This session shares as the title:
What Exactly Is Machine Learning
A Beginner’s Tutorial to Understand Machine Learning
First Steps in Machine Learning
Of course, it’s to understand its basic concepts
This article summarizes insights from the internet, personal learning notes✍
What is machine learning, and why does it have such great power? These questions are what this article aims to answer. At a time when artificial intelligence is booming, this article is meant to help beginners quickly understand and prepare for discussions about artificial intelligence and machine learning with friends👀

1. A Story to Explain What Machine Learning Is
The term machine learning can be confusing. First, it is a direct translation of the English term Machine Learning (abbreviated as ML), where ‘machine’ generally refers to a computer in the computing world.This name uses personification to indicate that this technology allows machines to “learn”. However, computers are lifeless; how could they possibly “learn” like humans?🤔
Traditionally, if we want to make a computer work, we give it a series of instructions, and it follows these instructions step by step. There is a clear cause and effect. But this method does not work in machine learning. Machine learning does not accept the instructions you input; instead, it accepts the data you input! In other words, machine learning is a method that allows computers to perform various tasks using data rather than instructions. This sounds incredible, but it is very feasible in practice.📈The idea of “statistics” will accompany you throughout your learning of concepts related to “machine learning,” and the concept of correlation rather than causation will be the core concept supporting the functionality of machine learning. You will overturn the fundamental idea of causation that you established in all your previous programs.
Now, let me illustrate what machine learning is through a story. This story is quite suitable for explaining a concept on Zhihu👇
This story is called “The Waiting Problem.”
I believe everyone has had experiences waiting for someone. In reality, not everyone is punctual, so when you encounter people who are often late, your time is inevitably wasted⌚. I have encountered such an example.
For my friend Xiao Y, he is not very punctual, and the most common manifestation is that he is often late🕊. Once, when I arranged to meet him at a McDonald’s at 3 PM, I suddenly thought of a question as I was heading out: Is it appropriate for me to leave now? Will I end up waiting for 30 minutes after arriving? I decided to adopt a strategy to solve this problem💡
To solve this problem, there are several methods.The first method is to use knowledge: I search for knowledge that can solve this problem. Unfortunately, no one teaches how to wait for someone, so I cannot find existing knowledge to solve this problem.The second method is to ask others: I ask others for their ability to solve this problem. But similarly, no one can answer this because perhaps no one has encountered a situation like mine. The third method is the rule method: I ask myself if I have set any rules to face this problem? For example, regardless of others, I will always arrive on time. But I am not a rigid person; I have not set such a rule🔑
In fact, I believe there is a method that is more suitable than the above three. I recall my past experiences of meeting Xiao Y and see how often he was late.And I use this to predict the likelihood of him being late this time; if this value exceeds a certain threshold in my mind, I choose to leave a little later. Suppose I have met Xiao Y 5 times, and he was late once, then his on-time arrival rate is 80%. My threshold is 70%, so I believe Xiao Y will not be late this time, and I leave on time. If Xiao Y was late 4 times out of 5, meaning his on-time arrival rate is 20%, since this value is below my threshold, I choose to delay my departure time. This method, from its utilization perspective, is also called the empirical method. In the process of empirical thinking, I actually utilized all the data from past appointments. Therefore, it can also be called a judgment based on data.
Judgments made based on data are fundamentally consistent with the ideas of machine learning.
