
(Click the blue text above to quickly follow us)
Compiled by: Author of the Jolly Online Column – Ree Ray
If you have good articles to submit, please click → here for details
This article introduces Natural Language Processing in Python from the ground up, covering both concepts and practical applications.
(Author’s note: This article is a complete revised version of my original publication in ACM Crossroads, Volume 13, Issue 4. The revision was necessary due to significant changes in the Natural Language Toolkit (NLTK). The revised code is compatible with the latest version of NLTK (updated to version 2.0.4 in September 2013). Although all code in this article has been tested, there may still be a few issues. If you encounter any problems, please report them to the author. If you must use version 0.7, please refer to here.
1 Introduction
This article attempts to introduce readers to the field of Natural Language Processing (NLP). Unlike typical articles that merely describe important concepts of NLP, this article also illustrates these concepts using Python. For readers unfamiliar with Python, some reference materials are provided to help you learn how to program in Python.
2 Related Introductions
2.1 Natural Language Processing
NLP encompasses a variety of technologies for the automatic generation, processing, and analysis of natural or human languages. While most NLP techniques inherit from linguistics and artificial intelligence, they are also influenced by relatively emerging disciplines such as machine learning, computational statistics, and cognitive science.
Before showcasing examples of NLP techniques, it is necessary to introduce some very basic terms. Note: To make the article more accessible, the definitions provided may not be linguistically rigorous.
-
Token: Before any actual processing of the input text, it needs to be segmented into linguistic units such as words, punctuation, numbers, or alphanumerics. These units are referred to as tokens.
-
Sentence: A sequence composed of ordered tokens.
-
Tokenization: The process of breaking a sentence down into its constituent tokens. In segmented languages like English, the presence of spaces makes tokenization relatively easy but also somewhat tedious. However, for languages like Chinese and Arabic, where clear boundaries are absent, this task becomes more challenging. Additionally, in some non-segmented languages, almost all characters can exist as single characters but can also combine to form multi-character words.
-
Corpus: A large body of text typically composed of rich sentences.
-
Part-of-speech (POS) Tag: Any word can be classified into at least one lexical set or part-of-speech category, such as noun, verb, adjective, and article. POS tags are represented by symbols to denote a lexical entry—NN (noun), VB (verb), JJ (adjective), and AT (article). The Brown Corpus is one of the oldest and most commonly used tagged corpora. More details will be provided later.
-
Parse Tree: Using the definitions of formal grammar, the syntactic structure of a given sentence can be represented using a tree diagram.
Having understood the basic terms, let us now explore common tasks in NLP:
-
POS Tagging: Given a sentence and a set of POS tags, a common language processing task is to tag each word in the sentence. For example, after POS tagging, the sentence ‘The ball is red’ would become ‘The/AT ball/NN is/VB red/JJ’. The most advanced POS taggers achieve an accuracy rate of up to 96%. POS tagging is essential for more complex NLP problems, such as parsing and machine translation, which we will discuss later.
-
Computational Morphology: A large number of words are composed of morphemes, which are the smallest units of language that carry meaning. Computational morphology focuses on discovering and analyzing the internal structure of words using computers.
-
Parsing: In the problem of syntactic analysis, a parser constructs a parse tree for a given sentence. To analyze syntax, some parsers assume a set of grammatical rules exists, but current parsers have become smart enough to directly infer parse trees using complex statistical models. Most parsers operate under a supervised setting where the sentence has already been POS tagged. Statistical parsing is a very active research area in NLP.
-
Machine Translation (MT): The goal of machine translation is to enable a computer to translate a text from one language to another fluently without human intervention. This is one of the most challenging tasks in NLP, and many different approaches have been developed over the years. Almost all machine translation methods rely on POS tagging and parsing as preprocessing steps.
2.2 Python
Python is a dynamically-typed, object-oriented interpreted programming language. Its primary advantage lies in allowing programmers to rapidly develop projects, yet its extensive standard library enables it to be suitable for large-scale, production-level engineering projects. The learning curve for Python is very steep, and there are many excellent online learning resources.
