Skip to content

MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and researchers in enterprises.
Community Vision is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for the progress of beginners.
Translation | Yang Haotong
The original English author is currently a scientist at Amazon, graduated from Peking University for undergraduate studies, and obtained a master’s degree from Georgia Tech, studying under Professor Yang Di from Stanford.
Original English Version:
https://jingfengyang.github.io/gpt
https://twitter.com/JingfengY/status/1625003999387881472
This tweet was written on February 12, 2023, and contains personal opinions for reference only.
Why have all public attempts to reproduce GPT-3 failed? On which tasks should we use GPT-3.5 or ChatGPT?
This article will include a summary I provided after carefully reviewing a series of articles, as well as my personal thoughts on the two questions above. These articles include, but are not limited to: GPT-3, PaLM, BLOOM, OPT, FLAN-T5/PaLM, HELM, etc. If you have more reliable references or practical experiences, please feel free to correct me.
For those who want to reproduce their own GPT-3 or ChatGPT, the first question is critical. The second question is important for those who want to use them (when mentioning GPT-3 below, it mainly refers to the latest versions of GPT-3.5 or InstructGPT, except in cases pointing to the original GPT-3).
Why Have All Public Attempts to Reproduce GPT-3 Failed?
Here, I refer to “failure” as training a model with parameters close to or larger than GPT-3, but still unable to match the performance reported in the original literature of GPT-3. By this standard, GPT-3 and PaLM are “successful”, but neither of these models is public. All public models (for example: OPT-175B and BLOOM-176B) have “failed” to some extent. However, we can still learn some lessons from these “failures”.
We need to note that if the open-source community can try various training setups multiple times, it may eventually reproduce GPT-3. However, as of now, the cost of training another version of OPT-175B remains prohibitively high—training such a large model would require at least 2 months on about 1000 80G A100 GPUs (data from the original OPT literature).
Despite some articles (for example, OPT-175B and GLM-130B) claiming they can match or even exceed the original GPT-3 performance on some tasks, such claims remain questionable in more tasks that GPT-3 has already been tested on. Additionally, based on the experiences of most users on more diverse tasks and evaluations by HELM, the recent OpenAI GPT-3 API performance still outperforms these open-source models.
While the underlying models may have used instruction tuning (like InstructGPT), similar OPT versions (OPT-IML) and BLOOM versions (BLOOMZ) that also used instruction tuning still perform significantly worse than InstructGPT and FLAN-PaLM (the instruction-tuned version of PaLM).
According to the details of the articles, there are several possible reasons for the failures of OPT-175B and BLOOM-176B compared to the successes of GPT-3 and PaLM. I categorize them into two parts: pre-training data and training strategies.
Let’s first look at how GPT-3 prepared and used its pre-training data. GPT-3 was trained on a total of 300B tokens, of which 60% came from filtered Common Crawl, and the rest from: webtext2 (the corpus used to train GPT-2), Books1, Books2, and Wikipedia.
The updated version of GPT-3 also used code datasets for training (e.g., Github Code). The proportion of each part does not correlate with the size of the original dataset; rather, higher quality datasets were sampled more frequently. The following three challenges may have contributed to the failures of OPT-175B and BLOOM-176B, making it difficult for the open-source community to collect similar data:
1. The first point is a classifier that performs well in filtering low-quality data. This was used to build the pre-training datasets for GPT-3 and PaLM, but it was not adopted in the training of OPT and BLOOM. Some articles have shown that a pre-training model trained on a smaller but higher-quality dataset can outperform another model trained on a larger mixed-quality dataset. Of course, the diversity of data is still very important, as we will discuss in the third point. Therefore, people should be very cautious in handling the trade-off between data diversity and quality.
2. The second point is the deduplication of the pre-training dataset. Deduplication helps avoid the pre-training model from memorizing or overfitting on the same data after encountering it multiple times, thus improving the model’s generalization ability. GPT-3 and PaLM employed document-level deduplication, which was also adopted by OPT. However, there are still many duplicates present in the deduplication Pile corpus used for OPT pre-training, which may have led to its poorer performance (Note: recent literature shows that the importance of deduplication for pre-training language models may not be as significant as previously thought).
