
Click on the above “Beginner’s Guide to Vision“, select to add “Starred” or “Pinned“
Important content delivered first-hand
What is it useful for?
Depth maps have a wide range of applications in computer vision, such as foreground-background segmentation (used for background blur, beautification, re-focusing, etc.), 3D reconstruction (used for robot navigation, 3D printing, visual effects entertainment, etc.). Currently, the fastest way to obtain depth maps directly is by using depth cameras. The principles of obtaining depth maps with different depth cameras can be found in: “Unveiling the Principles of Depth Cameras–Time of Flight (TOF)”, “Unveiling the Principles of Depth Cameras–Bilateral Stereo Vision”, “Unveiling the Principles of Depth Cameras–Structured Light (iPhone X Notch Principle)”.
However, many times due to hardware limitations, we cannot obtain depth maps through depth cameras. We can only use monocular cameras to indirectly calculate depth maps through relevant algorithms. A well-known method is Structure from Motion, meaning we need to move (usually a significant movement) the monocular camera to obtain multiple images from different angles to indirectly get the depth map.
Obtaining depth maps from small motion is one clever method to indirectly obtain depth maps using a monocular camera. This method utilizes very small movements to calculate the depth map. The purpose of this “very small movement” is to obtain the depth map during a time that the user does not notice (for example, a slight movement when a smartphone user is looking for the best shooting position, or the preview time before the user presses the shutter while holding the camera, or similar to live photos, etc.). If this method can achieve high-quality depth maps, it can somewhat replace the functionality of depth cameras based on RGB bilateral stereo vision (such as mobile dual cameras, for which the introduction can be found in the series of articles “Why Do Dual-Camera Phones Exist?”).
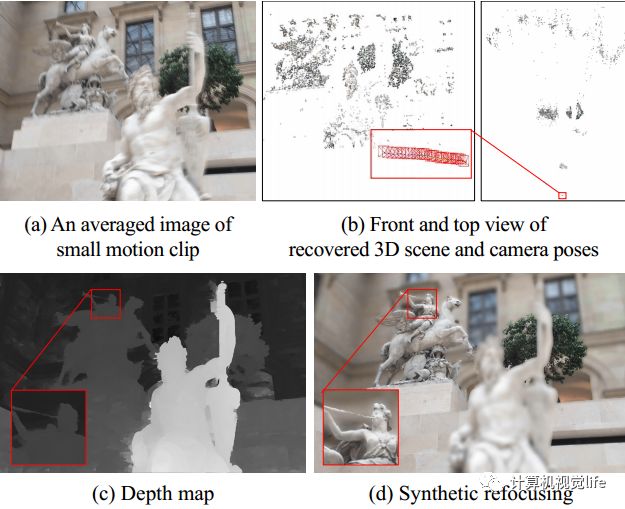
Next, let’s introduce an application of this technology. As shown in the figure below, (a) is the average overlay image of all frames in an input micro-motion video, where the motion is indeed very small. (c) is the depth map calculated by the algorithm, and from the enlarged details, the edges are still very sharp. (d) is the effect of re-focusing using the obtained depth map. We see that the subject is relatively clear, while the objects in the depth of field in front of and behind the subject are blurred.
What is the principle?
One highlight of this article is that it can estimate the depth map and the intrinsic and extrinsic parameters of an uncalibrated camera simultaneously. The general process is as follows:
1. Use the first frame as the reference frame, detect the Harris corners of the current frame and the reference frame, and match feature points using the KLT method.
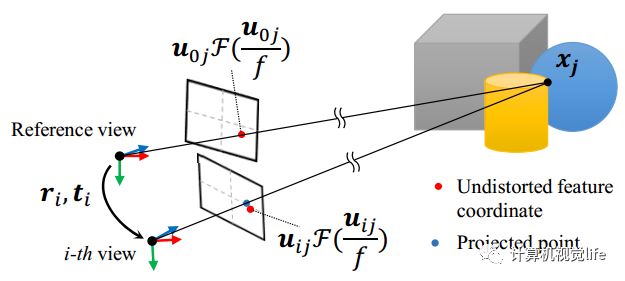
2. First, assume initial camera intrinsic and distortion parameters, use the bundle adjustment method to minimize the reprojection error, and iteratively obtain the camera’s intrinsic and extrinsic parameters, as well as the 3D spatial points corresponding to the feature points. The principle schematic diagram is shown below. Uij is the distorted coordinates of the j-th feature point in the i-th image relative to the image center, and the red points are their undistorted coordinates. The blue points are the reprojection coordinates. The goal is to minimize the positional error between the red and blue points in the i-th frame.
3. Use the obtained intrinsic and extrinsic parameters to perform dense stereo matching using a plane sweeping method, and adopt a winner-takes-all strategy to obtain a rough depth map. Small motion has the following advantages: due to the short time, small movement, and small change in field of view, it can be approximately assumed that the grayscale values of all frames remain unchanged during that time period. This assumption is crucial for reliable dense pixel matching.
4. Use the color image as a guidance image to refine the depth map. The process of obtaining the depth map is as follows:
(a) Use the winner-takes-all strategy to obtain a rough depth map; (b) Remove unreliable depth values; (c) The result after refining the depth map; (d) The reference image.

The pseudocode flowchart of the algorithm is shown below:

How effective is it?
The test results of the algorithm are shown in the figure below. The left side of the figure shows the average image of a series of small motion continuous images taken for 1 second with an iPhone 6, from which it can be seen that the motion is very small. The right side shows the corresponding depth map output by the algorithm.

The comparison of the re-focusing effects of this algorithm and other algorithms is shown in the figure below. It can be seen that this algorithm can maintain relatively sharp edges while blurring the background.

Although the algorithm is designed for cases of small motion, if the motion is particularly small, the estimated camera pose will be very unstable. Additionally, if the image edges lack effective feature points, it will lead to inaccurate estimation of radial distortion parameters. These situations may cause significant errors in the depth map.
This algorithm is only suitable for static scenes; if there are rapidly moving objects, this algorithm will fail. Additionally, it should be noted that the depth map estimated by this algorithm is relative depth.
Running time:
This algorithm was tested on a personal desktop computer. Computer configuration: Intel i7-4970K 4.0Ghz CPU, 16GB RAM. For a resolution of 1280×720 and a 30-frame micro-motion video, this algorithm (not optimized) takes 1 minute to complete feature extraction, tracking, and bundle adjustment. The dense stereo matching phase takes 10 minutes.
What reference materials are there?
The article corresponding to this algorithm:
Ha H, Im S, Park J, et al. High-Quality Depth from Uncalibrated Small Motion Clip[C]// Computer Vision and Pattern Recognition. IEEE, 2016:5413-5421.
Source code:
https://github.com/hyowonha/DfUSMC
Optimized and accelerated version of the above paper:
Monocular Depth from Small Motion Video Accelerated, 2017 International Conference on 3D Vision
Good news!
The Beginner's Guide to Vision knowledge community
is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Beginner's Guide to Vision" public account to download the first Chinese version of the OpenCV extension module tutorial available online, covering over twenty chapters including extension module installation, SFM algorithm, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of the "Beginner's Guide to Vision" public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the background of the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV for advanced learning of OpenCV.
Group discussion
Welcome to join the reader group of the public account to exchange ideas with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat ID below to join the group, noting: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, you will not be approved. After successful addition, you will be invited to enter the relevant WeChat group based on your research direction. Please do not send advertisements in the group, or you will be removed from the group. Thank you for your understanding~