Click on the above “Beginner Learning Vision” to select “Star Mark” or “Top”
Important content delivered to you firstThe development of artificial intelligence relies on a basic support layer and a technical layer. The basic support layer includes big data, computing power, and algorithms; the technical layer includes computer vision, speech recognition, and natural language processing. What is the technical essence of artificial intelligence? This article will analyze it in detail.
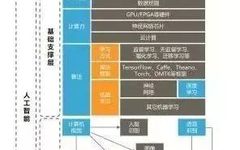
Overview of Artificial Intelligence Technology Map
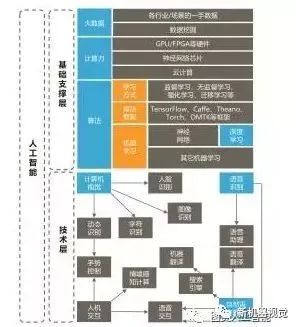
The algorithm innovation in the basic support layer occurred in the late 1980s, when big data and computing power brought artificial intelligence into the spotlight. The foundational technologies built on this are computer vision, speech recognition, and natural language understanding. Machines attempt to understand and communicate with humans using human language, studying the patterns of human intelligent activities.
1) What is Computer Vision
“About 70% of the activity in the human cerebral cortex is related to processing visual information. Vision is like the main door of the human brain, while other senses such as hearing, touch, and taste are narrower channels. Vision is like an eight-lane highway, while other senses are pedestrian paths on the sides. If visual information cannot be processed, the entire artificial intelligence system is just an empty shell, capable only of symbolic reasoning, like playing chess or theorem proving, and cannot enter the real world. Computer vision is to artificial intelligence what ‘Open Sesame’ is. The door is here; if it cannot open, it is impossible to study real-world artificial intelligence.” — Zhu Songchun, Professor of Statistics and Computer Science at UCLA, defines computer vision as a science that studies how to make machines “see”. More specifically, it refers to using computers to replace human eyes in recognizing, tracking, and measuring targets, and further performing image processing to make computer processing more suitable for human observation or for transmission to instruments for detection.
2) Computer Vision vs Machine Vision
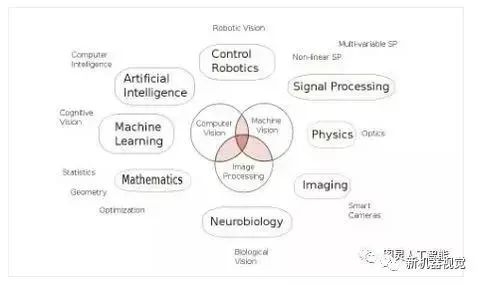
Computer vision focuses more on the study of image signals themselves and related interdisciplinary fields (maps, medical imaging); machine vision emphasizes the engineering of computer vision technology, focusing more broadly on image signals (like lasers and cameras) and applications in automation control (production lines).
3) Classification of Computer Vision Recognition Technologies
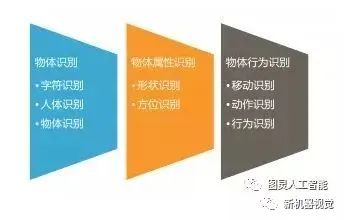
Object recognition is divided into “1 vs N” for categorizing different objects and “1 vs 1” for distinguishing and identifying similar objects; object attribute recognition combines map models to reconstruct memory of objects in visual three-dimensional space, and then analyze and judge scenes; object behavior recognition consists of three progressive steps: movement recognition to determine if an object has moved, action recognition to determine what action the object has taken, and behavior recognition that combines visual subjects and scene interactions to analyze and judge behavior.
4) Recognition Process of Computer Vision
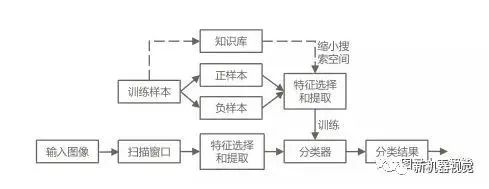
The recognition process of computer vision is divided into two routes: model training and image recognition.
Model training: Sample data includes positive samples (samples containing the target to be detected) and negative samples (samples without the target). The visual system uses algorithms to select and extract features from the raw samples to train a classifier (model); additionally, due to the thousands of sample data and the doubling of extracted features, to shorten the training process, a knowledge base is often artificially added (telling the computer some rules in advance) or constraints are introduced to reduce the search space.
