

Source: WeChat Official Account “Sensor Technology”
If someone throws a ball at you, what do you usually do? — Of course, you immediately catch it.
Is this question very silly? But in reality, this process is one of the most complex handling processes, and the actual process is roughly as follows: first, the ball enters the human retina, after a series of element analyses, it is sent to the brain, where the visual cortex thoroughly analyzes the image, sends it to the remaining cortex, compares it with any known objects, classifies the object and dimensions, and ultimately decides your next action: raise your hands, catch the ball (having already predicted its trajectory).

The above process occurs in just a fraction of a second, almost entirely subconsciously, and rarely makes mistakes. Therefore, reconstructing human vision is not just a single difficult topic, but a series of interconnected processes.
The Concept of Computer Vision Technology
Like other disciplines, a field studied by a large number of people for many years finds it difficult to provide a strict definition, such as pattern recognition, currently popular artificial intelligence, and computer vision. Concepts closely related to computer vision include visual perception, visual cognition, and image and video understanding. These concepts share some commonalities but also have essential differences.

Broadly speaking, computer vision is the discipline of “endowing machines with natural vision capabilities”. Natural vision capabilities refer to the visual abilities manifested by biological visual systems. Since biological natural vision cannot be strictly defined, and this broad definition of vision is “all-encompassing”, it does not quite conform to the research status of computer vision over the past 40 years. Therefore, this “broad definition of computer vision”, while impeccable, lacks substantive content and is merely a “circular game definition”.
In essence, computer vision is about studying visual perception issues. Visual perception, according to Wikipedia’s definition, refers to the process of organizing, recognizing, and interpreting visual information in the expression and understanding of the environment. Based on this definition, the goal of computer vision is to express and understand the environment; the core issue is to study how to organize the input image information, recognize objects and scenes, and subsequently interpret the content of the image.
Computer Vision (CV) is a discipline that studies how to enable computers to “see” like humans. More accurately, it is about using cameras and computers to replace human eyes, enabling computers to possess similar functions to humans for object segmentation, classification, recognition, tracking, and decision-making.
Computer vision simulates biological vision using computers and related devices. It is an important part of artificial intelligence, and its research goal is to enable computers to recognize three-dimensional environmental information through two-dimensional images. Computer vision is based on image processing technology, signal processing technology, probabilistic statistical analysis, computational geometry, neural networks, machine learning theory, and computer information processing technology, analyzing and processing visual information through computers.
Generally, the definition of computer vision should include the following three aspects:
-
1. Constructing a clear and meaningful description of objective objects in images;
-
2. Calculating the characteristics of the three-dimensional world from one or more digital images;
-
3. Making useful decisions about objective objects and scenes based on perceived images.
As an emerging discipline, computer vision attempts to establish artificial intelligence systems that extract “information” from images or multidimensional data through the study of relevant theories and technologies. Computer vision is a comprehensive discipline that includes computer science and engineering, signal processing, physics, applied mathematics, statistics, neurophysiology, and cognitive science, and is closely related to image processing, pattern recognition, projective geometry, statistical inference, statistical learning, and other disciplines. In recent years, it has also established strong connections with disciplines such as computer graphics and three-dimensional representation.
Artificial Intelligence and Computer Vision
Computer vision is closely related to artificial intelligence, but there are essential differences. The goal of artificial intelligence is to enable computers to see, hear, and read. The understanding of images, speech, and text constitutes the three main parts of current artificial intelligence. Among these fields of artificial intelligence, vision is the core. It is well known that vision accounts for 80% of all sensory input in humans and is also the most challenging part of perception. If artificial intelligence is a revolution, then it will originate from computer vision, not other fields.
Artificial intelligence emphasizes reasoning and decision-making, but at least currently, computer vision is still primarily at the stage of image information expression and object recognition. “Object recognition and scene understanding” also involves reasoning and decision-making from image features, but there are essential differences from the reasoning and decision-making of artificial intelligence.

