In 2019, the global voice interaction market reached $1.3 billion, and it is expected to grow to $6.9 billion by 2025, with widespread applications in smart home, in-car voice, intelligent customer service, and other industries and scenarios. The author has been engaged in voice interaction products for over a year, summarizing the concept definition, advantages and disadvantages, applicable scenarios and products, and future development of voice interaction.
1 What Is Voice Interaction?
Voice User Interface (VUI) refers to the transmission of information between humans and devices through natural speech. A complete voice interaction process involves ASR → NLP → Skill → TTS:
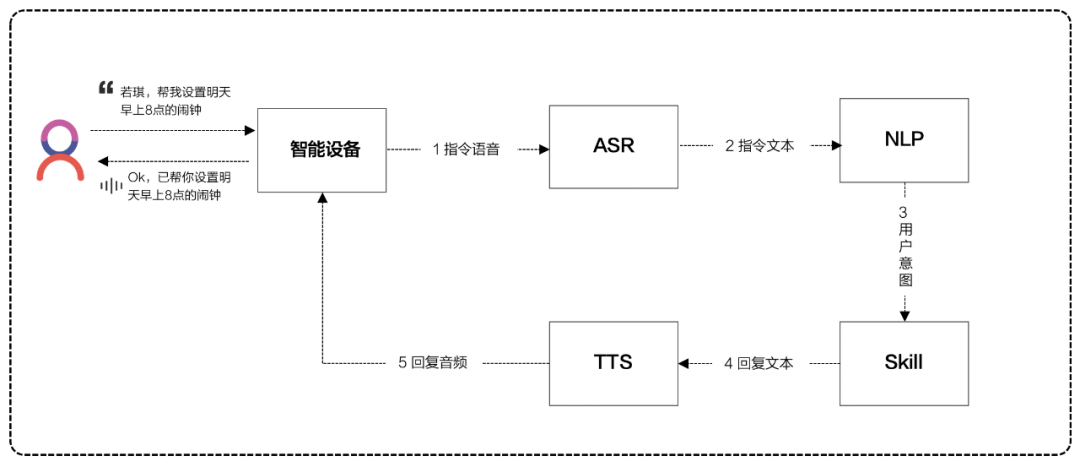
ASR is used to analyze acoustic speech and obtain corresponding text or pinyin information. Voice recognition systems generally consist of two stages: training and decoding. Training involves training a mathematical model using a large amount of labeled speech data and training a language model using a lot of labeled text data; decoding involves recognizing speech data into text using acoustic and language models. The acoustic model can be understood as modeling what occurs, converting speech input into acoustic representations, more accurately, giving the probability that the speech belongs to a certain acoustic symbol. The role of the language model can be simply understood as resolving homograph issues, finding the string sequence with the highest probability from the candidate text sequences after the acoustic model provides the pronunciation sequence.
NLP is used to convert user instructions into structured, machine-understandable language. The working logic of NLP is: breaking down user instructions into Domain (field) → Intent (intention) → Slot (slot) levels. For example, in the instruction “Help me set an alarm for 8 AM tomorrow”: the domain triggered is “alarm”, the intent is “create alarm”, and the slot is “tomorrow 8 AM”. This way, the user’s intention is broken down into language that machines can process.
Skill is essentially an app in the AI era. The role of Skill is to handle user intentions defined by NLP and provide feedback that meets user expectations.
TTS refers to speech synthesis, converting text into speech, allowing machines to speak. There are generally two methods used in the TTS industry: concatenation and parametric methods.
The concatenation method selects the required basic phonetic units from a large amount of pre-recorded speech. The advantage is that the naturalness of the speech is very good, while the disadvantage is that the cost is too high, often exceeding a million. The parametric method refers to using statistical models to generate speech parameters and convert them into waveforms. The advantage is low cost, generally ranging from 200,000 to 600,000, while the disadvantage is that the naturalness of pronunciation is not as good as the concatenation method. However, as models continue to be optimized, the performance of the parametric method has improved significantly, leading to its increasing use in the industry.

2 What Are the Advantages and Disadvantages of Voice Interaction?
PART1: Advantages of Voice Interaction
Advantage 1: High Information Transfer Efficiency
Research results from Baidu’s voice open platform indicate that compared to traditional keyboard input, voice input is superior in speed and accuracy. The speed of voice input for English and Mandarin is 3.24 times and 3.21 times that of traditional input methods, respectively, and information transfer efficiency can be further broken down into four categories:
-
Efficient Retrieval: For complex input words, especially in scenarios where input methods are inconvenient, voice interaction is more efficient. For instance, searching for movies in a television scenario.
