
Introduction
This article provides an in-depth analysis of the GPT series models, translated into Chinese, and shared here for everyone.

By Li Rumor | Source
Author:Fu Yao, [email protected], PhD student at the University of Edinburgh, graduated from Peking University, and together with Peng Hao, Tushar Khot co-authored the English manuscript at the Allen Institute for AI, and translated into Chinese with Guo Zhijiang from Cambridge University.
Thanks to He Junxian from Shanghai Jiao Tong University, Lu Pan from UCLA, and Liu Ruibo from Dartmouth College for discussions and suggestions on the initial draft. Thanks to Raj Ammanabrolu (Allen Institute for AI), Peter Liu (Google Brain), Brendan Dolan-Gavitt (New York University), Denny Zhou (Google Brain) for discussions and suggestions on the final draft; their suggestions greatly enhanced the completeness of this article. English Original: https://franxyao.github.io/blog.html
Recently, OpenAI’s pre-trained model ChatGPT has left a profound impression and inspiration on researchers in the field of artificial intelligence. Undoubtedly, it is powerful, intelligent, and fun to talk to, and it can even write code. Its capabilities in multiple areas far exceed the expectations of natural language processing researchers. Thus, we naturally have a question: How did ChatGPT become so powerful? Where do its various strong capabilities come from? In this article, we attempt to analyze the emergent abilities of ChatGPT, trace the origins of these abilities, and hope to provide a comprehensive technical roadmap to illustrate how the GPT-3.5 model series and related large language models evolved into their current powerful form.
We hope this article can promote transparency in large language models and serve as a roadmap for the open-source community to collectively work towards reproducing GPT-3.5.
To our compatriots in China:
-
In the eyes of the international academic community, ChatGPT / GPT-3.5 is a groundbreaking product, and the difference between it and previously common language models (Bert/Bart/T5) is almost like the difference between a missile and a bow and arrow, which must be taken seriously. -
In my discussions with international peers, mainstream academic institutions (such as Stanford University, UC Berkeley) and mainstream industry research institutes (such as Google Brain, Microsoft Research) have fully embraced large models. -
At this current stage, the gap between domestic technology levels, academic vision, scholarly philosophy, and international frontiers seems to have not diminished; rather, it is expanding, and if the status quo continues, there is a high possibility of a technological gap. -
This is indeed a critical moment for survival.
Many years later, facing the firing squad, Colonel Aureliano Buendía will remember that distant afternoon when his father took him to see ice for the first time. — One Hundred Years of Solitude by Gabriel García Márquez
1. The 2020 Version of the Original GPT-3 and Large-scale Training
1. The 2020 Version of the Original GPT-3 and Large-scale Training
The original GPT-3 demonstrated three important capabilities:
-
Language Generation: Following prompt words and then generating sentences that complete the prompt. This is also the most common way humans interact with language models today. -
In-Context Learning: Following several examples of a given task and then generating solutions for new test cases. Importantly, although GPT-3 is a language model, its paper hardly discusses “language modeling” — the authors devoted all their writing energy to the vision of in-context learning, which is the true focus of GPT-3. -
World Knowledge: Including factual knowledge and commonsense knowledge.
So where do these abilities come from?
Basically, the above three abilities all come from large-scale pre-training: pre-training a model with 175 billion parameters on a corpus of 300 billion words (60% of the training corpus comes from C4 from 2016-2019 + 22% from WebText2 + 16% from Books + 3% from Wikipedia). Among them:
-
The ability for language generation comes from the training objective of language modeling. -
World knowledge comes from the corpus of 300 billion words (where else could it come from?). -
The 175 billion parameters of the model are meant for storing knowledge; Liang et al. (2022) further proved this point. Their conclusion is that the performance of knowledge-intensive tasks is closely related to model size. -
The source of the ability for in-context learning and why it can generalize remains difficult to trace. Intuitively, this ability may come from the fact that data points of the same task are arranged sequentially in the same batch during training. However, few have studied why pre-training language models promotes in-context learning and why the behavior of in-context learning is so different from fine-tuning.
