
Essential Knowledge Delivered Instantly
Essential Knowledge Delivered Instantly
This article is sourced from the AI Knowledge Base and reprinted from Smart Vehicle Technology. The article is for academic exchange only.
/ Introduction/
Object tracking is an important problem in the field of computer vision, currently widely used in sports broadcasting, security monitoring, drones, unmanned vehicles, robots, and other fields.
In simple terms, object tracking involves establishing the positional relationship of the object to be tracked in a continuous video sequence, obtaining the complete motion trajectory of the object. Given the target coordinates in the first frame of the image, the exact position of the target in the next frame is calculated. During motion, the target may exhibit some changes in the image, such as changes in posture or shape, scale changes, background occlusion, or changes in light intensity, etc. The research on object tracking algorithms also revolves around solving these changes and specific applications.
Currently, the main difficulties in object tracking include:
Shape Changes – Posture changes are common interference issues in object tracking. When a moving target undergoes posture changes, its features and appearance model may change, leading to tracking failures. For example: athletes in sports competitions, pedestrians on the road.
Scale Changes – Adaptive scaling is also a key issue in object tracking. When the target scale decreases, the tracking box cannot adaptively track, including a lot of background information, leading to errors in updating the target model; when the target scale increases, the tracking box cannot fully encompass the target, leading to incomplete target information within the tracking box, which also results in errors in updating the target model. Therefore, achieving scale-adaptive tracking is essential.
Occlusion and Disappearance – The target may be occluded or temporarily disappear during motion. When this happens, the tracking box is likely to include occluders and background information, causing the tracking target in subsequent frames to drift onto the occluder. If the target is completely occluded, tracking will fail as the corresponding model of the target cannot be found.
Image Blur – Changes in illumination intensity, rapid target motion, low resolution, etc., can lead to image model degradation, especially when the moving target is similar to the background. Therefore, selecting effective features to distinguish between the target and background is very necessary.

Development of Object Tracking Algorithms
Compared to traditional algorithms like optical flow, Kalman, and Meanshift, correlation filtering algorithms track faster, while deep learning methods achieve higher accuracy.
Trackers that integrate multiple features and deep features perform better in tracking accuracy.
Using a powerful classifier is fundamental to achieving good tracking.
Adaptive scaling and the model update mechanism also affect tracking accuracy.

Concept of Correlation Filter
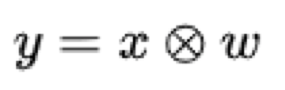
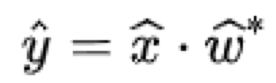

Development of Correlation Filters
MOSSE
CSK
CSK addresses the redundancy issue caused by sparse sampling in the MOSSE algorithm, expanding ridge regression, approximate dense sampling methods based on cyclic shifts, and kernel methods. Both MOSSE and CSK deal with single-channel grayscale images, introducing cyclic shifts and fast Fourier transforms, significantly improving the computational efficiency of the algorithm. However, the discrete Fourier transform also brings a side effect: boundary effects.
For boundary effects, there are two typical handling methods: overlaying a cosine window modulation on the image; increasing the area of the search region. The cosine window method makes the pixel values at the boundaries of the search area approach 0, eliminating the discontinuity at the boundary. However, the introduction of the cosine window also has drawbacks: it reduces the effective search area. For instance, during the detection phase, if the target is not at the center of the search area, some target pixels may be filtered out. If part of the target has already moved outside this area, it is likely that the remaining target pixels will also be filtered out. Its effect manifests as the algorithm struggling to track fast-moving targets. Expanding the search area can alleviate boundary effects and enhance the ability to track fast-moving targets, but the drawback is that it introduces more background information, potentially causing tracking drift.
CN
CN extends multi-channel color on the basis of CSK. It projects the 3-channel RGB image into 11 color channels, corresponding to commonly used color classifications in English: black, blue, brown, grey, green, orange, pink, purple, red, white, yellow, and normalizes to obtain 10-channel color features. PCA can also be used to reduce CN to 2D.
DCF KCF
From DCF to KCF, a Gaussian kernel is added, improving performance by 0.21% while reducing fps by 46.46%. Although the kernel trick is useful, its impact is minor; it can be discarded if speed is prioritized, while it can be used for extreme performance. KCF can be seen as an enhancement of CSK. The paper provides complete mathematical derivations for ridge regression, cyclic matrices, kernel tricks, rapid detection, etc. KCF extends multi-channel features based on CSK. The HoG features used in KCF have three types of kernels: Gaussian kernel, linear kernel, and polynomial kernel. The Gaussian kernel has the highest accuracy, while the linear kernel is slightly lower than the Gaussian kernel but much faster.