Image recognition: The image undergoes signal transformation, noise reduction, and other preprocessing steps, followed by the use of the classifier for target detection on the input image. Generally, the detection process involves sliding a scanning sub-window across the image being detected; at each position, the features of that area are calculated, and then the trained classifier is used to filter those features to determine if that area is the target.
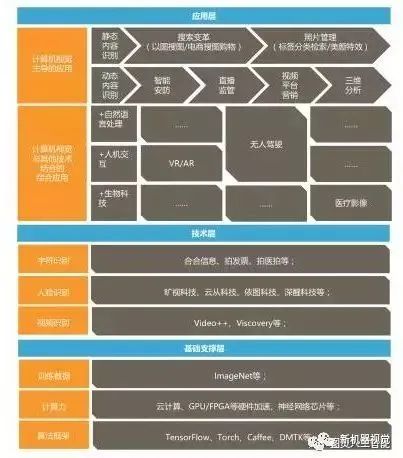
5) Computer Vision Technology Model Diagram and Corresponding Enterprise Diagram
The largest database for image recognition in the world is ImageNet provided by Stanford University’s AI Lab, which also needs to collect corresponding training data for specific fields like healthcare; tech giants like Google and Microsoft provide open-source algorithm frameworks to the market for startup visual recognition companies.
1) What is Speech Recognition
Speech recognition is a technology that studies speech as the object, allowing machines to automatically recognize and understand human spoken language through signal processing and recognition technology, converting speech signals into corresponding text or commands. Speech interaction, combining speech recognition, speech synthesis, natural language understanding, and semantic networks, is gradually becoming the main way of multi-channel, multimedia intelligent human-computer interaction.
2) The Process of Speech Recognition
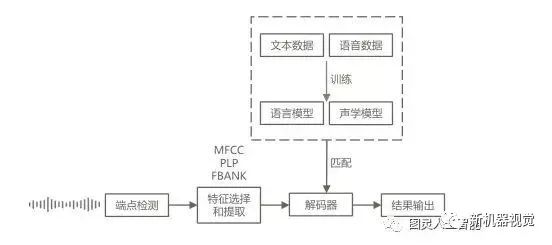
The speech recognition process is divided into training and recognition routes.
After the speech signal undergoes front-end signal processing, endpoint detection, and other preprocessing, speech features are extracted frame by frame. Traditional feature types include MFCC, PLP, FBANK, etc. The extracted features are sent to the decoder, which finds the most matching sequence as the recognition result output under the trained acoustic model and language model.
3) Speech Recognition Technology Model Diagram and Corresponding Enterprise Diagram

Basic layer: includes big data, computing power, and algorithms, where big data connects to third-party service providers in the respective fields. After recognizing human voice commands, machines connect and provide corresponding services, such as for films, movie tickets, dining, etc.;
Technical layer: speech technology providers led by iFlytek;
Application layer: traditional home environment television and speaker manufacturers have added speech recognition functions, introducing new interaction methods; intelligent vehicles also use speech interaction to keep hands on the wheel, enhancing safety; search providers have created voice assistants based on search.
1) What is Natural Language Understanding
Natural language understanding, or text understanding, is fundamentally different from pattern recognition technologies for speech and images. Language, as a carrier of knowledge, carries complex amounts of information and has a high degree of abstraction. Understanding language belongs to the cognitive level and cannot be completed solely by pattern matching.
2) Applications of Natural Language Understanding: Search Engines + Machine Translation;
The two most typical applications of natural language understanding are search engines and machine translation. Search engines can understand human natural language to some extent, extracting key content from natural language for retrieval, ultimately achieving good connections between search engines and natural language users, establishing a more efficient and deeper information transmission between the two.