Interestingly, how strong was the original GPT-3? It is actually difficult to determine whether the original GPT-3 (referred to as <span>davinci</span> in OpenAI API) is “strong” or “weak”. On the one hand, it reasonably responded to certain specific queries and achieved decent performance on many datasets; on the other hand, its performance on many tasks was even worse than that of smaller models like T5 (see its original paper). Today (December 2022), it is hard to say that the original GPT-3 is “intelligent” by ChatGPT’s standards. The OPT model open-sourced by Meta attempted to replicate the original GPT-3, but its capabilities sharply contrast with today’s standards. Many who have tested OPT also believe that compared to the current <span>text-davinci-002</span>, this model is indeed “not great.” Nevertheless, OPT may be a sufficiently good open-source approximation of the original GPT-3 (according to the OPT paper and Stanford University’s HELM evaluation).
2. From the 2020 Version of GPT-3 to the 2022 Version of ChatGPT
2. From the 2020 Version of GPT-3 to the 2022 Version of ChatGPT
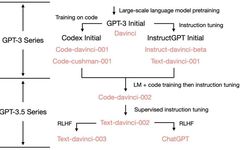
Starting from the initial GPT-3, to illustrate how OpenAI evolved to ChatGPT, let’s look at the evolutionary tree of GPT-3.5:
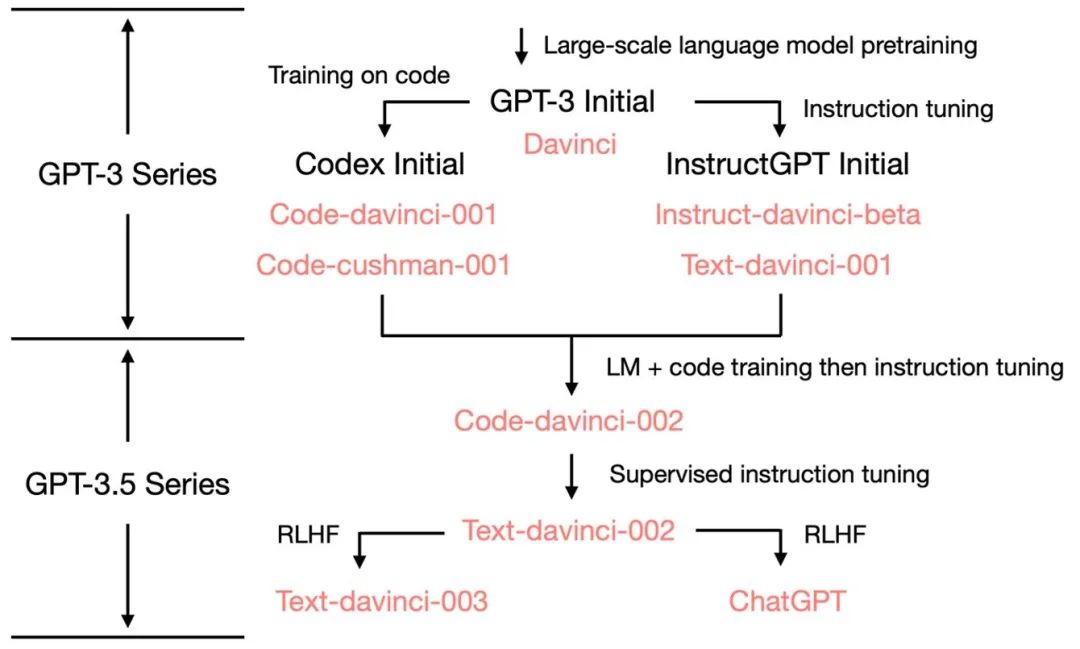
In July 2020, OpenAI released the paper for the original GPT-3 model indexed as <span>davinci</span>, marking the start of its continuous evolution. In July 2021, the paper for Codex was released, in which the initial Codex was fine-tuned from a (possibly internal) 12 billion parameter variant of GPT-3. Later, this 12 billion parameter model evolved into <span>code-cushman-001</span> in the OpenAI API. In March 2022, OpenAI released a paper on instruction tuning, where the supervised instruction tuning part corresponds to <span>davinci-instruct-beta</span> and <span>text-davinci-001</span>. From April to July 2022, OpenAI began beta testing the <span>code-davinci-002</span> model, also known as Codex. Then, <span>code-davinci-002</span>, <span>text-davinci-003</span>, and <span>ChatGPT</span> were all derived from <span>code-davinci-002</span> through instruction tuning. For detailed information, please refer to OpenAI’s model index documentation.
