Selected from Hackernoon
Author: Debarko De
Translated by Machine Heart
Contributors:Li Shimeng, Lu
This article briefly introduces what recurrent neural networks are and their operating principles, and provides an example implementation of an RNN.
What are recurrent neural networks (RNNs)? How do they work? Where can they be used? This article attempts to answer these questions and also shows a demo of an RNN implementation that you can expand upon as needed.
Architecture of Recurrent Neural Networks
Basic knowledge such as Python and CNN is essential. Understanding CNNs is necessary for comparison with RNNs: why and in what ways RNNs are better than CNNs.
Let’s start with the term “recurrent”. Why is it called recurrent? Recurrent means:
Occurring frequently or repeatedly
These types of neural networks are called recurrent neural networks because they perform the same operation repeatedly on a set of sequential inputs. The subsequent parts of this article will discuss the significance of this operation.
Why do we need RNNs?
Perhaps you are thinking that there are already networks like convolutional networks that perform very well; why do we need other types of networks? There is a specific case where RNNs are needed. To explain RNNs, you first need to understand sequences, so let’s talk about sequences first.
Sequences are interdependent (finite or infinite) streams of data, such as time series data, informative strings, conversations, etc. In a conversation, a sentence may have one meaning, but the overall conversation may convey a completely different meaning. Time series data like stock market data is similar; individual data points represent current prices, but the data throughout the day will show different changes, prompting us to make buy or sell decisions.
When input data has dependencies and follows a sequential pattern, CNNs generally do not perform well. There is no relationship between the previous input and the next input in CNNs. Thus, all outputs are independent. CNNs take input and output based on a trained model. If you run 100 different inputs, none of the outputs will be influenced by previous outputs. But think about text generation or translation: all generated words are independent of previously generated words (in some cases, they are also independent of subsequent words, which we won’t discuss here). Therefore, you need some bias based on previous outputs. This is where RNNs come in. RNNs have a certain memory of what has happened in the data sequence. This helps the system capture context. Theoretically, RNNs have infinite memory, meaning they have the ability to recall infinitely. Through recall, they can understand all previous inputs. But in practice, they can only recall the last few steps.
This article is only meant to relate to humans broadly and will not make any decisions. It is simply based on prior knowledge about the project (I have not even understood 0.1% of the human brain).
When to use RNNs?
RNNs can be used in many different areas. Below are the fields where RNNs are most commonly applied.
1. Language Modeling and Text Generation
Given a sequence of words, try to predict the likelihood of the next word. This is very useful in translation tasks, as the most likely sentence will be composed of the words with the highest probabilities.
2. Machine Translation
Translating text content from one language to another uses one or several forms of RNNs. All practical systems used daily employ some advanced version of RNNs.
3. Speech Recognition
Predicting speech segments based on input sound waves to determine words.
4. Generating Image Descriptions
A very broad application of RNNs is understanding what happens in images to make reasonable descriptions. This is the role of combining CNNs and RNNs. CNNs perform image segmentation, while RNNs reconstruct descriptions from the segmented data. Although this application is basic, the possibilities are endless.
5. Video Tagging
Videos can be tagged frame by frame for video search.
Diving Deeper
This article is structured around the following topics. Each section builds on the previous one, so do not skip around.
-
Feedforward Networks
-
Recurrent Networks
-
Recurrent Neurons
-
Backpropagation Through Time (BPTT)
-
RNN Implementation
Introduction to Feedforward Networks
Feedforward networks pass information through a series of operations performed at each node in the network. Feedforward networks pass information directly backward through each layer each time. This is different from other recurrent neural networks. Generally, feedforward networks accept an input and produce an output based on that, which is also the step of most supervised learning, where the output might be a classification result. Its behavior is similar to that of CNNs. The output could be categories labeled as cats, dogs, etc.
Feedforward networks are trained based on a series of pre-labeled data. The goal during the training phase is to minimize the error when the feedforward network guesses the category. Once training is complete, we can classify new batches of data using the trained weights.