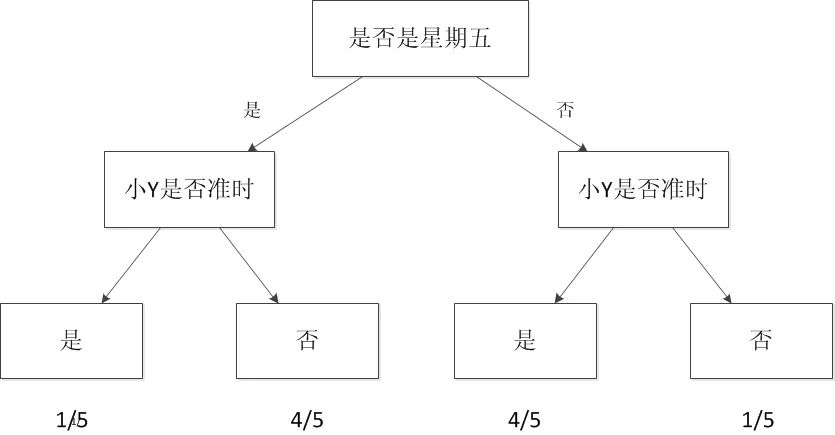
In the previous thought process, I only considered the attribute of “frequency.” In real machine learning, this might not even be an application.Generally, a machine learning model considers at least two quantities📏: one is the dependent variable, which is the result we want to predict, in this example, whether Xiao Y is late or not. The other is the independent variable, which is the quantity used to predict whether Xiao Y will be late. Suppose I take time as the independent variable; for example, I find that Xiao Y is mostly late on Fridays, while he is generally not late on other days. Thus, I can establish a model to simulate the probability of Xiao Y being late based on whether the day is Friday. See the image below:
Figure Decision Tree Model
This kind of diagram is the simplest machine learning model,
When we consider only one independent variable, the situation is relatively simple.If we add another independent variable, for example, Xiao Y is sometimes late when he is driving (you can understand this as he is a poor driver, or the traffic is heavy). So I can associate this information and establish a more complex model, which includes two independent variables and one dependent variable.
To make it even more complex, Xiao Y’s lateness can also be influenced by the weather, such as when it rains, at this point, I need to consider three independent variables.
If I want to predict the exact time Xiao Y will be late, I can create a model that combines the time he is late with the amount of rainfall and the previously considered independent variables. Thus, my model can predict values, such as how many minutes he might be late. This can help me plan my departure time better. In this case, the decision tree would not support well,because decision trees can only predict discrete values. We can use linear regression to establish this model.
If I hand over the modeling process to the computer, for example, by inputting all independent and dependent variables and letting the computer generate a model, while also allowing the computer to give me advice on whether I need to leave late and by how many minutes based on my current situation, then the process of the computer executing these auxiliary decisions is the process of machine learning.
Machine learning methods are a way for computers to utilize existing data (experience) to derive a certain model (the rules of being late) and use this model to predict the future (whether he will be late).
From the above analysis, we can see that machine learning is similar to the human process of inductive reasoning, but it can consider more situations and perform more complex calculations. In fact, one of the main purposes of machine learning is to transform the human process of inductively summarizing experience into the process by which computers derive models through data processing calculations. The models derived from computers can solve many flexible and complex problems in a way that approximates human thinking.
Next, I will begin a formal introduction to machine learning, including definitions, scope, methods, applications, and more.
2. Definition of Machine Learning
In a broad sense, machine learning is a method that enables machines to learn capabilities to accomplish functions that direct programming cannot achieve. But in practical terms, machine learning is a method that utilizes data to train a model and then uses that model to make predictions.
Let’s look at a specific example.
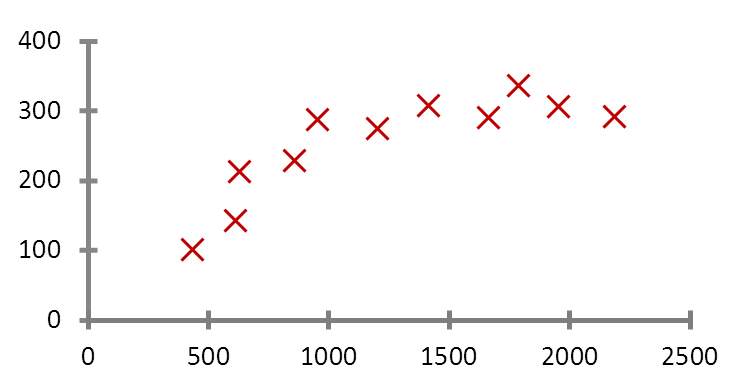
Figure 4 Example of Housing Prices
Take the national topic of housing as an example.