Although Codex sounds like a model focused solely on code, <span>code-davinci-002</span> is likely the most powerful GPT-3.5 variant for natural language (superior to <span>text-davinci-002</span> and <span>-003</span>). <span>code-davinci-002</span> was likely trained on both text and code, then adjusted based on instructions (which will be explained below). Then, the <span>text-davinci-002</span> released in May-June 2022 is a supervised instruction-tuned model based on <span>code-davinci-002</span>. Performing instruction tuning on <span>text-davinci-002</span> likely reduced the model’s in-context learning ability but enhanced the model’s zero-shot capability (which will be explained below). Then came <span>text-davinci-003</span> and <span>ChatGPT</span>, both released in November 2022, which are two different variants of the instruction-tuned model based on reinforcement learning from human feedback (RLHF).<span>text-davinci-003</span> restored (but still worse than <span>code-davinci-002</span>) some of the in-context learning abilities lost in <span>text-davinci-002</span> (likely because it mixed in language modeling during fine-tuning) and further improved zero-shot capability (thanks to RLHF). On the other hand, ChatGPT seems to have sacrificed almost all in-context learning ability to gain the ability to model conversational history.
Overall, during the period from 2020 to 2021, before <span>code-davinci-002</span>, OpenAI invested a lot of effort to enhance GPT-3 through code training and instruction tuning. By the time they completed <span>code-davinci-002</span>, all the capabilities were already present. It is likely that subsequent instruction tuning, whether through supervised versions or reinforcement learning versions, will do the following (which will be detailed later):
-
Instruction tuning does not inject new abilities into the model — all abilities were already present. The role of instruction tuning is to unlock / activate these abilities. This is mainly because the amount of data for instruction tuning is several orders of magnitude smaller than that of pre-training (the foundational abilities are injected through pre-training). -
Instruction tuning differentiates GPT-3.5 into different skill trees. Some are better at in-context learning, like <span>text-davinci-003</span>, while others excel at dialogue, like<span>ChatGPT</span>. -
Instruction tuning trades performance for alignment with humans (alignment tax). The authors of OpenAI’s instruction tuning paper referred to this as the “alignment tax.” Many papers have reported that <span>code-davinci-002</span>achieved the best performance on benchmark tests (but the model may not align with human expectations). After instruction tuning on<span>code-davinci-002</span>, the model can generate feedback that is more in line with human expectations (or aligns with humans), such as: zero-shot question answering, generating safe and fair conversational responses, and refusing questions beyond the model’s knowledge scope.
3. Code-Davinci-002 and Text-Davinci-002, Trained on Code, Tuned on Instructions
3. Code-Davinci-002 and Text-Davinci-002, Trained on Code, Tuned on Instructions
Before <span>code-davinci-002</span> and <span>text-davinci-002</span>, there were two intermediate models, namely davinci-instruct-beta and text-davinci-001. Both were inferior to the aforementioned two -002 models in many aspects (e.g., text-davinci-001 lacks strong chain-of-thought reasoning ability). Therefore, we will focus on the -002 models in this section.
3.1 The Source of Complex Reasoning Ability and Generalization to New Tasks
We focus on <span>code-davinci-002</span> and <span>text-davinci-002</span>, these two brothers are the first versions of the GPT-3.5 model, one for code and the other for text. They exhibit three important abilities that differ from the original GPT-3:
-
Responding to Human Instructions: Previously, GPT-3’s outputs were mainly common sentences in the training set. The current models generate more reasonable answers based on instructions/prompts (instead of relevant but useless sentences). -
Generalizing to Unseen Tasks: When the number of instructions used to adjust the model exceeds a certain scale, the model can automatically generate effective responses to new instructions it has never seen before. This ability is crucial for deployment, as users will always ask new questions, and the model must be able to answer them. -
Code Generation and Understanding: This ability is evident since the model has been trained on code. -
Utilizing Chain-of-Thought for Complex Reasoning: The original GPT-3 model had very weak or no ability for chain-of-thought reasoning. Code-davinci-002 and text-davinci-002 are two models with sufficiently strong chain-of-thought reasoning abilities. -
Chain-of-thought reasoning is important because it may be key to unlocking emergent abilities and surpassing scaling laws. Please refer to the previous blog post.
