Authorized Reprint
Authors: Long Xinchen, Han Xiaoyang
◆ ◆ ◆
1. Introduction
You might not be familiar with this thing called ‘Machine Learning’, but when you lift your iPhone to take a photo, you are already accustomed to it helping you frame human faces; you naturally click on the news recommended by today’s headlines; you are used to browsing Taobao and comparing goods after clicking on ‘Find Similar’; or you enjoy the results of Microsoft’s age recognition website that go viral on social media. Yes, the core algorithms behind these functions are part of the machine learning domain.
Using a definition from experts, machine learning studies how computers can simulate human learning behaviors to acquire new knowledge or skills, and reorganize existing knowledge structures to continuously improve themselves. In simpler terms, it means that computers learn patterns and rules from data to make predictions on new data. In recent years, the explosion of internet data has far exceeded what can be observed and summarized manually, and machine learning algorithms can guide computers to uncover useful value from vast amounts of data, captivating countless learners.
However, the more we talk about it, the more machine learning seems distant and enigmatic. We are not experts, but we do have some practical experience applying machine learning in projects with real data. This article summarizes some helpful methods for beginners and useful resources for advancement based on our experiences and the sharing of colleagues.

◆ ◆ ◆
2. Problems Addressed by Machine Learning
Not all problems are suitable for solving with machine learning (many logically clear problems can be efficiently and accurately handled with rules), and no single machine learning algorithm can be universally applied to all problems. Let’s first understand what kinds of problems machine learning is concerned with and aims to solve.
From a functional perspective, machine learning can solve the following problems with a certain scale of data:
1. Classification Problems
-
Determining which of a limited number of categories a data sample belongs to based on extracted features from the data. For example:
-
Spam email detection (result categories: 1. Spam 2. Normal email)
-
Text sentiment analysis (result categories: 1. Positive 2. Negative)
-
Image content recognition (result categories: 1. Cat 2. Dog 3. Human 4. Alpaca 5. None of the above).
2. Regression Problems
-
Predicting a continuous value based on features extracted from data samples. For example:
-
Box office of Stephen Chow’s ‘Mermaid’
-
Housing prices in the capital two months later
-
How many times the neighbor’s child visits your house in a day, and how many toys they favor
3. Clustering Problems
-
Grouping samples based on extracted features (similar/relevant samples are grouped together). For example:
-
Google’s news classification
-
User segmentation
We can categorize the common problems mentioned above into two typical classifications in machine learning.
-
Classification and regression problems require training with labeled data, which falls under ‘supervised learning’
-
Clustering problems do not require known labels, which falls under ‘unsupervised learning’.
If you wander around the IT industry (especially in the internet sector), you will find that machine learning is widely applied in the following hot topics:
1. Computer Vision
-
Typical applications include: face recognition, license plate recognition, text scanning recognition, image content recognition, image search, etc.
2. Natural Language Processing
-
Typical applications include: intelligent matching in search engines, text content understanding, text sentiment judgment, speech recognition, input methods, machine translation, etc.
3. Social Network Analysis
-
Typical applications include: user profiling, network correlation analysis, fraud detection, hot topic discovery, etc.
4. Recommendations
-
Typical applications include: Xiami Music’s ‘Song Recommendations’, Taobao’s ‘You May Also Like’, etc.
◆ ◆ ◆
3. Entry Methods and Learning Path
Alright, let’s cut to the chase and get to the core content. Although machine learning appears to have a steep learning curve, there is a relatively common learning path for most beginners, along with some excellent introductory resources that can lower the learning threshold and stimulate our enthusiasm for learning.
