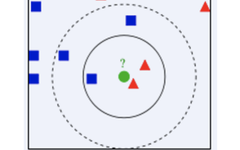

KNN algorithm, or K-Nearest Neighbor (KNN) classification algorithm, is simply a method of classification by measuring the distance between different feature values.
KNN is a very fundamental algorithm in the field of machine learning that can solve classification or regression problems. If you are just starting to learn machine learning, KNN is a very good choice for beginners due to its ease of understanding and simple implementation.
A simple example is judging whether a student passes based on their class performance. It can clearly distinguish between top students and those who struggle. In simple terms, the guiding principle of the KNN algorithm is “birds of a feather flock together,” where your neighbors help infer your category.
Basic Steps of KNN Algorithm
1. Calculate the distance between the object to be classified and other objects;
2. Count the K nearest neighbors;
3. For the K nearest neighbors, the category that they belong to the most will determine the category of the object to be classified.
Advantages and Disadvantages of KNN Algorithm
Advantages: high accuracy, insensitive to outliers, no data input assumptions.
Disadvantages: high computational complexity, high space complexity.
Applicable data range: numeric and nominal.
A major drawback of the KNN algorithm in classification is that when the sample is imbalanced, for example, if one class has a large sample size while others are small, it may lead to a situation where the majority of the K neighbors of a new sample belong to the large class. The algorithm only calculates the nearest neighbor samples; if a certain class has a large number of samples, either these samples are not close to the target sample, or they are very close.
Regardless, quantity does not affect the running result. A weighting method can be adopted (increasing the weight of neighbors that are close to the sample) for improvement.
Key Points of KNN Algorithm
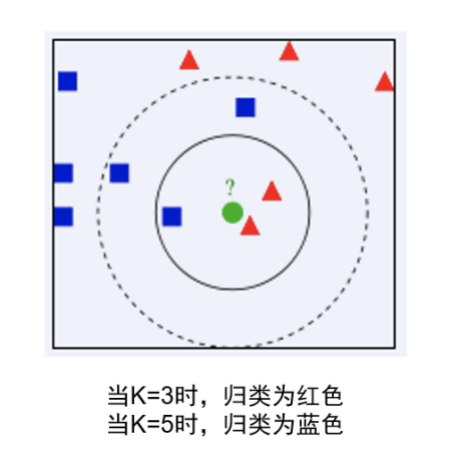
Generally, a small k value can make the model overly complex, causing overfitting; a large k value can make the model classification vague, causing underfitting. In practical applications, we can choose different k values and determine the size of K through cross-validation. In the code, we set k as a tunable parameter.
1. All features of the sample must be quantifiable for comparison.
If there are non-numeric types among the sample features, measures must be taken to quantify them into numeric values. For example, if the sample features include colors, they can be converted to grayscale values for distance calculations.
2. Sample features need to be normalized.
If a sample has multiple parameters, each parameter has its own domain and range of values, and their influence on distance calculations varies. For example, parameters with larger values can overshadow those with smaller values. Therefore, sample parameters must undergo some scale processing, the simplest way being to normalize all feature values.
3. A distance function is needed to calculate the distance between two samples.
Euclidean distance, Manhattan distance, Chebyshev distance, etc.
4. Determine the value of K.
If the value of K is too large, it can lead to underfitting; if it’s too small, it can easily cause overfitting. Cross-validation is needed to determine the value of K.
Among these, normalization and K value selection are particularly important.
Normalization:
When multiple features are present, if one feature has a much larger magnitude than others, the final classification result will be dominated by that feature, weakening the influence of other features. This is due to the different dimensions of each feature, necessitating data normalization.

K Value Selection
Generally, a small k value can make the model overly complex, causing overfitting; a large k value can make the model classification vague, causing underfitting. In practical applications, we can choose different k values and determine the size of K through cross-validation. In the code, we set k as a tunable parameter.
Summary of KNN Algorithm
The most important steps in building a KNN model are actually the selection and processing of data features. The more thorough the preparation work, the better the results. KNN algorithm has many improved versions. In terms of classification efficiency, it can pre-reduce sample attributes, deleting those that have little impact on classification results, quickly arriving at the category of the sample to be classified.
In terms of classification effectiveness, using a weighting method, increasing the weight of neighbors that are close to the sample can enhance classification performance.
To reduce computational complexity, we can decrease the size of the training set, using clustering to take the centroids generated as new training samples.
Optimizing similarity measures, using Euclidean distance to calculate similarity, this distance measurement standard makes the KNN algorithm very sensitive to noisy features. To modify the traditional KNN algorithm’s flaw of treating features equally, we can assign different weights to features in the distance formula used for measuring similarity, with weights generally set according to the role of each feature in classification. etc.
In conclusion, the KNN algorithm is a very useful and intuitive machine learning algorithm that plays a key role in many applications, such as dating sites, game matching systems, and intelligent recognition. This article mainly serves as an introduction, and more content related to machine learning and data mining will be updated in the future. Your feedback is welcome.
Genetic Division Zhang Qiaoshi | Copywriter
Hu Yuxiao | Editor
Image sources from the internet, please delete if infringed.