The Relationship Between Computer Vision and Artificial Intelligence:
-
First, it is a very important problem that artificial intelligence needs to solve.
-
Second, it is currently a strong driving force for artificial intelligence. Many applications and technologies have emerged from computer vision and are then re-applied to the AI field.
-
Third, computer vision has a large foundation of quantum AI applications.
The Principles of Computer Vision Technology
Computer vision uses various imaging systems to replace visual organs as input-sensitive means, with computers replacing the brain to complete processing and interpretation. The ultimate research goal of computer vision is to enable computers to observe and understand the world through vision like humans, possessing the ability to autonomously adapt to the environment. Before achieving the final goal, the ultimate goal that people strive for is to establish a visual system that can complete certain tasks based on a certain degree of visual sensitivity and feedback intelligence. For example, an important application area of computer vision is the visual navigation of autonomous vehicles, which has not yet achieved the ability to recognize and understand any environment and complete autonomous navigation like humans. Therefore, the research goal is to achieve a visual assistance driving system that can track roads on highways and avoid collisions with vehicles ahead.
It should be noted that in computer vision systems, computers play the role of replacing the human brain, but this does not mean that computers must process visual information in the same way that human vision does. Computer vision can and should process visual information according to the characteristics of the computer system. However, the human visual system is, to date, the most powerful and complete visual system known to humans. Research on the mechanisms of human visual processing will provide inspiration and guidance for the research of computer vision. Therefore, using computer information processing methods to study the mechanisms of human vision and establish computational theories of human vision is also a very important and interesting research area.
This field of in-depth research began in the 1950s, taking three directions — replicating the human eye; replicating the visual cortex; and replicating the remaining parts of the brain.
Replicating the Human Eye — Enabling Computers to “See”
The most effective area so far has been in “replicating the human eye”. Over the past few decades, scientists have developed sensors and image processors that match, and even to some extent surpass, the human eye. With powerful, optically superior lenses and semiconductor pixels manufactured at a nanometer scale, the precision and sensitivity of modern cameras have reached an astonishing level. They can also capture thousands of images per second and measure distances with great accuracy.
However, the problem is that while we can achieve extremely high fidelity at the output end, in many respects, these devices are not superior to 19th-century pinhole cameras: they merely record the distribution of photons in the corresponding direction, and even the best camera sensors cannot “recognize” a ball, let alone catch it.
In other words, without software, hardware is quite limited. Therefore, the software in this area is the more challenging problem that needs to be addressed. However, the advanced technology of cameras indeed provides a rich and flexible platform for this software.
Replicating the Visual Cortex — Enabling Computers to “Describe”
It is important to know that the human brain fundamentally performs the action of “seeing” through consciousness. Compared to other tasks, a considerable part of the brain is dedicated to “seeing”, and this specialization is accomplished by the cells themselves — billions of cells working together to extract patterns from noisy, irregular retinal signals.
If there is a difference along a line at a specific angle or rapid movement in a certain direction, then a group of neurons will become excited. Higher-level networks will categorize these patterns into meta-patterns: one is a ring moving upward. At the same time, another network is formed: this time it is a white ring with a red line. And another pattern will grow in size. From these rough but complementary descriptions, specific images begin to be generated.