In simple terms, a rough learning path looks like this:
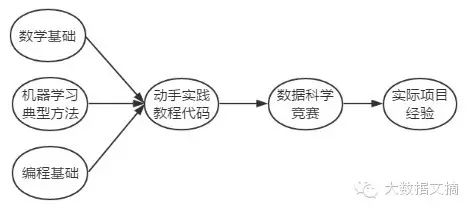
To explain a bit, the reason for listing ‘Mathematical Foundations’, ‘Typical Machine Learning Algorithms’, and ‘Programming Basics’ in parallel on the far left is that machine learning is a field that tightly integrates mathematical/algorithmic theory with engineering practice. A solid theoretical foundation is necessary to guide data analysis and model tuning, while excellent engineering skills are required to efficiently train and deploy models and services.
It is worth mentioning that in the internet field, there are two common backgrounds among people engaged in machine learning. One large group comes from programming backgrounds, who tend to have more engineering experience, while the other group comes from mathematics and statistics, who tend to have a stronger theoretical foundation. Therefore, compared to the diagram above, the two groups of learners have different areas to strengthen when entering machine learning.
Next, let’s elaborate on the sections mentioned in the diagram:
3.1 Mathematical Foundations
Countless passionate individuals march forward, determined to make a mark in the field of machine learning, only to feel overwhelmed upon seeing formulas. Indeed, the fundamental reason machine learning has a higher barrier compared to other development work is mathematics. Each algorithm requires maximum fitting on the training set while ensuring generalization ability, which necessitates constant analysis of results and data, and parameter tuning. This requires a certain understanding of data distributions and the underlying mathematical principles of the models. Fortunately, if one only wishes to apply machine learning reasonably without delving into high-end research in related fields, the required mathematical knowledge can be grasped with some effort. As for the more advanced parts, well, I am willing to admit that I am a ‘mathematics novice’.
All common machine learning algorithms require a mathematical foundation concentrated in calculus, linear algebra, and probability and statistics. Below, we will briefly go over the key knowledge areas, and the latter part of the article will introduce some resources to help learn and consolidate this knowledge.
3.1.1 Calculus
-
The computation of derivatives and their geometric and physical meanings are central to the solving processes of most algorithms in machine learning. For example, methods such as gradient descent and Newton’s method are used. A thorough understanding of their geometric meanings can help one grasp that ‘gradient descent approximates locally with a plane, while Newton’s method approximates locally with a surface’, leading to a better understanding of the application of these methods.
-
Knowledge of convex optimization and constrained optimization is ubiquitous in algorithm applications, and systematic learning of these concepts will elevate your understanding of algorithms to a new level.
3.1.2 Linear Algebra
-
Most machine learning algorithms rely on efficient computation, and in such scenarios, the multi-layer for loop commonly used by programmers may not be effective. Most looping operations can be transformed into matrix multiplication, which is closely related to linear algebra.
-
The inner product operation of vectors is also ubiquitous.
-
Matrix multiplication and decomposition appear prominently in principal component analysis (PCA) and singular value decomposition (SVD) in machine learning.
3.1.3 Probability and Statistics
Broadly speaking, many tasks in machine learning are very similar to statistical data analysis and uncovering hidden patterns.
-
The concepts of maximum likelihood and Bayesian models serve as the theoretical foundation, while Naïve Bayes, language models (N-gram), hidden Markov models (HMM), and latent variable mixture probability models are their advanced forms.
-
Common distributions such as Gaussian distribution are foundational for Gaussian mixture models (GMM) and others.
3.2 Typical Algorithms
The vast majority of problems can be solved using typical machine learning algorithms. Here is a rough list of these methods:
-
Common algorithms for handling classification problems include: logistic regression (most commonly used in industry), support vector machines, random forests, Naïve Bayes (commonly used in NLP), deep neural networks (used in multimedia data such as video, images, and audio).
-
Common algorithms for handling regression problems include: linear regression, ordinary least squares regression, stepwise regression, multivariate adaptive regression splines.
-
Common algorithms for handling clustering problems include: K-means, density-based clustering, LDA, etc.
-
Common algorithms for dimensionality reduction include: principal component analysis (PCA), singular value decomposition (SVD), etc.
-
Common algorithms for recommendation systems: collaborative filtering algorithms.
