



1. Concept of Speech Recognition
Speech recognition technology, also known as Automatic Speech Recognition (ASR), aims to convert the vocabulary content of human speech into computer-readable input, such as keystrokes, binary codes, or character sequences. In simple terms, speech recognition technology allows intelligent devices to understand human speech. It is a science that involves multiple disciplines, including digital signal processing, artificial intelligence, linguistics, mathematical statistics, acoustics, affective computing, and psychology. This technology can provide applications such as automated customer service, automatic speech translation, command control, and voice verification codes. In recent years, with the rise of artificial intelligence, speech recognition technology has made significant breakthroughs in both theory and application, moving from the laboratory to the market and gradually entering our daily lives. Today, speech recognition is used in many fields, mainly including speech recognition dictation, voice paging and Q&A platforms, autonomous advertising platforms, and intelligent customer service.

2. Principles of Speech Recognition
The essence of speech recognition is a type of pattern recognition based on speech feature parameters, which means that through learning, the system can classify the input speech according to certain patterns and then find the best matching result based on decision criteria. Currently, pattern matching principles have been applied in most speech recognition systems.
General pattern recognition includes basic modules such as preprocessing, feature extraction, and pattern matching. During actual recognition, the test speech is processed to generate templates based on the training process, and finally, recognition is performed according to distortion judgment criteria.
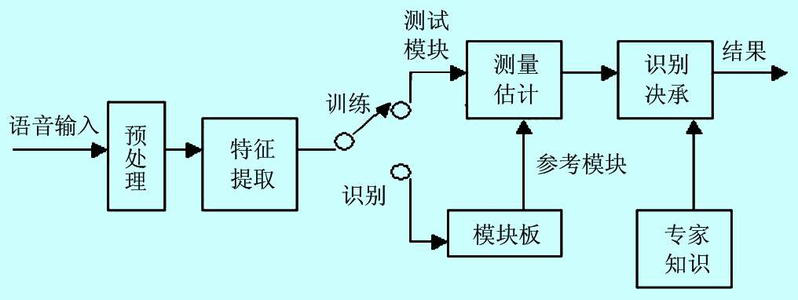
3. Overview of Speech Recognition Technology
From the development of speech recognition algorithms, speech recognition technology can be divided into three major categories: the first category is model matching methods, including vector quantization (VQ) and dynamic time warping (DTW); the second category is probabilistic statistical methods, including Gaussian mixture models (GMM) and hidden Markov models (HMM); the third category is discriminative classification methods, such as support vector machines (SVM), artificial neural networks (ANN), and deep neural networks (DNN), as well as various combination methods. Below is a brief introduction to the mainstream recognition technologies:
1. Dynamic Time Warping (DTW)
In speech recognition, due to the randomness of speech signals, even if the same person utters the same sound, as long as the speaking environment and emotions are different, the duration may also vary. Therefore, time warping is essential. DTW is a nonlinear warping technique that organically combines time warping with distance measurement. In speech recognition, it is necessary to compare the test template with the reference template and perform actual comparison and nonlinear stretching, selecting the template with the smallest distance as the recognition result output based on a certain distance measurement.
2. Support Vector Machine (SVM)
Support vector machines are a classification method based on VC dimension theory and structural risk minimization theory. It seeks the best compromise between model complexity and learning ability based on limited sample information. Theoretically, SVM is a simple optimization process that resolves the local extremum problem in neural network algorithms and obtains a global optimal solution. SVM has been successfully applied to speech recognition and has demonstrated good recognition performance.
3. Vector Quantization (VQ)
Vector quantization is an important signal compression technique widely used in speech and image compression coding, with its ideas stemming from Shannon’s rate-distortion theory. Its basic principle is to perform overall quantization of each frame of feature vector parameters in a multi-dimensional space, compressing the data with minimal information loss, and is generally applied to isolated word speech recognition systems with small vocabulary.
4. Hidden Markov Model (HMM)
The hidden Markov model is a statistical model currently widely used in the field of speech signal processing. In this model, whether a state in the Markov chain transitions to another state depends on the state transition probability, while the observation value generated by a certain state depends on the state generation probability.
5. Gaussian Mixture Model (GMM)
The Gaussian mixture model is an extension of a single Gaussian probability density function. GMM can smoothly approximate any shape of density distribution. There are two types of Gaussian mixture models: single Gaussian model (SGM) and Gaussian mixture model (GMM). Currently, in the field of speech recognition, GMM needs to be constructed together with HMM to form a complete speech recognition system.
6. Artificial Neural Network (ANN/BP)
Artificial neural networks were proposed in the late 1980s and are essentially adaptive nonlinear dynamic systems based on biological neural systems. They aim to simulate the way the nervous system performs tasks. Similar to the human brain, neural networks consist of interconnected neurons that influence each other’s behavior, also referred to as nodes or processing units. Neural networks mimic human neuronal activity through numerous nodes and connect all nodes into an information processing system to reflect the basic characteristics of brain function.
7. Deep Neural Network/Deep Belief Network – Hidden Markov (DNN/DBN-HMM)
Currently, most classification learning methods, such as ANN and BP, are shallow structure algorithms and have limitations compared to deep algorithms. Especially when sample data is limited, their ability to represent complex functions is significantly insufficient. Deep learning can achieve complex function approximation through learning deep nonlinear network structures, representing input data distributions, and demonstrating powerful capabilities to learn essential features from small sample sets.