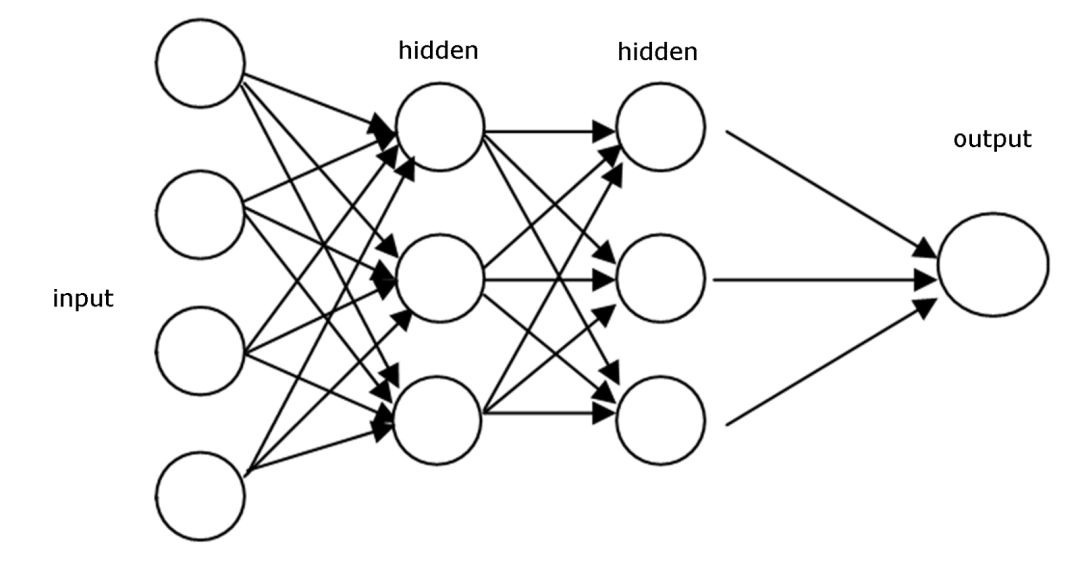
A typical architecture of a feedforward network
Another thing to note is that in feedforward networks, regardless of what image is presented to the classifier during the testing phase, the weights will not change, so it will not affect the second decision. This is a significant difference between feedforward networks and recurrent networks.
Unlike recurrent networks, feedforward networks do not remember previous input data during testing. They are always dependent on the time point. They only remember historical input data during the training phase.
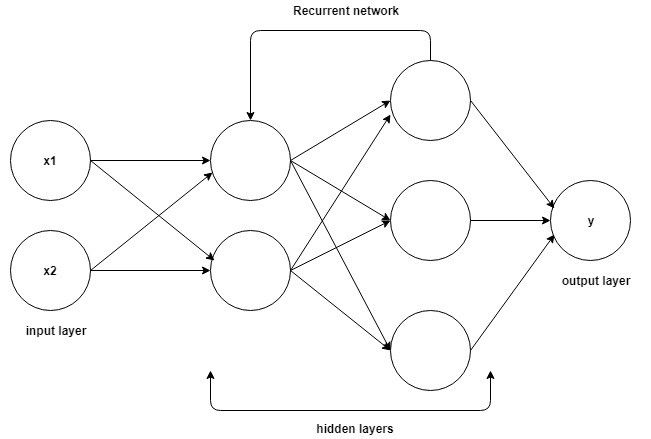
Recurrent Networks
That is to say, recurrent networks not only take the current input sample as network input but also include what they have perceived before as input.
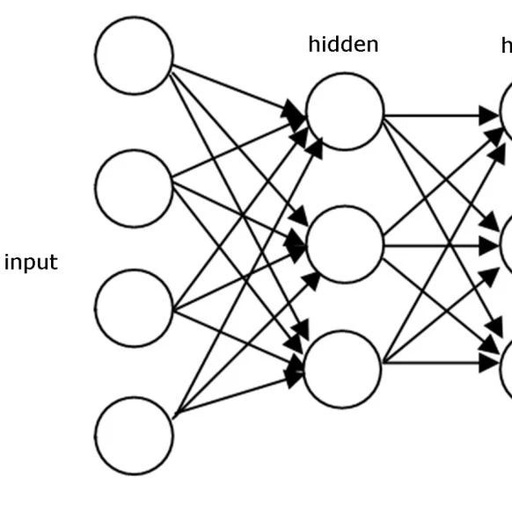
We attempted to build a multilayer perceptron. From a simple perspective, it has an input layer, a hidden layer with a specific activation function, and finally produces an output.
Example architecture of a multilayer perceptron
If the number of layers in the above example increases, the input layer also receives input. Then the first hidden layer will pass the activation to the next hidden layer, and so on. Finally, it reaches the output layer. Each hidden layer has its own weights and biases. Now the question becomes, can we input to the hidden layers?