SAMF
SAMF is based on KCF, with features being HoG + CN. The method for achieving multi-scale object tracking is relatively direct, similar to multi-scale detection methods in detection algorithms. A translation filter is applied to image patches at multiple scales for target detection, taking the translation position with the maximum response and the corresponding scale. Therefore, this method can simultaneously detect changes in the target center and scale.
DSST fDSST
From DSST to fDSST, feature compression and scale filter acceleration were performed, resulting in a performance increase of 6.13% and an fps increase of 83.37%.
DSST treats object tracking as two independent problems: target center translation and target scale changes. First, it uses the HoG feature’s DCF to train the translation correlation filter responsible for detecting target center translation. Then, it trains another scale correlation filter using the HoG feature’s MOSSE (where the difference from DCF is that padding is not added) to detect target scale changes. An accelerated version, fDSST, was proposed in a paper published in 2017.
The scale filter only needs to detect the optimal matching scale without caring about the translation situation. Its calculation principle is as shown in the figure. DSST computes features (CN + HoG) by resizing all scale detection image patches to the same size, and then represents the features as one-dimensional (without cyclic shifts), with the response map for scale detection being a one-dimensional Gaussian function.
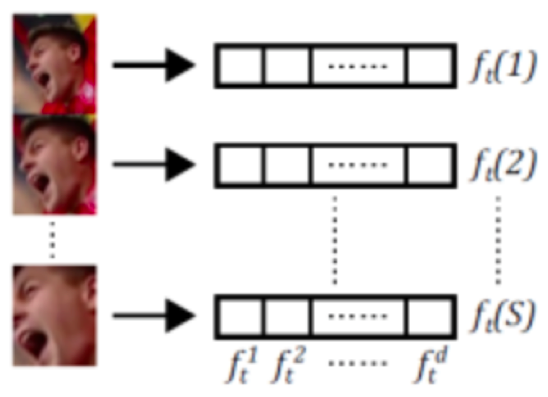
DSST was originally a fast solution to the scale adaptation problem (supporting 33 scales while being much faster than SAMF). In fDSST, MD has further accelerated DSST:
Translation Filter: The PCA method reduces the HOG features of the translation filter from 31 channels to 18 channels. This step is similar to the CN feature above, directly using PCA for dimensionality reduction. The author mentions that since a linear kernel is used here, there is no need for the smooth subspace constraints used in CN, making it simpler and more straightforward. As HOG features naturally reduce response resolution (cell_size=4), a simple and straightforward method is also employed to upsample the resolution of the response map to the original image resolution, which means interpolating the response map to improve detection accuracy. The method is triangular interpolation, equivalent to adding 0 to the frequency spectrum, making the method simpler, but this step increases algorithm complexity and may lead to poorer results due to its simplicity.
Scale Filter: The QR method reduces the HOG features of the scale filter (two features, without cyclic shifts) from 100017 to 1717. Due to the large dimension of the autocorrelation matrix affecting speed, PCA was not used here for efficiency, but instead QR decomposition. The number of scales is 17 (half of that in DSST), and the response map is a 1*17; here, interpolation is used to increase the scale number from 17 to 33 for more accurate scale localization.
SRDCF
SRDCF and CFLB share the idea of expanding the search area while constraining the effective scope of the filter template to solve boundary effects. A constraint is added to the filter template, penalizing areas close to the boundary more heavily, or making the coefficients of the filter template near the boundary approach 0, which is relatively slow.
CFLB/BACF
In the search area, pixels outside the target area are set to 0. CFLB only uses single-channel grayscale features, while the latest BACF expands the features to multi-channel HOG features. Both CFLB and BACF use the Alternating Direction Method of Multipliers (ADMM) for fast solving.
DAT
DAT is not a correlation filtering method but a method based on color statistical features. DAT statistics the color histogram of the foreground target and background area, which serves as the color probability model for the foreground and background. In the detection phase, the Bayesian method is used to determine the probability of each pixel belonging to the foreground, resulting in a pixel-level color probability map.
