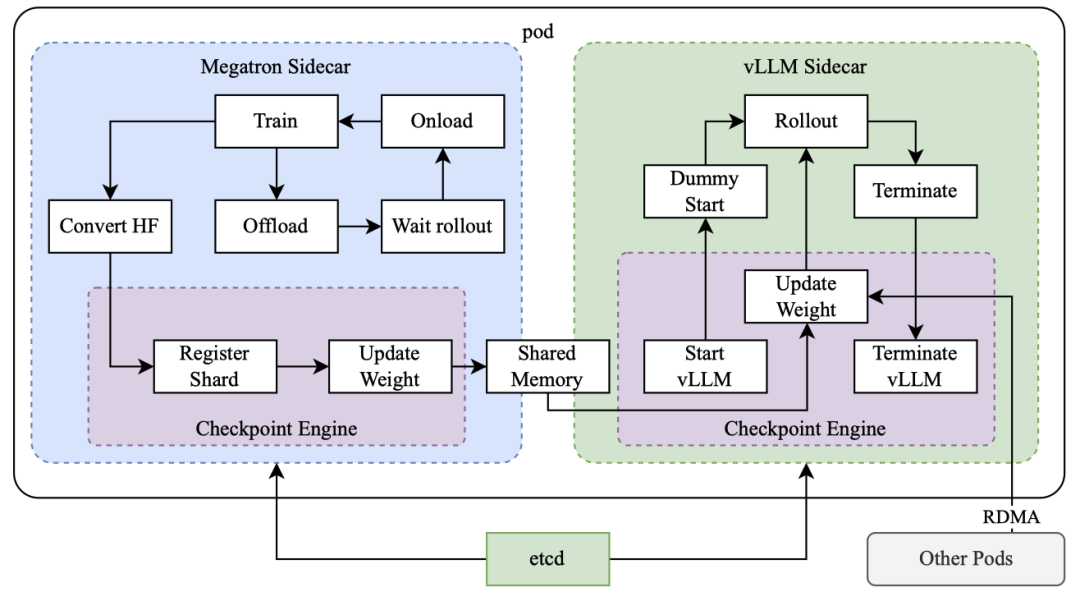
Experimental Results
Long Text Reasoning Performance
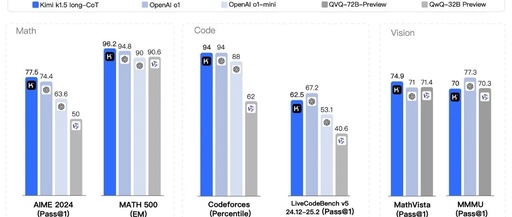
The long text reasoning version of Kimi k1.5 has performed excellently in multiple benchmark tests, achieving a pass rate of 77.5 in AIME 2024, an accuracy rate of 96.2 in MATH 500, and reaching the 94th percentile in Codeforces, comparable to OpenAI’s o1, and even surpassing existing models on certain tasks. This indicates that Kimi k1.5 has reached a top level in handling complex reasoning tasks. 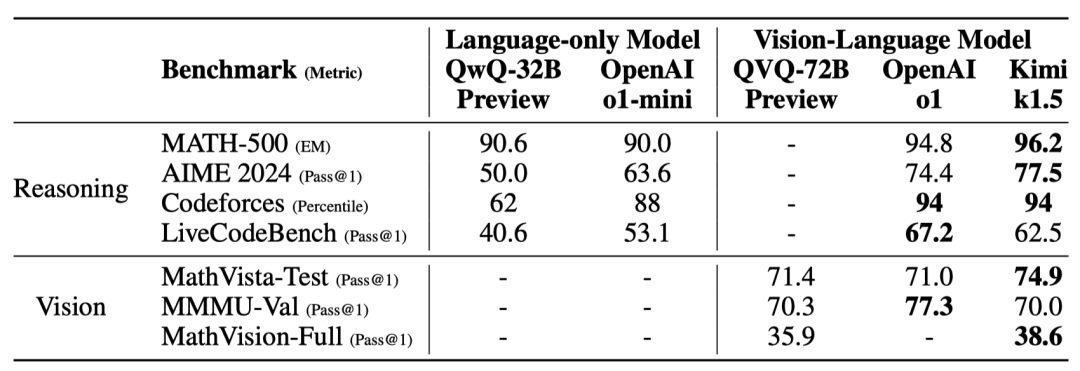
Short Text Reasoning Performance
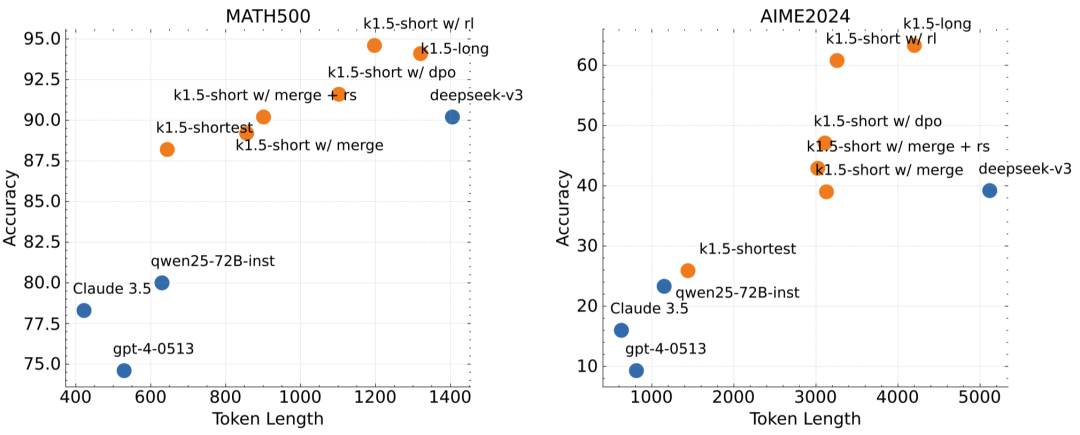 Through the ‘long-to-short’ method, the short text reasoning version of Kimi k1.5 has also achieved significant performance improvements. For example, it reached a pass rate of 60.8 in AIME 2024, an accuracy rate of 94.6 in MATH 500, and a pass rate of 47.3 in LiveCodeBench, significantly outpacing existing short text reasoning models like GPT-4o and Claude Sonnet 3.5. This demonstrates that Kimi k1.5 not only excels in long text reasoning but can also convert this advantage into short text reasoning capabilities, allowing the model to perform strongly in various scenarios.