3. The third point is the diversity of the pre-training dataset, including domain diversity, format diversity (e.g., text, code, and tables), and language diversity. The Pile corpus used by OPT claims to have better diversity, but the ROOTS corpus used by BLOOM contains too many existing academic datasets, lacking the diversity contained in Common Crawl data. This may lead to BLOOM’s poorer performance. In contrast, GPT-3 has a much higher proportion of data coming from Common Crawl, which is diverse and from a wide range of fields; this may be one of the reasons why GPT-3 could serve as the foundational model for the first general-purpose chatbot, ChatGPT.
Please note: While generally, diverse data is important for training a general LLM (Large Language Model), the specific distribution of the pre-training data can have a huge impact on the performance of the LLM on specific downstream tasks. For example, BLOOM and PaLM have a higher proportion of multilingual data, which leads to better performance on some multilingual tasks and machine translation tasks.
OPT utilized a lot of conversational data (e.g., Reddit), which may be one reason for its good performance in dialogues. PaLM has a large proportion of data in social media conversations, which may be why it performs exceptionally well on various question-answering tasks and datasets. Similarly, both PaLM and the updated versions of GPT-3 have a significant proportion of code datasets, enhancing their capabilities on coding tasks and possibly improving their Chain-of-Thought (CoT) abilities.
An interesting phenomenon is that BLOOM’s performance on code and CoT remains poor, even though it used code data during pre-training. This may suggest that code data alone does not guarantee the model’s coding and CoT abilities.
In summary, some articles have highlighted the importance of the above three points: avoiding memorization and overfitting through data deduplication, obtaining high-quality data through data filtering, and ensuring data diversity to maintain LLM’s generalization. Unfortunately, the details regarding how PaLM and GPT-3 preprocess these data, or the pre-training data themselves, have not been disclosed, making it difficult for the public community to reproduce them.
This includes training frameworks, training duration, model architectures/training settings, and modifications during the training process. When training very large models, these are used to achieve better stability and convergence. Generally, due to unknown reasons, loss spikes and convergence failures are widely observed during the pre-training process. As a result, numerous modifications to training settings and model architectures have been proposed to avoid these problems. However, some of these modifications in OPT and BLOOM are not optimal solutions, which may lead to their poorer performance. GPT-3 does not explicitly mention how they resolved this issue.
1. Training Framework. A model with more than 175B parameters often requires ZeRO-style data parallelism (distributed optimizer) and model parallelism (including tensor parallelism, pipeline parallelism, and sometimes sequence parallelism). OPT adopted the FSDP implementation of ZeRO and the Megatron-LM implementation of model parallelism. BLOOM used the Deepspeed implementation of ZeRO and the Megatron-LM implementation of model parallelism.
PaLM utilized Pathways, a TPU-based model parallelism and data parallelism system. The details of GPT-3’s training system remain unknown, but they at least used model parallelism to some extent (some people claim it used Ray). Different training systems and hardware may lead to different phenomena during training. Clearly, some settings presented in PaLM’s articles for TPU training may not be applicable to all models using GPU training.
An important impact of the hardware and training framework is whether one can use bfloat16 to store model weights and intermediate activation values. This has proven to be a crucial factor for stable training, as bfloat16 can represent a larger range of floating-point numbers, capable of handling large values that occur during loss spikes. On TPU, bfloat16 is the default setting, which may be one of the secrets to PaLM’s success. However, on GPUs, float16 was primarily used, which is the only option for mixed-precision training in V100.
OPT used float16, which may be one of the factors for its instability. BLOOM identified this issue and eventually used bfloat16 on A100 GPUs, but it did not realize the importance of this setting, leading to the introduction of additional layer normalization after the first word vector layer to address the instability in their preliminary experiments using float16. However, this layer normalization has been shown to lead to worse zero-shot generalization, which may be a factor in BLOOM’s failure.
2. Modifications during the Training Process. OPT made numerous mid-course adjustments and restarted training from recent checkpoints, including changing the clipped gradient norm, learning rates, switching to a simple SGD optimizer and then back to Adam, resetting the dynamic loss scalar, switching to updated versions of Megatron, and so on.
This mid-course adjustment may be one of the reasons for OPT’s failure. In contrast, PaLM made almost no mid-course adjustments. It simply restarted training from a checkpoint about 100 steps before a loss spike occurred and skipped about 200-500 batches of data. Relying solely on this simple restart, PaLM achieved remarkable success. This is due to its already completed sampling during pre-training data construction, giving the model a degree of determinism in a bit sense, along with many modifications to its model architecture and training settings to achieve better stability. Such modifications in PaLM are demonstrated in the next point.
