This series of articles follows the “MetaGPT Multi-Agent Course” (https://github.com/datawhalechina/hugging-multi-agent), deeply understanding and practicing the development of multi-agent systems.
This article is the fifth note of the fourth chapter (Multi-Agent Development) of the course. Today we will analyze a previously mentioned multi-agent case – BabyAGI, clarifying its implementation principles and the interaction process among agents (data flow). This is the most native multi-agent case, implemented without any multi-agent frameworks like AutoGPT or MetaGPT. From this case, we can better understand the underlying implementation principles of agents.
Series Notes
-
• 【AI Agent Series】【MetaGPT Multi-Agent Learning】0. Environment Preparation – Upgrading to MetaGPT version 0.7.2 and the pitfalls encountered
-
• 【AI Agent Series】【MetaGPT Multi-Agent Learning】1. Re-understanding AI Agents – Overview of Classic Cases and Popular Frameworks
-
• 【AI Agent Series】【MetaGPT Multi-Agent Learning】2. Revisiting Single-Agent Development – Delving into Source Code to Understand Single-Agent Operating Framework
-
• 【AI Agent Series】【MetaGPT Multi-Agent Learning】3. Developing a Simple Multi-Agent System while Observing MetaGPT Multi-Agent Operating Mechanism
-
• 【AI Agent Series】【MetaGPT Multi-Agent Learning】4. Developing Your First Agent Team Based on MetaGPT’s Team Component
-
• 【MetaGPT Multi-Agent Learning】5. Multi-Agent Case Analysis – Agent Debate Based on MetaGPT (with complete code)
-
• 【AI Agent Practical】6. All-Inclusive Tutorial: Complete Guide to Creating the 【You Draw, I Guess】 Game Based on MetaGPT (with complete code)
0. Introduction to BabyAGI
Project Address: https://github.com/yoheinakajima/babyagi/blob/main/README.md
This project is an example of an AI-supported task management system that creates a task list based on an initial task or goal, prioritizes tasks, and executes them using OpenAI. The main idea behind it is to create tasks based on the results of previous tasks and predefined goals, and then use OpenAI’s capabilities to create new tasks according to the goals. This is a simplified version of the original task-driven self-driving agent (March 28, 2023).
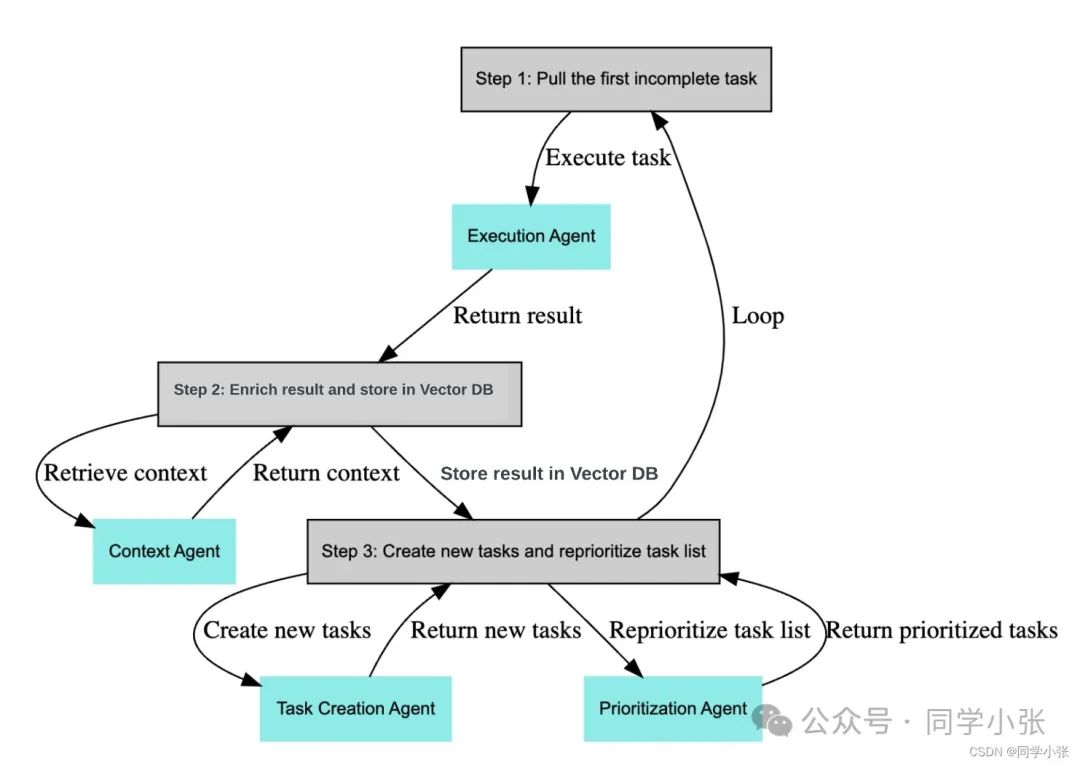
0.1 Operational Process
The operational process is as follows:
(1) Extract the first task from the task list
(2) Send the task to the Execution Agent, which uses LLM to complete the task based on the context.