-
Algorithms for model ensemble and boosting include: bagging, AdaBoost, GBDT, GBRT.
-
Other important algorithms include: the EM algorithm, etc.
It is worth noting that the ‘algorithm’ referred to in machine learning differs slightly from the ‘algorithm’ in data structures and algorithm analysis as discussed by programmers. The former focuses more on the recall rate, accuracy, and precision of resulting data, while the latter emphasizes time complexity and space complexity of execution processes. Of course, considerations of efficiency and resource usage are indispensable in practical machine learning problems.
3.3 Programming Languages, Tools, and Environments
After reviewing numerous theories and knowledge, it is essential to put them into practice and solve problems. Without the right tools, all the materials, frameworks, logic, and ideas won’t get you far. Therefore, we need appropriate programming languages, tools, and environments to help us apply machine learning algorithms on datasets or realize our ideas. For beginners, Python and R are excellent introductory languages that are easy to use, supported by active communities, and have rich toolkits to help us execute our ideas. Relatively speaking, computer science students tend to use Python more, while those from mathematics and statistics backgrounds prefer R. Here is a brief introduction to programming languages, tools, and environments:
3.3.1 Python
Python has a comprehensive suite of data science tools, from data acquisition and cleaning to integrating various algorithms.
-
Web Crawling: scrapy
-
Data Mining:
-
pandas: simulates R for data browsing and preprocessing.
-
numpy: array operations.
-
scipy: efficient scientific computing.
-
matplotlib: a very convenient data visualization tool.
-
-
Machine Learning:
-
scikit-learn: a well-known machine learning package. It may not be the most efficient, but its interface is well encapsulated, and nearly all machine learning algorithms have consistent input and output formats. Its supporting documentation can even serve as a tutorial for learning, showing great care. For non-high-dimensional, non-large-scale data, scikit-learn performs exceptionally well (you can check out sklearn’s source code if you’re interested; it’s quite interesting).
-
libsvm: an efficient implementation of the SVM model (understanding it is very beneficial, as the coefficient data input format of libsvm is very common).
-
keras/TensorFlow: for those interested in deep learning, it’s also easy to build your own neural networks.
-
-
Natural Language Processing:
-
nltk: comprehensive functionalities for natural language processing, with typical corpora, and very easy to get started.
-
-
Interactive Environment:
-
ipython notebook: seamlessly connects data to results, extremely convenient. Highly recommended.
-
3.3.2 R
The greatest advantage of R is its open-source community, which has gathered many powerful packages that can be used directly. Most machine learning algorithms have well-developed packages available in R, and the documentation is very comprehensive. Common packages include: RGtk2, pmml, colorspace, ada, amap, arules, biclust, cba, descr, doBy, e1071, ellipse, etc. Additionally, R excels in visualization, which is very beneficial for machine learning.
3.3.3 Other Languages
To meet the demands of seasoned programmers, here are some machine learning packages related to Java and C++.
-
Java Series
-
WEKA Machine Learning Workbench: equivalent to scikit-learn in Java.
-
Other tools such as Massive Online Analysis (MOA), MEKA, Mallet, etc., are also very well-known.
-
For more detailed applications, please refer to the article ’25 Java Machine Learning Tools & Libraries’.
-
C++ Series
-
mlpack: an efficient and extensible machine learning library.
-
Shark: a well-documented, established C++ machine learning library.
3.3.4 Big Data Related
-
Hadoop: basically an industry standard. Generally used for feature cleaning and processing.
-
spark: provides a big data machine learning platform called MLlib, implementing many commonly used algorithms. However, reliability and stability still need improvement.
3.3.5 Operating Systems
-
Mac and Linux are somewhat more convenient, while Windows can be a bit limiting in development. The convenience mainly refers to the quicker installation and configuration of software on Mac and Linux.
-
For those who only use Windows, I recommend Anaconda, which installs the complete suite of Python data science tools in one go.