3. Model Architecture/Training Settings: To make training more stable, PaLM made several adjustments to model architecture and training settings, including using a modified version of Adafactor as the optimizer, scaling the output logits before softmax, using auxiliary loss to encourage the softmax normalizer to be close to 0, using different initializations for word vectors and other layer weights, not using bias terms in feedforward layers and layer normalization, and not using dropout during pre-training.
Note that GLM-130B contains more valuable content on how to train very large models stably, such as using post-layer normalization based on DeepNorm instead of pre-layer normalization, and gradient clipping for word vector layers. Most of the above model modifications were not adopted by OPT and BLOOM, which may lead to their instability and failure.
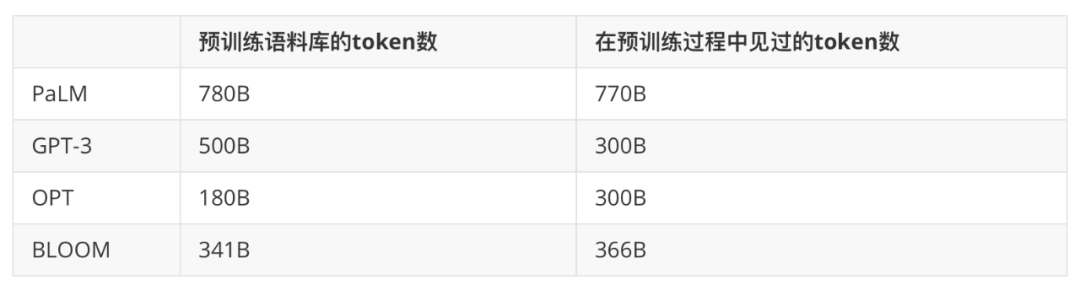
4. Training Process: As shown in the table below, the number of tokens seen during the original GPT-3 pre-training process is close to that of OPT and BLOOM, while PaLM far exceeds them. Similarly, the pre-training corpora of PaLM and GPT-3 are larger than those of BLOOM and OPT. Therefore, pre-training on a larger scale with higher-quality corpora may be a significant factor for the success of GPT-3 and PaLM.
In addition to the four points listed above, there are other factors that may not be critical for more stable training but can still affect final performance.
The first point is that both PaLM and GPT-3 used gradually increasing batch sizes during training, which has been shown to be effective for training a better LLM, while both OPT and BLOOM used constant batch sizes.
The second point is that OPT used the ReLU activation function, while PaLM used the SwiGLU activation function, and GPT-3 and BLOOM used GeLU, which generally leads to better performance when training LLMs.
The third point is that to better model longer sequences, PaLM used RoPE word vectors, BLOOM used ALiBi word vectors, while the original GPT-3 and OPT used learned word vectors, which may impact performance on long sequences.
On Which Tasks Should We Use GPT-3.5 or ChatGPT?
I attempt to explain which tasks and applications we should use GPT-3 for and which ones we should not. To determine if GPT-3 is suitable for a specific task, I primarily compared prompting GPT-3 with fine-tuned smaller models, which sometimes incorporate other special designs. Given the good performance of the recently emerged smaller and fine-tunable FLAN-T5 model, this question has become even more important.
Ideally, if the burden of fine-tuning GPT-3 is manageable, it may lead to further improvements. However, the enhancements brought by fine-tuning PaLM-540B on some tasks are so limited that one might question whether fine-tuning GPT-3 is worthwhile for certain tasks. From a scientific perspective, a fair comparison should be made between fine-tuning GPT-3 and prompting GPT-3. However, to use GPT-3, people might be more concerned with comparing prompting GPT-3 against fine-tuning a smaller model.
