Author: louwill
From: Deep Learning Notes
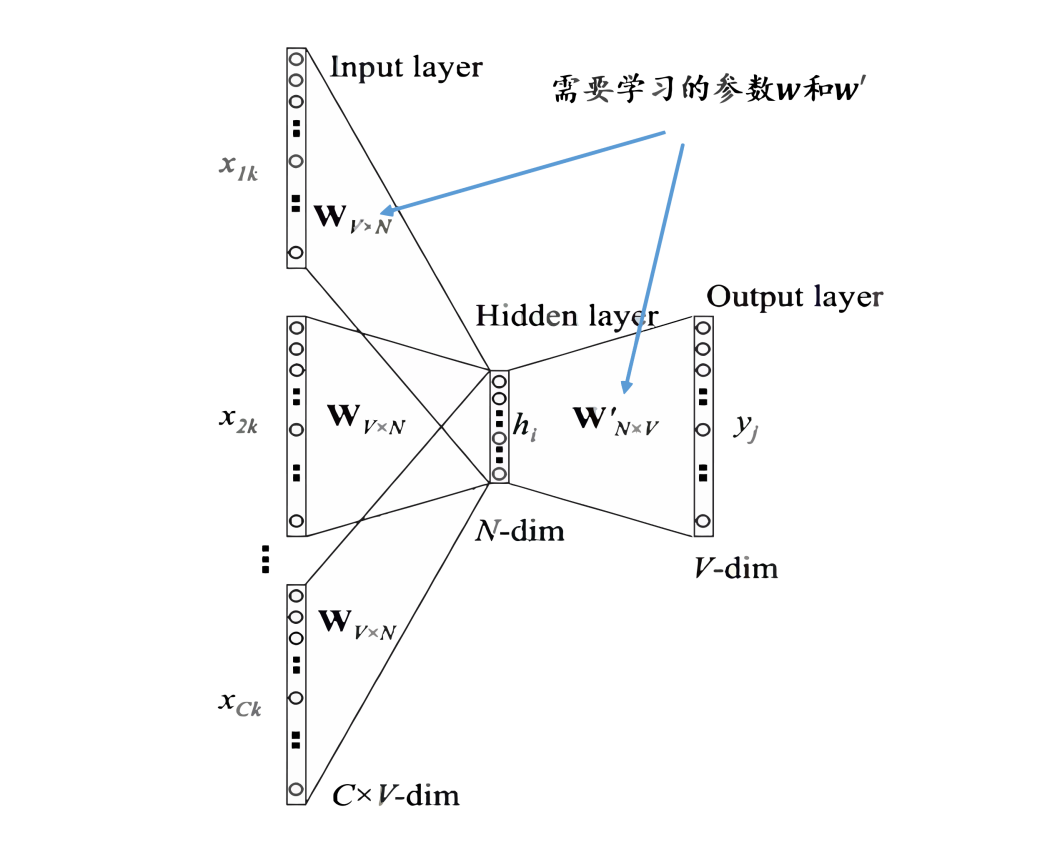
-
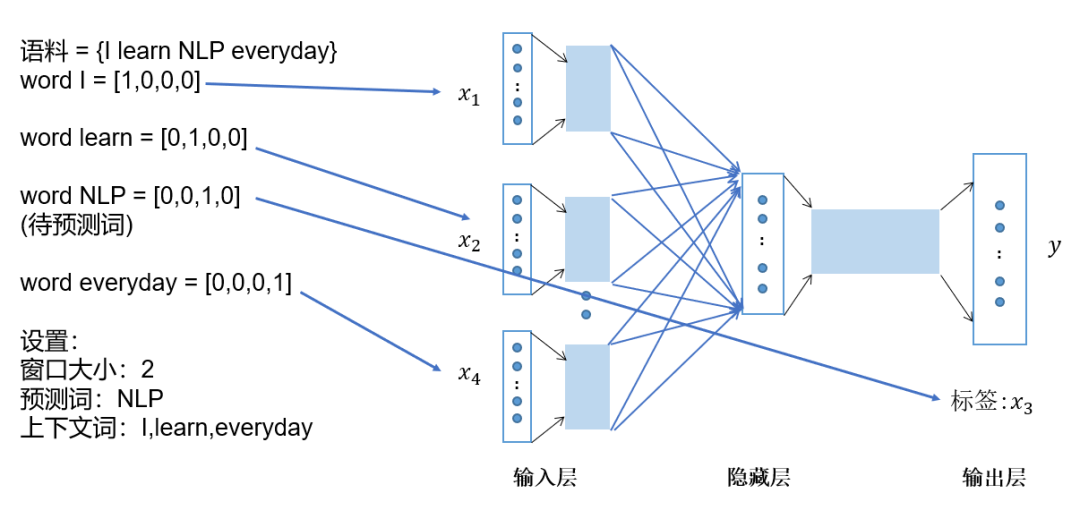
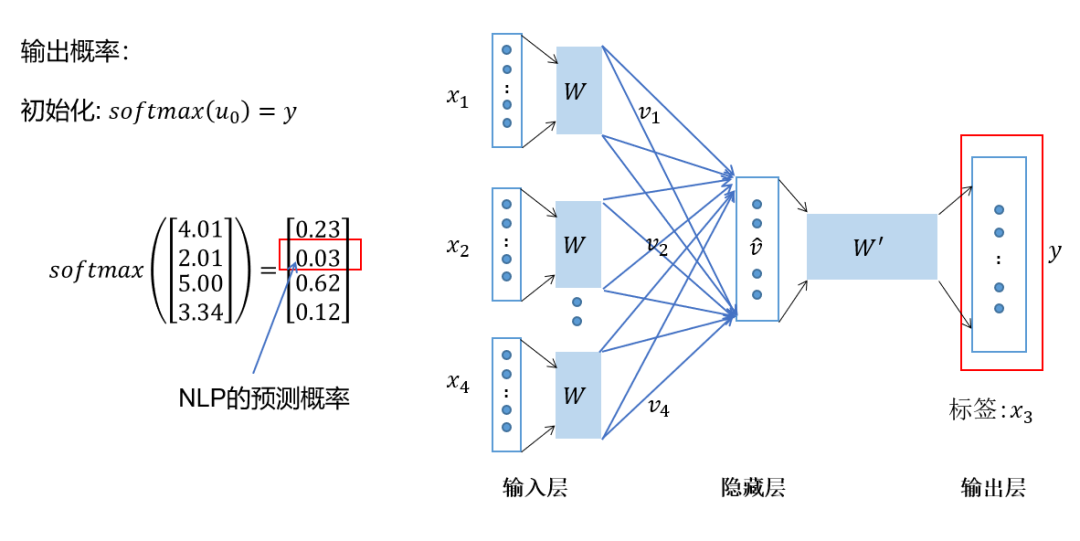
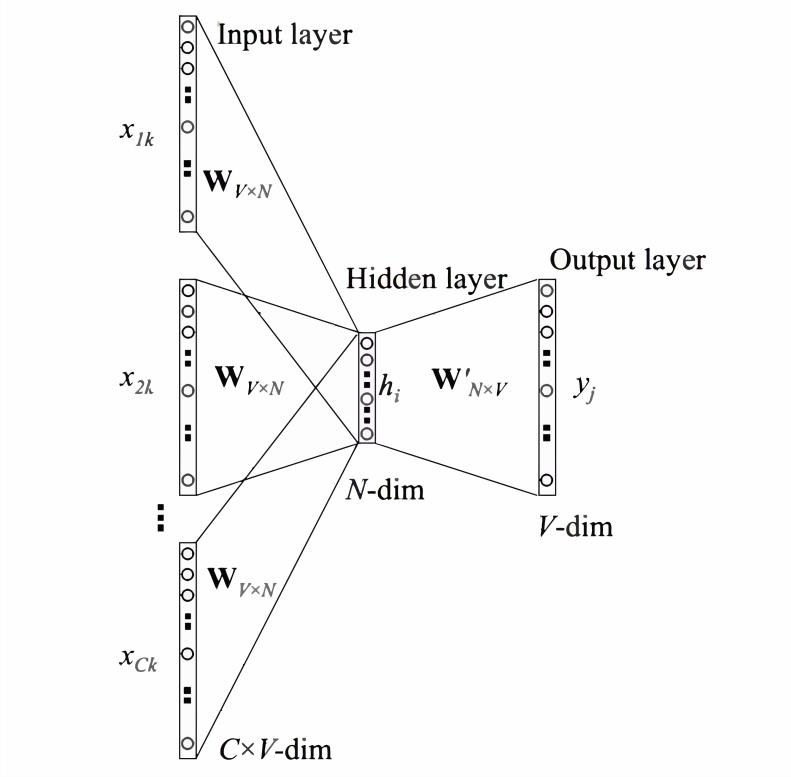
Represent the context words as one-hot vectors as the model input, where the dimension of