2.3 Natural Language Toolkit (NLTK)
Although Python can handle simple NLP tasks, it is insufficient for standard NLP tasks. This is where NLTK (Natural Language Processing Toolkit) comes into play. NLTK integrates modules and corpora and is released under an open-source license, allowing students to study and conduct research in NLP. The biggest advantage of using NLTK is its integration; it not only provides convenient functions and wrappers for building common NLP task blocks but also offers raw and preprocessed standard corpus versions used in NLP literature and courses.
3 Using NLTK
The NLTK website provides excellent documentation and tutorials for learning guidance. Simply reiterating the authors’ words would be unfair to them and to this article. Therefore, I will introduce NLTK by processing four NLP tasks of ascending difficulty. These tasks are derived from exercises or variations not provided in the NLTK tutorial. Thus, the solutions and analyses for each task are original to this article.
3.1 NLTK Corpora
As mentioned earlier, NLTK encompasses several practical corpora widely used in the NLP research community. In this section, we will look at three corpora that will be used later:
-
Brown Corpus: The Brown Corpus of Standard American English is considered the first general English corpus that can be used in computational linguistics. It contains one million words of American English text published in 1961. It represents a sample of general English, sampled from novels, news, and religious texts. Subsequently, a POS tagged version was created after extensive manual annotation.
-
Gutenberg Corpus: The Gutenberg Corpus consists of 14 texts selected from the largest online free eBook platform, the Gutenberg Project, containing a total of 1.7 million words.
-
Stopwords Corpus: In addition to regular text words, another category of words, such as prepositions, conjunctions, determiners, etc., which have important grammatical functions but carry little meaning, is called stop words. The stop words corpus collected by NLTK contains 2400 stop words from 11 different languages, including English.
3.2 NLTK Naming Conventions
Before we start using NLTK to handle our tasks, let’s familiarize ourselves with its naming conventions. The top-level package is nltk, and we refer to its built-in modules using fully qualified dot notation, such as nltk.corpus and nltk.utilities. Any module can import the top-level namespace using Python’s standard structure from … import ….
3.3 Task 1: Exploring Corpora
As mentioned above, NLTK contains several NLP corpora. We set this task to explore one of the corpora.
Task: Use NLTK’s corpus module to read the file austen-persuasion.txt contained in the Gutenberg corpus and answer the following questions:
-
How many words are in this corpus?
-
How many unique words are there in this corpus?
-
How many times do the top 10 most frequent words appear?
Using the corpus module, we can explore the built-in corpora, and NLTK also provides several useful classes and functions in the probability module that can be used to compute probability distributions for tasks. One of them is FreqDist, which can track the sample frequencies in the distribution. Listing 1 demonstrates how to use these two modules to handle the first task.
Listing 1: Exploring NLTK’s built-in corpora.