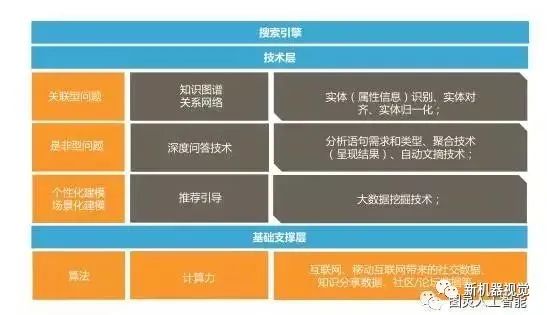
3) Application of Natural Language Understanding Technology in Search Engines
4) Application of Natural Language Understanding Technology in Machine Translation
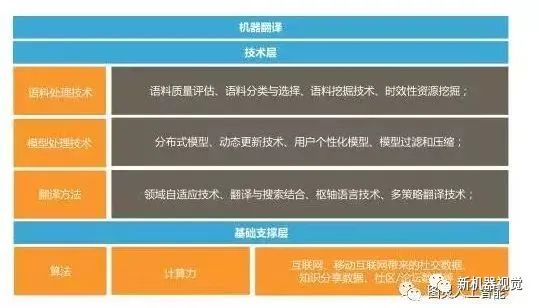
In fact, search engines and machine translation are inseparable. The internet and mobile internet have enriched their corpus, leading to a qualitative change in their development model. The internet and mobile internet not only onlineize the previously offline information (existing corpus) but also generate new UGC models: knowledge sharing data, such as Wikipedia and Baidu Baike, which are humanly calibrated entries with low noise; social data, like Weibo and WeChat, which display user personalization, subjectivity, and timeliness, can be used for personalized recommendations, sentiment analysis, and detection and tracking of trending topics; community and forum data, like