







Speech Recognition


AI Science Popularization ⑥
Speech recognition technology has become a common technology. In daily life, features such as the Siri voice assistant in Apple products, the “voice-to-text” function in WeChat, smart speakers, and smart home voice assistants all rely on speech recognition. In this issue, we will explore the concept and working principle of speech recognition.

01
What is Speech Recognition?
Speech recognition technology is the key technology that helps machines “understand” human natural language, allowing machines to convert speech signals into corresponding text or commands through recognition and understanding. Essentially, it is a form of pattern recognition that matches the best recognition result by comparing unknown speech with known speech.

02
Working Principle of Speech Recognition
How does a machine “understand” human natural language? Before introducing the working principle of speech recognition, we need to understand several core concepts involved.
(1) Core Concepts
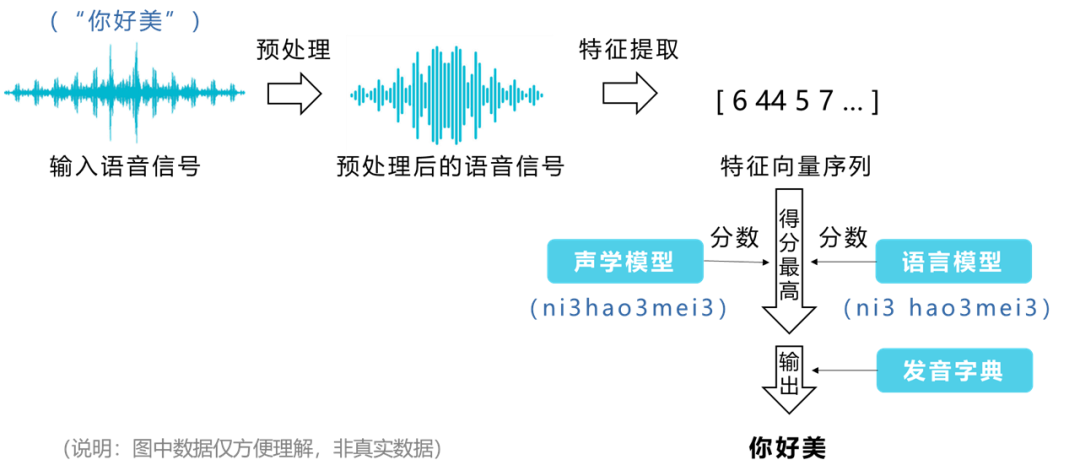
1. Preprocessing: This occurs before analyzing and processing speech signals, including pre-emphasis, framing, etc., aimed at filtering out noise and converting complex, irregular speech signals into digital information that can be recognized by computers, thereby improving the efficiency and success rate of speech recognition.
2. Feature Extraction: This involves extracting effective acoustic features from short-term speech frames, which can represent the essence of the speech, thus forming a related sequence of feature vectors.
3. Acoustic Model: This is used to calculate the distance between the sequence of speech feature vectors and each pronunciation template, to find the pronunciation that best matches the speech feature vector sequence. It converts the feature vector sequence into corresponding pronunciations.
4. Language Model: This is used to predict the probability of character (word) sequences, determining whether a language sequence is a normal statement. For example, the phrase “你|好美” is more in line with our language habits than “你好|美”, thus the former has a higher probability of being judged as a normal statement.
5. Pronunciation Dictionary: This contains the mapping between words and phonemes, used to connect the acoustic model and the language model. In simple terms, it is the correspondence between pinyin and Chinese characters, such as “hǎo” corresponding to “好” or “郝”. In practical speech recognition, the choice of which character to correspond to is based on the probabilities calculated by the language model, generally, “好” is more likely to be the recognition result than “郝”.
(2) Working Principle
After understanding the core concepts, let’s look at the main steps to achieve speech recognition:
1. Input the speech signal that needs to be recognized.
2. Preprocess and extract features from the speech signal to obtain the corresponding sequence of feature vectors and several hypothesized word sequences.
3. Calculate the acoustic model scores and language model scores for each, where higher scores indicate higher similarity and greater likelihood.
4. Take the word sequence with the highest overall score as the recognition result, outputting it in conjunction with the pronunciation dictionary.
[Textbook Express]
[References]
[1] Wang Tong, Ma Yanzhou, Yi Mianzhuz. DTW-based Speech Recognition for Short Russian Commands [J]. Journal of Shandong University (Natural Science Edition), 2017, 52(11): 29-36.
[2] Ma Han, Tang Roubing, Zhang Yi, Zhang Qiaoling. Overview of Speech Recognition Research [J]. Computer Systems Applications, 2022, 31(01): 1-10.
[3] Fu Xuetong. Preprocessing Process of Speech Recognition and Its Existing Problems [J]. Science and Technology Communication, 2019, 11(08): 135-136.
[4] Ren Huiyang. Design of NAO Robot Behavior Control System [D]. Jinan University, 2016.
Provided by|Resource Service Department
Edited by|Library Promotion Team
Reviewed by | Leader of Library Promotion Team
