


Intelligent synchronization model and tools for video lip sync achieve innovative upgrades
The generative AI integration platform LTX Studio can intelligently realize film visualization previews
The AI tool LAVE utilizes large language models (LLM) for intelligent video editing
【Highlight】
In 2021, the globally popular Hollywood film “Free Guy” decided to change the actor’s dialogue after filming was completed. The creative team used deep neural network rendering combined with traditional visual effects production technology to modify the character’s facial movements in just 5 days to match the dialogue. Today, with the launch of generative AI large models for audio and video both domestically and internationally, it is now possible to generate matching videos from static images and audio in just a few seconds.
Effectively, reasonably, and feasibly applying existing AI model tools in film production practices is a key aspect of enhancing the intelligence level of the film industry. Currently, there is a global trend to utilize open-source models and production tools to build integrated application platforms, relying on AI agents to complete film production tasks, exploring the vertical application of existing language, visual, sound, and other AI large models in film visual previews, editing, visual effects, sound production, and other process links, seeking points of convergence between AI technology and film demand, thereby forming a new productive force in the film industry.
01
Intelligent synchronization model and tools for video lip sync achieve innovative upgrades
Recently, Alibaba launched the EMO (Emote Portrait Alive) video generation framework, which can intelligently generate videos of characters speaking or singing from a static image and an audio clip, capturing comprehensive dynamic changes in the character’s head and achieving natural transitions of expressions, facial features, and postures that match the audio. The video length corresponds to the length of the audio, and the character’s features remain consistent; currently, the longest generated case is about 1 minute and 30 seconds.

▲Using Sora to generate characters as input images to create videos
EMO adopts a UNet architecture similar to the Stable Diffusion image generation model, with training divided into three phases: image pre-training, video training, and speed layer training. In the image pre-training phase, the network is trained with single-frame images as input; in the video training phase, a time module and audio layer are introduced to process consecutive frames; the speed layer training focuses on adjusting the speed and frequency of the character’s head movements. The training data is sourced from widely available Talking Head videos, adjusted and cropped to a resolution of 512×512 for training.