3.4 Basic Workflow
Now that we have the necessary conditions for machine learning, the next step is to apply them to complete a machine learning project. The workflow is as follows:
3.4.1 Abstracting into a Mathematical Problem
-
Clearly defining the problem is the first step in conducting machine learning. The training process in machine learning is usually very time-consuming, and random attempts can be very costly.
-
By abstracting into a mathematical problem, we clarify what kind of data we can obtain, whether the target is a classification, regression, or clustering problem, and if it does not fall into any of these categories, how to classify it.
3.4.2 Data Acquisition
-
Data determines the upper limit of machine learning results, while algorithms only strive to approach this limit.
-
Data must be representative; otherwise, overfitting is inevitable.
-
For classification problems, data skew cannot be too severe; the quantity of different categories should not differ by several orders of magnitude.
-
Moreover, it is essential to assess the scale of data: how many samples, how many features, and to estimate the memory consumption. This helps determine whether the memory can accommodate it during training. If not, consider improving the algorithm or applying some dimensionality reduction techniques. If the data volume is too large, consider distributed processing.
3.4.3 Feature Preprocessing and Selection
-
Good data must extract good features to be effective.
-
Feature preprocessing and data cleaning are critical steps that can significantly improve the effectiveness and performance of algorithms. Normalization, discretization, factorization, handling missing values, and removing multicollinearity often consume a lot of time during data mining processes. These tasks are straightforward to replicate, yield stable and predictable benefits, and are essential foundational steps in machine learning.
-
Selecting significant features and discarding insignificant ones requires machine learning engineers to repeatedly understand the business context. This has a decisive impact on many results. When feature selection is done well, even very simple algorithms can yield good and stable results. This requires the application of techniques for analyzing feature effectiveness, such as correlation coefficients, chi-square tests, average mutual information, conditional entropy, posterior probabilities, and logistic regression weights.
3.4.4 Model Training and Tuning
-
Only at this stage do we apply the algorithms mentioned above for training. Many algorithms can now be packaged into black boxes for user convenience. However, true expertise is tested by adjusting the (hyper)parameters of these algorithms to enhance results. This requires a deep understanding of the principles behind the algorithms. The deeper the understanding, the better one can identify the crux of problems and propose effective tuning solutions.
3.4.5 Model Diagnosis
How do we determine the direction and approach for model tuning? This requires model diagnostic techniques.
-
Determining overfitting and underfitting is a crucial step in model diagnosis. Common methods include cross-validation and plotting learning curves. The basic tuning approach for overfitting is to increase data volume and reduce model complexity. The basic tuning approach for underfitting is to enhance feature quantity and quality and increase model complexity.
-
Error analysis is also a vital step in machine learning. By examining error samples, we can comprehensively analyze the reasons for errors: whether it is an issue with parameters, algorithm selection, features, or the data itself…
-
The diagnosed model requires tuning, and the newly tuned model needs re-diagnosis; this is a repetitive iterative process that constantly approaches the optimal state through continuous attempts.
3.4.6 Model Ensemble
-
Generally speaking, model ensembles tend to improve results. Moreover, the effects are often quite good.
-
In engineering, the primary methods to enhance algorithm accuracy are to work on the front end (feature cleaning and preprocessing, different sampling modes) and the back end (model ensemble), as they tend to yield stable and replicable results. Direct parameter tuning is less frequent since training on large datasets is too slow, and results are hard to guarantee.
3.4.7 Online Deployment
-
This section is primarily related to engineering implementation. In engineering, results are outcome-oriented, and the performance of a model in a live environment directly determines its success. This includes not only accuracy and error metrics but also speed (time complexity), resource consumption (space complexity), and whether stability is acceptable.
This workflow is based on experiences summarized in engineering practice. Not every project will encompass a complete workflow. The sections here serve as a guiding outline, and only through hands-on practice and accumulating project experience will you gain a deeper understanding.