STAPLE STAPLE+CA
From Staple to STAPLE+CA, a Context-Aware constraint term was added, improving performance by 3.28% while reducing fps by 43.18%, indicating that the constraint term is effective but sacrifices a lot of fps. STAPLE combines the template feature method DSST and the color statistical feature method DAT.
Correlation filtering template features (HOG) perform poorly on rapid deformations and rapid movements but work well under conditions of motion blur and light changes; while color statistical features (DAT) are insensitive to deformations and do not belong to the correlation filtering framework, avoiding boundary effects, but they perform poorly under light changes and similar background colors. Therefore, these two methods can complement each other.
C-COT
The expressive capability of image features plays a crucial role in object tracking. Image features represented by HoG + CN perform excellently with significant speed advantages, but they also become a bottleneck for further performance improvement.
Deep features represented by Convolutional Neural Networks (CNN) have stronger feature expression capabilities, generalization capabilities, and transfer capabilities. Introducing deep features into correlation filtering is thus a natural progression.
LMCF
LMCF proposes two methods: multi-peak target detection and high-confidence updates. Multi-peak target detection performs multi-peak detection on the response map of translation detection. If the peak value of other peaks exceeds a certain threshold compared to the main peak value, it indicates that the response map is in multi-peak mode, and re-detection is performed around these multi-peaks, taking the maximum value of these response maps as the final target position.
High-confidence updates: The tracking model is only updated when the tracking confidence is relatively high, to avoid contaminating the target model. One confidence indicator is the maximum response. Another confidence indicator is the average peak-to-correlation energy (APCE), which reflects the fluctuation of the response map and the confidence level of detecting the target.
CSR-DCF
CSR-DCF proposes spatial reliability and channel reliability methods. Spatial reliability utilizes image segmentation methods to calculate spatial binary constraint masks through the foreground-background color histogram probability and center prior. The binary mask here is similar to the mask matrix P in CFLB. CSR-DCF uses image segmentation methods to more accurately select effective tracking target areas. Channel reliability is used to differentiate the weights of each channel during detection.
ECO ECO-HC
ECO is an accelerated version of C-COT, speeding up from three aspects: model size, sample set size, and update strategy. The speed is 20 times faster than C-COT, with an increase in EAO of 13.3% on the VOT2016 database. Of course, the most powerful is the hand-crafted features version of ECO-HC with 60FPS. Let’s take a look at these three steps.
The first step is to reduce model parameters. Since both CN features and HOG features can be dimensionally reduced, can convolutional features be tried? This is the first and most critical step in ECO’s acceleration, which is to factorize the convolution operation. The effect is similar to PCA, but Conv. Feat. is different from CN and HOG:
CNN feature dimensions are excessively large, requiring dimensionality reduction to ensure speed, while unsupervised dimensionality reduction may directly affect performance (compared to general methods – retaining over 95% of the feature dimensions while ensuring information retention);
Although CNN features have strong transfer capabilities, they are not specifically trained for tracking problems. Useful information for tracking is hidden in a large number of CNN activation values. If simple unsupervised dimensionality reduction is applied, it may filter out features that, while not significant, are effective for tracking. Of course, HOG and CN features have the same issue.
By using PCA, supervised dimensionality reduction:
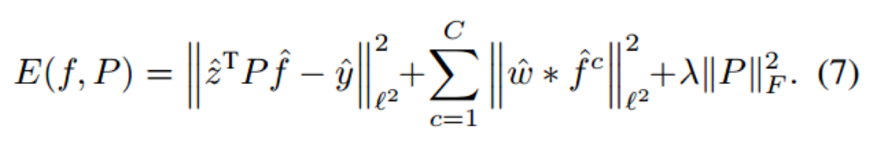

Statement: Some content is sourced from the internet, intended only for readers’ learning and exchange purposes. The copyright of the article belongs to the original author. If there are any issues, please contact for deletion.
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the "Visual Learning for Beginners" public account backend to download the first Chinese version of the OpenCV extension module tutorial on the internet, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc. over twenty chapters.
Download 2: Python Visual Practical Projects 52 Lectures
Reply "Python Visual Practical Projects" in the "Visual Learning for Beginners" public account backend to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc. to assist in quickly learning computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the "Visual Learning for Beginners" public account backend to download 20 practical projects based on OpenCV for advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the public account to exchange with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for notes, otherwise, it will not be approved. After adding successfully, you will be invited to related WeChat groups based on research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~