▲Character: Audrey Kathleen Hepburn-Raston, voice source: interview clips
At the same time, the AI video generation tool Pika has launched a lip sync function that can achieve mouth animation synchronization with audio in generated videos, with audio technology support provided by AI voice cloning company ElevenLabs. Users can choose to directly input text to generate audio or upload their own audio, deciding both the content of what the video character says and customizing the speaking voice style.
Currently, this function can only generate lip sync video segments of up to 3 seconds in length and can only simulate lip movements.
02
The Generative AI Integration Platform LTX Studio Can Intelligently Achieve Film Visualization Previews
Recently, AI technology company Lightricks announced the launch of the generative AI film production platform LTX Studio, aimed at helping creators quickly visualize stories.
LTX Studio is a content generation platform that integrates a series of generative open-source AI models and tools, capable of creating videos, music, sound effects, and dialogues through text prompts. LTX Studio integrates these functions into a single interface, allowing users to complete the entire audio and video content creation process in one place.
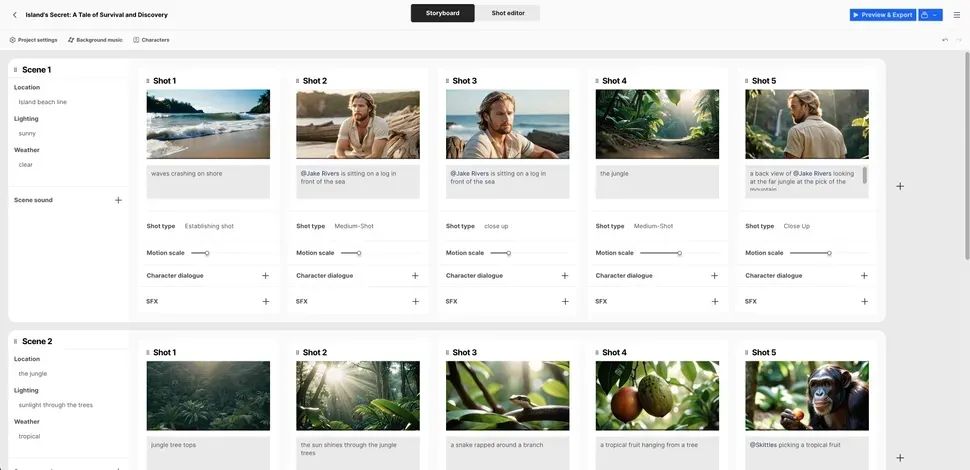
▲LTX Studio interface
Users input their creative intentions in text form, and LTX Studio first generates a set of scenes (Scene) containing photos, styles, names, and sounds based on the text prompts. Each scene contains multiple shots (Shot). Users can customize the style, weather, location of each scene, adjust the angles, characters, scene consistency, camera movement, lighting, etc., and can change elements within, such as changing characters in the generated scene or altering the color of vehicles in the scene. After refining the storyline and editing the shots, users can preview and export the video for sharing and feedback.
The generative case for LTX Studio is approximately 25 seconds long, with relatively simple camera movements, mostly consisting of camera pans, and character expressions appearing stiff with limited movement and minimal interaction with the surrounding environment. Compared to the previously released Sora generated videos by OpenAI, there is still a significant gap, but it meets the requirements for simple virtual previews.
Given the current functionalities and effects, LTX Studio allows users to flexibly adjust and preview film effects, which can be used by filmmakers to quickly create conceptual stories, reducing production costs and improving efficiency.
Lightricks previously developed image editing software Photoleap, video editing software Videoleap, and portrait retouching software Facetune. The launch of LTX Studio is a further enhancement of existing creative tools with generative AI technology.
03
The AI Tool LAVE Uses Large Language Models (LLM) for Intelligent Video Editing
Researchers from the University of Toronto, Meta (Reality Labs Research), and the University of California San Diego recently jointly proposed the video editing tool LAVE, utilizing the powerful language capabilities of large language models (LLM) for video editing.
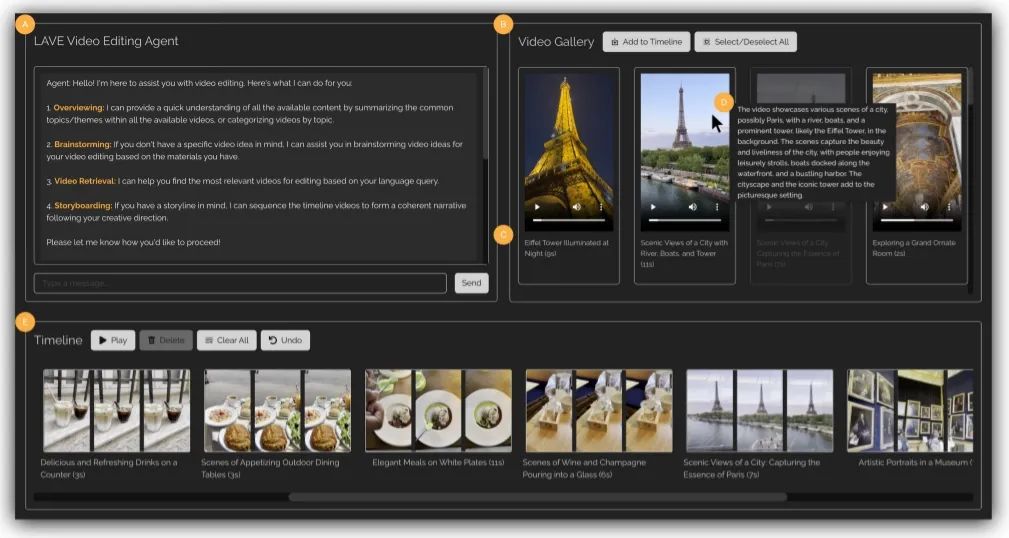
LAVE introduces an LLM-based planning and execution agent that can interpret user language commands, plan, and execute related operations to achieve editing goals. The agent can provide conceptual assistance, such as creative brainstorming and video material overviews, as well as operational help, including semantic video retrieval, storyboarding, and editing modifications.
To ensure smooth operation of these agents, LAVE uses a visual language model (VLM) to automatically generate language descriptions of video visual effects, enabling the LLM to understand video content and assist users in editing with their language capabilities. Additionally, LAVE offers two video editing interaction modes: agent assistance and direct operation. This dual mode provides users with flexibility while allowing for on-demand improvements to agent operations.
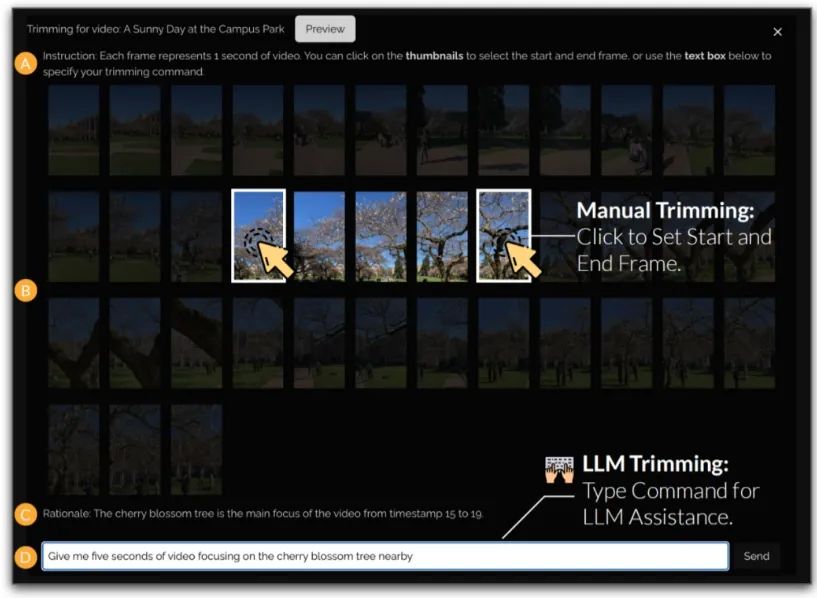
The user interface of LAVE consists of three main components: a language-enhanced video library displaying video clips with automatically generated language descriptions, a video editing timeline containing the main timeline for editing, and a video editing agent that allows users to interact with the conversational agent for assistance.
When users interact with the agent, message records are displayed in the chat interface. When performing related operations, the agent makes changes to the video library and editing timeline. Additionally, users can directly interact with the video library and timeline using the cursor, similar to a traditional editing interface.
(All images in this issue are sourced from the internet)

Edited by丨Zhang Xue
Proofread by丨Wang Jian
Reviewed by丨Wang Cui
Final review丨Liu Da


Don’t forget to like + follow!