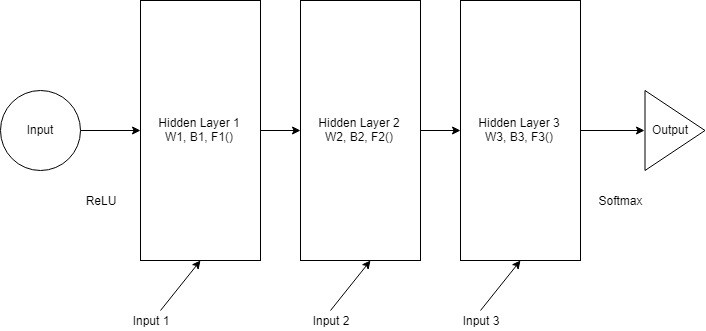
Each layer has its own weights (W), biases (B), and activation functions (F). The behavior of these layers differs, and merging them is technically challenging. To merge them, we replace the weights and biases of all layers with the same values. As shown in the figure below:
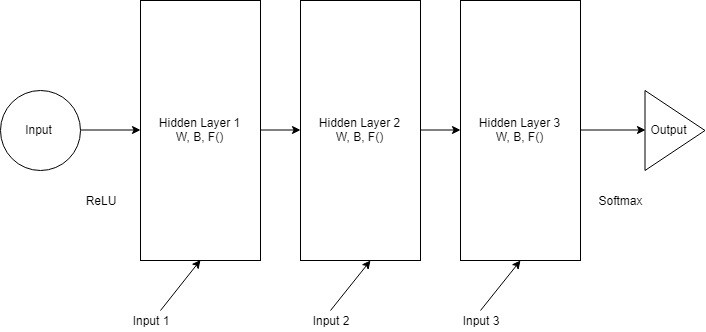
Now we can combine all layers together. All hidden layers can be combined into a recurrent layer. So it looks like the figure below:
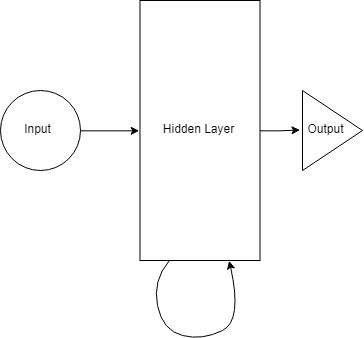
We provide input to the hidden layer at every step. Now a recurrent neuron stores all previous inputs and combines this information with the current step’s input. Thus, it also captures some correlation information between the current data step and previous steps. The decision at step t-1 affects the decision made at step t. This is very similar to how humans make decisions in life. We combine current data with recent data to help solve the specific problem at hand. This example is simple, but in principle, it is consistent with human decision-making ability. It makes me very curious whether we, as humans, are truly intelligent, or if we have very advanced neural network models. The decisions we make are just training on the data collected in life. So once we have advanced models and systems that can store and compute data within a reasonable time frame, can we digitize the brain? So what happens when we have models that are better and faster than the brain (trained on data from millions of people)?
An interesting perspective from another article (https://deeplearning4j.org/lstm.html): Humans are always troubled by their own behavior.
We use an example to illustrate the explanation above, which is predicting the next letter after a series of letters. Imagine a word with 8 letters: namaskar.
namaskar (合十礼): A traditional Indian greeting or gesture of respect, placing palms together in front of or at the chest.
If we try to find out the 8th letter after inputting 7 letters into the network, what will happen? The hidden layer will go through 8 iterations. If the network is unfolded, it becomes an 8-layer network, with each layer corresponding to a letter. So you can imagine a standard neural network being repeated multiple times. The number of unfoldings is directly related to how long ago it remembers the data.

How Recurrent Neural Networks Operate
Recurrent Neurons
Here we will delve deeper into the actual neurons responsible for decision-making. Using the previously mentioned namaskar as an example, after giving the first 7 letters, we try to find out the 8th letter. The complete vocabulary of input data is {n,a,m,s,k,r}. In the real world, words or sentences would be more complex. To simplify the problem, we use the following simple vocabulary.