-
Convenience Across Spaces: Far-field voice interaction can communicate across 3-5 meters, making it more efficient for operations that require cross-space actions, such as smart home control.
-
Convenience Across Scenarios: A potential benefit of voice interaction is its ability to automatically determine the intent scenario based on spoken content, making it more efficient in scenarios that require frequent cross-scenario interactions.
-
Support for Combined Commands: Voice interaction can issue multiple commands at once, executing them separately, making it more efficient in scenarios that require simultaneous intent transmission. For example, if you want to watch a movie tonight, you can say: “Play a movie by Andy Lau that has a rating of four stars or above and is free to watch.”
Advantage 2: Freeing Hands and Eyes
Through voice interaction, users can free their hands and eyes to handle other tasks, increasing efficiency in scenarios requiring multi-sensory collaboration. For example, in-car scenarios can use voice to play music, while doctors can record medical records while discussing patient conditions.
Advantage 3: Low Entry Barrier
-
Friendly for Non-Literate Users: Humans first had speech before writing; everyone can speak, but some cannot write. For the elderly, children, and visually impaired, who cannot use text interaction, voice interaction offers significant convenience.
-
Low Learning Cost: Voice interaction is more natural; in non-complex scenarios, it is easier to use than interface interaction, resulting in a lower learning curve.
Advantage 4: Conveying Acoustic Information
-
Voiceprint Identification: Voiceprints can be used for identity verification, allowing for identity judgment while issuing commands, increasing efficiency. Additionally, voice can convey information such as gender, age, and emotion.
-
Voice Conveys Emotion: Voice interaction can convey emotions, making it a good choice in scenarios requiring emotional appeal.
PART2: Disadvantages of Voice Interaction
Disadvantage 1: Low Information Reception Efficiency
Voice output is linear; when someone is speaking, you may have to wait until they finish to understand, unlike text which allows you to skip reading. Voice interaction also increases the user’s memory burden, especially when facing multiple choices with lengthy content. Therefore, it cannot output a lot of content simultaneously, and in terms of accepting information and multi-choice interactions, visual methods have a greater advantage. In summary, voice interaction is more effective for unidirectional commands, while bidirectional interaction is less effective.
Disadvantage 2: Reduced Voice Recognition Accuracy in Noisy Environments
Voice recognition requires clear identification of human voices, separating them from environmental sounds and other voices. Noisy environments make it very difficult to extract human voices, especially for far-field voice interaction, where noise issues are more pronounced. Currently, the industry commonly uses microphone array hardware and related algorithms to optimize this issue, but it cannot be completely resolved. For example, the accuracy of voice recognition in a quiet far-field environment can reach 95%, but in noisy environments, it may only exceed 80%. However, with technological advancements, the accuracy of far-field voice recognition in noisy environments is expected to gradually improve.
Disadvantage 3: Psychological Burden of Voice Interaction in Public Environments
Voice interaction carries a psychological barrier as users cannot preset or predict outcomes. In the same situation, different people may exhibit completely different behaviors and expectations. This poses significant challenges for designers and uncertainty for users. From a psychological perspective, not many people are willing to speak to machines, as they may receive emotionless or incorrect responses.