(3) Enrich the results and store them in a vector database
(4) Create new tasks and re-prioritize the task list based on the goals and results of the previous task.
(5) Repeat the above steps
This involves four agents, the first three of which utilize the capabilities of large models for task planning and summarization:
-
• The Execution Agent receives goals and tasks and calls the large model LLM to generate task results.
-
• The Task Creation Agent uses the large model LLM to create new tasks based on the goals and results of the previous task. Its inputs are: goals, results of the previous task, task description, and current task list.
-
• The Prioritization Agent uses the large model LLM to reorder the task list. It accepts one parameter: the ID of the current task.
-
• The Context Agent uses vector storage and retrieval of task results to obtain context.
The official data flow diagram is as follows:
1. Running BabyAGI
To better understand its principles and workflow, we first need to run the project.
1.1 Downloading the Open Source Code
git clone https://github.com/yoheinakajima/babyagi.git
pip install -r requirements.txt1.2 Filling in the Configuration File
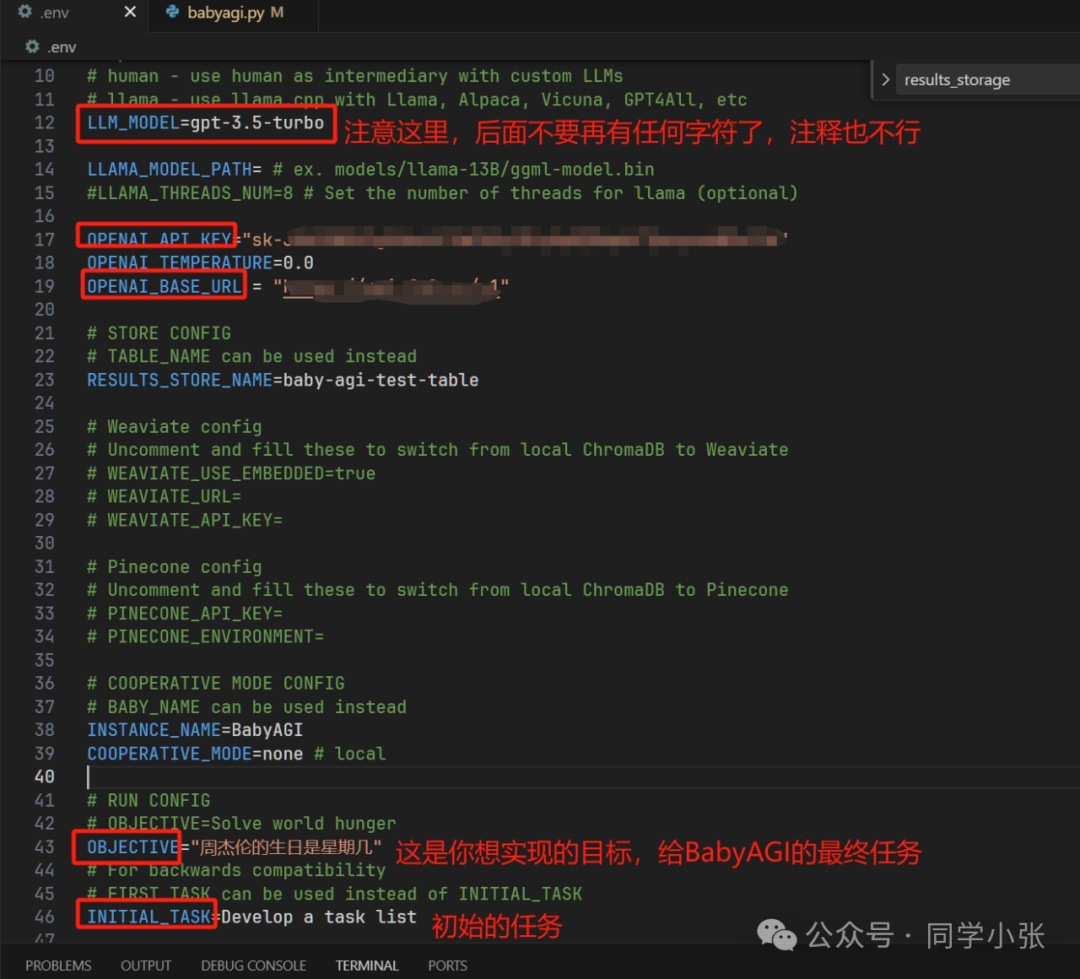
(1) Copy the .env.example file and rename it to .env
cp .env.example .env(2) Fill in your OpenAI key, OpenAI Base URL, etc. in the .env file. My run does not use Weaviate and Pinecone, so I do not fill in the related config.