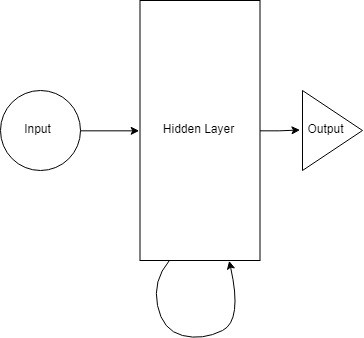
In the above figure, the hidden layer or RNN block applies the formula to the current input and the previous state. In this case, there is nothing before the letter n of namaste. So we directly use the current information to infer and move to the next letter a. In the process of inferring the letter a, the hidden layer applies the above formula combining the information of the current inference a with the information inferred from n before. Each state the input passes through in the network is a time step or one step, so the input at time step t is a, and the input at time step t-1 is n. By applying the formula to both n and a, we arrive at a new state.
The formula used for the current state is as follows:
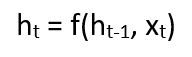
In this example, only the last step is remembered, thus merging only with the last step’s data. To enhance the memory capacity of the network and retain longer sequences in memory, we must add more states to the equation, such as h_t-2, h_t-3, etc. The final output can be computed in the same way as during the testing phase:
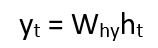
Where y_t is the output. By comparing the output with the actual output, we calculate the error value. The network learns by updating weights through backpropagating the error. The subsequent parts of this article will discuss backpropagation.
Backpropagation Through Time (BPTT)
This section assumes you already understand the concept of backpropagation. If you need a deeper understanding of backpropagation, please refer to the link: http://cs231n.github.io/optimization-2/.
Now we understand how RNNs actually operate, but how do we train RNNs in practice? How do we determine the weights for each connection? How do we initialize the weights of these hidden units? The purpose of recurrent networks is to accurately classify sequence inputs. This is achieved through backpropagation of the error value and gradient descent. However, the standard backpropagation used in feedforward networks cannot be applied here.
Unlike the directed acyclic feedforward networks, RNNs are cyclic graphs, which is where the problem lies. In feedforward networks, the error derivatives of previous layers can be computed. But the hierarchical arrangement of RNNs is different from that of feedforward networks.
The answer lies in what we discussed earlier. We need to unfold the network. Unfolding the network makes it look like a feedforward network.
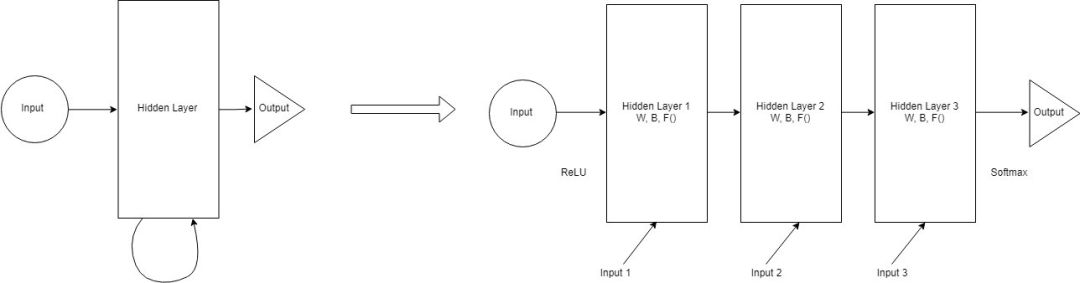
Unfolding RNN
At each time step, take out the hidden units of the RNN and copy them. Each copy in the time step acts like a layer in a feedforward network. In time step t+1, each layer in time step t connects to all possible layers. Therefore, we randomly initialize the weights, unfold the network, and optimize the weights in the hidden layers through backpropagation. This initialization is completed by passing parameters to the lowest layer. These parameters are also optimized as part of backpropagation.
The result of unfolding the network is that now the weights of each layer are different, resulting in different levels of optimization. There is no guarantee that the error calculated based on the weights will be equal. Therefore, at the end of each run, the weights of each layer will be different. This is something we absolutely do not want to see. The simplest solution is to somehow combine the errors of all layers together. The error values can be averaged or summed. In this way, we can use one layer across all time steps to maintain the same weights.
RNN Implementation
This article attempts to implement RNN using the Keras model. We try to predict the next sequence based on the given text.
Code link: https://gist.github.com/09aefc5231972618d2c13ccedb0e22cc.git
This model was built by Yash Katariya. I made some minor modifications to fit the requirements of this article.

This article is translated by Machine Heart, please contact the original author for authorization.
✄————————————————
Join Machine Heart (Full-time Reporter / Intern): [email protected]
Submissions or inquiries: content@jiqizhixin.com
Advertising & Business Cooperation: [email protected]