Using techniques similar to those in the human brain’s visual area, locating object edges and other features forms the “directional gradient histogram”.
Since these networks were once considered “deeply complex”, in the early stages of computer vision research, another approach was adopted: the “top-down reasoning” model — for example, a book looks “like this”, so pay attention to patterns similar to “this”. A car looks “like this”, and when it moves, it looks “like this”.
In certain controlled situations, this process can indeed be completed for a few objects, but to describe every object around, including all angles, lighting changes, movements, and hundreds of other factors, even recognition at the level of babbling infants requires unimaginably large amounts of data.
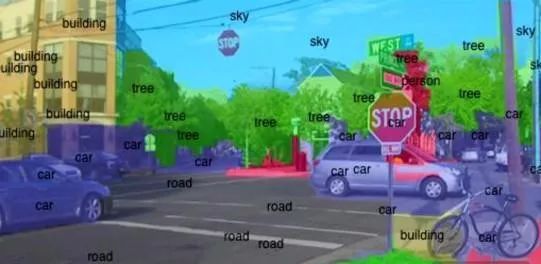
However, if instead of using a “top-down” approach, we adopt a “bottom-up” method, simulating the processes in the brain, the prospects look more promising: computers can perform a series of transformations on a picture among multiple images to find the edges of objects, discover objects, angles, and motion in the image. Just like the human brain, by showing various shapes to the computer, it will use a large amount of computation and statistics to try to match the “seen” shapes with those recognized in previous training.
Scientists are studying how to enable smartphones and other devices to understand and quickly recognize objects in the camera’s field of view. As shown in the image above, objects in the street scene are labeled with text describing the objects, and the processor completing this process is 120 times faster than traditional smartphone processors.
With the advancements in parallel computing in recent years, related barriers are gradually being removed. There has been explosive growth in research and applications mimicking brain-like functions. The process of pattern recognition is gaining orders of magnitude acceleration, and we are making more progress every day.
Replicating the Remaining Parts of the Brain — Enabling Computers to “Understand”
Of course, merely “recognizing” and “describing” is not enough. A system can recognize an apple, including in any situation, at any angle, and in any motion state, even if it has been bitten, etc. But it still cannot recognize an orange. Moreover, it cannot even tell people: what is an apple? Can it be eaten? What is its size? Or what is its specific use?

As mentioned earlier, without software, hardware performance is very limited. But now the problem is that even with excellent software and hardware, without an outstanding operating system, it is still “useless”.
For humans, the remaining parts of the brain consist of long-term and short-term memory, inputs from other senses, attention and cognition, and billions of knowledge acquired from trillions of interactions with the world, which are written into interconnected neurons in ways we find difficult to understand. Replicating this is more complex than anything we have encountered.
Image Processing Methods in Computer Vision Technology
The processing technology of visual information in computer vision systems mainly relies on image processing methods, including image enhancement, data encoding and transmission, smoothing, edge sharpening, segmentation, feature extraction, image recognition, and understanding. After these processes, the quality of the output image is significantly improved, enhancing both the visual effect of the image and making it easier for computers to analyze, process, and recognize the image.
Image Enhancement
Image enhancement is used to adjust the contrast of the image, highlight important details in the image, and improve visual quality. The gray histogram modification technique is commonly used for image enhancement. The gray histogram of an image represents the statistical characteristics of the gray distribution of the image and is closely related to contrast. By examining the shape of the gray histogram, one can determine the clarity and black-and-white contrast of the image. If the histogram effect of an image is not ideal, it can be appropriately modified through histogram equalization processing, which maps the pixel gray levels of an image with a known gray probability distribution into a new image with a uniform gray probability distribution, achieving the goal of making the image clear.