1.3 Simplified Code
Since my run does not use Weaviate and Pinecone, and only uses the OpenAI model, I removed the unused code to make it look cleaner. Then, I adapted it to the OpenAI API > 1.0 version interface. The original code used the API < 1.0, which is too old.
#!/usr/bin/env python3
from dotenv import load_dotenv
# Load default environment variables (.env)
load_dotenv()
import os
import time
import logging
from collections import deque
from typing import Dict, List
import importlib
# import openai
import chromadb
import tiktoken as tiktoken
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
from chromadb.api.types import Documents, EmbeddingFunction, Embeddings
import re
from openai import OpenAI
# default opt out of chromadb telemetry.
from chromadb.config import Settings
client = chromadb.Client(Settings(anonymized_telemetry=False))
# Engine configuration
# Model: GPT, LLAMA, HUMAN, etc.
LLM_MODEL = os.getenv("LLM_MODEL", os.getenv("OPENAI_API_MODEL", "gpt-3.5-turbo")).lower()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "")
# API Keys
if not (LLM_MODEL.startswith("llama") or LLM_MODEL.startswith("human")):
assert OPENAI_API_KEY, "\033[91m\033[1m" + "OPENAI_API_KEY environment variable is missing from .env" + "\033[0m\033[0m"
# Table config
RESULTS_STORE_NAME = os.getenv("RESULTS_STORE_NAME", os.getenv("TABLE_NAME", ""))
assert RESULTS_STORE_NAME, "\033[91m\033[1m" + "RESULTS_STORE_NAME environment variable is missing from .env" + "\033[0m\033[0m"
# Run configuration
INSTANCE_NAME = os.getenv("INSTANCE_NAME", os.getenv("BABY_NAME", "BabyAGI"))
COOPERATIVE_MODE = "none"
JOIN_EXISTING_OBJECTIVE = False
# Goal configuration
OBJECTIVE = os.getenv("OBJECTIVE", "")
INITIAL_TASK = os.getenv("INITIAL_TASK", os.getenv("FIRST_TASK", ""))
# Model configuration
OPENAI_TEMPERATURE = float(os.getenv("OPENAI_TEMPERATURE", 0.0))
# Extensions support begin
def can_import(module_name):
try:
importlib.import_module(module_name)
return True
except ImportError:
return False
DOTENV_EXTENSIONS = os.getenv("DOTENV_EXTENSIONS", "").split(" ")
# Command line arguments extension
# Can override any of the above environment variables
ENABLE_COMMAND_LINE_ARGS = (
os.getenv("ENABLE_COMMAND_LINE_ARGS", "false").lower() == "true"
)
if ENABLE_COMMAND_LINE_ARGS:
if can_import("extensions.argparseext"):
from extensions.argparseext import parse_arguments
OBJECTIVE, INITIAL_TASK, LLM_MODEL, DOTENV_EXTENSIONS, INSTANCE_NAME, COOPERATIVE_MODE, JOIN_EXISTING_OBJECTIVE = parse_arguments()
# Human mode extension
# Gives human input to babyagi
if LLM_MODEL.startswith("human"):
if can_import("extensions.human_mode"):
from extensions.human_mode import user_input_await
# Load additional environment variables for enabled extensions
# TODO: This might override the following command line arguments as well:
# OBJECTIVE, INITIAL_TASK, LLM_MODEL, INSTANCE_NAME, COOPERATIVE_MODE, JOIN_EXISTING_OBJECTIVE
if DOTENV_EXTENSIONS:
if can_import("extensions.dotenvext"):
from extensions.dotenvext import load_dotenv_extensions
load_dotenv_extensions(DOTENV_EXTENSIONS)
# TODO: There's still work to be done here to enable people to get
# defaults from dotenv extensions, but also provide command line
# arguments to override them
# Extensions support end
print("\033[95m\033[1m" + "\n*****CONFIGURATION*****\n" + "\033[0m\033[0m")
print(f"Name : {INSTANCE_NAME}")
print(f"Mode : {'alone' if COOPERATIVE_MODE in ['n', 'none'] else 'local' if COOPERATIVE_MODE in ['l', 'local'] else 'distributed' if COOPERATIVE_MODE in ['d', 'distributed'] else 'undefined'}")
print(f"LLM : {LLM_MODEL}")
# Check if we know what we are doing
assert OBJECTIVE, "\033[91m\033[1m" + "OBJECTIVE environment variable is missing from .env" + "\033[0m\033[0m"
assert INITIAL_TASK, "\033[91m\033[1m" + "INITIAL_TASK environment variable is missing from .env" + "\033[0m\033[0m"
print("\033[94m\033[1m" + "\n*****OBJECTIVE*****\n" + "\033[0m\033[0m")
print(f"{OBJECTIVE}")
if not JOIN_EXISTING_OBJECTIVE:
print("\033[93m\033[1m" + "\nInitial task:" + "\033[0m\033[0m" + f" {INITIAL_TASK}")
else:
print("\033[93m\033[1m" + f"\nJoining to help the objective" + "\033[0m\033[0m")
# Results storage using local ChromaDB
class DefaultResultsStorage:
def __init__(self):
logging.getLogger('chromadb').setLevel(logging.ERROR)