I have a house that needs to be sold; how much should I price it?💴
The area of the house is 100 square meters; should the price be 1 million, 1.2 million, or 1.4 million?
Clearly, I want to find a certain pattern between housing prices and area. So how do I obtain this pattern? Should I use the average data from newspapers? Or should I refer to similar-sized houses? Either way, it seems not very reliable.
I now want to find a reasonable pattern that can best reflect the relationship between area and housing price.So I surveyed some houses similar to mine in the vicinity to gather a set of data.This set of data includes the areas and prices of various houses. If I can find the pattern between area and price from this data, then I can determine the price of my house.
Finding the pattern is quite simple, fitting a line📈 that “passes through” all the points while minimizing the distance to each point as much as possible.
Through this line, I obtain a pattern that best reflects the relationship between housing prices and area. This line is also represented by the following function:
Housing Price = Area * a + b
In the above, a and b are the parameters of the line. Once I obtain these parameters, I can calculate the price of the house.
Assuming a = 0.75, b = 50, then Housing Price = 100 * 0.75 + 50 = 1.25 million. This result differs from the previously listed 1 million, 1.2 million, and 1.4 million. Since this line considers most situations, it is the most reasonable prediction from a “statistical” perspective.
This process reveals two pieces of information💡:1. The housing price model is determined by the type of fitted function.If it is a straight line, then the fitted function is the linear equation.If it is another type of line, such as a parabola, then the fitted function is the parabolic equation. Machine learning has many algorithms; some powerful algorithms can fit complex non-linear models to reflect situations that cannot be expressed by a straight line. 2. If my data is more abundant, my model can consider more situations, thus potentially improving the prediction accuracy for new situations. This reflects the machine learning community’s idea that “data is king.” Generally speaking (not absolutely), the more data you have, the better the prediction effect of the model generated by machine learning.
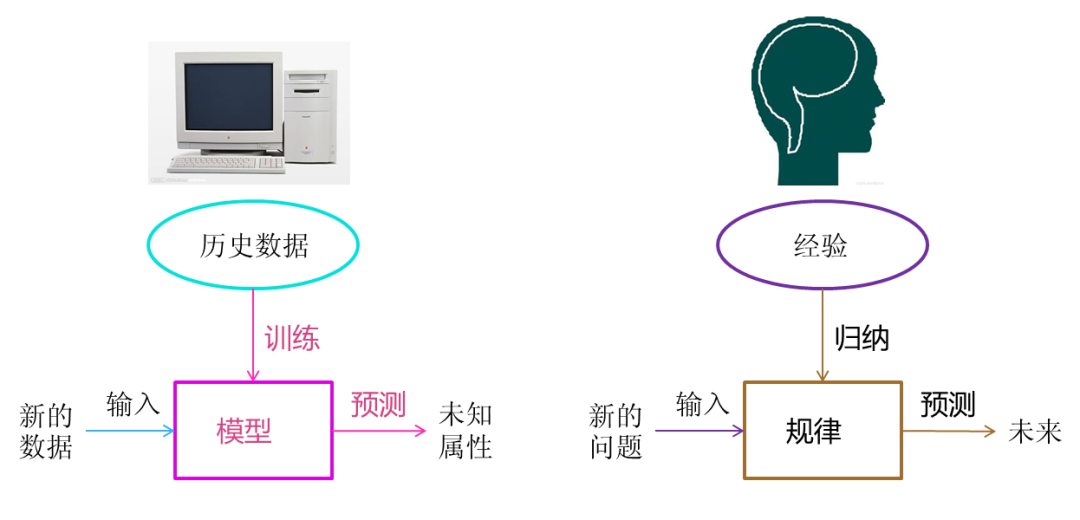
Through the process of fitting the line, we can do a complete review of the machine learning process. First, we need to store historical data in the computer. Then, we process this data using machine learning algorithms; this process is called “training” in machine learning, and the result of the processing can be used to predict new data; this result is generally referred to as a “model.” The process of predicting new data in machine learning is called “prediction.”“Training” and “prediction” are the two processes of machine learning, and “model” is the intermediate output result of the process. “Training” generates a “model,” which guides the “prediction.”