Through the ‘long-to-short’ method, the short text reasoning version of Kimi k1.5 has also achieved significant performance improvements. For example, it reached a pass rate of 60.8 in AIME 2024, an accuracy rate of 94.6 in MATH 500, and a pass rate of 47.3 in LiveCodeBench, significantly outpacing existing short text reasoning models like GPT-4o and Claude Sonnet 3.5. This demonstrates that Kimi k1.5 not only excels in long text reasoning but can also convert this advantage into short text reasoning capabilities, allowing the model to perform strongly in various scenarios. 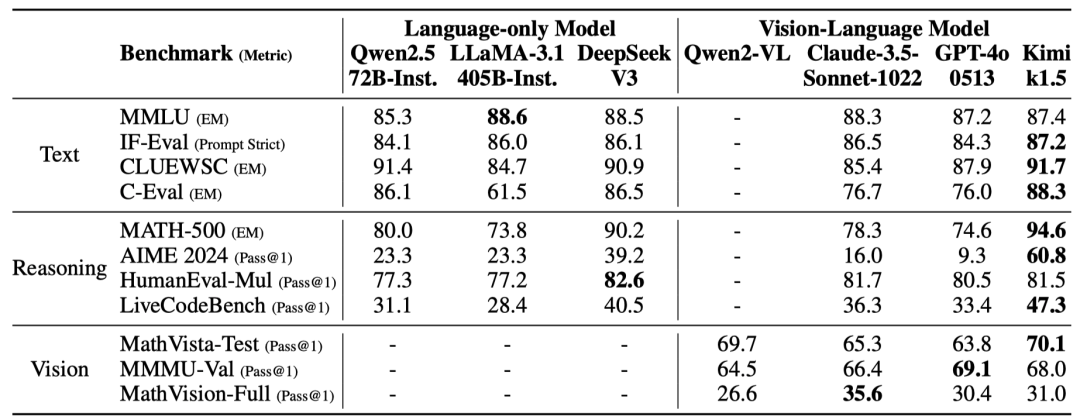
Conclusion
Kimi k1.5 achieves efficient training under a reinforcement learning framework through long context expansion and improved policy optimization methods, and has attained performance in multimodal reasoning tasks that is comparable to or even superior to OpenAI’s o1. In the future, the team will continue to explore how to further enhance the efficiency and scalability of long context reinforcement learning training, while investigating how to better convert long text reasoning capabilities into short text reasoning abilities, enabling the model to perform strongly in more scenarios.
Definitely going to try it soon~ Hehe~
Note:Nickname-School/Company-Direction/Conference (e.g., ACL), enter the technical/submission group

ID: DLNLPer, remember to note it