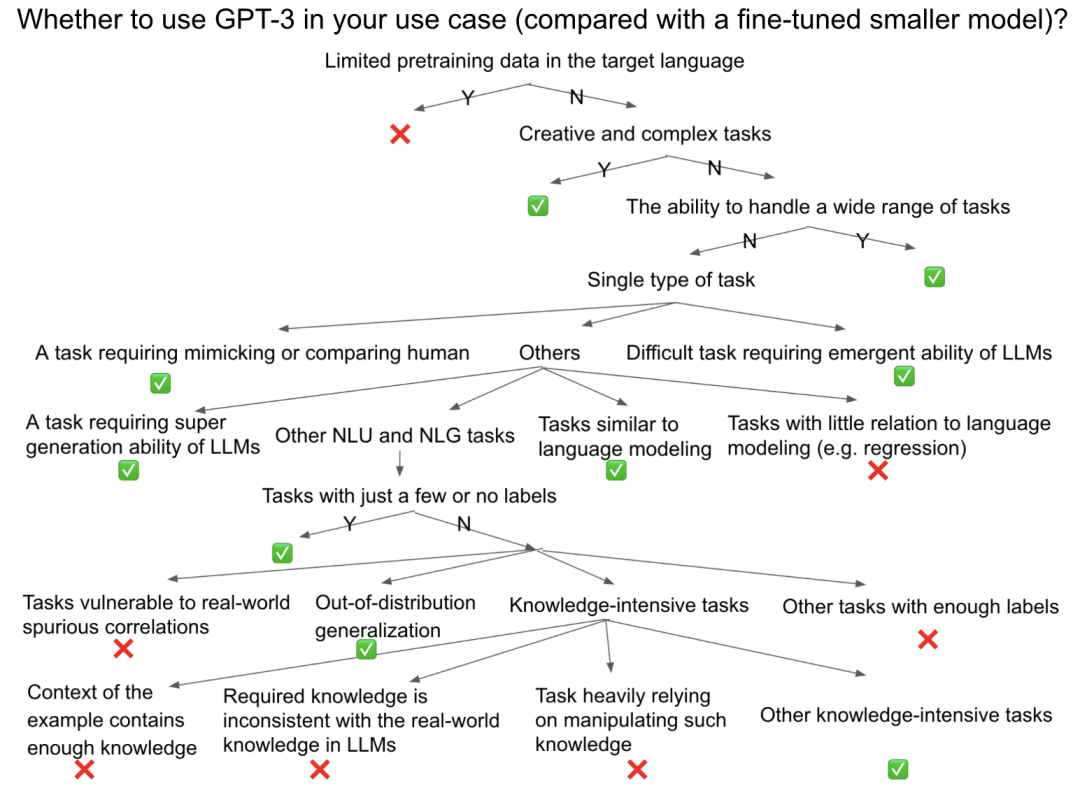
Note that I am primarily concerned with the accuracy of task completion as a metric, but there are still many other important dimensions, such as toxicity, fairness, etc., that should also be considered when deciding whether to use GPT-3, as presented in the HELM article. The following diagram illustrates a rough decision flow, which I hope can serve as a useful practical guide, whether for existing tasks or a brand new task.
Note 1: Due to good alignment in dialogue scenarios, ChatGPT performs excellently as a chatbot. However, we usually use models like GPT-3, InstructGPT (GPT-3.5), and Codex, which are behind ChatGPT, as general models for more tasks and usage scenarios.
Note 2: The conclusions in this section are based on findings from some current versions of the models, which may not apply to future, more powerful models. For instance, using more pre-training data that is closer to the target dataset, academic dataset instruction tuning (e.g., prompting a FLAN-PaLM may yield stronger performance, though it has not been publicly disclosed), or aligning the model better with the target task through RLHF could improve the model’s performance on the target task, even if it sometimes sacrifices capabilities in other scenarios (e.g., the “alignment tax” of InstructGPT).
In this case, it is difficult to determine whether GPT is generalizing and cross-task generalizing or merely memorizing some test examples seen during pre-training, or whether it has encountered those tasks that are supposedly “unseen” during pre-training. However, whether memory is indeed a serious problem in practice remains questionable. Because users differ from researchers; if they find that GPT performs well on their test data, they may not care whether GPT saw the same or similar data during pre-training.
Regardless, to maximize the practical value of this section, I have made every effort to compare fine-tuning public smaller models (T5, FLAN-T5, some specially designed fine-tuned SOTA models, etc.) with the recent best performances of GPT-3 (GPT-3.5, InstructGPT) and PaLM (or FLAN-PaLM), if evaluation data for these models is available.
Generally, the following situations are more suitable for using prompting GPT-3. Surprisingly, if we look back at the introduction section of the GPT-3 paper, many of the initial design goals covered these tasks. This means that those grand goals have been partially realized.