Image Smoothing
Image smoothing processing technology refers to the denoising process of images, mainly aimed at removing distortions in images caused by imaging devices and environments, and extracting useful information. It is well-known that actual images obtained during formation, transmission, reception, and processing inevitably suffer from external and internal interferences, such as uneven sensitivity of sensitive components during photoelectric conversion, quantization noise during digitization, errors during transmission, and human factors, which can degrade the image. Therefore, removing noise and restoring the original image is an important aspect of image processing.
Data Encoding and Transmission of Images
The amount of data in digital images is quite large. A digital image with 512×512 pixels has a data volume of 256 K bytes. Assuming a transmission of 25 frames of images per second, the transmission channel rate would be 52.4 M bits/second. High channel rates imply high investments and increased difficulty in popularization. Therefore, compressing image data during transmission becomes very important. Data compression is mainly completed through image data encoding and transformation. Image data encoding generally adopts predictive coding, which expresses the spatial and sequential variations of image data using a predictive formula. If the values of neighboring pixels are known, the value of a certain pixel can be predicted using the formula. This method can compress the data of an image down to a few dozen bits for transmission, which can then be transformed back at the receiving end.
Edge Sharpening
Image edge sharpening processing primarily enhances the contours and details in the image, forming complete object boundaries, achieving the goal of isolating objects from the image or detecting regions that represent the same object’s surface. It is a fundamental issue in early visual theories and algorithms, and one of the important factors determining the success of mid and late-stage vision.
Image Segmentation
Image segmentation divides an image into several parts, each corresponding to a certain object surface. During segmentation, the gray level or texture of each part conforms to a certain uniform measure. Essentially, it classifies pixels based on their gray values, colors, spectral characteristics, spatial characteristics, or texture characteristics. Image segmentation is one of the fundamental methods of image processing technology, applied in areas such as chromosome classification, scene understanding systems, and machine vision. There are two main methods of image segmentation: one is the gray threshold segmentation method based on metrics, which determines the clustering of pixels in the spatial domain of the image based on the image’s gray histogram. The second is the region-growing segmentation method in the spatial domain, which connects pixels that have similar properties (such as gray levels, organization, gradients, etc.) to form segmented regions. This method has good segmentation results, but its downside is complex calculations and slow processing speeds.
Data-Driven Segmentation
Common data-driven segmentation includes edge detection-based segmentation, region-based segmentation, and a combination of edge and region segmentation. For edge detection-based segmentation, the basic idea is to first detect edge points in the image and then connect them according to certain strategies to form contours, thereby creating segmentation regions. The challenge lies in the contradiction between noise resistance performance and detection accuracy during edge detection. Improving detection accuracy can lead to unreasonable contours due to spurious edges caused by noise; increasing noise resistance can result in missed edges and positional deviations. Therefore, various multi-scale edge detection methods have been proposed, designing combinations of multi-scale edge information according to practical problems to better balance noise resistance performance and detection accuracy.
The basic idea of region-based segmentation is to partition the image space into different regions based on the characteristics of image data. Common features include gray or color features directly from the original image and features obtained from transformations of original gray or color values. Methods include threshold methods, region-growing methods, clustering methods, and relaxation methods.
Edge detection can obtain the intensity of local changes in gray or color values, while region segmentation can detect the similarity and uniformity of features. By combining both, edge points can be limited to avoid excessive segmentation of regions; at the same time, region segmentation can supplement missed edges, making contours more complete. For example, first perform edge detection and connection, then compare the features (gray mean, variance) of adjacent regions, and if they are close, merge them; perform edge detection and region growing on the original image separately to obtain edge and region fragment maps, which are then fused according to certain criteria to achieve the final segmentation result.
Model-Driven Segmentation
Common model-driven segmentation includes dynamic contour (Snakes) models, combinatorial optimization models, and target geometric and statistical models. The Snakes model is used to describe the dynamic contours of segmentation targets. Due to its energy function employing integral operations, it has good noise resistance and is not sensitive to local blurriness of the target, making it widely applicable. However, this segmentation method is prone to converge to local optima, so the initial contour should be as close to the true contour as possible.
In recent years, research on universal segmentation methods has tended to treat segmentation as a combinatorial optimization problem, employing a series of optimization strategies to complete image segmentation tasks. The main idea is to define an optimization objective function based on specific tasks beyond the constraints defined for segmentation, where the solution to the sought segmentation is the global optimum of that objective function under the constraints. By treating the segmentation problem from a combinatorial optimization perspective, the segmentation task is framed as optimizing the objective function that comprehensively represents various requirements and constraints.
Segmentation based on target geometric and statistical models integrates target segmentation and recognition, commonly referred to as target detection or extraction. The basic idea is to represent the geometric and statistical knowledge related to the target as a model, transforming segmentation and recognition into matching or supervised classification tasks. Common models include templates, feature vector models, and connection-based models. This segmentation method can simultaneously complete part or all of the recognition tasks, achieving high efficiency. However, due to variations in imaging conditions, targets in actual images often differ from the models, leading to the need to address the contradiction of false positives and missed detections, making the matching process time-consuming.
Image Recognition
The image recognition process can actually be viewed as a labeling process, using recognition algorithms to identify each object in the segmented scene and assign a specific label to it, which is a task that the computer vision system must complete. Based on the difficulty of image recognition, it can be divided into three categories. The first category of recognition problems involves pixels in the image expressing a specific piece of information about an object. The second category involves tangible wholes to be recognized. Two-dimensional image information is sufficient to recognize the object, such as text recognition or recognition of certain three-dimensional bodies with stable visible surfaces. The third category involves deriving a three-dimensional representation of the measured object from input two-dimensional images, feature maps, or 2×5-dimensional maps. This raises the question of how to extract implicit three-dimensional information, which is a hot research topic today.