Where do these abilities come from?
Compared to previous models, two main differences are instruction tuning and code training. Specifically,
-
The ability to respond to human instructions is a direct product of instruction tuning. -
The ability to respond to unseen instructions generalizes automatically after the number of instructions exceeds a certain threshold; T0, Flan, and FlanPaLM papers further prove this point. -
The ability to use chain-of-thought for complex reasoning is likely a magical byproduct of code training. We have the following facts as some support: -
The original GPT-3 had not been trained on code, and it could not perform chain-of-thought. -
The text-davinci-001 model, although it underwent instruction tuning, had very weak chain-of-thought reasoning ability, as reported in the first chain-of-thought paper — so instruction tuning may not be the reason for the existence of chain-of-thought; code training is the most likely reason the model can perform chain-of-thought reasoning. -
PaLM has 5% of code training data and can perform chain-of-thought. -
The code data amount in the Codex paper is 159G, which is about 28% of the 570 billion training data of the original GPT-3. Code-davinci-002 and its subsequent variants can perform chain-of-thought reasoning. -
In the HELM test, Liang et al. (2022) conducted large-scale evaluations of different models. They found that models trained on code had strong language reasoning abilities, including the 12 billion parameter code-cushman-001. -
Our work at AI2 also shows that when equipped with complex chain-of-thought, code-davinci-002 performs best on important math benchmarks such as GSM8K. -
Intuitively, procedure-oriented programming is very similar to how humans solve tasks step by step, while object-oriented programming is very similar to how humans break down complex tasks into simpler tasks. -
All of the above observations suggest a correlation between code and reasoning abilities/chain-of-thought. This correlation between code and reasoning abilities/chain-of-thought is a very interesting question for the research community, but it is still not well understood. However, there is still no conclusive evidence that code training is the cause of CoT and complex reasoning. The origin of chain-of-thought remains an open research question. -
Additionally, another potential byproduct of code training is long-distance dependencies, as noted by Peter Liu: “The next word prediction in language is often very local, while code often requires longer dependencies to do things, such as matching parentheses or referencing distant function definitions.” Here, I would like to add that due to class inheritance in object-oriented programming, code may also help the model build the ability to establish coding hierarchies. We will leave the testing of this hypothesis for future work.
Moreover, some details differ:
-
Text-Davinci-002 vs. Code-Davinci-002 -
Code-davinci-002 is the base model, while text-davinci-002 is the product of instruction-tuning code-davinci-002 (see OpenAI’s documentation). It was fine-tuned on the following data: (1) manually labeled instructions and expected outputs; (2) model outputs selected by human labelers. -
When there are in-context examples, code-davinci-002 is better at in-context learning; when there are no in-context examples/zero-shot, text-davinci-002 performs better on zero-shot tasks. In this sense, text-davinci-002 is more in line with human expectations (as writing in-context examples for a task can be cumbersome). -
OpenAI is unlikely to have intentionally sacrificed in-context learning ability for zero-shot ability—the reduction in in-context learning ability is more of a side effect of instruction learning, which OpenAI refers to as alignment tax. -
001 Models (Code-Cushman-001 and Text-Davinci-001) vs. 002 Models (Code-Davinci-002 and Text-Davinci-002) -
001 models are primarily designed for pure code/pure text tasks; 002 models have deeply integrated code training and instruction tuning, capable of handling both code and text. -
Code-davinci-002 may be the first model to deeply integrate code training and instruction tuning. Evidence suggests: code-cushman-001 can perform reasoning but performs poorly on pure text, while text-davinci-001 performs well on pure text but struggles with reasoning. Code-davinci-002 can do both.
