
MLNLP ( Machine Learning Algorithms and Natural Language Processing ) community is a well-known natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university professors, and industry researchers.
The vision of the community is to promote communication between the academic and industrial circles of natural language processing and machine learning, especially for the progress of beginners.
Reprinted from | Quantum Bits
Tom Goldstein, an associate professor at the University of Maryland, recently published a tweet that stirred up quite a discussion.
Even big names in the tech industry have come to pay attention:

The key term “pointing at” in the discussion is Diffusion Model, which Tom describes as:
In 2021, it could even be said to be unheard of.
However, this algorithm is not unfamiliar, as it is the core of the AI art generator DALL·E.
Moreover, the authors of DALL·E had “no interest” in GAN from the start and directly abandoned it.
Coincidentally, the same topic has sparked considerable discussion domestically:
So why is there a wave of “new waves pushing out the old waves” in the field of image generation?
Let’s explore this.
1
『What is the Diffusion Model?』
1
『What is the Diffusion Model?』
The Diffusion Model has come into the spotlight, thanks to the popularity of various “AI one-sentence image generation” tools.
For example, OpenAI’s DALL·E 2:

Google’s Imagen:

It is not difficult to see that these recently popular image generation tools, whether in terms of realism or imagination and understanding ability, meet human expectations quite well.
Thus, they have become the “new favorites” for netizens (just as GAN was back in the day).
The key behind such capabilities is the Diffusion Model.
Its research can be traced back to 2015 when researchers from Stanford and Berkeley published a paper titled Deep Unsupervised Learning using Nonequilibrium Thermodynamics:

However, this research is very different from the current Diffusion Model; the research that truly made it effective was in 2020, a study titled Denoising Diffusion Probabilistic Models:

Let’s first take a look at the comparison between various generative models:

It is clear that the Diffusion Model differs from other models in that its latent code (z) is the same size as the original image.
To simply summarize the Diffusion Model, there exists a series of Gaussian noise (T rounds) that transforms the input image x0 into pure Gaussian noise xT.
Breaking it down further, the Diffusion Model first includes a forward process (Forward diffusion process).
The purpose of this process is to add noise to the image; however, image generation cannot be achieved at this step.
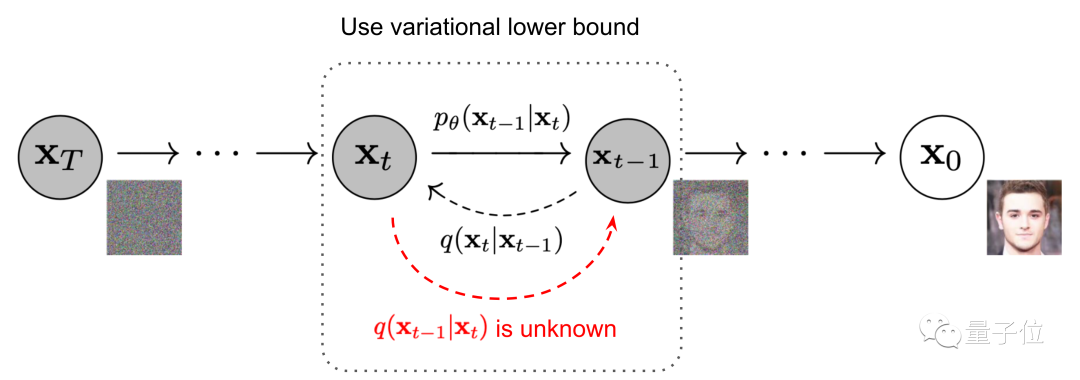
Next is a reverse process (Reverse diffusion process), which can be understood as the denoising inference process of Diffusion.
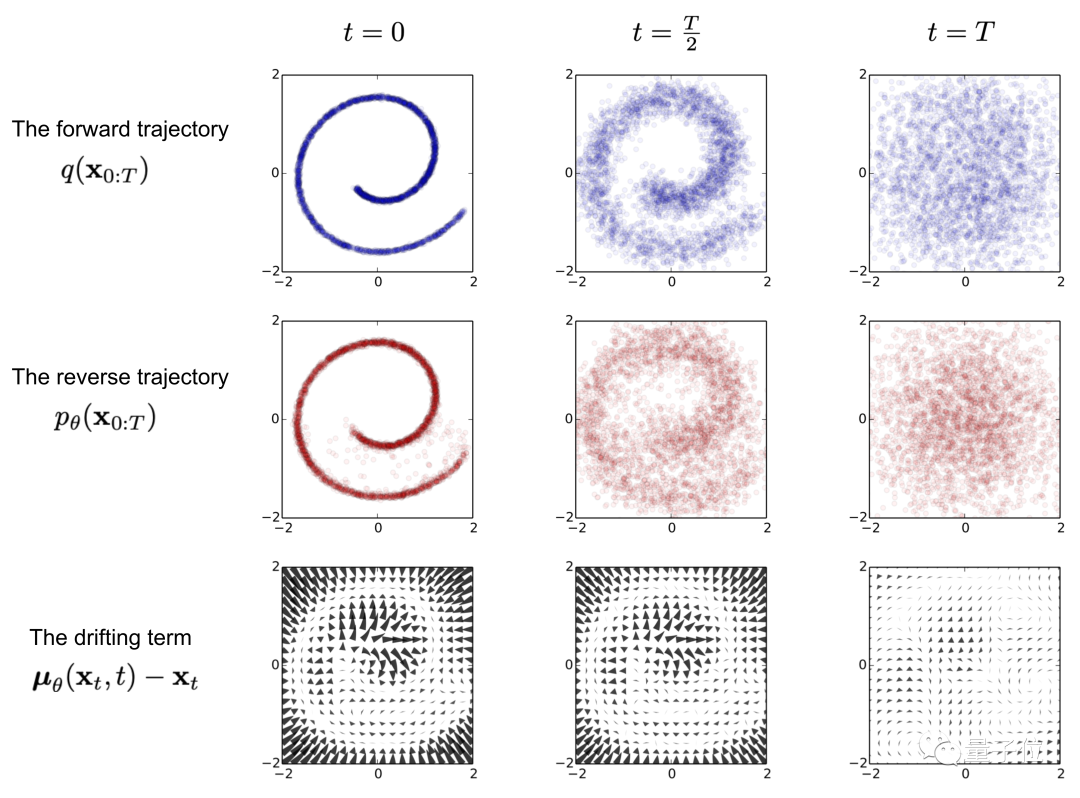
Finally, during the training phase, the goal is to maximize the log likelihood of the model’s predicted distribution under the real data distribution.
The above processes are based on the DDPM research.
However, Zhihu user “I want to sing high C” (TSAIL PhD) believes:
When DDPM was proposed, researchers in the field did not fully understand the mathematical principles behind this model, so the description in the article did not explore the more essential mathematical principles.
In his view, it was not until Stanford University’s Yang Song et al. revealed the mathematical background corresponding to the continuous version of the diffusion model in Score-Based Generative Modeling through Stochastic Differential Equations.
They unified the denoising score matching method in statistical machine learning with the denoising training in DDPM.