3 What Scenarios and Devices Are Suitable for Voice Interaction?
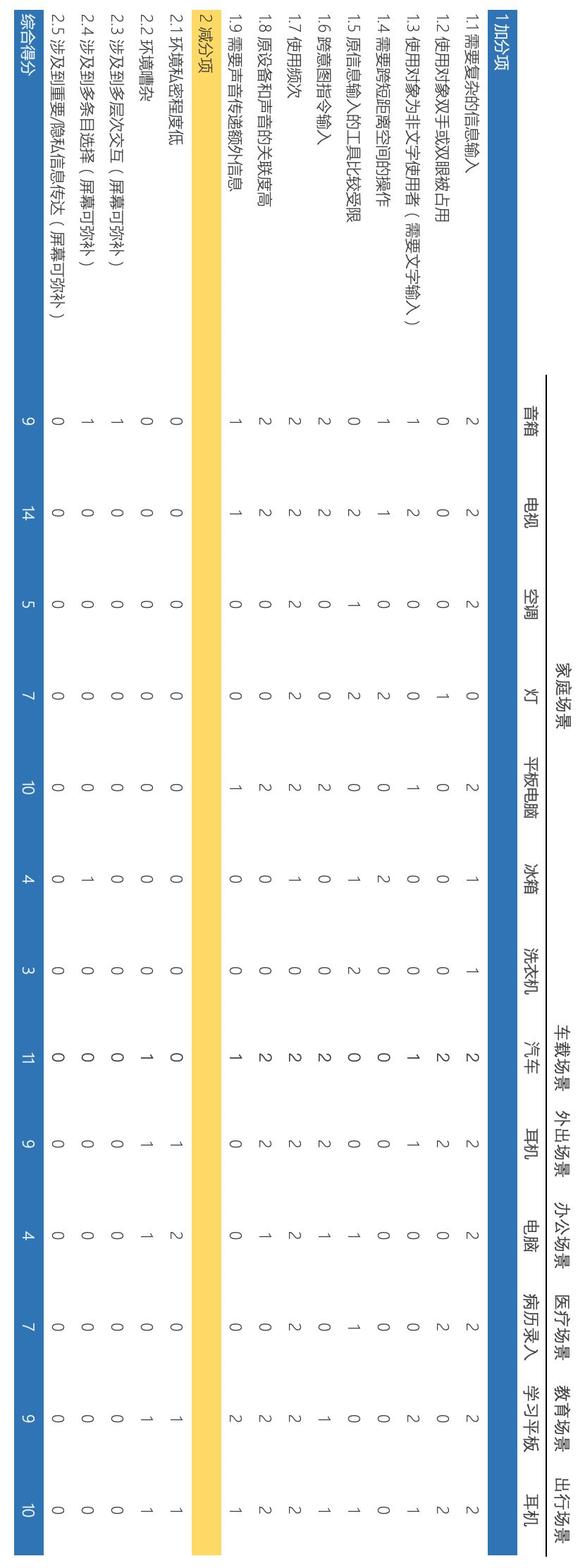
We determine which scenarios and devices are suitable for adding voice interaction based on the analysis of its advantages and disadvantages. We derive the following scoring items for positive and negative aspects. For simplicity, each item is given equal weight, and then a comprehensive score is calculated, categorizing applicability into high, medium, and low levels, corresponding to scores of 2, 1, and 0, respectively.
Principle 1: Each device type only considers its inherent functionality, not the additional functions that may arise from its entry nature. For instance, smart speakers have been assigned roles beyond just speaker functionalities, such as weather and smart home control. In the future, the voice entry point in homes will be distributed, and the role of smart speakers as life assistants will be separated.
Principle 2: When considering device functionality, potential future extended functionalities will also be taken into account, such as refrigerators supporting inquiries about their contents.
Positive Scoring Items:
-
Complex Information Input Required: If input commands cannot be exhaustively enumerated, the score is highest; if only simple input commands are needed, the score is lower.
-
Users’ Hands or Eyes Are Occupied
-
Users Are Non-Literate: If the user group includes many elderly, children, and visually impaired individuals, the score is high; otherwise, it is low.
-
Operations Require Cross-Short-Distance Actions: If there are physical buttons, the score is high; if remote control is possible, the score is next highest; if neither is available, no score is given.
-
Original Information Input Tools Are Limited: The convenience of input methods ranks as touchscreen > remote control > buttons.
-
Cross-Intent Command Input Required: If different intent commands need to be issued simultaneously or successively, the score is high; otherwise, it is low.
-
Frequency of Use: If it is used almost daily, the score is highest; if around three times a week, it is second highest; if less than once a week, no score is given.
-
Device’s Association with Sound: If the device itself plays multimedia content, the score is high; otherwise, no score is given.
-
Additional Information Needs to Be Conveyed via Sound: For example, voiceprints or pronunciation assessments.
Negative Scoring Items:
-
Low Privacy Level of Environment: For example, office scenarios.
-
Noisy Environment: For example, shopping mall scenarios.
-
Involves Multi-Level Interaction (Touchscreen Can Compensate): For example, ordering takeout.
-
Involves Multiple Selection Items (Touchscreen Can Compensate): For example, shopping.