3.2 Are These Abilities Present After Pre-Training or Injected Later Through Fine-Tuning?
At this stage, we have identified the key roles of instruction tuning and code training. An important question is how to further analyze the effects of code training and instruction tuning? Specifically: do the aforementioned three abilities already exist in the original GPT-3, merely triggered/unlocked through instruction and code training? Or do these abilities not exist in the original GPT-3, but are injected through instruction and code training? If the answer is that they already exist in the original GPT-3, then these abilities should also be present in OPT. Therefore, to reproduce these abilities, one might directly adjust OPT through instruction and code. However, code-davinci-002 may not be based on the original GPT-3 davinci but on a model larger than the original GPT-3. If that is the case, it may not be possible to reproduce it by adjusting OPT. The research community needs to further clarify what kind of model OpenAI trained as the base model for code-davinci-002.
We have the following hypotheses and evidence:
-
The base model of code-davinci-002 may not be the original GPT-3 davinci model. Here is the evidence: -
The original GPT-3 was trained on the C4 dataset from 2016-2019, while the training set for code-davinci-002 likely extended to 2021. Therefore, code-davinci-002 may have been trained on the 2019-2021 version of C4. -
The original GPT-3 has a context window size of 2048 tokens, while code-davinci-002 has a context window size of 8192 tokens. The GPT series uses absolute positional embedding, and extrapolating directly from absolute positional embeddings without training is difficult and can severely degrade model performance (refer to Press et al., 2022). If code-davinci-002 is based on the original GPT-3, how did OpenAI extend the context window? -
On the other hand, whether the base model is the original GPT-3 or a later trained model, the ability to follow instructions and zero-shot generalization may have already existed in the base model and were later unlocked through instruction tuning (rather than injected). -
This is mainly because the instruction data size reported in OpenAI’s papers is only 77K, several orders of magnitude smaller than the pre-training data. -
Other instruction tuning papers further prove the comparison of dataset sizes on model performance; for example, in Chung et al. (2022), the instruction tuning for Flan-PaLM was only 0.4% of the pre-training computation. Generally, instruction data is significantly less than pre-training data. -
However, the model’s complex reasoning ability may have been injected during the pre-training phase through code data. -
The scale of the code dataset differs from that of the instruction tuning. The amount of code data is large enough to occupy an important part of the training data (for example, PaLM has 8% of code training data). -
As mentioned, the previous model text-davinci-001 likely did not undergo fine-tuning on code data, so its reasoning/chain-of-thought ability was very poor, as reported in the first chain-of-thought paper; sometimes it even performed worse than the smaller code-cushman-001. -
The best way to distinguish the effects of code training and instruction tuning may be to compare code-cushman-001, T5, and FlanT5. -
Because they have similar model sizes (11 billion and 12 billion), similar training datasets (C4), the biggest difference is whether they have been trained on code or undergone instruction tuning. -
Currently, there has not been such a comparison. We leave this for future research.