# Create Chroma collection
chroma_persist_dir = "chroma"
chroma_client = chromadb.PersistentClient(
settings=chromadb.config.Settings(
persist_directory=chroma_persist_dir,
)
)
metric = "cosine"
embedding_function = OpenAIEmbeddingFunction(api_key=OPENAI_API_KEY)
self.collection = chroma_client.get_or_create_collection(
name=RESULTS_STORE_NAME,
metadata={"hnsw:space": metric},
embedding_function=embedding_function,
)
def add(self, task: Dict, result: str, result_id: str):
# Break the function if LLM_MODEL starts with "human" (case-insensitive)
if LLM_MODEL.startswith("human"):
return
# Continue with the rest of the function
embeddings = llm_embed.embed(result) if LLM_MODEL.startswith("llama") else None
if (
len(self.collection.get(ids=[result_id], include=[]) ["ids"]) > 0
): # Check if the result already exists
self.collection.update(
ids=result_id,
embeddings=embeddings,
documents=result,
metadatas={"task": task["task_name"], "result": result},
)
else:
self.collection.add(
ids=result_id,
embeddings=embeddings,
documents=result,
metadatas={"task": task["task_name"], "result": result},
)
def query(self, query: str, top_results_num: int) -> List[dict]:
count: int = self.collection.count()
if count == 0:
return []
results = self.collection.query(
query_texts=query,
n_results=min(top_results_num, count),
include=["metadatas"]
)
return [item["task"] for item in results["metadatas"][0]]
# Initialize results storage
def use_chroma():
print("\nUsing results storage: " + "\033[93m\033[1m" + "Chroma (Default)" + "\033[0m\033[0m")
return DefaultResultsStorage()
results_storage = use_chroma()
# Task storage supporting only a single instance of BabyAGI
class SingleTaskListStorage:
def __init__(self):
self.tasks = deque([])
self.task_id_counter = 0
def append(self, task: Dict):
self.tasks.append(task)
def replace(self, tasks: List[Dict]):
self.tasks = deque(tasks)
def popleft(self):
return self.tasks.popleft()
def is_empty(self):
return False if self.tasks else True
def next_task_id(self):
self.task_id_counter += 1
return self.task_id_counter
def get_task_names(self):
return [t["task_name"] for t in self.tasks]
# Initialize tasks storage
tasks_storage = SingleTaskListStorage()
if COOPERATIVE_MODE in ['l', 'local']:
if can_import("extensions.ray_tasks"):
import sys
from pathlib import Path
sys.path.append(str(Path(__file__).resolve().parent))
from extensions.ray_tasks import CooperativeTaskListStorage
tasks_storage = CooperativeTaskListStorage(OBJECTIVE)
print("\nReplacing tasks storage: " + "\033[93m\033[1m" + "Ray" + "\033[0m\033[0m")
elif COOPERATIVE_MODE in ['d', 'distributed']:
pass
def limit_tokens_from_string(string: str, model: str, limit: int) -> str:
"""Limits the string to a number of tokens (estimated)."""
try:
encoding = tiktoken.encoding_for_model(model)
except:
encoding = tiktoken.encoding_for_model('gpt2') # Fallback for others.
encoded = encoding.encode(string)
return encoding.decode(encoded[:limit])
client = OpenAI()
def openai_call(
prompt: str,
model: str = LLM_MODEL,
temperature: float = OPENAI_TEMPERATURE,
max_tokens: int = 100,
):
# Use 4000 instead of the real limit (4097) to give a bit of wiggle room for the encoding of roles.
trimmed_prompt = limit_tokens_from_string(prompt, model, 4000 - max_tokens)
# Use chat completion API
messages = [{"role": "system", "content": trimmed_prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
n=1,
stop=None,
)
return response.choices[0].message.content.strip()
def task_creation_agent(
objective: str, result: Dict, task_description: str, task_list: List[str]
):
prompt = f"""
You are to use the result from an execution agent to create new tasks with the following objective: {objective}.
The last completed task has the result: \n{result["data"]}
This result was based on this task description: {task_description}.\n"""
if task_list:
prompt += f"These are incomplete tasks: {', '.join(task_list)}\n"
prompt += "Based on the result, return a list of tasks to be completed in order to meet the objective. "
if task_list:
prompt += "These new tasks must not overlap with incomplete tasks. "
prompt += ""
Return one task per line in your response. The result must be a numbered list in the format:
#. First task
#. Second task
The number of each entry must be followed by a period. If your list is empty, write "There are no tasks to add at this time."