-
Involves Transmission of Important/Private Information (Screen Can Compensate): For example, ATMs.
The following table shows the scores for various scenarios and devices suitable for voice interaction.
Home Scenarios
Home environments are relatively closed and private with low noise, making them ideal for implementing voice interaction.
01 Television: Set-top boxes are considered analogous to televisions. Televisions have high penetration rates and usage frequency, and their rich ecological content makes operations relatively complex. However, limited by the inefficient input method of remote controls, televisions become the most suitable devices for voice transformation. Nevertheless, due to high costs, the pace of transformation is relatively slow. However, the voice transformation of the next generation of televisions is undoubtedly an unstoppable trend.
02 Tablets: Currently popular smart speakers with screens are more appropriately referred to as voice tablets.
03 Speakers: Speakers have ignited the market due to their low cost (no screen or video resources required).
04 Lights: Although the commands are simple, their frequent operation and the need to get up to operate them increase the cross-space cost, resulting in a high demand for voice control of lighting. However, the most appropriate voice control for lights is local offline commands, meaning directly recognizing and controlling the lights through commands like “turn on the light” or “turn off the light” without needing to send the commands to the cloud for processing.
05 Air Conditioners: Due to their relatively high frequency of use and complex commands, air conditioners, like lights, have a certain necessity for voice control.
06 Refrigerators: Generally, there is no necessity for voice control unless the refrigerator’s functions are significantly expanded, such as adding a screen to serve as a television in the dining room, making its need for voice control similar to that of televisions.
07 Washing Machines: Generally, there is no necessity for voice control.
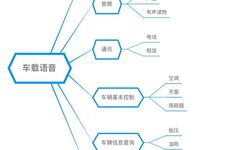
In-Car Scenarios
With the rise of connected vehicles and smart cars, more and more functions are being integrated into car systems. The plethora of functions and increasingly complex interfaces create competition for the driver’s attention, leading to new conflicts. The unique advantage of in-car voice technology is helping drivers reduce reliance on operating in-car devices, thereby increasing driving safety. In-car scenarios are relatively private, but the noise level is higher than in home scenarios, especially when windows are open. However, since hands and eyes are occupied while driving, voice interaction becomes the best choice for commands such as answering calls, opening and closing windows, playing music, and navigation, making driving safer and allowing for better focus on the road.
Common voice functions in cars include:
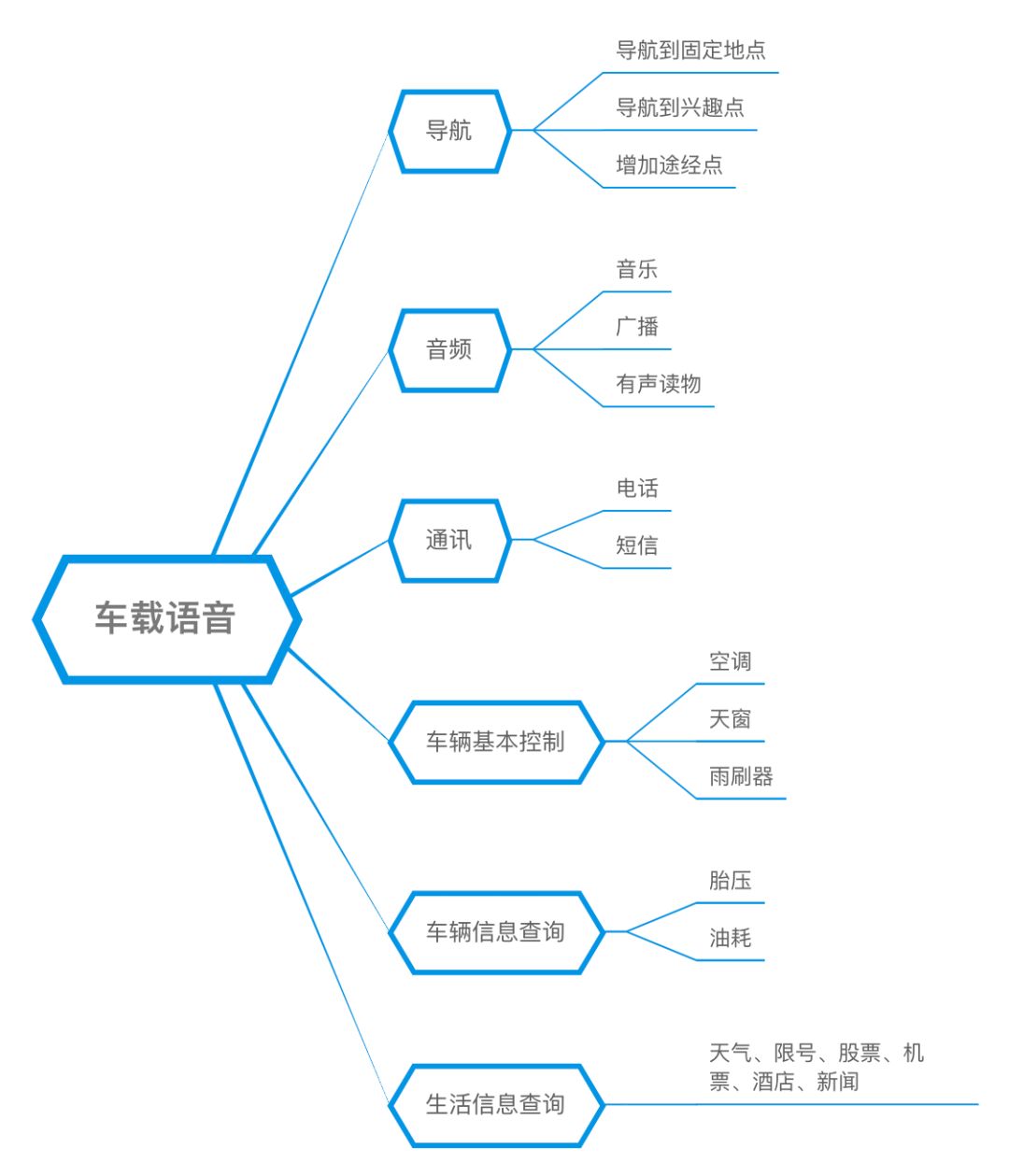
Medical Scenarios
Medical Record Entry: The application of voice recognition in medicine primarily focuses on directly converting speech into structured electronic medical records, facilitating easy access for doctors and significantly reducing their workload. It saves doctors time spent on handwriting medical records and can provide material evidence for doctor-patient disputes.