# Import the Gutenberg collection
>>> fromnltk.corpus importgutenberg
# What corpora are in this collection?
>>> printgutenberg.fileids()
[‘austen-emma.txt’,‘austen-persuasion.txt’,‘austen-sense.txt’,‘bible-kjv.txt’,‘blake-poems.txt’,‘bryant-stories.txt’,‘burgess-busterbrown.txt’,‘carroll-alice.txt’,‘chesterton-ball.txt’,‘chesterton-brown.txt’,‘chesterton-thursday.txt’,‘edgeworth-parents.txt’,‘melville-moby_dick.txt’,‘milton-paradise.txt’,‘shakespeare-caesar.txt’,‘shakespeare-hamlet.txt’,‘shakespeare-macbeth.txt’,‘whitman-leaves.txt’]
# Import the FreqDist class
>>> fromnltk importFreqDist
# Instantiate frequency distribution
>>> fd = FreqDist()
# Count the tokens in the text
>>> forword ingutenberg.words(‘austen-persuasion.txt’):
…fd.inc(word)
…
>>> printfd.N()# total number of samples
98171
>>> printfd.B()# number of bins or unique samples
6132
# Get the top 10 words sorted by frequency
>>> forword infd.keys()[:10]:
…printword,fd[word]
,6750
the3120
to2775
.2741
and2739
of2564
a1529
in1346
was1330
;1290
Answer: Jane Austen’s novel Persuasion contains a total of 98171 words and 6141 unique words. Furthermore, the most common token is the comma, followed by the word ‘the’. In fact, the last part of this task is one of the most interesting observations, perfectly illustrating the phenomenon of word occurrence. If you conduct statistics on a massive corpus, recording the occurrence count of each word and the frequency of word occurrences in descending order, you can intuitively observe the relationship between word frequency and word rank in the list. In fact, Zipf has proven that this relationship can be expressed as a mathematical expression, for any given word, $fr$ = $k$, where $f$ is the frequency of the word, $r$ is the rank of the word in the sorted list, and $k$ is a constant. Therefore, for example, the fifth most frequent word should occur twice as often as the tenth most frequent word. In NLP literature, this relationship is often referred to as Zipf’s Law.
Even though the mathematical relationship described by Zipf’s Law may not be entirely accurate, it still provides useful insight into the distribution of words in human language—words with lower ranks occur more frequently, while those with slightly higher ranks occur less frequently, and those with very high ranks seldom appear. The last part of Task 1 can be easily visualized using NLTK, as shown in Listing 1a. The corresponding log-log relationship can be clearly seen in Figure 1, illustrating the corresponding expansion relationship in our corpus.
Listing 1a: Using NLTK to visualize Zipf’s Law
>>> fromnltk.corpus importgutenberg
>>> fromnltk importFreqDist
# Import matplotlib for plotting (available from NLTK download page)
>>> importmatplotlib
>>> importmatplotlib.pyplot asplt
# Count the frequency of each token in Gutenberg
>>> fd = FreqDist()
>>> fortext ingutenberg.fileids():
…forword ingutenberg.words(text):
…fd.inc(word)
# Initialize two empty lists to hold ranks and frequencies
>>> ranks = []
>>> freqs = []
# Generate (rank, frequency) points for each token and add them to the corresponding lists
# Note that fd will automatically sort in the loop
>>> forrank,word inenumerate(fd):
…ranks.append(rank+1)
…freqs.append(fd[word])
…
# Show the relationship between rank and frequency in a log-log plot
>>> plt.loglog(ranks,freqs)
>>> plt.xlabel(’frequency(f)’,fontsize=14,fontweight=’bold’)
>>> plt.ylabel(’rank(r)’,fontsize=14,fontweight=’bold’)
>>> plt.grid(True)
>>> plt.show()
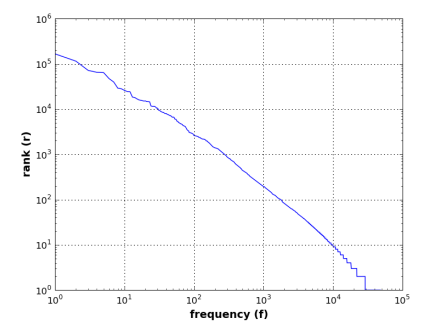
Figure 1: Is Zipf’s Law applicable in the Gutenberg Corpus?
3.4 Task 2: Predicting Words
Now that we have explored the corpus, let’s define a task that can utilize the results of our previous exploration.
Task: Train and create a word predictor program that can predict the next word given a training corpus. Use this predictor to randomly generate a sentence of 20 words.
To create the word predictor, we first need to calculate the sequential distribution of two words in the training corpus, for example, we need to accumulate the occurrence count of the next word following a given word. Once we have computed the distribution, we can input a word and get a list of all possible next words in the corpus and randomly output one from the list. To randomly generate a sentence of 20 words, I just need to provide an initial word, use the predictor to predict the next word, and repeat the operation until the sentence reaches 20 words. Listing 2 describes how to implement this using NLTK’s provided modules, using Jane Austen’s Persuasion as the training corpus.