Guokr and Zhihu, provide search engines with Q&A knowledge and resources. On the other hand, the black box model of deep learning, which learns spontaneously from large-scale data, is not explainable, while communication between people mediated by language should be based on mutual understanding. Therefore, the utility of deep learning in search engines and machine translation is not as significant as in speech and image recognition fields.
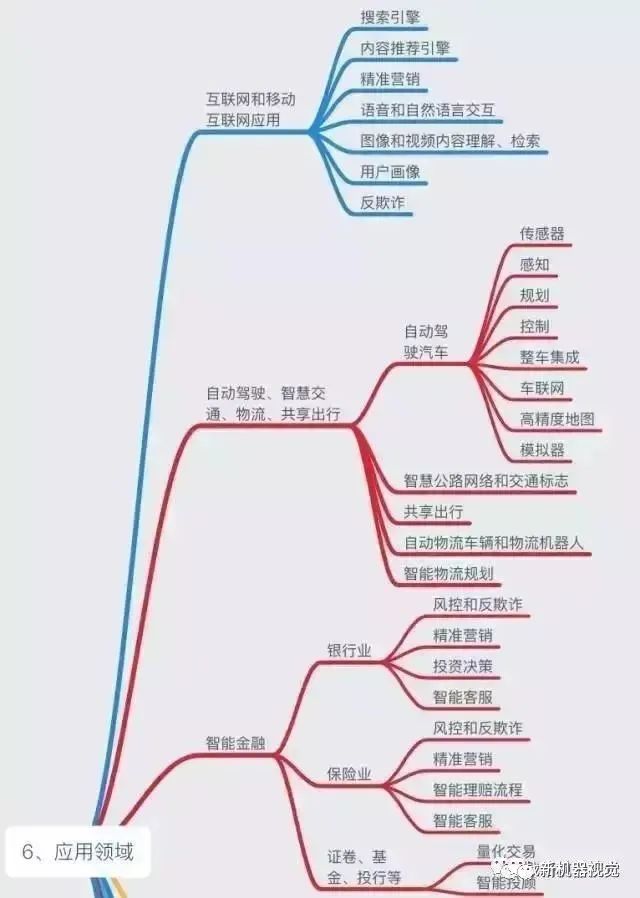
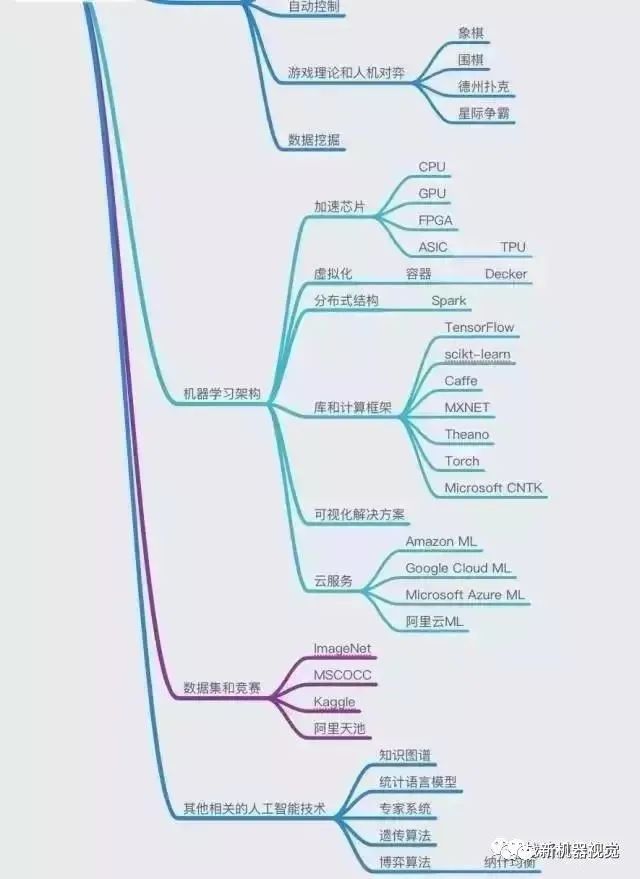
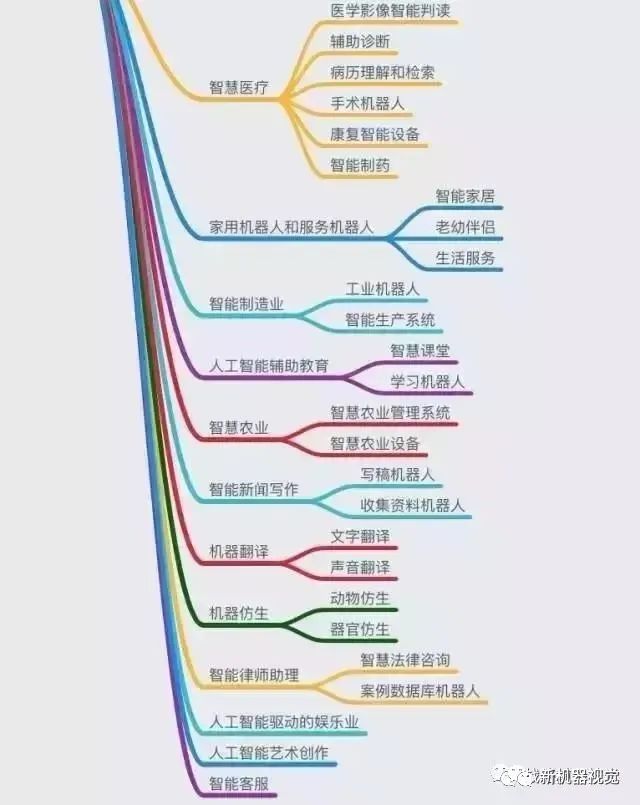
One image to understand the new generation
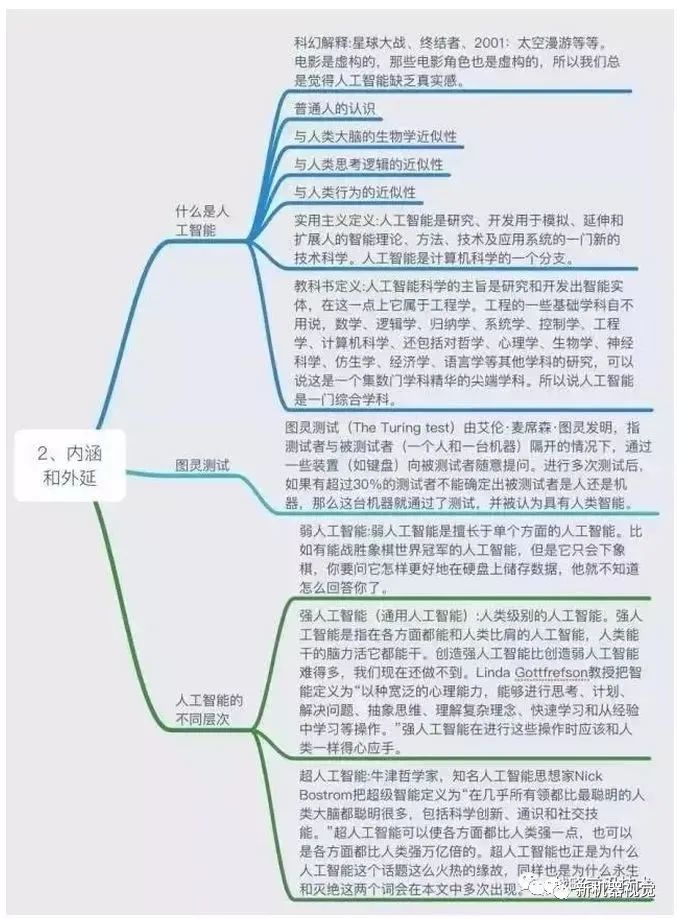
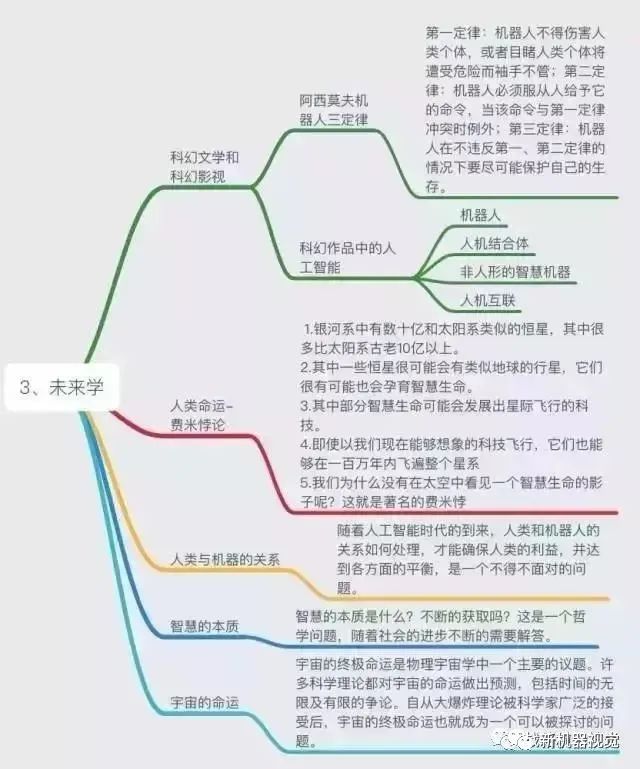
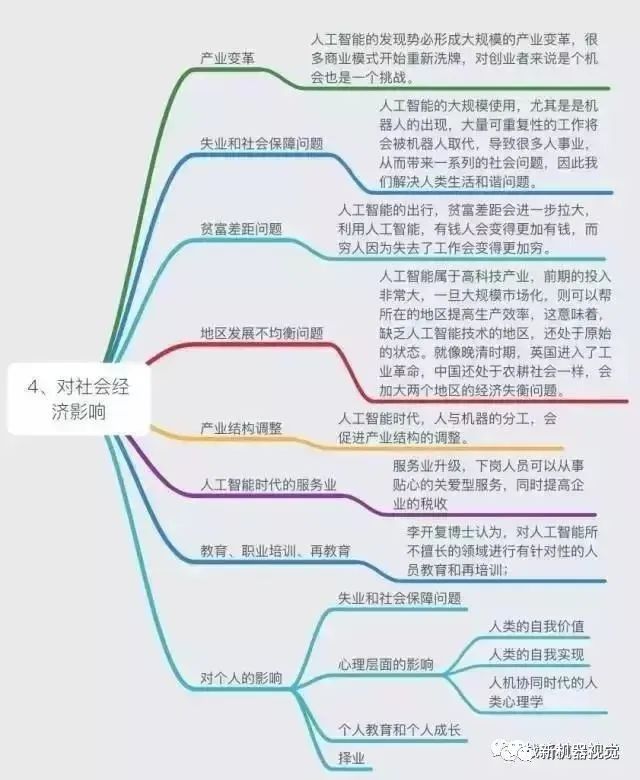
Comprehensive Knowledge System of Artificial Intelligence



Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply “Extension Module Chinese Tutorial” in the backend of the “Beginner Learning Vision” public account to download the first OpenCV extension module tutorial in Chinese available online, covering installation of the extension module, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters.
Download 2: Python Vision Practical Project 52 Lectures
Reply “Python Vision Practical Project” in the backend of the “Beginner Learning Vision” public account to download 31 practical vision projects, including image segmentation, mask detection, lane detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply “OpenCV Practical Project 20 Lectures” in the backend of the “Beginner Learning Vision” public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Discussion Group
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, the request will not be approved. After successful addition, you will be invited into related WeChat groups based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding.~