Unless your list is empty, do not include any headers before your numbered list or follow your numbered list with any other output. OUTPUT IN CHINESE"""
print(f'\n*****TASK CREATION AGENT PROMPT****\n{prompt}\n')
response = openai_call(prompt, max_tokens=2000)
print(f'\n****TASK CREATION AGENT RESPONSE****\n{response}\n')
new_tasks = response.split('\n')
new_tasks_list = []
for task_string in new_tasks:
task_parts = task_string.strip().split(".", 1)
if len(task_parts) == 2:
task_id = ''.join(s for s in task_parts[0] if s.isnumeric())
task_name = re.sub(r'[^
\w\s_]+', '', task_parts[1]).strip()
if task_name.strip() and task_id.isnumeric():
new_tasks_list.append(task_name)
# print('New task created: ' + task_name)
out = [{"task_name": task_name} for task_name in new_tasks_list]
return out
def prioritization_agent():
task_names = tasks_storage.get_task_names()
bullet_string = '\n'
prompt = f"""
You are tasked with prioritizing the following tasks: {bullet_string + bullet_string.join(task_names)}
Consider the ultimate objective of your team: {OBJECTIVE}.
Tasks should be sorted from highest to lowest priority, where higher-priority tasks are those that act as pre-requisites or are more essential for meeting the objective.
Do not remove any tasks. Return the ranked tasks as a numbered list in the format:
#. First task
#. Second task
The entries must be consecutively numbered, starting with 1. The number of each entry must be followed by a period.
Do not include any headers before your ranked list or follow your list with any other output. OUTPUT IN CHINESE"""
print(f'\n****TASK PRIORITIZATION AGENT PROMPT****\n{prompt}\n')
response = openai_call(prompt, max_tokens=2000)
print(f'\n****TASK PRIORITIZATION AGENT RESPONSE****\n{response}\n')
if not response:
print('Received empty response from priotritization agent. Keeping task list unchanged.')
return
new_tasks = response.split("\n") if "\n" in response else [response]
new_tasks_list = []
for task_string in new_tasks:
task_parts = task_string.strip().split(".", 1)
if len(task_parts) == 2:
task_id = ''.join(s for s in task_parts[0] if s.isnumeric())
task_name = re.sub(r'[^
\w\s_]+', '', task_parts[1]).strip()
if task_name.strip():
new_tasks_list.append({"task_id": task_id, "task_name": task_name})
return new_tasks_list
# Execute a task based on the objective and five previous tasks
def execution_agent(objective: str, task: str) -> str:
"""
Executes a task based on the given objective and previous context.
Args:
objective (str): The objective or goal for the AI to perform the task.
task (str): The task to be executed by the AI.
Returns:
str: The response generated by the AI for the given task.
"""
context = context_agent(query=objective, top_results_num=5)
# print("\n****RELEVANT CONTEXT****\n")
# print(context)
# print('')
prompt = f'OUTPUT IN CHINESE. Perform one task based on the following objective: {objective}.\n'
if context:
prompt += 'Take into account these previously completed tasks:' + '\n'.join(context)
prompt += f'\nYour task: {task}\nResponse:'
return openai_call(prompt, max_tokens=2000)
# Get the top n completed tasks for the objective
def context_agent(query: str, top_results_num: int):
"""
Retrieves context for a given query from an index of tasks.
Args:
query (str): The query or objective for retrieving context.
top_results_num (int): The number of top results to retrieve.
Returns:
list: A list of tasks as context for the given query, sorted by relevance.
"""
results = results_storage.query(query=query, top_results_num=top_results_num)
print("****RESULTS****")
print(results)
return results
# Add the initial task if starting new objective
if not JOIN_EXISTING_OBJECTIVE:
initial_task = {
"task_id": tasks_storage.next_task_id(),
"task_name": INITIAL_TASK
}
tasks_storage.append(initial_task)
def main():
loop = True
while loop:
# As long as there are tasks in the storage...
if not tasks_storage.is_empty():
# Print the task list
print("\033[95m\033[1m" + "\n*****TASK LIST*****\n" + "\033[0m\033[0m")
for t in tasks_storage.get_task_names():
print(" • " + str(t))
# Step 1: Pull the first incomplete task
task = tasks_storage.popleft()
print("\033[92m\033[1m" + "\n*****NEXT TASK*****\n" + "\033[0m\033[0m")
print(str(task["task_name"]))
# Send to execution function to complete the task based on the context
result = execution_agent(OBJECTIVE, str(task["task_name"]))
print("\033[93m\033[1m" + "\n*****TASK RESULT*****\n" + "\033[0m\033[0m")
print(result)
# Step 2: Enrich result and store in the results storage
# This is where you should enrich the result if needed
enriched_result = {
"data": result
}
# extract the actual result from the dictionary
# since we don't do enrichment currently
# vector = enriched_result["data"]
result_id = f"result_{task['task_id']}"
results_storage.add(task, result, result_id)
# Step 3: Create new tasks and re-prioritize task list
# only the main instance in cooperative mode does that
new_tasks = task_creation_agent(
OBJECTIVE,
enriched_result,
task["task_name"],
tasks_storage.get_task_names(),
)
print('Adding new tasks to task_storage')
for new_task in new_tasks:
new_task.update({"task_id": tasks_storage.next_task_id()})
print(str(new_task))
tasks_storage.append(new_task)
if not JOIN_EXISTING_OBJECTIVE:
prioritized_tasks = prioritization_agent()
if prioritized_tasks:
tasks_storage.replace(prioritized_tasks)
# Sleep a bit before checking the task list again
time.sleep(5)
else:
print('Done.')