Listing 2: Using NLTK to predict words
>>> fromnltk.corpus importgutenberg
>>> fromnltk importConditionalFreqDist
>>> fromrandomimportchoice
# Instantiate the distribution
>>> cfd = ConditionalFreqDist()
# For each instance, count the next word for a given word
>>> prev_word = None
>>> forword ingutenberg.words(’austen–persuasion.txt’):
…cfd[prev_word].inc(word)
…prev_word = word
# Given ‘therefore’ as the initial word for the predictor
>>> word = ’therefore’
>>> i = 1
# Find all possible next words for the given word and randomly select one
>>> whilei < 20:
…printword,
…lwords = cfd[word].samples()
…follower = choice(lwords)
…word = follower
…i += 1
…
therefore it known of women ought.Leave me so well
placed infive altogether well placed themselves delighted
Answer: The output sentence of 20 words is certainly not grammatically correct. However, from the perspective of word pairs, it is grammatically correct because the training corpus used to estimate the conditional frequency distribution is grammatical, and we are using this conditional distribution probability. Note that in this task, we use the previous word as the contextual hint for the predictor. It is also possible to use the previous two or even three words.
3.5 Task 3: Exploring POS Tags
NLTK combines a series of excellent modules that allow us to train and build relatively complex POS taggers. However, for this task, we will limit ourselves to a simple analysis of the already tagged corpus built into NLTK.
Task: Tokenize the built-in Brown Corpus and create one or more suitable data structures that can help us answer the following questions:
-
What is the most frequent POS tag?
-
Which word has the most different POS tags assigned?
-
What is the frequency ratio of male pronouns to female pronouns?
-
How many words are ambiguous, i.e., have at least two POS tags?
For this task, it is important to note that NLTK has two versions of the Brown Corpus: the first, which we have used in the previous two tasks, is the raw version, and the second is the tagged version, where each token in every sentence has been correctly POS tagged. In this version, each sentence is stored in a list of tuples, represented as: (token, tag). For example, a sentence in the tagged corpus like ‘the ball is green’ would be represented in NLTK as [(’the’,’at’), (’ball’,’nn’), (’is’,’vbz’), (’green’,’jj’)].
As previously explained, the Brown Corpus contains 15 different parts, represented by the words “a” to “r”. Each part represents a different text type, which is necessary for classification, but this is beyond the scope of this article. With this information, we need to build a data structure to analyze this tagged corpus. Considering the questions we need to solve, we will use the tokens in the text to discover the frequency distribution of POS standards and the conditional frequency distribution of POS tags. Note that NLTK also allows us to directly import FreqDist and ConditionalFreqDist classes from the top-level namespace. Listing 3 demonstrates how to use NLTK for this analysis.
Listing 3: Analyzing the tagged corpus with NLTK
>>> fromnltk.corpus importbrown
>>> fromnltk importFreqDist,ConditionalFreqDist
>>> fd = FreqDist()
>>> cfd = ConditionalFreqDist()
# For each tagged sentence in the corpus, represent it as (token, POS tag) pairs and count the POS tags and the tokens’ POS tags
>>> forsentence inbrown.tagged_sents():
…for(token,tag)insentence:
…fd.inc(tag)
…cfd[token].inc(tag)
>>> fd.max()# The most frequent POS tag is …
’NN’
>>> wordbins = []# Initialize a list to hold (numtags, word) tuples
# Add each (unique POS tag count, token) tuple to the list
>>> fortokenincfd.conditions():
…wordbins.append((cfd[token].B(),token))
…
# Sort the tuples by the number of unique POS tags in descending order
>>> wordbins.sort(reverse=True)
>>> printwordbins[0]# The token with the most tags is …
(12,’that’)
>>> male = [’he’,’his’,’him’,’himself’]# Male pronouns
>>> female = [’she’,’hers’,’her’,’herself’]# Female pronouns
>>> n_male,n_female = 0,0# Initialize counters
# Total male pronouns:
>>> forminmale:
…n_male += cfd[m].N()
…
# Total female pronouns:
>>> forfinfemale:
…n_female += cfd[f].N()
…
>>> printfloat(n_male)/n_female# Calculate the ratio
3.257
>>> n_ambiguous = 0
>>> for(ntags,token)inwordbins:
…ifntags > 1:
…n_ambiguous += 1
…
>>> n_ambiguous# Number of tokens with more than one POS tag
8729
Answer: In the Brown Corpus, the most frequent POS tag is naturally the noun (NN). The word with the most POS tags is ‘that’. The usage rate of male pronouns is approximately three times that of female pronouns. Finally, there are over 8700 ambiguous words in the corpus—this number illustrates the difficulty of the POS tagging task.