Voice recognition technology has been successfully utilized in departments such as radiology, pathology, and emergency rooms in hospitals, particularly in Western countries led by the United States. The proportion of clinical use of voice recognition for data entry has reached over 20%, significantly reducing the workload of doctors and improving efficiency, thus lowering the operational costs of hospitals. Medical business revenue accounts for 50% of the total revenue of Nuance, the largest voice technology company globally.
Enterprise Scenarios
Intelligent Customer Service: Intelligent customer service can be viewed in two parts: voice call centers and online customer service. In the customer service industry, after a user requests access, 80% of common problems are first answered by intelligent customer service robots, with the remaining 20% of complex issues handled by human expert customer service representatives. The entire process created by intelligent customer service robots has completely changed the labor structure and working methods of the customer service industry.
-
Currently, there are about 5 million full-time customer service representatives in China. Assuming an average annual salary of 60,000 RMB, plus hardware and infrastructure costs, the overall scale is about 400 billion RMB. With a replacement ratio of 40-50%, excluding basic infrastructure and budget cuts from clients, around 20-30 billion RMB will be left for intelligent customer service companies.
-
The impact of AI on the enterprise service market is not limited to customer service scenarios. As a bridge and entry point for communication between enterprises and users, intelligent customer service companies can extend to marketing, sales, and other important external enterprise service scenarios, promoting comprehensive intelligence in external services from perspectives such as interaction methods, process optimization, and data analysis, thereby releasing 10-20 billion RMB from the original marketing, sales, and other market scales.
-
In addition to replacing some human customer service representatives, AI is also transforming traditional offline customer service interaction methods. With the proliferation of smart devices and the Internet of Things, various devices will also become entry points for enterprises to serve customers and emerging scenarios, providing opportunities for intelligent customer service companies, especially AI companies, to capture a share of the billion-dollar smart device interaction market, potentially worth 20-30 billion RMB.
Educational Scenarios
Voice Tablets: In children’s educational scenarios, the potential of voice can be significant. On one hand, children’s literacy learning is not yet fully developed, making language a lower-barrier interaction choice for information input and interaction. On the other hand, voice can be used for real-time assessment and correction of pronunciation in both Chinese and English, adding greater value to children’s learning and growth.
