
Click the image below to get the knowledge card

Reading Difficulty: ★★☆☆☆
Skill Requirements: Machine Learning, Python, Tokenization, Data Visualization
Word Count: 1500 words
Reading Time: 6 minutes
This article combines the recently popular TV series “Yanxi Palace” to analyze the character relationships from a data perspective. By collecting relevant novels, scripts, character introductions, etc., from the internet, we train a Word2Vec deep learning model to construct a character relationship graph and display it visually.
1
Graph
First, let’s take a look at the character relationship graph for the entire series:

The larger the node and the closer it is to the center, the more complex its relationships with other characters in the series..
We can zoom in on the graph for a closer look:
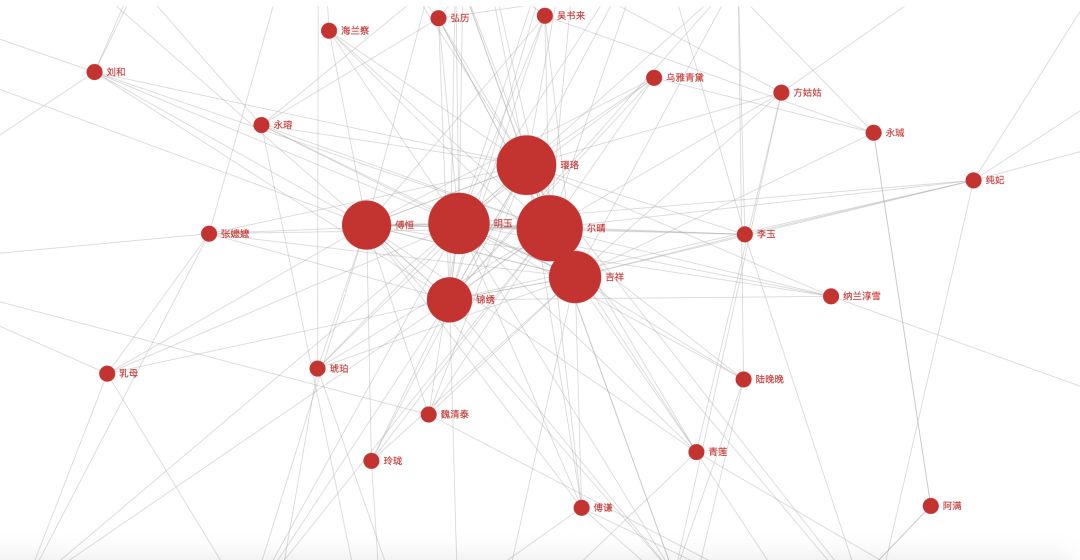
We can observe that:
Ying Luo, Er Qing, Ji Xiang, Ming Yu, Jin Xiu, Fu Heng
These six characters are the key to driving the plot of the entire series. From this perspective, “Yanxi Palace” is a story about multiple palace maids and a guard.
This graph also shows the correlation between each character and others.
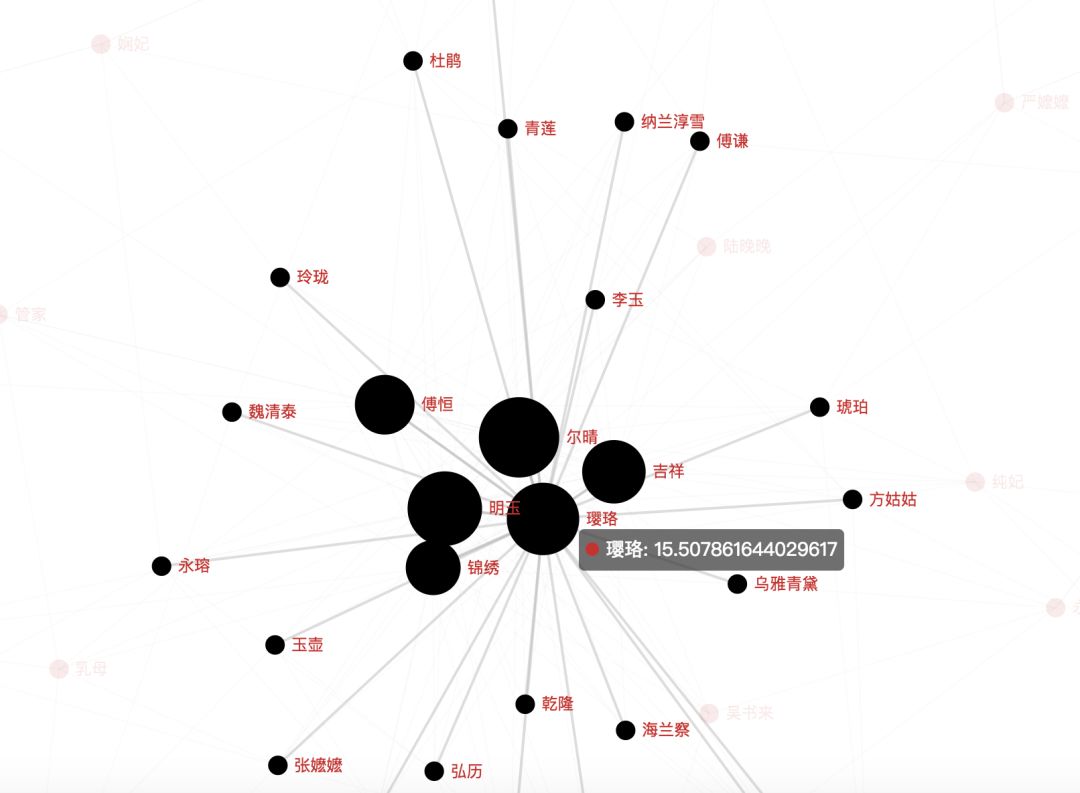
Next, let’s look at the relationship between Qianlong and other characters:

Of course, we can also query using code:
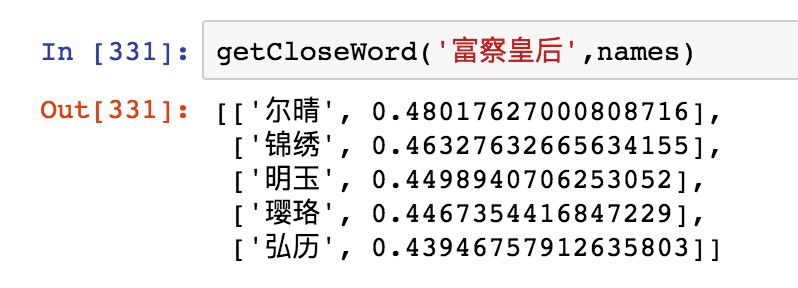
Graph experience address:
https://shadowcz007.github.io/text2kg/
How was the graph above created?
2
Construction Idea
Required data:
Yanxi Palace novel
Yanxi Palace script
Yanxi Palace character names
Algorithm:
Word2Vec
Frontend:
ECharts
Development Environment:
Python
When processing data, we need to remove punctuation marks and some unnecessary words (e.g., chapter indicators). Using Jieba Tokenization, we perform a round of tokenization and remove characters with a length of 1 (e.g., various modal particles, quantifiers, etc.).
Finally, the data is processed into:

After preparing the data, we mainly use Gensim to train the Word2Vec model. Gensim is a Python NLP package that wraps Google’s C language version of Word2Vec. Installing Gensim is very easy, just use “pip install gensim”.
3
Word2Vec
Word2Vec, also known as word embeddings, is a method for converting words in natural language into dense vectors that computers can understand. The relationship of word conversion to vectors is shown in the diagram below:

Word2Vec can learn the relationships between words, based on the principle that related words in text tend to appear together frequently. Let’s look at the diagram:
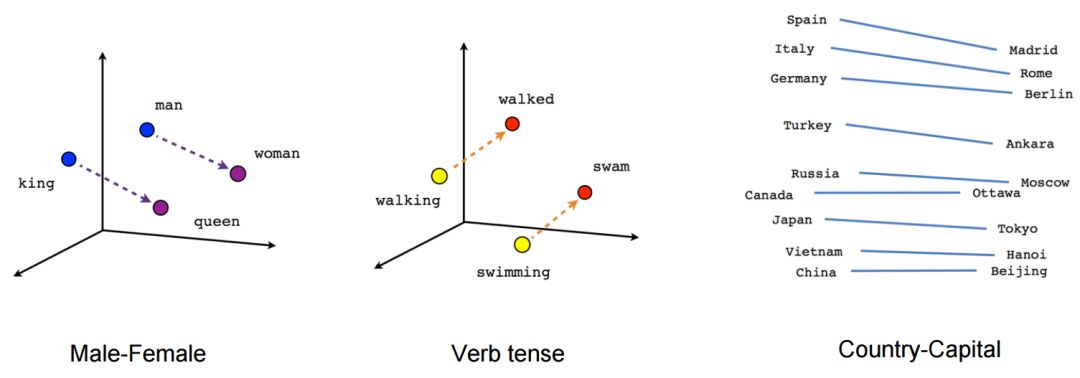
From the diagram, we can see that Word2Vec can learn various interesting relationships. For example, the word “king” often appears together with “queen”, while “man” frequently appears with “woman”.
Through Word2Vec analysis, we can find that the vector representing “king” can be related to the vectors representing “queen”, “man”, and “woman” as follows:
king = queen – woman + man
Through the conversion from words to vectors, we can perform various calculations based on the vectors.
In addition to applications in linguistics, it can also be applied in chemistry, for example, Atom2Vec, which can learn to differentiate between different atoms based on the names of compounds formed from combinations of different elements (such as NaCl, KCl, H2O), thus discovering potential new compounds. This program borrows simple concepts from natural language processing:
The characteristics of a word can be derived from the other words that appear around it; similarly, chemical elements can be clustered based on their chemical environment.
From the analysis of this data, AI programs can discover that potassium and sodium have similar properties because they can both combine with halogens to form compounds, “just like king and queen are similar, potassium and sodium are also similar.”.
The trained model can input compounds composed of different atoms for various vector calculations, helping us discover new compounds.
4
Gensim Word2Vec Implementation
You can start training the model with a simple line of code:
model = Word2Vec(line_sent, size=100, window=5, min_count=1)After training, you can find the most similar words to a given word vector:
model.wv.similar_by_word('璎珞', topn=10)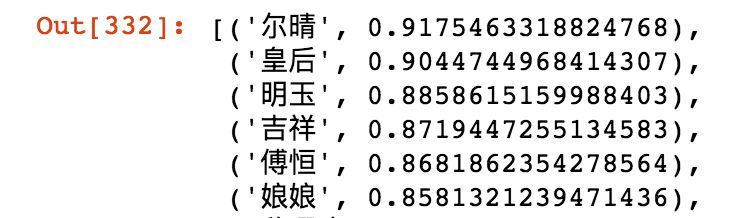
You can also check the similarity between two word vectors. Here are the similarity scores for two groups of characters in the series:
print(model.wv.similarity('璎珞', '尔晴'))
print(model.wv.similarity('皇后', '弘历'))Similarity:
0.9175463897110617
0.8206695311318175
Or find the odd one out among different classes of words. Here’s a classification of characters:
model.wv.doesnt_match("璎珞 皇后 弘历 傅恒 尔晴".split())Result: 弘历
From the result, we see that 弘历 is the emperor, thus not belonging to this group.
Let’s look at another set:
model.wv.doesnt_match("璎珞 皇后 傅恒 尔晴".split())Result: 傅恒
傅恒 is male, and thus also different from these characters.
That concludes the content. Word2Vec has many other interesting applications, such as analyzing the personalities of each character to find descriptive words; applying it to design language mining to extract characteristics of a design style; or analyzing the style of a certain article to enable machines to assist us in writing creation, etc.
September
MixLab Offline Event Recommendation:
Personal Homepage/Card in the Intelligent Era
On September 1st, we are preparing a workshop to help students with no programming background master programming and design skills in just one day.Course Features: Face-to-face communication, efficient learning, and online guidance.
Click on “Read the Original Text” at the bottom to register
——————-——————-
MixLab is a future-oriented laboratory that advocates the concept of “cross-border innovation and open growth”. By not setting boundaries, innovation has more possibilities; because of its openness and inclusiveness, every cross-border participant can grow fully here. Therefore, MixLab’s Chinese name is “Boundaryless Community”.
MixLab promotes a decentralized model, allowing cross-border participants in the community to help each other and grow together.
Here, we do not have absolute elites; we believe that anyone can become elite as long as they continuously break through their cognitive boundaries. Because even just one day of cross-border experience can inspire infinite possibilities. We believe that innovators are those who can effectively merge values from different fields. Here, we do not cultivate technical experts; we cultivate innovative spirit and innovators. The common vision of this community is to make every ordinary person an innovation driver.
——Cross-border, Open, Mutual Assistance, Learning, Thinking, Innovation
MixLab looks forward to your joining!

Ways to show appreciation include clicking on ads~