Let’s compare the machine learning process with the human process of inductively summarizing experiences.
Figure 5 Comparison of Machine Learning and Human Thinking
Humans accumulate a lot of history and experience during growth and life. Humans periodically inductively summarize these experiences to gain “patterns” in life. When humans encounter unknown problems or need to “speculate” about the future, they use these “patterns” to guide their lives and work.
The “training” and “prediction” processes in machine learning correspond to the human processes of “induction” and “speculation.” Through this correspondence, we can find that the ideas of machine learning are not complex; they are merely a simulation of how humans learn and grow in life. Since machine learning is not the result formed by programming, its processing is not causal logic but conclusions drawn through inductive reasoning.
This can also be related to why humans study history; history is essentially a summary of human past experiences. There is a saying that goes, “History often differs, but it is always remarkably similar.” By studying history, we inductively summarize the laws of life and nations to guide our next steps, which is immensely valuable. Some contemporary people overlook the true value of history and instead use it as a means to promote achievements; this is actually a misuse of the genuine value of history.
3. Scope of Machine Learning🔖
Although the above text explains what machine learning is, it does not provide the scope of machine learning.
In fact, machine learning is closely related to fields such as pattern recognition, statistical learning, data mining, computer vision, speech recognition, and natural language processing.
In terms of scope, machine learning is similar to pattern recognition, statistical learning, and data mining, while the combination of machine learning with other processing technologies has formed interdisciplinary fields like computer vision, speech recognition, and natural language processing. Therefore, when we speak of data mining, it can be equated with machine learning. At the same time, the applications we commonly refer to in machine learning should be general and not limited to structured data; it also includes applications in images, audio, etc.
This content introduces the relevant fields of machine learning, which helps us clarify the application scenarios and research scope of machine learning and better understand the subsequent algorithms and application levels.
The following image shows some related fields and research areas involved in machine learning:
 Figure 6 Machine Learning and Related Disciplines
It can be seen that machine learning has extensive applications and extensions in many fields. The development of machine learning technology has driven progress in many intelligent areas, improving our lives.
Hope we all maintain a love for life❤
The following are previously shared valuable contents
Hope the content shared by seniors helps both you and me💪
Kubernetes Series Articles
Figure 6 Machine Learning and Related Disciplines
It can be seen that machine learning has extensive applications and extensions in many fields. The development of machine learning technology has driven progress in many intelligent areas, improving our lives.
Hope we all maintain a love for life❤
The following are previously shared valuable contents
Hope the content shared by seniors helps both you and me💪
Kubernetes Series Articles
[Technical Analysis] Data Processing Tool Pandas Below
[Technical Analysis] Data Processing Tool Pandas Above
-
[Habit Rules] Do All Habit Cultivations Follow the 21-Day Rule?
-
[Senior Talks] Positive Waste Person Self-Rescue Guide
-
[Sharing] The Less Known Side of Houchang Village
-
[Sharing] HI, Long Time No See Senior
-
[Test Development] Sharing the Inner Monologue of Test Development Engineers
-
[AI] Code Autocomplete Tool, KITE
-
[Film Sharing] What Preparations Are Needed Before Watching Nolan’s New Film “Tenet”
-
[Interview Experience] About – ByteDance. -01 Byte Encounter
-
[Interview Experience] Senior’s First Interview at Baidu – Experience Sharing
-
[Learning Resources] Python Course Sharing_Suggestions for Sharing and Collecting
-
[Summer Eight Talks] Set Up a Stall, Young People
“Life is suffering, and I set sail with my broken paddle again”
PS: Reply in the public account: Senior WeChat, you can contact me!
If you find the content good, please click "Looking" to support it, thank you all.
I also hope this world will be better because of sharing!
Purely sharing, with no interests involved!
Finally, let me share my personal blog and personal photography website📷