loop = False
if __name__ == "__main__":
main()
1.4 Running
At this point, clicking run should succeed. However, it is particularly important to note that it is not recommended to run it directly. Due to the large model’s capability of planning tasks having great uncertainty, it may lead to your run generating a large number of tasks, and even the tasks will keep increasing without stopping. This will greatly consume your Key or Token, potentially leading to account suspension or even bankruptcy!!! I am running in debug mode, with breakpoints in each function, so I can stop at any time.
2. Process and Results Analysis
-
• Given Objective: What day of the week is Jay Chou’s birthday?
-
• Initial Task: Develop a task list
2.1 Running Output – Detailed Explanation
(1) Based on the given Objective and Initial Task. At the beginning, the Task List only contains one initial Task. Therefore, the next Task to execute is this initial Task. The execution_agent executes this task, and the result is a series of steps to achieve the Objective, producing four tasks. Honestly, that’s a bit too many.
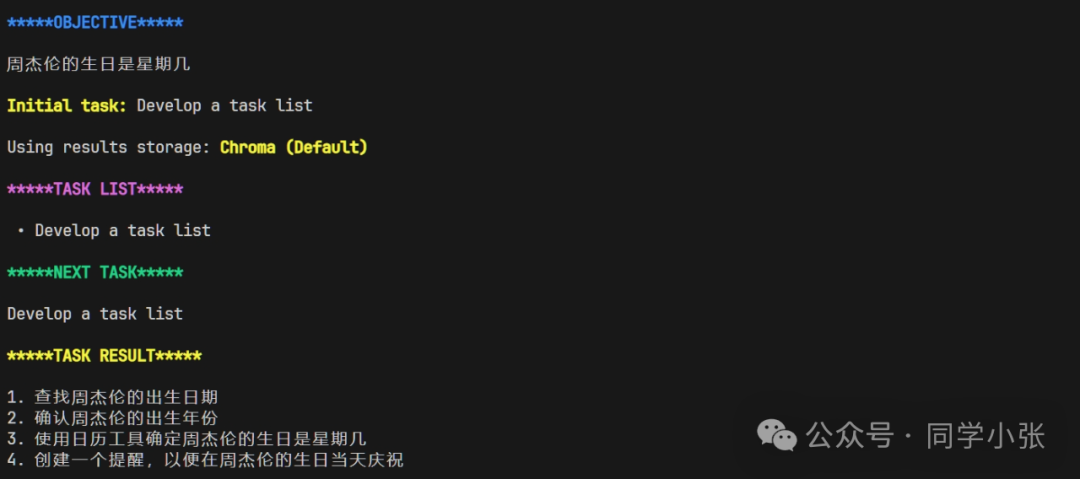
(2) Based on the results produced by execution_agent and the final Objective, task_creation_agent creates a new Task list and adds it to the task queue.
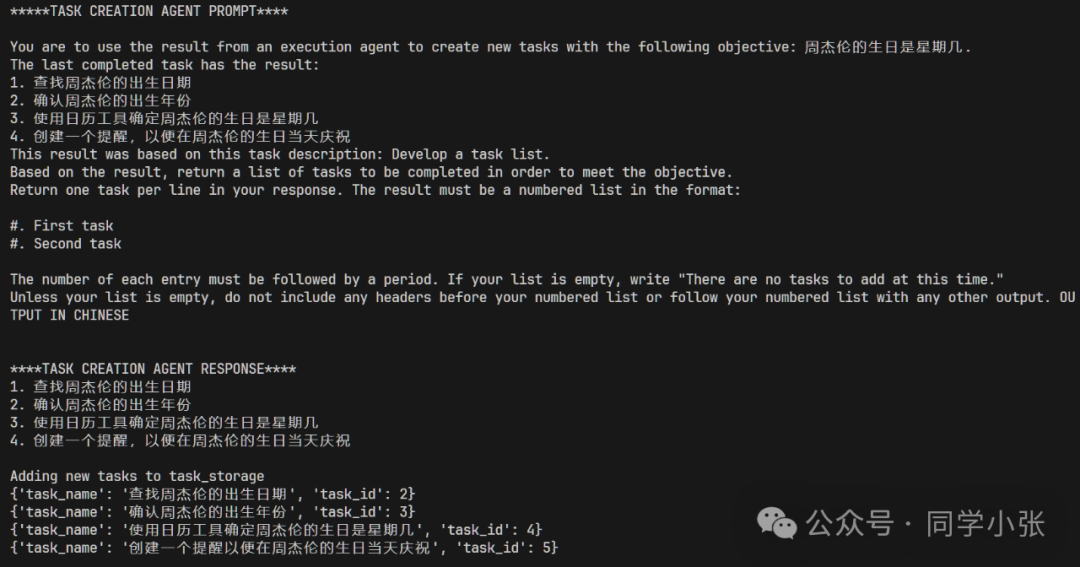
(3) Based on the task list generated by task_creation_agent, prioritization_agent sorts the tasks based on the task list and final objective. The sorting here is a bit unreliable; the capabilities of the large model are still unstable.