-
4. Text-Davinci-003 and ChatGPT,
The Power of Reinforcement Learning from Human Feedback
(RLHF)
5. Summary of the Evolution of GPT-3.5 at the Current Stage
4. Text-Davinci-003 and ChatGPT,
The Power of Reinforcement Learning from Human Feedback
(RLHF)
5. Summary of the Evolution of GPT-3.5 at the Current Stage
So far, we have carefully examined all the abilities that have emerged along the evolutionary tree, and the following table summarizes the evolutionary path:
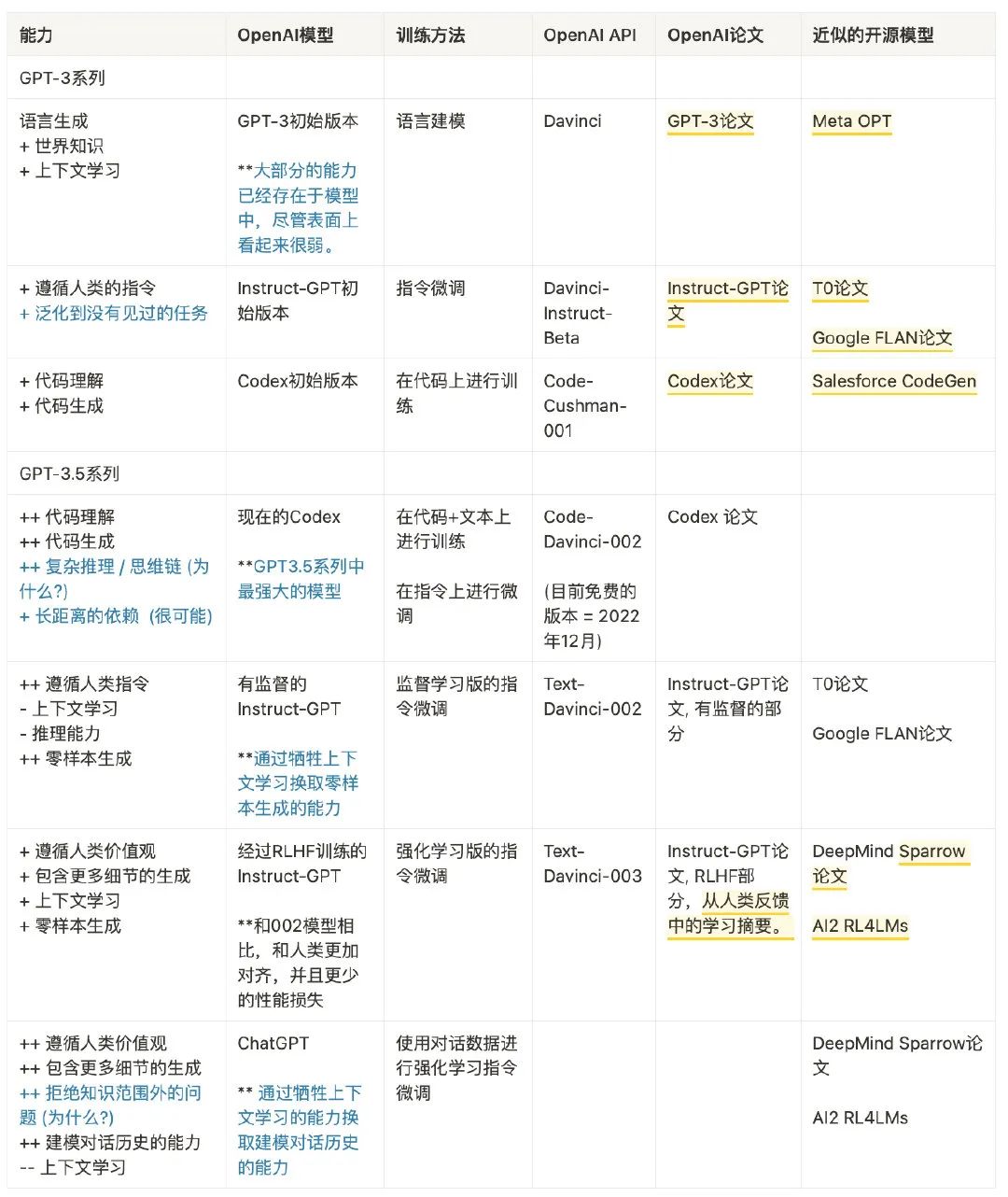
We can conclude:
-
Language generation ability + foundational world knowledge + in-context learning all come from pre-training ( <span>davinci</span>). -
The ability to store a large amount of knowledge comes from the 175 billion parameters. -
The ability to follow instructions and generalize to new tasks comes from expanding the number of instructions in instruction learning ( <span>Davinci-instruct-beta</span>). -
The ability to perform complex reasoning likely comes from code training ( <span>code-davinci-002</span>). -
The ability to generate neutral, objective, safe, and detailed answers comes from alignment with humans. Specifically: -
If it is a supervised learning version, the resulting model is <span>text-davinci-002</span> -
If it is a reinforcement learning version (RLHF), the resulting model is <span>text-davinci-003</span> -
Whether supervised or RLHF, the model’s performance on many tasks cannot exceed that of code-davinci-002; this phenomenon of performance degradation due to alignment is called alignment tax. -
The conversational ability also comes from RLHF ( <span>ChatGPT</span>), specifically sacrificing in-context learning ability to gain: -
Modeling conversational history -
Increasing the amount of information in conversations -
Refusing questions beyond the model’s knowledge scope
6. What GPT-3.5 Currently Cannot Do
7. Conclusion
6. What GPT-3.5 Currently Cannot Do
7. Conclusion
In this blog post, we carefully examined the capabilities of the GPT-3.5 series and traced the sources of all its emergent abilities. The original GPT-3 model gained generation capabilities, world knowledge, and in-context learning through pre-training. Then, through the instruction tuning model branch, it obtained the ability to follow instructions and generalize to unseen tasks. The code-trained branch model gained the ability to understand code, and as a byproduct of code training, the model also potentially acquired complex reasoning abilities. Combining these two branches, code-davinci-002 appears to be the strongest GPT-3.5 model with all powerful capabilities. Next, through supervised instruction tuning and RLHF, it achieved alignment with humans at the cost of model capabilities, known as alignment tax. RLHF enables the model to generate more detailed and fair answers while refusing questions beyond its knowledge scope.