More detailed processes can be referenced in the paper details linked at the end.
Next, we need to discuss a question:
2
『Why is GAN Being Replaced So Quickly?』
2
『Why is GAN Being Replaced So Quickly?』
According to a paper from OpenAI, the image quality generated by the Diffusion Model is significantly superior to that of the GAN model.
DALL·E is a multimodal pre-trained large model, and the terms “multimodal” and “large” indicate that the dataset used to train this model is very large and complex.
Professor Tom Goldstein, who posted this tweet, mentioned that a challenge in the GAN model training process is determining the optimal weights of numerous saddle points in the loss functions, which is actually a quite complex mathematical problem.
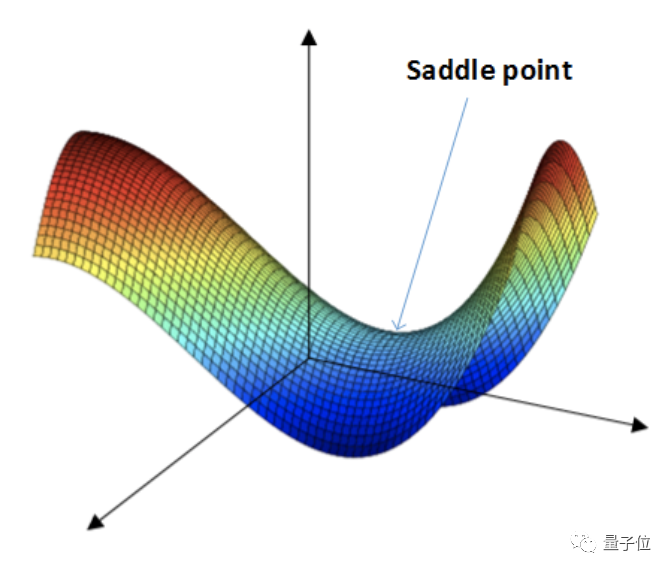
In the training process of multi-layer deep learning models, feedback must be provided multiple times until the model converges.
However, in practice, it is found that the loss function often cannot reliably converge to the saddle point, leading to poor model stability. Even though some researchers have proposed techniques to enhance the stability of the saddle point, it is still insufficient to solve this problem.
Especially when facing more complex and diverse data, handling saddle points becomes increasingly difficult.
Unlike GAN, DALL·E uses the Diffusion Model, which does not have to get entangled in saddle point issues, but only needs to minimize a standard convex cross-entropy loss, and it is already known how to stabilize it.
This greatly simplifies the difficulty of data processing in the model training process. In other words, it uses a new mathematical paradigm to overcome an obstacle from a novel perspective.
Additionally, during the training process of the GAN model, besides needing a “generator” to map the sampled Gaussian noise to the data distribution; it also requires an additional training discriminator, which complicates the training process.
In contrast, the Diffusion Model only needs to train the “generator”, the objective function is simple, and there is no need to train other networks (discriminator, posterior distribution, etc.), which instantly simplifies a lot of things.
Current training technologies allow the Diffusion Model to directly bypass the stage of tuning models in the GAN field and can be used directly for downstream tasks.
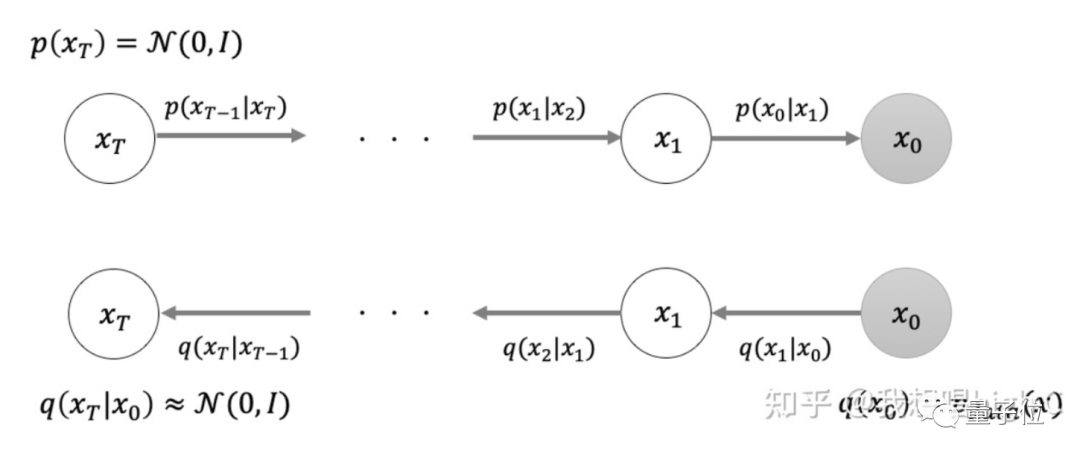
△Diffusion Model Intuitive Diagram