The methods currently used for image recognition are mainly divided into decision theory and structural methods. The basis of decision theory methods is the decision function, which uses it to classify and recognize pattern vectors, based on timed descriptions (such as statistical textures); the core of structural methods is to decompose objects into patterns or pattern primitives, where different object structures have different sequences of primitives (or strings), using the given pattern primitives to find the coding boundaries of unknown objects and obtain strings, then judging their categories based on the strings. This is a method that relies on symbolic descriptions of the relationships between measured objects.
Application Areas of Computer Vision
The application areas of computer vision mainly include the interpretation of photographs and video materials such as aerial photos, satellite photos, video clips, precise guidance, visual navigation of mobile robots, medical auxiliary diagnosis, hand-eye systems of industrial robots, map drawing, three-dimensional shape analysis and recognition of objects, and intelligent human-computer interfaces.
One of the early purposes of digital image processing was to improve the quality of photos using digital technology, assisting in the reading, judgment, and classification of aerial and satellite photos. Due to the large number of photos that need to be interpreted, there was a desire for an automatic visual system to perform interpretation. In this context, many systems and methods for interpreting aerial and satellite photos were developed. The further application of automatic interpretation is to directly determine the nature of targets, perform real-time automatic classification, and combine this with guidance systems. Currently, common guidance methods include laser guidance, television guidance, and image guidance. In missile systems, inertial guidance is often combined with image guidance, using images for precise terminal guidance.
The hand-eye system of industrial robots is one of the most successful application areas of computer vision. Due to many controllable factors in industrial environments, such as lighting conditions and imaging directions, this greatly simplifies the problem and facilitates the construction of practical systems. Unlike industrial robots, mobile robots must solve behavioral planning issues, which means understanding the environment. With the development of mobile robots, there is an increasing demand for visual capabilities, including road tracking, obstacle avoidance, and specific target recognition. Currently, research on mobile robot vision systems is still in the experimental stage, mostly employing remote control and long-distance vision methods.
The image processing technologies used in medicine generally include compression, storage, transmission, and automatic/assisted classification interpretation, and can also serve as training tools for doctors. Work related to computer vision includes classification, interpretation, and rapid three-dimensional structure reconstruction. For a long time, map drawing has been a labor-intensive, resource-intensive, and time-consuming task. Previously, this was done manually, but now it is more common to use aerial measurements combined with methods to recover three-dimensional shapes in stereo vision, greatly improving the efficiency of map drawing. At the same time, general three-dimensional shape analysis and recognition of objects has been an important research goal of computer vision, achieving some progress in feature extraction, representation, knowledge storage, retrieval, and matching recognition, forming systems used for three-dimensional scene analysis.

In recent years, biometric identification technology has received widespread attention, mainly focusing on features such as faces, irises, fingerprints, and voices, most of which are related to visual information. Another important application closely related to biometric recognition is to form intelligent human-computer interfaces. Currently, communication between computers and humans is still mechanical, and computers cannot recognize the true identity of users, and other input methods besides keyboards and mice are still immature. Using computer vision technology can enable computers to detect whether a user is present, identify user identity, and recognize user gestures (such as nodding or shaking head). Additionally, this form of human-computer interaction can be extended to any situation requiring human-computer interaction, such as access security control and customs clearance of personnel.

Editor: Lemon