-
Interactive Language Learning: Real-time assessment and correction of language pronunciation to enhance learning effectiveness.
-
Interactive Animation: Inserting scenario-based voice interaction into animations to educate and entertain, enhancing children’s immersion.
Travel Scenarios
Smart Earphones: Using portable tools for voice interaction in public scenarios enhances privacy and convenience. Earphones, being a wearable product, are easy to carry, allowing for more natural usage scenarios. Whether commuting to work, exercising outdoors, or traveling, earphones can maintain a high usage rate. When you interact with earphones, it feels more like conversing with a friend. Using gestures to wake them up, such as tapping the earphones, can be more natural than shouting, even in public settings.
Robots
Language interaction is the most commonly used interaction method in daily life, so robots naturally need to integrate voice interaction capabilities. Robots can be classified into consumer-grade and commercial-grade. Consumer-grade robots use voice to convey emotions and enhance interaction efficiency, while commercial-grade robots use voice to convey brand sentiment and improve service efficiency.
Security and Authentication
Voiceprint is a form of identity recognition that is unobtrusive. The theoretical basis of voiceprint recognition is that every voice has unique features, allowing effective differentiation between different speakers. U.S. research institutions have indicated that under certain conditions, voiceprints can be used as valid evidence. Moreover, the FBI has statistically analyzed 2,000 cases related to voiceprints, showing an error rate of only 0.31% when using voiceprints as evidence. The technology for distinguishing different individuals using voiceprints has been widely recognized and applied across various fields.
Voiceprints are commonly used in criminal investigations, criminal tracking, national defense monitoring, personalized applications, etc. Speaker verification technology is often applied in securities trading, banking transactions, police evidence collection, voice-activated locks for personal computers and cars, identity cards, and credit card recognition.
4 The Integration of Voice Interaction with Other Interaction Methods?
Voice interaction has disadvantages such as low information reception efficiency, reduced recognition accuracy in noisy environments, and psychological burdens in public settings. Therefore, in many scenarios, pure voice interaction is quite limited, but these interaction methods can be compensated by other interactions. Undoubtedly, more products with different combination methods will emerge in the coming years.

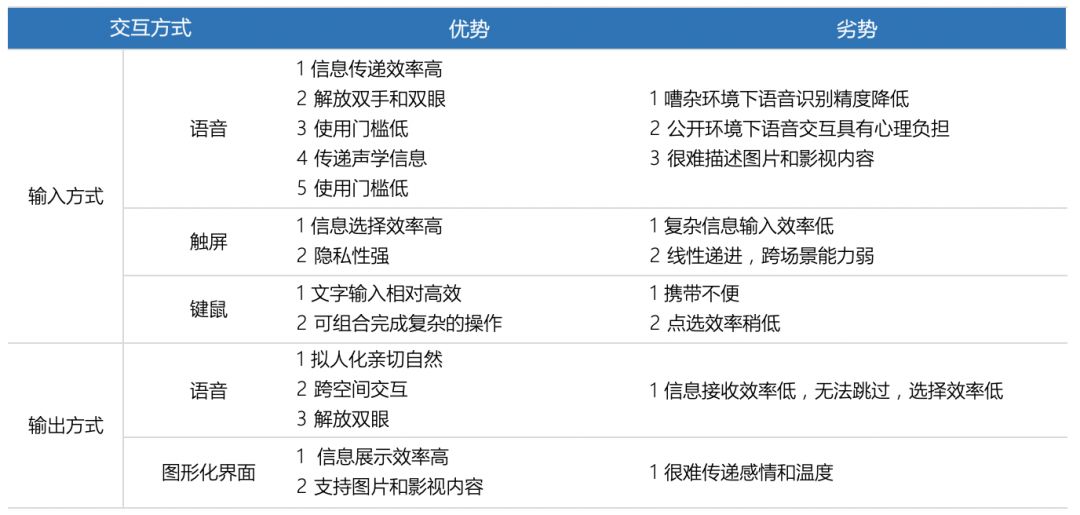
Voice Input/Visual Output
In recent years, many products have incorporated voice input, many of which are products with displays. In these products, users are allowed to input via voice while the interface displays the output information.