the vocabulary is the number of context words; -
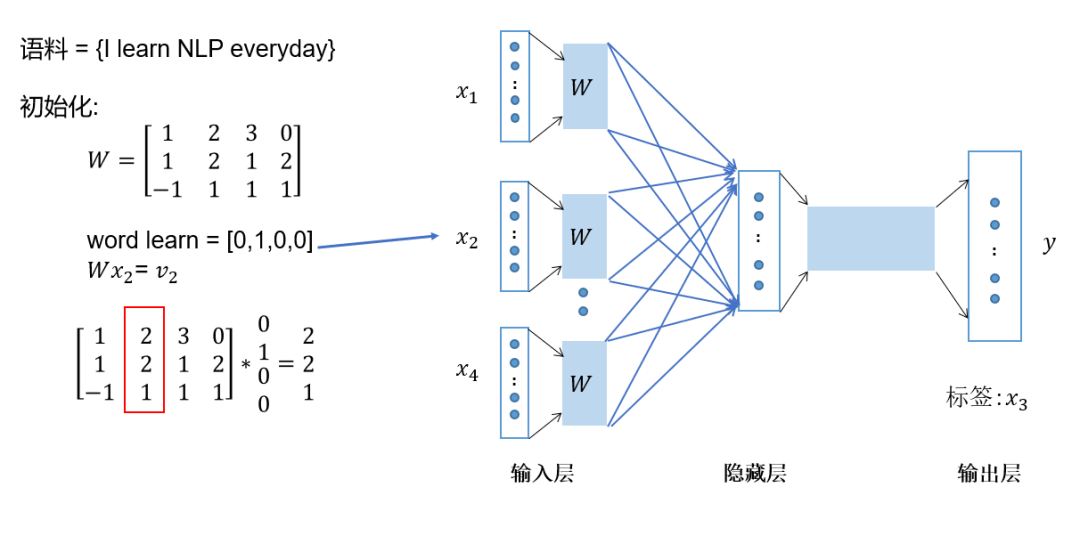
Then multiply the one-hot vectors of all context words by the shared input weight matrix; -
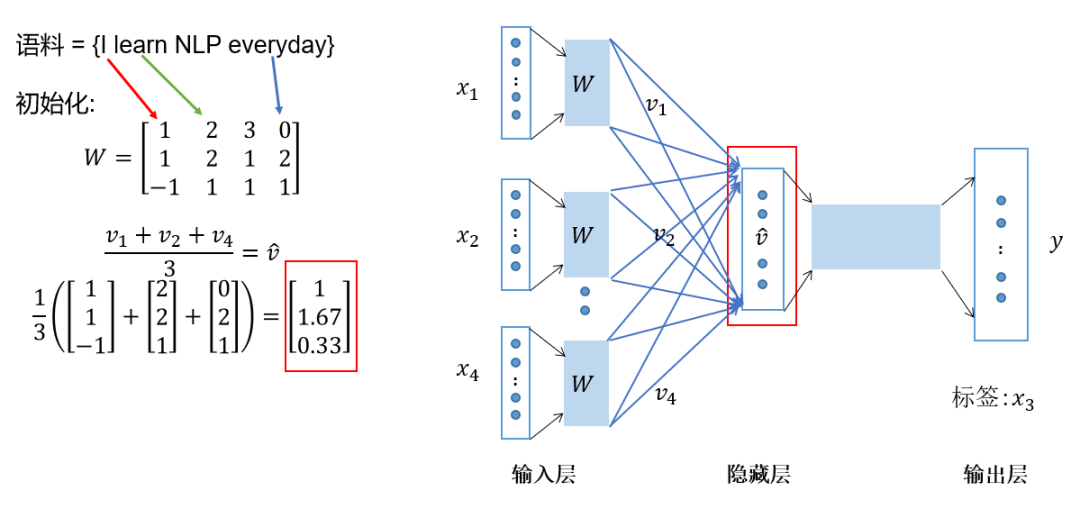
Average the vectors obtained in the previous step to form the hidden layer vector; -