(4) The next loop begins, taking the first unfinished task from the task list. The execution_agent executes the task. The incorrect task sorting above leads to the large model giving a hallucinatory answer…

(5) Again, based on the results produced by the execution_agent and the final Objective, the task_creation_agent creates a new Task list and adds it to the task queue.
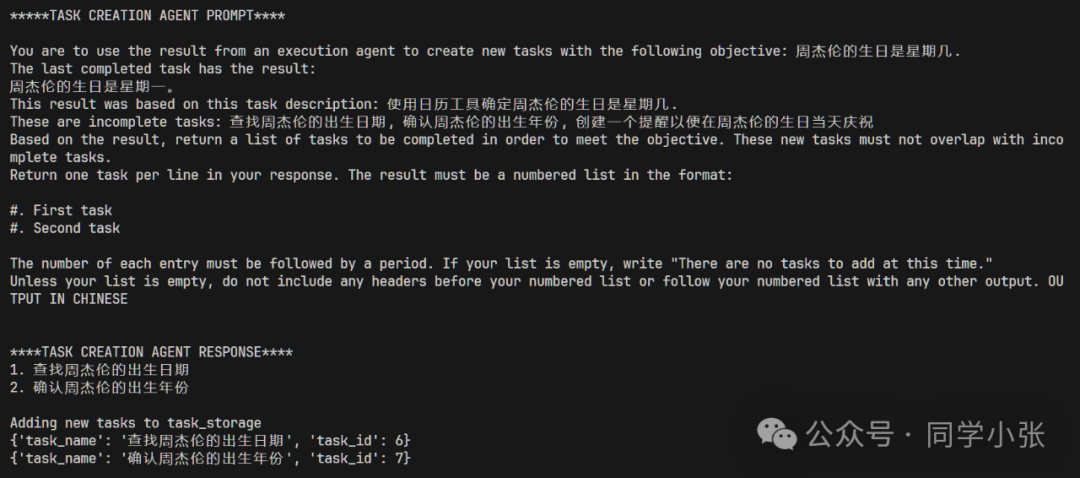
(6) Based on the new task list generated by task_creation_agent, prioritization_agent once again prioritizes based on the new task list and final objective.
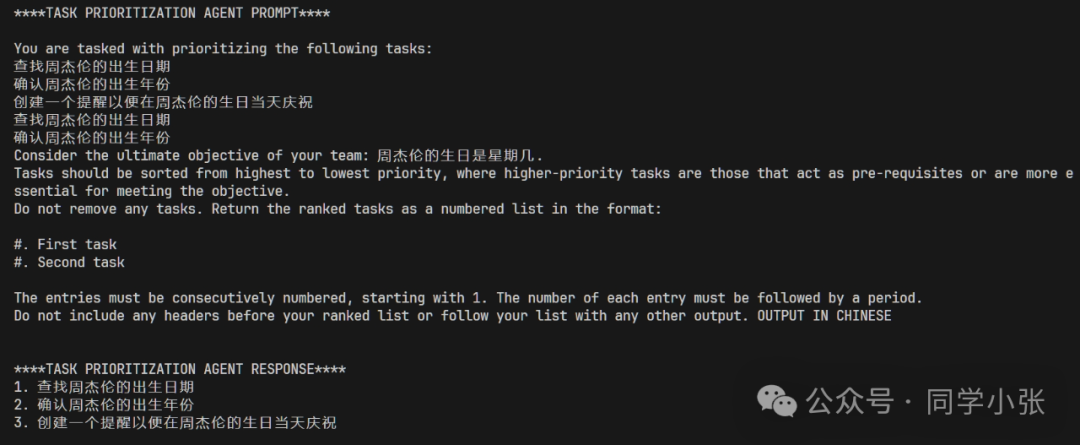
(7) Another round of looping begins, taking the first unfinished task from the task list, and the execution_agent executes the task.

(8) …… Continues looping until there are no unfinished tasks in the task queue.