1. Creative and complex tasks: including coding (code completion, generating code from natural language instructions, code translation, bug fixing), text summarization, translation, creative writing (e.g., writing stories, articles, emails, reports, and writing improvements, etc.). As shown in the original GPT-3 literature, GPT-3 was designed for those difficult and “impossible to label” tasks. To some extent, for these tasks, the previously fine-tuned models could not be applied to real-world applications; whereas GPT-3 makes them possible. For example, recent articles have shown that human-annotated text summaries have been surpassed by summaries generated by LLMs.
In some machine translation tasks requiring translation from low- and medium-resource languages into English, prompting PaLM-540B can even surpass fine-tuned models.
A similar trend has been observed in BLOOM-176B. This is because English data usually occupies a significant proportion in the pre-training corpus, making LLMs adept at generating English sentences. Note that to achieve good performance in coding tasks, although Codex and PaLM generally outperform previous models, we still need to allow LLMs to sample multiple times (k times) to pass test examples (using pass@k as a metric).
2. Tasks with few or no labeled data. As stated in the original GPT-3 literature, GPT-3 was designed for those “expensive labeling” tasks. In this case, fine-tuning a smaller model with a very small amount of labeled data is often not possible to achieve the performance of GPT-3 in zero-shot, one-shot, or few-shot scenarios.
3. Out-of-distribution (OOD) generalization. Given some training data, traditional fine-tuning may overfit the training set and have poor out-of-distribution generalization; whereas few-shot in-context learning can achieve better out-of-distribution generalization. For example, prompting PaLM can surpass fine-tuned SOTA models on the adversarial natural language inference task (ANLI), while it may still perform worse than fine-tuned SOTA on standard language inference tasks.
Another example is that prompting LLMs shows better compositional generalization than fine-tuned models. The better out-of-distribution generalization may be due to the fact that in-context learning does not require parameter updates, avoiding overfitting; or because past out-of-distribution examples are in-distribution for the LLM. This usage scenario is illustrated as one of GPT-3’s initial design goals: “The performance of fine-tuned models on specific task datasets can reach so-called human-level, which may exaggerate the performance on that task in the real world, as the model has merely learned the false correlations present in the training set and has overfitted the narrow distribution of this training set.”
4. The ability to handle multiple tasks, rather than focusing on outstanding performance on specific tasks. Chatbots are such a scenario where users expect them to respond correctly to a wide variety of tasks. This may explain why ChatGPT is one of the most successful use cases of GPT-3.
5. Knowledge-intensive tasks where retrieval is not feasible. The knowledge stored in LLMs can significantly improve performance on knowledge-intensive tasks such as closed-book question answering and MMLU (a benchmark dataset including multiple-choice questions from 57 disciplines such as STEM, humanities, and social sciences, used to test LLM’s world knowledge and question-answering abilities). However, if a pre-retrieval step can be added for retrieval-augmented generation, a fine-tuned smaller model (e.g., Atlas model) can even outperform PaLM and the latest InstructGPT on closed-book NaturalQuestions and TrivialQA datasets.
Retrieval or traditional search is also a necessary step for integrating GPT-3 or ChatGPT into search engines, which can enhance the accuracy of generation and provide more reference links to strengthen persuasion. However, we should acknowledge that in some cases, retrieval is not allowed or is difficult, such as taking the USMLE (United States Medical Licensing Examination), where Google has shown that FLAN-PaLM-based models can perform well.
Similarly, in the MMLU benchmark, PaLM-540B exhibits better performance than other fine-tuned models, even when the latter incorporates retrieval, although the latest version of InstructGPT still lags behind these retrieval-augmented fine-tuned SOTAs. Also, note that instruction-tuning a smaller model can achieve results close to those of larger LLM models, as demonstrated in FLAN-T5.
6. Some difficult tasks that require the emergent capabilities of LLMs, such as reasoning with CoT and complex tasks in BIG-Bench (including logical reasoning, translation, question answering, mathematical tasks, etc.). For example, PaLM has demonstrated that in seven multi-step reasoning tasks, the 8-shot CoT outperformed fine-tuned SOTA in four of the tasks, while remaining competitive in the other three.
This successful performance is attributed both to the larger model size and to CoT. PaLM has also shown discontinuous performance improvements on BIG-Bench tasks from 8B to 62B to 540B models, exceeding scaling laws, referred to as the emergent capabilities of LLMs. Additionally, PaLM-540B with five prompts outperformed previous (few-shot) SOTAs in 44 out of 58 common tasks in Big-Bench. The overall performance of PaLM-540B in Big-Bench also surpassed the average performance of humans.