3.6 Task 4: Word Association
Free word association is a common task in psycholinguistics, especially in the context of lexical retrieval—human subjects tend to choose highly associative words rather than completely unrelated ones. This indicates that the processing of word associations is quite direct—when a subject hears a particular word, they immediately think of another word.
Task: Use a large, POS-tagged corpus to implement free word association. Ignore function words, assuming that associative words are all nouns.
For this task, we need to use the concept of “word co-occurrences,” for example: counting how often the closest words appear together, and then estimating their associative strength. For each token in the sentence, we will observe all subsequent words within a specified range and use the conditional frequency distribution to count their occurrence rates in that context. Listing 4 demonstrates how we can process the POS-tagged Brown Corpus within a range of 5 words using Python and NLTK.
Listing 4: Implementing word association with NLTK
>>> fromnltk.corpus importbrown,stopwords
>>> fromnltk importConditionalFreqDist
>>> cfd = ConditionalFreqDist()
# Get the English stop words list
>>> stopwords_list = stopwords.words(’english’)
# Define a function to return true if the tag is a noun
>>> defis_noun(tag):
…returntag.lower()in[’nn’,’nns’,’nn$’,’nn–tl’,’nn+bez’,
’nn+hvz’,’nns$’,’np’,’np$’,’np+bez’,’nps’,
’nps$’,’nr’,’np–tl’,’nrs’,’nr$’]
…
# Count the occurrences of the top 5 words
>>> forsentence inbrown.tagged_sents():
…for(index,tagtuple)inenumerate(sentence):
…(token,tag) = tagtuple
…token = token.lower()
…iftokennotinstopwords_list andis_noun(tag):
…window = sentence[index+1:index+5]
…for(window_token,window_tag)inwindow:
…window_token = window_token.lower()
…ifwindow_token notinstopwords_list and
is_noun(window_tag):
…cfd[token].inc(window_token)
# Done. Let’s start the associations!
>>> printcfd[’left’].max()
right
>>> printcfd[’life’].max()
death
>>> printcfd[’man’].max()
woman
>>> printcfd[’woman’].max()
world
>>> printcfd[’boy’].max()
girl
>>> printcfd[’girl’].max()
trouble
>>> printcfd[’male’].max()
female
>>> printcfd[’ball’].max()
player
>>> printcfd[’doctor’].max()
bills
>>> printcfd[’road’].max()
block
Answer: The word associator we built seems to work surprisingly well, especially given the minimal effort involved (in fact, in the context of popular psychology, our associator appears to exhibit human-like characteristics, albeit negative and pessimistic). The results of our task clearly demonstrate the effectiveness of general corpus linguistics. As a further exercise, the associator can easily be expanded using syntactically analyzed corpora and information-theoretic association tests.
4 Discussion
While this article uses Python and NLTK as the foundation for introducing basic NLP, it is important to note that there are other NLP frameworks active in academia and industry beyond NLTK. Among them, GATE (General Architecture for Text Engineering), developed by the NLP research group at the University of Sheffield, is quite popular. Written in Java, its windowed environment describes the connections between language processing components. GATE is available for free download and is primarily used in text mining and information extraction.