Voice smart televisions are a good example. They lack hardware that supports complex input but have enough functionality to support natural semantic queries. For instance, saying “Play The Wandering Earth” directly is much more convenient than using the remote control’s directional buttons.
Voice smart screens are another example. Starting from the second half of 2018, voice smart screens became popular, primarily targeting elderly and children. For the elderly, the value lies in being able to search for desired video content through voice interaction, while for children, it provides value in voice communication, video playback control, and pronunciation assessment.
In fact, those systems with complex functions that require complex inputs, which can be replaced by voice commands, and whose outputs are not suitable for machine reading, are well-suited for using voice as an input method and visual as an output method.
Hybrid Modes
Many devices are developing towards hybrid modes, combining voice, physical input, and screen and voice output. Navigation apps are a typical example that integrates these interaction methods.
Users can touch and drag the map to view, input destinations using physical buttons or virtual keyboards, and when driving, they can start navigation by simply saying the destination name. This way, users can operate without shifting their gaze to the screen or using their hands. Voice output can provide navigation commands, while difficult-to-describe information, such as traffic conditions, can be displayed on the screen.
This is a good way to combine input and output, allowing each interaction method to leverage its strengths. The entire navigation system will choose the presentation method of information based on user needs and the complexity of the information. On one hand, users can operate without using their hands or eyes in specific scenarios, while on the other hand, they can choose to use the screen in other scenarios.
However, this design is still rare because such methods are based on a deep understanding of user usage patterns. While using voice in cars is a relatively obvious scenario, not all products have a clear usage environment, making it difficult to determine when to use voice interaction.
5 The Future of Voice Interaction
Although current voice recognition technology allows machines to understand most human voices, it is still far from the interactive capabilities of hypothetical super-intelligent assistants like “Jarvis.” The development direction of voice recognition technology will shift from recognition to perception and cognition.
Trend 1: Wake Word-Free Interaction
Far-field voice interaction, due to intent recognition considerations, requires a wake word to initiate conversations, but this also increases communication costs. Especially in certain multi-turn interaction scenarios, for example, if you want to watch a movie, the main process requires “I want to watch a movie” – “Play the third one” – “Full screen” – “Fast forward 3 minutes.” If every time a wake word is needed, the user experience is poor, and in some cases, it may be less efficient than using a remote control. Therefore, wake word-free interaction is urgently needed in specific multi-process scenarios.
Trend 2: Offline Voice Recognition
Offline voice recognition refers to recognizing and processing commands directly on the local device without connecting to the cloud. The benefits are that it eliminates the need for wake words and does not require internet connectivity, making it faster. For devices like lights, air conditioners, and televisions, using offline command recognition enhances the experience, such as directly saying “turn on the light” or “turn off the light” for quick control.
Trend 3: Multi-Channel Interaction
In the IoT era, the number of connected devices in homes is increasing, but the experience improvement has been limited until IoT is enhanced by voice AI, marking the arrival of the AIoT era. Through voice devices, users can control connected devices, further promoting the penetration and coverage of smart home devices. In 2018, approximately 22 million smart speakers were sold in China, and as the number of smart home devices grows, user demands are gradually showing new characteristics.
The first characteristic: demands are often not single-task but a combination of multiple tasks;
The second characteristic: there is a need for interaction between multiple devices;
The third characteristic: service states can continuously migrate, whether across time or space;
Multi-channel interaction integrates various input and output channels, delivering services in the most appropriate way to meet user needs. In simpler terms, multimodal interaction registers and manages the channels of smart devices, assigning corresponding tasks based on user needs to meet them in the most suitable manner. For example, integrating smart speakers and televisions as a system for multi-channel interaction can comprehensively utilize their five input and output channels. A simple example is when I ask the speaker about the weather, the weather graphics can be displayed and reported through the television for a more intuitive user experience.
The most typical case of the MCUI landing in home scenarios is the combination of smart speakers and set-top boxes, which can realize all functions of a smart speaker with a screen and provide a better experience. On one hand, it is more cost-effective, with a non-screen speaker costing under 100 RMB, while a smart speaker with a screen costs around 500 RMB. On the other hand, the large screen provides a better viewing experience; for children’s education scenarios, a large screen is less likely to cause myopia, and parental control is stronger. Therefore, the product experience of smart speakers combined with set-top boxes will definitely become mainstream in the future.
October 25-27


Click Read Original
View Conference Schedule