From a theoretical perspective, the success of the Diffusion Model lies in the fact that the trained model only needs to “imitate” the simple forward process corresponding to the reverse process, rather than “black box” searching for the model like other models.
Moreover, every small step of this reverse process is very simple, only needing to fit with a simple Gaussian distribution (q(x(t-1)| xt)).
This brings many conveniences for the optimization of the Diffusion Model, which is also one of the reasons for its excellent empirical performance.
3
『Is the Diffusion Model Perfect?』
3
『Is the Diffusion Model Perfect?』
Not necessarily.
From a trend perspective, the Diffusion Model field is indeed flourishing, but as “I want to sing high C” stated:
There are still some core theoretical issues in this field that need to be researched, which provides a very valuable research topic for those of us in theory. > Moreover, even for those not interested in theoretical research, since this model is already working well, its combination with downstream tasks has only just begun, and there are many places where one can quickly stake a claim.
I believe that the accelerated sampling of the Diffusion Model will definitely be resolved in the near future, allowing the Diffusion Model to dominate deep generative models.
Regarding the effectiveness of the Diffusion Model and its rapid replacement of GAN, Professor Ma Yi believes it fully illustrates a principle:
A few simple correct mathematical deductions can be much more effective than nearly a decade of large-scale parameter tuning and network structure debugging.
However, for the current enthusiasm of “new waves pushing out the old waves”, Professor Ma Yi also has a different viewpoint:
I hope young researchers correct their research purposes and attitudes, and do not be misled by the currently popular things.
Including the Diffusion Process, this is actually an idea that is hundreds of years old; it is just an old tree sprouting new buds, finding new applications.
“I want to sing high C” Zhihu answer:
https://www.zhihu.com/question/536012286/answer/2533146567
Reference links:
[1]https://twitter.com/tomgoldsteincs/status/1560334207578161152?s=21&t=QE8OFIwufZSTNi5bQhs0hQ[2]https://www.zhihu.com/question/536012286[3]https://arxiv.org/pdf/2105.05233.pdf[4]https://arxiv.org/abs/1503.03585[5]https://arxiv.org/abs/2006.11239[6]https://arxiv.org/abs/2011.13456[7]https://weibo.com/u/3235040884?topnav=1&wvr=6&topsug=1&is_all=1

Scan the QR code to add the assistant on WeChat
About Us