3.5 About Accumulating Project Experience
A common misconception among beginners in machine learning is to dive straight into pursuing various advanced algorithms. One might frequently wonder if they can use deep learning to solve a problem, or if they should employ boosting algorithms for model ensemble. I have always held the view that ‘discussions about algorithms divorced from business and data are meaningless’.
In reality, based on our learning experience, starting with a single data source, even using the most traditional machine learning algorithms that have been in use for years, and completing the entire machine learning workflow while continuously exploring the value of the data, truly understanding the data, features, and algorithms, and accumulating project experience is the fastest and most reliable learning path.
So how can one obtain data and projects? A shortcut is to actively participate in various data mining competitions both domestically and internationally. The data can be downloaded directly, and you can continuously optimize according to competition requirements and build experience. Platforms like Kaggle in the US, DataCastle in China, and Alibaba’s Tianchi competitions are excellent platforms where you can access real data and learn alongside data scientists while competing. Attempting to apply all the knowledge you have learned to complete the competition is also a very enjoyable endeavor. Discussions with other data scientists can broaden your perspective and deepen your understanding of machine learning algorithms.
Interestingly, some platforms, such as Alibaba’s Tianchi competitions, even provide components that cover everything from data processing to model training, evaluation, visualization, and model ensemble enhancement. All you need to do is participate in the competition, acquire the data, and use these components to realize your ideas. For specific content, you can refer to the Alibaba Cloud Machine Learning Documentation.
3.6 Self-Learning Ability
Let me add a few words here. This part is not directly related to machine learning itself, but we believe that this ability is crucial for learning any new knowledge and skills. Enhancing self-learning ability means you can find the most suitable learning materials and the fastest growth paths based on your situation.
3.6.1 Information Retrieval, Filtering, and Integration Skills
For beginners, the vast majority of required knowledge can be found online.
Google search engine techniques—combining and replacing search keywords, site search, academic literature search, PDF search, etc.—are all essential.
A good habit is to find the original sources of information, such as personal websites, public accounts, blogs, professional sites, books, etc. This way, you can find systematic and high-quality information that is not distorted.
Technical information found on Baidu is often not of high quality and should be used only as supplementary searches. Using various search engines in combination can yield better results.
Learn to search common high-quality information sources: stackoverflow (for programming-related queries), quora (for high-quality answers), wikipedia (for systematic knowledge, far better than other encyclopedias), zhihu (Chinese, informative), and cloud storage searches (plenty of free resources).
Organize collected webpages into a well-categorized cloud bookmark folder and frequently tidy it up. This way, whether at work or home, in front of a computer or on a phone, you can always find what you like.
Store collected files, code, e-books, etc., in cloud storage and keep them organized regularly.
3.6.2 Summarization and Refinement Skills
Regularly taking notes and summarizing what you have learned is an infallible way to grow. The main difficulty is often laziness, but persistence will lead to discovering commonalities in knowledge, allowing you to remember less while mastering more.
It is advisable to store notes in cloud note-taking apps like Evernote or Weizhi Note. This way, you can review notes and continue thinking during idle moments, such as on the subway or while waiting in line.
3.6.3 Questioning and Seeking Help Skills
There are numerous QQ groups, forums, and communities related to machine learning. Someone always knows the answer to your question.
However, most students are busy and cannot provide step-by-step guidance like a tutor.
To help responders quickly understand your question, learn to ask questions correctly: clearly state your business scenario and needs, what known conditions you have, which specific point you are struggling with, and what efforts you have made.
A classic article teaches you how to gain help through questioning: ‘The Art of Asking Questions’, which I strongly recommend. Although the tone may be sharp, the content is very valuable.
The likelihood of receiving help from others is exponentially related to the specificity and importance of your questions.
3.6.4 The Habit of Sharing
We firmly believe: ‘The best way to prove that you truly understand a knowledge area is to explain it clearly to someone who wants to learn it.’ Sharing can significantly enhance one’s own learning level. This is also the primary reason we insist on long-term sharing.
Sharing has the additional benefit of increasing your chances of receiving help when you seek assistance, which is also very important.