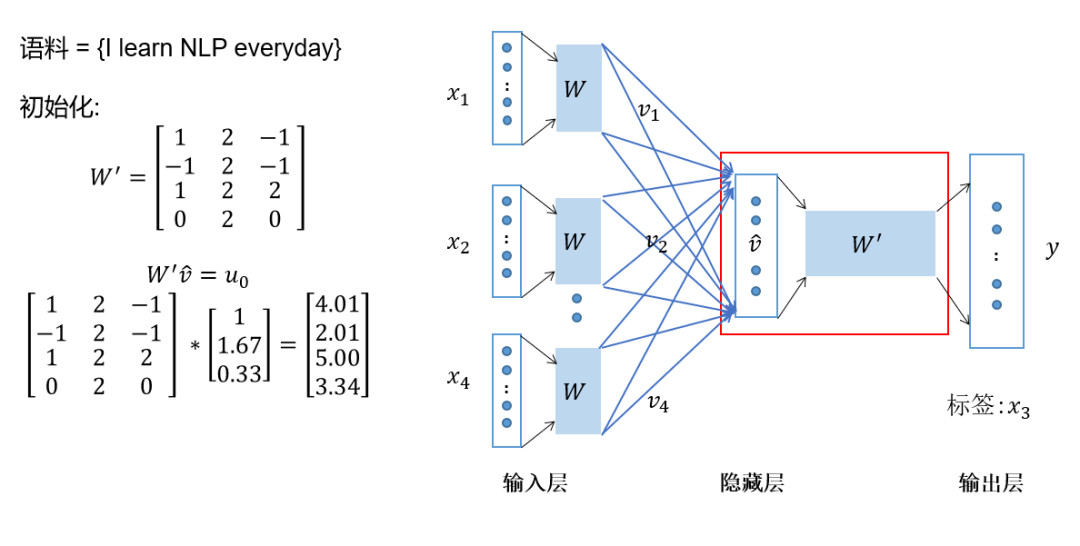
Multiply the hidden layer vector by the shared output weight matrix; -
Apply softmax activation to the computed vector to obtain a probability distribution of the dimension, and take the index with the highest probability as the predicted target word.