We hope this article can help provide a clear assessment map for GPT and spark discussions about language models, instruction tuning, and code tuning. Most importantly, we hope this article can serve as a roadmap for reproducing GPT-3.5 within the open-source community.
“Because the mountain is there.” — George Mallory, pioneer of Everest exploration
Frequently Asked Questions
-
Are the statements in this article more like hypotheses or conclusions? -
The ability of complex reasoning comes from code training is a hypothesis we tend to believe. -
The ability to generalize to unseen tasks comes from large-scale instruction learning is the conclusion of at least four papers. -
GPT-3.5 comes from other large foundational models, not the 175 billion parameter GPT-3 is a well-founded guess. -
All these abilities existed and were unlocked through instruction tuning, whether supervised learning or reinforcement learning, rather than injected is a strong hypothesis, strong enough that you cannot not believe it. This is mainly because the amount of instruction tuning data is several orders of magnitude smaller than that of pre-training. -
Conclusion = Many pieces of evidence support the correctness of these statements; hypothesis = positive evidence but not strong enough; well-founded guess = no conclusive evidence, but some factors point in that direction. -
Why are other models (like OPT and BLOOM) not as powerful? -
OPT is likely due to an unstable training process. -
The situation with BLOOM is unknown. If you have more opinions, please contact me.
Appendix – English-Chinese Terminology Comparison
| English | Chinese | Definition |
|---|---|---|
| Emergent Ability | 突现能力 | Small models do not have, only appear when the model reaches a certain size. |
| Prompt | 提示词 | Inputting a prompt to the large model, which then provides a completion. |
| In-Context Learning | 上下文学习 | Writing several examples in the prompt allows the model to generate based on those examples. |
| Instruction Tuning | 指令微调 | Fine-tuning a large model using instructions. |
| Code Tuning | 在代码上微调 | Fine-tuning a large model using code. |
| Reinforcement Learning with Human Feedback (RLHF) | 基于人类反馈的强化学习 | Scoring the results generated by the model using human feedback to adjust the model. |
| Chain-of-Thought | 思维链 | When writing prompts, not only providing the result but also detailing how the result was derived step by step. |
| Scaling Laws | 缩放法则 | The effect of the model grows linearly requires an exponential growth in model size. |
| Alignment | 与人类对齐 | Enabling machines to generate sentences that align with human expectations and values. |
Latest Papers on Complex Science

Recommended Reading
-
CausalML: An Open Source Project for Causal Learning Based on Python -
Explainable AI Open Source Framework — XAITK -
Practicing Open Science, We Cast a Paper into NFT -
“Zhangjiang: Frontiers of Complex Science 27 Lectures” Fully Online! -
Become a Jizhi VIP and Unlock All Site Courses/Book Clubs -
Join Jizhi and Explore Complexity Together!