Each programming language and framework has its advantages and disadvantages. For the purposes of this article, we chose Python because it offers advantages over other languages, including: (a) high readability (b) an object-oriented paradigm that is easy to learn (c) ease of extensibility (d) strong decoding support (e) a powerful standard library. It is also particularly robust and efficient, as evidenced in complex and large-scale NLP projects, such as the latest machine translation decoders.
5 Conclusion
Natural language processing is a very popular research field, attracting many graduate students each year. It combines advantages from multiple disciplines, such as linguistics, psychology, computer science, and mathematics, to study human language. Additionally, a more important reason for choosing NLP as a graduate career is that there are many interesting problems without fixed solutions. For example, the original problem of machine translation has driven the development of this field; even after twenty years of enticing and active research, this problem remains unsolved. Several leading NLP problems currently have a significant amount of research work, some of which are listed below:
-
Syntax-based Machine Translation: Over the past several decades, most machine translation has focused on using statistical methods to learn translations of words and phrases through large corpora. However, an increasing number of researchers are beginning to incorporate syntax into their studies.
-
Multi-document Summarization: Currently, a lot of work involves automatically generating highly relevant summaries from collections of similar documents. This task is considered more difficult than single-document summarization because there is more redundant information in multi-document contexts.
-
Computational Parsing: Although using probabilistic models to automatically generate the syntactic structure of a given text has been around for a long time, there is still much room for improvement. The biggest challenge lies in accurate analysis, especially when comparing English with Chinese or Arabic, where the differences in language characteristics are significant.
Python and NLTK allow programmers to engage with NLP tasks without spending a lot of time acquiring resources. The text aims to provide examples and references for anyone interested in learning NLP to solve these simple tasks.
6 Author Bio
Nitin Madnani is a research scientist at Educational Testing Service (ETS). Previously, he was a PhD student in the Computer Science Department at the University of Maryland, College Park, and an assistant researcher at the Institute for Advanced Computer Studies. His research focuses on statistical natural language processing, particularly in machine translation and text summarization. Regardless of the task size, he firmly believes: Python is great.
References
[1]: Dan Bikel. 2004. On the Parameter Space of Generative Lexicalized Statistical Parsing Models. Ph.D. Thesis. http://www.cis.upenn.edu/~dbikel/papers/thesis.pdf
[2]: David Chiang. 2005. A hierarchical phrase-based model for statistical machine translation. Proceedings of ACL.
[3]: Kenneth W. Church and Patrick Hanks. 1990. Word association norms, mutual information, and lexicography. Computational Linguistics. 16(1).
[4]: H. Cunningham, D. Maynard, K. Bontcheva. and V. Tablan. 2002. GATE: A Framework and Graphical Development Environment for Robust NLP Tools and Applications. Proceedings of the 40th Anniversary Meeting of the Association for Computational Linguistics. 15
[5]: Michael Hart and Gregory Newby. Project Gutenberg. Proceedings of the 40th Anniversary Meeting of the Association for Computational Linguistics. http://www.gutenberg.org/wiki/Main_Page
[6]: H. Kucera and W. N. Francis. 1967. Computational Analysis of PresentDay American English. Brown University Press, Providence, RI.
[7]: Roger Levy and Christoper D. Manning. 2003. Is it harder to parse Chinese, or the Chinese Treebank? Proceedings of ACL.
[8]: Dragomir R. Radev and Kathy McKeown. 1999. Generating natural language summaries from multiple on-line sources. Computational Linguistics. 24:469-500.
[9]: Adwait Ratnaparkhi 1996. A Maximum Entropy Part-Of-Speech Tagger. Proceedings of Empirical Methods on Natural Language Processing.
[10]: Dekai Wu and David Chiang. 2007. Syntax and Structure in Statistical Translation. Workshop at HLT-NAACL.
[11]: The Official Python Tutorial. http://docs.python.org/tut/tut.html
[12]: Natural Language Toolkit. http://nltk.sourceforge.net
[13]: NLTK Tutorial. http://nltk.sourceforge.net/index.php/Book
If you found this article helpful, please share it with more people
Follow