7. Some scenarios that require imitation of humans, or where the goal is to create general artificial intelligence that performs at human level. ChatGPT is one such case, where it presents itself more like a human, achieving phenomenal success. This is also articulated as one of GPT-3’s initial design goals: “Humans do not need large-scale supervised datasets to learn most language tasks. At most, only a few examples are needed for humans to seamlessly mix or switch between various tasks and skills. Therefore, traditional fine-tuned models lead to an unfair comparison with humans, even though they claim to have human-level performance on many benchmark datasets.”
8. In some traditional NLP tasks close to language modeling, few-shot PaLM-540B can roughly match or even exceed fine-tuned SOTA, such as fill-in-the-blank tasks for the last sentence and last word of a paragraph, as well as anaphora resolution. It should be noted that in these cases, zero-shot LLMs are already sufficient, and one-shot or few-shot examples usually do not help much.
Other tasks do not require prompting a model as large as GPT-3:
1. Calling the OpenAI GPT-3 API exceeds the budget (e.g., for startups with limited funds).
2. Calling the OpenAI GPT-3 API poses security issues (e.g., data leaking to OpenAI, or potentially generating harmful content).
3. There are not enough engineering or hardware resources to deploy a similarly sized model and eliminate inference latency issues. For instance, deploying OPT-175B using Alpa on 16 40G A100s requires 10 seconds to complete inference for a single sample, which is unacceptable latency for most real-world online applications.
4. If one wants to replace a well-performing, highly accurate fine-tuned model with GPT-3, or wants to deploy an NLU (Natural Language Understanding) or NLG (Natural Language Generation) model for some specific single tasks and usage scenarios, one should think carefully about whether it is worthwhile.
-
For some traditional NLU tasks, such as classification tasks, I recommend first trying to fine-tune the FLAN-T5-11B model instead of prompting GPT-3. For example, on SuperGLUE, a challenging NLU benchmark dataset (including reading comprehension, text entailment, word sense disambiguation, coreference resolution, and causal reasoning tasks), the few-shot prompting performance of all PaLM-540B is inferior to that of fine-tuned T5-11B, with significant gaps in most of those tasks. Using the original GPT-3, the gap between its prompting results and those of fine-tuned SOTA is even larger. Interestingly, even fine-tuned PaLM performs only marginally better than fine-tuned T5-11B, and even fine-tuned PaLM is worse than the fine-tuned 32B MoE model. This suggests that using a more suitable architecture (e.g., encoder-decoder models) to fine-tune smaller models remains a better solution than using a very large decoder-only model, whether for fine-tuning or prompting these large models. According to a recent paper, even for the most traditional NLU classification task—sentiment analysis, ChatGPT still performs worse than fine-tuned smaller models.
-
Some difficult tasks that are not based on real-world data. For example, there are still many difficult tasks for LLMs in BigBench. Specifically, for 35% of BigBench tasks, the average human performance is still higher than that of PaLM-540B, and in some tasks, scaling up the model size does not help, such as navigation and mathematical induction. In mathematical induction, when the hypothesis in the prompt is incorrect (e.g., “2 is an odd number”), PaLM makes many mistakes. Similar trends have been observed in the Inverse Scaling Law Challenge, where redefining mathematical symbols (e.g., the prompt may say “redefine π as 462”) and then using that symbol. In such cases, the real-world prior knowledge in the LLM is too strong to be overridden by the prompt, whereas fine-tuning smaller models may learn these counterfactuals better.
-
In many multilingual tasks and machine translation tasks, using few-shot prompting GPT still performs worse than fine-tuned smaller models. This is likely due to the limited representation of languages other than English in the pre-training corpus.
-
When translating from English to other languages, and translating high-resource languages into English, PaLM and ChatGPT still perform worse on machine translation tasks than fine-tuned smaller models.
-
For multilingual question-answering tasks, there is still a significant gap between few-shot PaLM-540B and fine-tuned smaller models.
-
For multilingual text generation (including text summarization and data-to-text generation), there remains a considerable gap between few-shot PaLM-540B and fine-tuned smaller models. In most tasks, even fine-tuned PaLM-540B shows only marginal improvement over fine-tuned T5-11B and still lags behind fine-tuned SOTA.