Do you see it? At this rate, when will the task queue be empty? It’s a huge waste of tokens.
2.2 Problems and Reflections
From the above running process, it can be seen that this multi-agent case is too dependent on the capabilities of large models, just like I previously wrote about AutoGPT (【AI Large Model Application Development】【AutoGPT Series】2. Handwriting AutoGPT – A Step-by-Step Guide to Writing a Simplified AutoGPT from Scratch with LangChain).
Current issues and reflections:
(1) The first step generates too many subtasks – the initial task can include more prompts to limit the number or quality of tasks.
(2) The prioritization is somewhat unstable, heavily reliant on the capabilities of the large model. Perhaps human sorting needs to be introduced?
(3) Even if the answer can address the user’s set Objective, as long as there are unfinished tasks in the list, it will continue to run. – Need to add ending conditions or judgments.
For example, in the following case, I set the Objective as “What happened on this day in history?”. It directly queued a large number of unnecessary tasks.

Then actually, after executing the first task, I got the result I wanted.
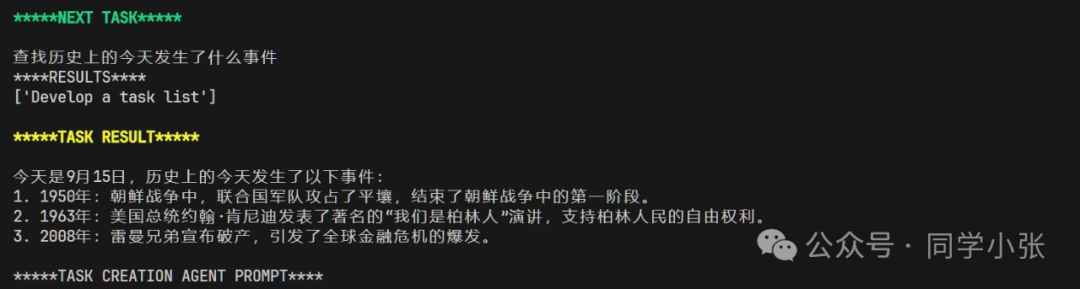
But it continues to create new tasks, and I have no idea when it will stop.
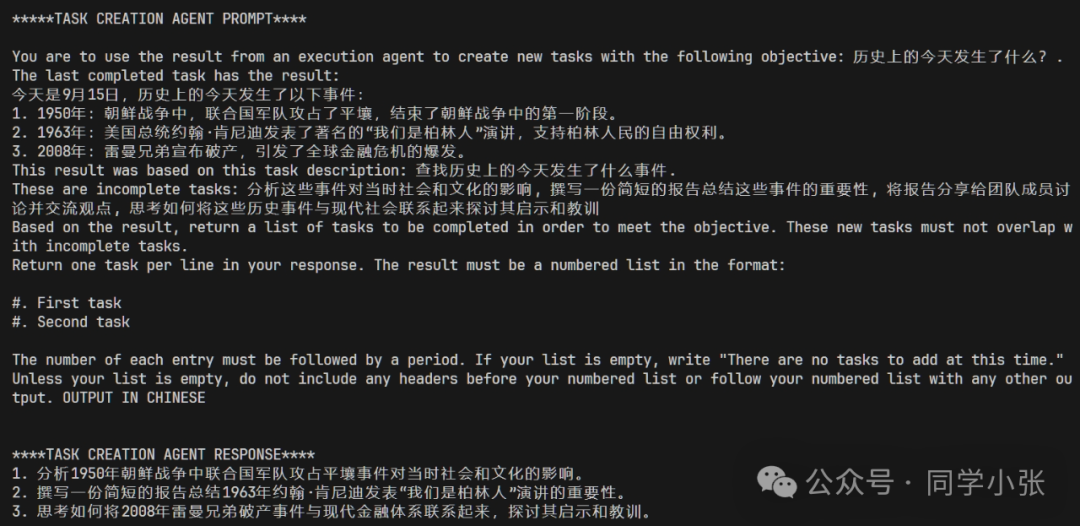
(4) The most serious problem mentioned earlier is the lack of a loop count limit. The code is essentially equivalent to while True, leading to an infinite loop. This is very dangerous.

(5) Another point I don’t understand is why in execution_agent it needs to retrieve previous tasks? It seems more appropriate to replace it with the execution results of previous tasks?

3. Summary
In this article, we learned about a native multi-agent case – BabyAGI, from environment setup to operation, providing detailed explanations for each step’s output, and finally offering some optimization thoughts on the issues discovered during the running process.
BabyAGI essentially utilizes large models for task planning, task prioritization, and task execution. These three processes loop continuously, along with some context information to obtain higher quality results until the final goal is met.
All three main processes rely heavily on the capabilities of large models, which can be somewhat uncontrollable. Currently, I believe it is relatively challenging to implement in practice. Let’s mainly learn its implementation ideas.