◆ ◆ ◆
4. Recommended Resources
In the last part of the article, we continue to provide valuable resources. In fact, there are many high-quality resources for machine learning. I have browsed through my browser bookmarks and consulted with colleagues to compile a portion of these resources as follows:
4.1 Introductory Resources
First, coursera is an excellent learning platform that gathers top courses from around the globe. You can find suitable courses for the knowledge learning process mentioned above. There are also many other course websites, and here are some recommended courses for the mathematics and machine learning algorithms we need to learn (some courses have Chinese subtitles, some have only English subtitles, and some have no subtitles at all; adjust based on your situation; if you are not comfortable with English, many domestic courses are also of high quality):
-
Calculus Related
Calculus: Single Variable Multivariable Calculus
-
Linear Algebra
Linear Algebra
-
Probability and Statistics
Introduction to Statistics: Descriptive Statistics Probabilistic Systems Analysis and Applied Probability
-
Programming Languages
Programming for Everybody: Python DataCamp: Learn R with R tutorials and coding challenges: R
-
Machine Learning Methods
Statistical Learning (R) Machine Learning: Highly recommended, Andrew Ng’s course Foundations of Machine Learning Machine Learning Techniques: Professor Lin Xuantian’s course is relatively in-depth, and completing the assignments will enhance your understanding of machine learning.Natural Language Processing: Stanford University course
-
Daily Reading Resources
@Aikeke-Ai Life’s Weibo Subscription to Machine Learning Daily etc.
4.2 Advanced Resources
-
Tutorials with Source Code
Examples of various algorithms in scikit-learn ‘Machine Learning in Action’ has a Chinese version and includes Python source code. ‘The Elements of Statistical Learning (Douban)’ has a corresponding Chinese version: ‘Statistical Learning Fundamentals (Douban)’. The book includes R packages, allowing you to learn algorithms by referring to the code. The Chinese version is available on cloud storage.‘Natural Language Processing with Python (Douban)’ is a classic in NLP, mainly discussing the NLTK package in Python. The Chinese version is also available on cloud storage.‘Neural Networks and Deep Learning’: Michael Nielsen’s textbook on neural networks, easy to understand. Some translations are available in China, but not complete; it is recommended to read the original version directly.
-
Books and Textbooks
‘Mathematics is Beautiful’: A great introductory read. ‘Statistical Learning Methods (Douban)’: A classic textbook by Li Hang. ‘Pattern Recognition and Machine Learning (Douban)’: A classic textbook. ‘Statistical Natural Language Processing’ is a classic textbook in natural language processing. ‘Applied Predictive Modeling’: an engineering practice-oriented machine learning textbook in English. ‘UFLDL Tutorial’: A classic textbook on neural networks. ‘Deep Learning Book’: A classic textbook on deep learning.
-
Reference Books
‘SciPy and NumPy (Douban)’ ‘Python for Data Analysis (Douban)’: authored by the creator of the Pandas package.
-
Other Online Resources
A comprehensive collection of materials on Machine Learning and Deep Learning: The author is very dedicated, with a wealth of high-quality content. Interested learners can check it out; I have only skimmed a small part so far.
◆ ◆ ◆
Author Introduction
Long Xinchen and Han Xiaoyang: Engaged in machine learning/data mining-related applications, passionate about machine learning/data mining.
‘We are a group of machine learning enthusiasts who love to communicate and share. We hope to exchange knowledge related to machine learning through the ‘ML Credit Plan’ and meet more friends. Everyone is welcome to join our discussion group for resources, materials, and sharing.’
Contact Information:
Long Xinchen
http://blog.csdn.net/han_xiaoyang
Han Xiaoyang
http://blog.csdn.net/longxinchen_ml
For previous exciting articles, click on the images to read.
-
Machine Learning: Interpreting Logistic Regression with Elementary Mathematics

-
Overview of Machine Learning Algorithms
-
[Valuable Content] Text Classification Using Naïve Bayes