-
For common-sense reasoning tasks, there remains a significant gap between the best few-shot prompting LLM and fine-tuned SOTA, such as OpenbookQA, ARC (both Easy and Challenge versions), and CommonsenseQA (even with CoT prompting).
-
For machine reading comprehension tasks, there remains a significant gap between the best few-shot prompting LLM and fine-tuned SOTA. In most datasets, this gap can be very large. This may be because all the knowledge needed to answer questions is already contained in the provided text, and does not require additional knowledge from the LLM.
In summary, the above tasks can be categorized into one of the following categories:
1. Some NLU tasks that neither require additional knowledge nor the generative capabilities of LLMs. This means that most test data falls within the same distribution as the training data at hand. In these tasks, previously fine-tuned smaller models have already performed well.
2. Some tasks that do not require additional knowledge from LLMs, as each example already contains sufficient knowledge within the context or prompt, such as machine reading comprehension.
3. Some tasks that require additional knowledge but are unlikely to obtain such knowledge from LLMs, or where LLMs are unlikely to have seen tasks from a similar distribution, such as tasks in low-resource languages where LLMs have only a limited number of pre-training samples in those languages.
4. Some tasks that require knowledge inconsistent with that contained in LLMs, or knowledge not based on real-world language data. Because LLMs are trained on real-world language data, they struggle to leverage counterfactual knowledge in new tasks. In addition to the “redefining mathematical symbols” problem in the Inverse Scaling Law Challenge, there is another task that involves rephrasing slightly altered quotes, where LLMs are asked to rephrase a modified quote that appears in the prompt. In such cases, LLMs tend to repeat the original version of the quote rather than the modified version.
5. Some tasks require knowledge from LLMs but also heavily rely on manipulating that knowledge, which the LLM’s goal of “predicting the next token” cannot easily achieve. An example is some common-sense reasoning tasks. CoT and least-to-most prompting can help LLMs reason, possibly because they better retrieve those continuous pre-training texts that mimic the process of planning and decomposing/composing knowledge.
Therefore, CoT and least-to-most prompting perform well in some mathematical reasoning, coding, and other simple natural language reasoning tasks, but still perform poorly in many common-sense reasoning (such as deductive reasoning tasks demonstrated in the Inverse Scaling Law Challenge) and custom symbol reasoning tasks. These tasks are typically not included in most real-world continuous sequences in natural language data and require manipulating knowledge scattered throughout.
6. Some tasks that are easily influenced by contextual learning examples or false correlations present in real-world data. An example is the question-and-answer task involving negation words from the Inverse Scaling Law Challenge. If an LLM is asked, “If a cat’s body temperature is below average, it is not…”, it tends to answer “in danger” rather than “within a safe range”. This is because LLMs are governed by the common relationship between “below average temperature” and “danger”, which is a false correlation in the case of negation.
7. Some tasks whose objectives are significantly different from processing language data, such as regression problems, where fine-tuned models are difficult to replace with LLMs. As for multimodal tasks, they cannot be solved by LLMs but may benefit from large-scale pre-trained multimodal models.
8. Some tasks do not require the emergent capabilities of LLMs. To accurately identify more such tasks, we need to better understand where the emergent capabilities of LLMs arise during training.
Note that in real-world usage scenarios, even if LLMs cannot be used online due to latency requirements, they can still be used offline to generate or label data. Such automatically labeled tags can be searched online and provided to users, or used to fine-tune smaller models. Using such data to fine-tune smaller models can reduce the amount of manual annotation data needed to train models and inject some of the emerging capabilities of LLMs (such as CoT) into smaller models.
In summary, when sufficient labeled data is available, considering the remarkable performance of the open-source FLAN-T5 on many tasks, I recommend that individuals with limited resources calling the OpenAI API should first try fine-tuning FLAN-T5-11B on their target tasks. Furthermore, based on recent performance comparisons on the MMLU dataset, FLAN-PaLM-540B has shown astonishing performance compared to the latest version of InstructGPT (according to HELM), suggesting that Google may have stronger foundational models than OpenAI, if OpenAI has already released their strongest LLM through the API.
The only remaining step for Google is to align this LLM with dialogue scenarios through human feedback. If they quickly release a chatbot similar to ChatGPT or better, I would not be surprised—despite their recent “failure” to showcase a version possibly based on LaMDA Bard.